前言
因为一直接触的是闭源的东西,所以一直很想和大家分享一点关于这部分的实现,碰巧看到了痞子叔的博客,于是一起来学习一下。
我所涉及到的平时都是基于ARM架构的自研SoC,这次还是第一次搞恩智浦的MCU,所以也是有很多值得学习的。我会在文末放上原文链接,访问原文可以看到更多精彩的文章。
下面开始吧。
DCP
整个MCU是有很多的模块,但是因为我们只是关注于加解密,因此这里就不展开其他的,更多可以访问前辈的原文。这里只关注于加解密模块。
i.MXRT不仅仅是处理性能超强的MCU,也是安全等级极高的MCU。如果大家用过痞子衡开发的一站式安全启动工具 NXP-MCUBootUtility,应该会从其 用户手册 3.3节中了解到i.MXRT支持的几种安全启动等级,其中HAB加密启动方式和BEE/OTFAD加密启动方式中都提及了一种神秘的密钥 - SNVS Master Key,今天痞子衡就跟大家聊聊这个密钥用于DCP模块的注意事项(文中仅以i.MXRT1060为例,其他RT10xx型号或许有微小差别)。
一、DCP模块简介
先来给大家科普下DCP模块,DCP是Data Co-Processor的简称,从名字上看是个通用数据协处理器。在i.MXRT1060 Security Reference Manual中有一张系统整体安全架构简图,这个简图中标出了DCP模块的主要功能 :CRC-32算法、AES算法、Hash算法、类DMA数据搬移。
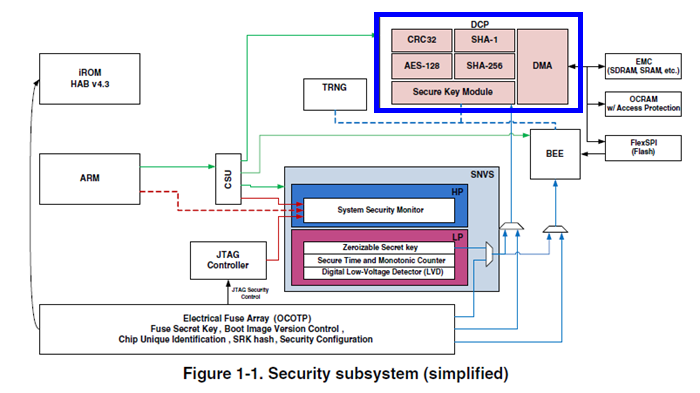
看到DCP支持的功能,你就能明白其模块命名的由来了。本质上它就是一个数据处理加速器,如果说CRC-32/Hash算法只是算出一个结果(下图中Mode3),而AES算法则是明文数据到密文数据的转换(存在数据迁移,下图中Mode2),DMA式数据搬移则更明显了(下图中Mode1),DCP内部集成了memcopy功能,可以实现比普通DMA方式效率更高的内存到内存数据块搬移,memcopy功能还支持blit模式,支持传输矩形数据块到frame buffer用于LCD显示。

我们今天主要是聊DCP的AES加解密功能,其支持AES-128算法,包含Electronic Code Book (ECB)和Cipher Block Chaining (CBC)模式,算法标准符合 NIST US FIPS PUB 197 (2001)规范,AES运算的最小单元是16字节。
二、DCP-AES密钥来源
对于加解密而言,一个很重要的特性就是密钥管理。 DCP的AES密钥(长度均为128bits)来源很丰富,按性质可分成四类:
- SRAM-based keys: 用户自定义的存放于SRAM中的密钥,最终会被写入DCP的KEY_DATA寄存器中,最多四组。
- Payload key: 用户自定义的跟加解密数据放一起的密钥,操作时DCP直接解析。
- eFuse SW_GP2 key: 用户烧录到eFuse SW_GP2区域的密钥,可锁定住让软件无法访问,但DCP可通过内置专用途径获取到。
