分类目录:《深入理解深度学习》总目录
相关文章:
作为当下最先进的深度学习架构之一,Transformer被广泛应用于自然语言处理领域。它不单替代了以前流行的循环神经网络(recurrent neural network, RNN)和长短期记忆(long short-term memory, LSTM)网络,并且以它为基础衍生出了诸如BERT、GPT-3、T5等知名架构。
循环神经网络和长短期记忆网络已经广泛应用于时序任务,比如文本预测、机器翻译、文章生成等。然而,它们面临的一大问题就是如何记录长期依赖。为了解决这个问题,一个名为Transformer的新架构应运而生。从那以后,Transformer被应用到多个自然语言处理方向,到目前为止还未有新的架构能够将其替代。可以说,它的出现是自然语言处理领域的突破,并为新的革命性架构(BERT、GPT-3、T5等)打下了理论基础。
Transformer完全依赖于注意力机制,并摒弃了循环。它使用的是一种特殊的注意力机制,称为自注意力(self-attention)。在《深入理解深度学习——注意力机制(Attention Mechanism):自注意力(Self-attention)》文章中,我们比较了卷积神经网络(CNN)、循环神经网络(RNN)和自注意力(self-attention)。值得注意的是,自注意力同时具有并行计算和最短的最大路径长度这两个优势。因此,使用自注意力来设计深度架构是很有吸引力的。对比之前仍然依赖循环神经网络实现输入表示的自注意力模型,Transformer模型完全基于注意力机制,没有任何卷积层或循环神经网络层。尽管Transformer最初是应用于在文本数据上的序列到序列学习,但现在已经推广到各种现代的深度学习中,例如语言、视觉、语音和强化学习领域。
Transformer作为“编码器—解码器”架构的一个实例,其整体架构图在下图中展示。正如所见到的,Transformer是由编码器和解码器组成的。与《深入理解深度学习——注意力机制(Attention Mechanism):Bahdanau注意力》中基于Bahdanau注意力实现的序列到序列的学习相比,Transformer的编码器和解码器是基于自注意力的模块叠加而成的,源(输入)序列和目标(输出)序列的嵌入(Embedding)表示将加上位置编码(Positional Encoding),再分别输入到编码器和解码器中。
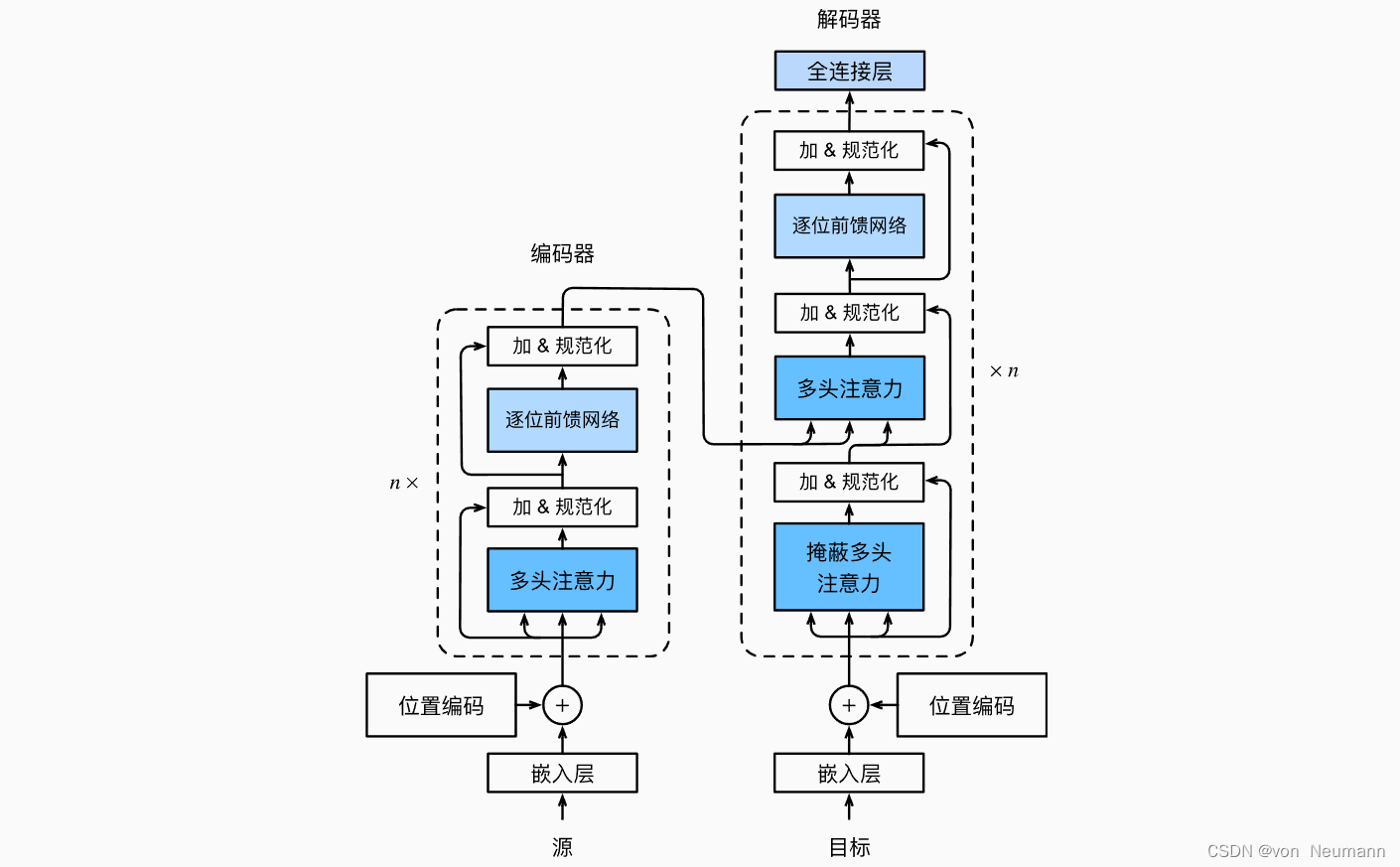
