7. Hive分桶
7.1 分桶概述
分区提供一个通过目录隔离数据和查询优化的的遍历方式,不过不是所有的数据集都能形参合理的分区。对于一张表或这分区,可以进一步形参分桶,相比于分区分桶是个更小粒度的数据范围的划分。
分桶表是对列值取哈希值取模的方式,将不同数据放到不同文件中存储;由列的哈希值除以桶的个数得到的余数来决定每条数据划分在哪个桶中。
分区的本质是分目录,分桶的本质是分文件。
适用场景:
数据抽样( sampling )
关联查询
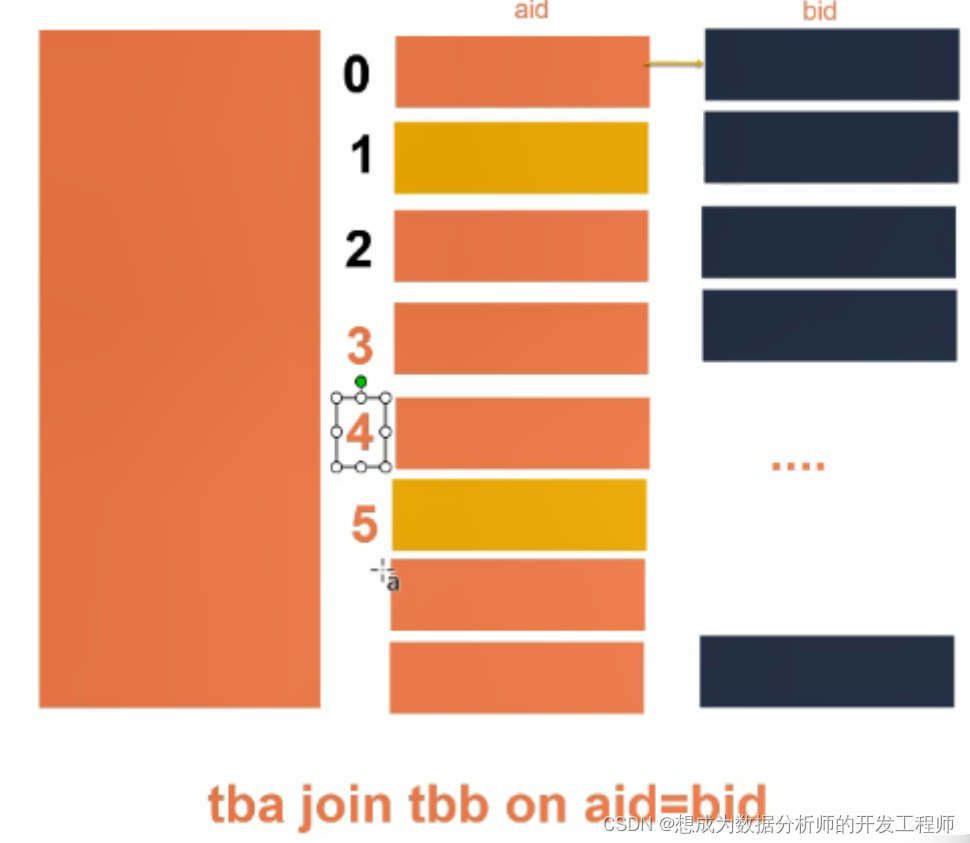
mr运行时会根据bucket的个数自动分配reduce task个数。
(用户也可以通过mapred.reduce.tasks自己设置reduce任务个数,但分桶时不推荐使用)注意:一次作业产生的桶数(文件数量)和reduce task个数一致
7.2 分桶操作
7.2.1 创建分桶表
建表脚本:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT
EXISTS] [db_name.]table_name
[(col_name data_type
[column_constraint_specification] [COMMENT
col_comment], ... [constraint_specification])]
[PARTITIONED BY (col_name data_type [COMMENT
col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO
num_buckets BUCKETS]
[ROW FORMAT row_format]
创建分桶表:
create table psnbucket( id int, name string, age int)
clustered by (age) into 4 buckets
row format delimited fields terminated by ',';
创建原始数据表:
create table psn31( id int, name string, age int)
row format delimited fields terminated by ',';
准备测试数据
[root@node4 data]# vim bucket
1,tom,11
2,cat,22
3,dog,33
4,hive,44
5,hbase,55
6,mr,66
7,alice,77
8,scala,88
将数据给添加到psn31表中:
hive> load data local inpath '/root/data/bucket' into table psn31;
Loading data to table default.psn31
OK
Time taken: 1.656 seconds
hive> select * from psn31;
OK
psn31.id psn31.name psn31.age
1 tom 11
2 cat 22
3 dog 33
4 hive 44
5 hbase 55
6 mr 66
7 alice 77
8 scala 88
Time taken: 3.263 seconds, Fetched: 8 row(s)
将psn31中的数据导入到psnbucket分桶表中
hive> insert into table psnbucket select id,name,age from psn31;
Query ID = root_20211119125326_ea57ba42-a38f-
43d9-9c78-b9ce17d7cf4d
Total jobs = 2
Hadoop job information for Stage-1: number of
mappers: 1; number of reducers: 4
4个桶对应四个reduce任务数。
查看结果文件列表:
[root@node4 data]# hdfs dfs -ls /user/hive_remote/warehouse/psnbucket
Found 4 items
-rw-r--r-- 3 root supergroup 21 2021-
11-19 12:55
/user/hive_remote/warehouse/psnbucket/000000_0
-rw-r--r-- 3 root supergroup 20 2021-
11-19 12:54
/user/hive_remote/warehouse/psnbucket/000001_0
-rw-r--r-- 3 root supergroup 17 2021-
11-19 12:54
/user/hive_remote/warehouse/psnbucket/000002_0
-rw-r--r-- 3 root supergroup 20 2021-
11-19 12:55
/user/hive_remote/warehouse/psnbucket/000003_0
查看文件中的内容
[root@node4 data]# hdfs dfs -cat
/user/hive_remote/warehouse/psnbucket/000000_0
8,scala,88
4,hive,44
[root@node4 data]# hdfs dfs -cat
/user/hive_remote/warehouse/psnbucket/000001_0
7,alice,77
3,dog,33
[root@node4 data]# hdfs dfs -cat
/user/hive_remote/warehouse/psnbucket/000002_0
6,mr,66
2,cat,22
[root@node4 data]# hdfs dfs -cat
/user/hive_remote/warehouse/psnbucket/000003_0
5,hbase,55
1,tom,11
7.2.2 抽样查询分析(了解)
select * from bucket_table tablesample(bucket x out of y on columns);
tablesample语法:
tablesample(bucket x out of y on columns)
x:表示从哪个bucket开始抽取数据
y:必须为该表总bucket数的倍数或因子
columns:分桶的列名
当表总bucket数为32时
-
TABLESAMPLE(BUCKET 3 OUT OF 16 on columns),抽取哪些数据?
共抽取2(32/16)个bucket的数据,抽取第3、第19(3+16)个bucket的数据 -
TABLESAMPLE(BUCKET 3 OUT OF 8 on columns),抽取哪些数据?
共抽取4(32/8)个bucket的数据,抽取:3,11,19,27 -
TABLESAMPLE(BUCKET 3 OUT OF 256 on columns),抽取哪些数据?
共抽取1/8(32/256)个bucket的数据,抽取第3个bucket的1/8数据。
该描述在hive1.2.1的版本中如上所描述的一致(和hive官网中的说法一致)
但是在hive3.1.2的版本中使用时,有bug。
当表总bucket数为4时
抽取1和3号桶中的数据:
select * from psnbucket tablesample(bucket 1 out of 2 on age);
注意:x<=y,不能是x>y。如果x>y将会出现如下的错误提示:
hive> select * from psnbucket
tablesample(bucket 5 out of 4 on age);
FAILED: SemanticException [Error 10061]:
Numerator should not be bigger than denominator
in sample clause for table psnbucket
总结:分区是分目录存储,分桶是将表中的数据分文件存储。