- SNVS Master key: 芯片出厂时预存的唯一密钥,密钥值无法获知,DCP可通过内置专用途径获取到。
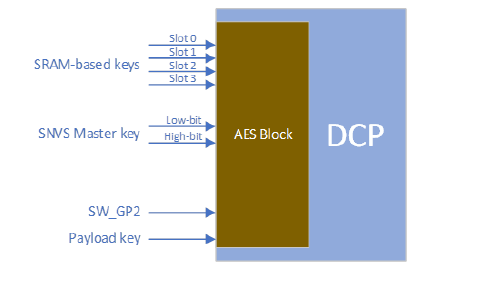
选用SRAM-based keys和Payload key仅需要在DCP模块内部配置即可,而选用eFuse SW_GP2 key和SNVS Master key则要在如下IOMUXC_GPR寄存器中额外设置。
IOMUXC_GPR_GPR10寄存器用于选择Key是来自eFuse SW_GP2还是SNVS Master Key:

IOMUXC_GPR_GPR3寄存器用于选择Key是来自SNVS Master Key(总256bits)的低128bit还是高128bit(注意此寄存器对eFuse SW_GP2其实不生效,因为SW_GP2仅128bits):

三、什么是SNVS Master Key?
SNVS全称Secure Non-Volatile Storage,它既是DCP的配套模块,也是芯片系统的安全事务监测中心。它能够提供一个独特的Master Key给DCP模块,这个Master Key可有三种产生方式**(在SNVS_LPMKCR中设置):**

- OTPMK:这种就是直接使用eFuse里出厂预烧录的OTPMK(256bits),这个OTPMK是每个芯片唯一的,并且被锁住了软件不可访问。
- ZMK:这种是利用存在SNVS_LP ZMKRx寄存器组中的密钥,该秘钥可由用户写入,此密钥在芯片主电源断掉时会继续保留(因为在LP域可由纽扣电池供电),在芯片受到安全攻击时密钥会被自动擦除。
- CMK:前两者组合后的Key,即OTPMK和ZMK的异或结果。
一般来说,使用最多的SNVS Master Key就是默认的OTPMK。
四、两种DCP驱动
关于DCP模块的驱动,在下载的芯片SDK包里有两种:
- ROM版本:\SDK_2.x.x_EVK-MIMXRT1060\devices\MIMXRT1062\drivers\fsl_dcp.c
- SDK版本:\SDK_2.x.x_EVK-MIMXRT1060\middleware\mcu-boot\src\drivers\dcp\fsl_dcp.c
middleware里的DCP驱动是ROM team负责的,他们是在芯片Tapeout之前写的,属于早期驱动;device包里的DCP驱动才是SDK team负责的,是芯片Tapeout之后写的,是正式版本。
两版驱动都实现了AES加解密,不过代码风格不同。
- 比如ROM版本驱动的dcp_aes_ecb_crypt()函数同时支持加密和解密模式,
- 而在SDK版本驱动里则分成两个函数:DCP_AES_EncryptEcb() - 加密 、DCP_AES_DecryptEcb() - 解密。
五、DCP正确获取SNVS Master Key
前面铺垫了那么多,终于来到正题了。DCP模块如何拿到正确的SNVS Master Key?