上图概述了Transformer的架构。从宏观角度来看,Transformer的编码器是由多个相同的层叠加而成的,每个层都有两个子层。第一个子层是多头自注意力(Multi-head Self-attention)汇聚;第二个子层是基于位置的前馈网络(Positionwise Feed-forward Network)。具体来说,在计算编码器的自注意力时,查询、键和值都来自前一个编码器层的输出。受残差网络的启发,每个子层都采用了残差连接(Residual Connection)。在Transformer中,对于序列中任何位置的任何输入 x ∈ R d x \in R^d x∈Rd都要求满足 Sublayer ( x ) ∈ R d \text{Sublayer}(x) \in R^d Sublayer(x)∈Rd,以便残差连接满足 x + Sublayer ( x ) ∈ R d x + \text{Sublayer}(x) \in R^d x+Sublayer(x)∈Rd。在残差连接的加法计算之后,紧接着应用层规范化(Layer Normalization)。因此,输入序列对应的每个位置,Transformer编码器都将输出一个 d d d维表示向量。
Transformer解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化。除了编码器中描述的两个子层之外,解码器还在这两个子层之间插入了第三个子层,称为“编码器—解码器”注意力(Encoder-decoder Attention)层。在“编码器—解码器”注意力中,查询来自前一个解码器层的输出,而键和值来自整个编码器的输出。在解码器自注意力中,查询、键和值都来自上一个解码器层的输出。但是,解码器中的每个位置只能考虑该位置之前的所有位置。这种掩蔽(Masked)注意力保留了自回归(Auto-regressive)属性,确保预测仅依赖于已生成的输出词元。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015
[2] Aston Zhang, Zack C. Lipton, Mu Li, Alex J. Smola. Dive Into Deep Learning[J]. arXiv preprint arXiv:2106.11342, 2021.
[3] Sudharsan Ravichandiran. BERT基础教程:Transformer大模型实战[M]. 人民邮电出版社, 2023