让我们以\SDK_2.x.x_EVK-MIMXRT1060\boards\evkmimxrt1060\driver_examples\dcp 例程来做个测试。
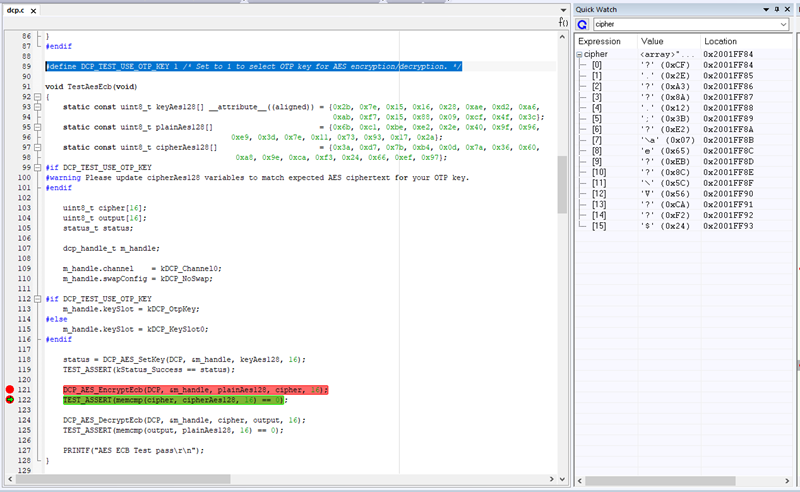
这个dcp例程演示了五种DCP工作模式,我们就测试第一种TestAesEcb(),将宏DCP_TEST_USE_OTP_KEY改为1,即使用OTPMK低128bits作为DCP的密钥:
#define DCP_TEST_USE_OTP_KEY 1 /* Set to 1 to select OTP key for AES encryption/decryption. */
int main(void)
{
dcp_config_t dcpConfig;
// ...
/* Initialize DCP */
DCP_GetDefaultConfig(&dcpConfig);
#if DCP_TEST_USE_OTP_KEY
/* Set OTP key type in IOMUX registers before initializing DCP. */
/* Software reset of DCP must be issued after changing the OTP key type. */
DCP_OTPKeySelect(kDCP_OTPMKKeyLow);
#endif
/* Reset and initialize DCP */
DCP_Init(DCP, &dcpConfig);
/* Call DCP APIs */
TestAesEcb();
// ...
}
在初始芯片状态(Hab Open)下,使用J-Link下载工程进RAM直接单步调试看一看,在执行完DCP_AES_EncryptEcb()函数后查看cipher[]数组,可以看到其值为0xCF, 0x2E, 0xA3…,好吧我们根本不知道SNVS Master Key到底是多少,所以这个密文是否正确也无从知晓。
既然无法得知SNVS Master Key,那我们做个小实验,使用SRAM-based keys来做一次加密,密钥姑且设个全0吧,再看一下结果,你发现了什么,cipher[]的值是不是很熟悉?跟之前SNVS Master Key加密的结果一致,难道这颗芯片的SNVS Master Key是全0?想想不可能,肯定是流程哪里出了问题!

现在让我们再回忆 MCUBootUtility 用户手册里关于测试HAB加密以及BEE/OTFAD加密使用SNVS Master Key的前提条件,是的,芯片状态需要先设置为Hab Close,好,让我们现在在eFuse里将SEC_CONFIG[1:0]设为2’b10(Hab Close),然后再次使用J-Link调试进去看一看,怎么回事?cipher[]值依旧是0xCF, 0x2E, 0xA3…

上面的测试对TestAesEcb()函数做了一个简单的修改,将cipher[]值通过串口打印出来,那我们就将程序通过NXP-MCUBootUtility下载到Flash里由ROM来启动运行吧(退出调试状态),我们再来看串口打印,哈哈,终于值变了,这意味着DCP终于拿到了正确的SNVS Master Key(非0)。
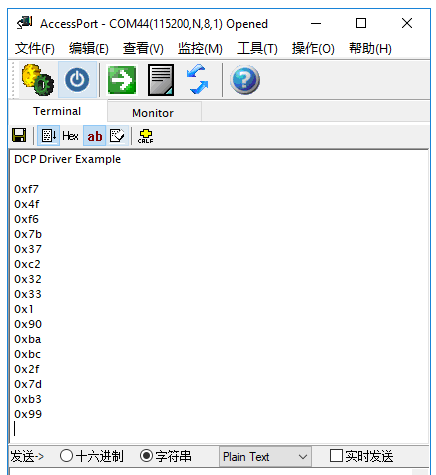
总结一下,SNVS Master Key仅在芯片Hab状态是Close并且非调试状态下才能被DCP正常获取,否则DCP获取到的是全0的假Key。(什么是HAB状态)
至此,i.MXRT系列中数据协处理器DCP使用SNVS Master Key加解密的注意事项痞子衡便介绍完毕了,掌声在哪里~~~(痞子叔鼓掌)
DCP硬件引擎做Hash校验偶尔会失败?
今天痞子衡给大家介绍的是利用i.MXRT1xxx系列内部DCP引擎计算Hash值时需特别处理L1 D-Cache。
实际上DCP模块除了对AES加解密算法支持外,还支持经典的Hash算法(SHA-1/SHA-256/CRC32)。
一、客户项目基本情况
先介绍下客户基本情况,他们项目使用的主芯片是i.MXRT1062,并且配置了外部串行Flash存储程序代码(XiP),以及外部SDRAM放置程序数据区(其实主要是做frameBuffer的,但也同时放置了.data段和STACK),项目基于的SDK版本是v2.6.2。
项目中主要调用了 \SDK_2.6.2_EVK-MIMXRT1060\middleware\mbedtls\library\sha256.c 中的 mbedtls_sha256() 函数,这个函数其实是通过调用 \SDK_2.6.2_EVK-MIMXRT1060\middleware\mbedtls\port\ksdk\ksdk_mbedtls.c 里的一系列底层函数mbedtls_sha256_xx() 来进一步实现的。
ksdk_mbedtls.c 文件是同时适用Kinetis/LPC/i.MXRT等系列MCU的,不同MCU上硬件引擎不同(比如有LTC/CAAM/CAU3/DCP/HashCrypt)。对于i.MXRT1xxx,硬件引擎就是DCP,这些 mbedtls_sha256_xx() 函数主要调用了 SDK 标准驱动 fsl_dcp.c 里的如下函数:
status_t DCP_HASH_Init(DCP_Type *base, dcp_handle_t *handle, dcp_hash_ctx_t *ctx, dcp_hash_algo_t algo);
status_t DCP_HASH_Update(DCP_Type *base, dcp_hash_ctx_t *ctx, const uint8_t *input, size_t inputSize);
status_t DCP_HASH_Finish(DCP_Type *base, dcp_hash_ctx_t *ctx, uint8_t *output, size_t *outputSize);
二、概率性失败情况分析
既然是概率性失败的问题,那大概率和Cache处理有关了,我们需要检查下 fsl_dcp.c 驱动是否很好地处理了Cache。
让我们打开 \SDK_2.6.2_EVK-MIMXRT1060\boards\evkmimxrt1060\driver_examples\dcp 例程先看一下,在 dcp.c 文件的 main() 函数里可以看到明显的提醒。
**如果项目里用到了SDRAM,必须将DCache关掉,说明 dcp 驱动并不支持在DCache使能下运行。**但显然这个客户项目用到了SDRAM,后来跟客户确认,他们DCache一直是使能的,这显然是有问题的。
int main(void)
{
dcp_config_t dcpConfig;
/* Init hardware*/
BOARD_ConfigMPU();
BOARD_InitPins();
BOARD_BootClockRUN();
BOARD_InitDebugConsole();
/* Data cache must be temporarily disabled to be able to use sdram */
SCB_DisableDCache();
...
让我们再次回到SDK版本,在 恩智浦SDK下载主页 可以看到所有i.MXRT1060 SDK历史版本,v2.6.2是2019年7月发布的(这个版本里的dcp驱动版本是v2.1.1),是的,这个客户算是i.MXRT早期客户了。而现在最新的SDK版本已经是v2.9.3(dcp驱动已经升级到v2.1.6),时间快过去两年了,客户并没有实时更新SDK版本。
早期的 dcp 驱动没有处理DCache,所以其必须在 DCache 关掉的情况下才能正常工作。从v2.1.5开始增加了对 DCache 的处理,这样 dcp 驱动就可以在 DCache 使能的情况下正常工作了。
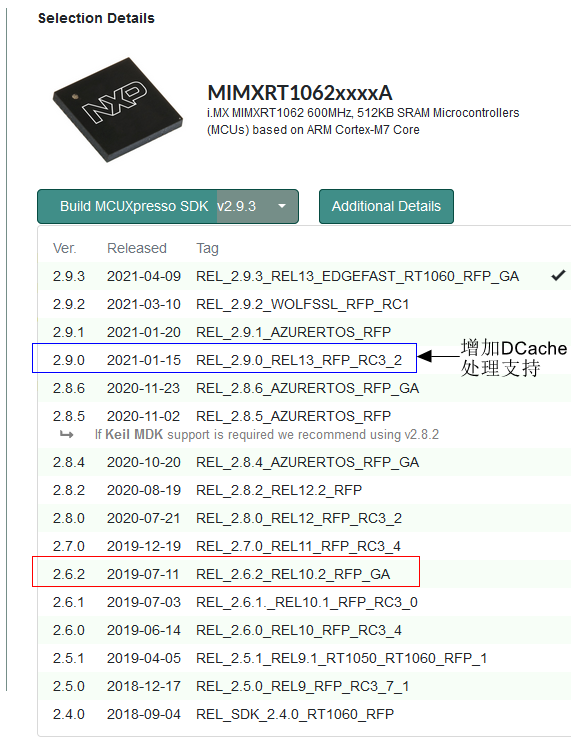
三、DCP驱动里是如何处理DCache的?
现在让我们在SDK标准驱动 fsl_dcp.c 中看一下它到底是怎么增加对DCache处理的。
3.1 DCP上下文buffer设置
使用 dcp 驱动的第一步是DCP模块初始化,即DCP_Init()函数,这个函数会在DCP->CTRL寄存器里将模块全部的四通道都使能以及将上下文(Context)的缓存和通道自切换功能也都开启,其中关于上下文切换有一个重要的私有全局变量 s_dcpContextSwitchingBuffer,这个变量被放置到了NON-CACHE区域(驱动改进处一)。下述DCP->CONTEXT寄存器就是用来存储 s_dcpContextSwitchingBuffer 地址的。

AT_NONCACHEABLE_SECTION_INIT(static dcp_context_t s_dcpContextSwitchingBuffer);
void DCP_Init(DCP_Type *base, const dcp_config_t *config)
{
// 代码省略...
/* use context switching buffer */
base->CONTEXT = (uint32_t)&s_dcpContextSwitchingBuffer;
}
3.2 DCP用户数据in/out buffer设置
DCP 模块初始化完成后,就是调用 dcp 驱动里的DCP_HASH()函数进行Hash运算,这个函数参数里有两个用户Buffer,一个Input Buffer存放待计算的消息数据,另一个Output Buffer存放计算好的Hash值(SHA256是32bytes),这两个Buffer最好由用户处理放置在NON-CACHE区。
/* Input data for DCP like input and output should be handled properly
* when DCACHE is used (e.g. Clean&Invalidate, use non-cached memory)
*/
AT_NONCACHEABLE_SECTION(static uint8_t s_outputSha256[32]);
status_t calc_sha256(const uint8_t *messageBuf, uint32_t messageLen)
{
size_t outLength = sizeof(s_outputSha256);
dcp_handle_t m_handle;
m_handle.channel = kDCP_Channel0;
m_handle.keySlot = kDCP_KeySlot0;
m_handle.swapConfig = kDCP_NoSwap;
memset(&s_outputSha256, 0, outLength);
return DCP_HASH(DCP, &m_handle, kDCP_Sha256, messageBuf, messageLen, s_outputSha256, &outLength);
}
3.3 DCP_HASH()相关代码中DCache处理
DCP_HASH()函数运行过程中会一直用到一个非常关键的内部结构体 dcp_hash_ctx_internal_t,这个结构体大小为47 Words(包含128byte的待计算消息数据块blk、32bytes实时计算结果runningHash、及其他辅助变量成员)。
/*! internal dcp_hash context structure */
typedef struct _dcp_hash_ctx_internal
{
dcp_hash_block_t blk; /*!< memory buffer. only full blocks are written to DCP during hash updates */
size_t blksz; /*!< number of valid bytes in memory buffer */
dcp_hash_algo_t algo; /*!< selected algorithm from the set of supported algorithms */
dcp_hash_algo_state_t state; /*!< finite machine state of the hash software process */
uint32_t fullMessageSize; /*!< track message size */
uint32_t ctrl0; /*!< HASH_INIT and HASH_TERM flags */
uint32_t runningHash[9]; /*!< running hash. up to SHA-256 plus size, that is 36 bytes. */
dcp_handle_t *handle;
} dcp_hash_ctx_internal_t;
dcp 驱动直接定义了 dcp_hash_ctx_t 型局部变量hashCtx,hashCtx空间后续会被用作dcp_hash_ctx_internal_t。旧版本里DCP_HASH_CTX_SIZE值为58,新版本增加到64,这是为了后续L1DCACHE的LINE对齐(驱动改进处二)。
/*! @brief DCP HASH Context size. */
#define DCP_HASH_CTX_SIZE 64
/*! @brief Storage type used to save hash context. */
typedef struct _dcp_hash_ctx_t
{
uint32_t x[DCP_HASH_CTX_SIZE];
} dcp_hash_ctx_t;
status_t DCP_HASH(DCP_Type *base, dcp_handle_t *handle, dcp_hash_algo_t algo, const uint8_t *input, size_t inputSize, uint8_t *output, size_t *outputSize)
{
dcp_hash_ctx_t hashCtx = {0};
status_t status;
status = DCP_HASH_Init(base, handle, &hashCtx, algo);
status = DCP_HASH_Update(base, &hashCtx, input, inputSize);
status = DCP_HASH_Finish(base, &hashCtx, output, outputSize);
// ...
}
status_t DCP_HASH_Init/Update/Finish(...,dcp_hash_ctx_t *ctx,...)
{
dcp_hash_ctx_internal_t *ctxInternal;
/* Align structure on DCACHE line*/
#if defined(__DCACHE_PRESENT) && (__DCACHE_PRESENT == 1U) && defined(DCP_USE_DCACHE) && (DCP_USE_DCACHE == 1U)
ctxInternal = (dcp_hash_ctx_internal_t *)(uint32_t)((uint8_t *)ctx + FSL_FEATURE_L1DCACHE_LINESIZE_BYTE);
#else
ctxInternal = (dcp_hash_ctx_internal_t *)(uint32_t)ctx;
#endif
// 代码省略...
}
DCP_HASH()函数中启动DCP引擎去计算消息块数据前,都会调用 DCACHE_InvalidateByRange() 函数对 ctxInternal 所占空间做清理(驱动改进处三)。启动DCP引擎工作一次的函数是dcp_hash_update(),这个函数会利用 dcp_work_packet_t 型结构体变量,对于这个结构,代码中也同样做了L1DCACHE对齐处理(驱动改进处四):
/*! @brief DCP's work packet. */
typedef struct _dcp_work_packet
{
uint32_t nextCmdAddress;
uint32_t control0;
uint32_t control1;
uint32_t sourceBufferAddress;
uint32_t destinationBufferAddress;
uint32_t bufferSize;
uint32_t payloadPointer;
uint32_t status;
} dcp_work_packet_t;
#if defined(__DCACHE_PRESENT) && (__DCACHE_PRESENT == 1U) && defined(DCP_USE_DCACHE) && (DCP_USE_DCACHE == 1U)
static inline uint32_t *DCP_FindCacheLine(uint8_t *dcpWorkExt)
{
while (0U != ((uint32_t)dcpWorkExt & ((uint32_t)FSL_FEATURE_L1DCACHE_LINESIZE_BYTE - 1U)))
{
dcpWorkExt++;
}
return (uint32_t *)(uint32_t)dcpWorkExt;
}
#endif
static status_t dcp_hash_update(DCP_Type *base, dcp_hash_ctx_internal_t *ctxInternal, const uint8_t *msg, size_t size)
{
status_t completionStatus = kStatus_Fail;
/* Use extended DCACHE line size aligned structure */
#if defined(__DCACHE_PRESENT) && (__DCACHE_PRESENT == 1U) && defined(DCP_USE_DCACHE) && (DCP_USE_DCACHE == 1U)
dcp_work_packet_t *dcpWork;
uint8_t dcpWorkExt[sizeof(dcp_work_packet_t) + FSL_FEATURE_L1DCACHE_LINESIZE_BYTE] = {0U};
dcpWork = (dcp_work_packet_t *)(uint32_t)DCP_FindCacheLine(dcpWorkExt);
#else
dcp_work_packet_t dcpWorkPacket = {0};
dcp_work_packet_t *dcpWork = &dcpWorkPacket;
#endif
do
{
completionStatus = dcp_hash_update_non_blocking(base, ctxInternal, dcpWork, msg, size);
} while (completionStatus == (int32_t)kStatus_DCP_Again);
completionStatus = DCP_WaitForChannelComplete(base, ctxInternal->handle);
ctxInternal->ctrl0 = 0;
return (completionStatus);
}
至此,利用i.MXRT1xxx系列内部DCP引擎计算Hash值时需特别处理L1 D-Cache痞子衡便介绍完毕了,掌声在哪里~~~
太硬核,内容太干了,瑞斯拜。
MbedTLS算法库软硬件实现效率差别竟然这么大?
今天给大家介绍的是MbedTLS算法库纯软件实现与i.MXRT上DCP,CAAM硬件加速器实现性能差异。
近期有 i.MXRT 客户在集成 OTA SBL 项目去实现产品的 2nd bootloader 时遇到了 MbedTLS 库算法性能问题,客户想知道 MbedTLS 纯软件实现和使用 i.MXRT 芯片里的硬件加速器实现,在性能上差距有多大。借着客户这个问题,我们今天就在 i.MXRT 上实测看一下两个方式的性能差异。
客户使用的是 i.MXRT1170,这个型号上的硬件加速器是 CAAM,相比前一代架构 i.MXRT10xx 系列上的 DCP 有升级,我们今天把 DCP 和 CAAM 同时测一下。
一、mbedtls算法库简介
MbedTLS(前身 PolarSSL)是一个开源的 SSL/TLS 算法库,最早由 ARM 公司开源和维护,现在已经移交 TrustedFirmware 社区维护。MbedTLS 开源仓库地址为:
MbedTLS 代码由 C 语言写成,其以最小的编码占用空间实现了 SSL/TLS 功能及各种加密算法,易于理解、使用、集成和扩展,方便开发人员轻松地在嵌入式产品中使用 SSL/TLS 功能。
MbedTLS 软件包主要提供了如下支持:
1. 完整的 SSL v3、TLS v1.0、TLS v1.1 和 TLS v1.2 协议实现
2. X.509 证书处理
3. 基于 TCP 的 TLS 传输加密
4. 基于 UDP 的 DTLS(Datagram TLS)传输加密
5. 其它加解密库实现
二、i.MXRT上的硬件加速器简介
2.1 i.MXRT10xx系列上的DCP
DCP 是 Data Co-Processor 的简称,从名字上看是个通用数据协处理器。在 i.MXRT1060 Security Reference Manual 中有一张系统整体安全架构简图,这个简图中标出了 DCP 模块的主要功能:CRC-32算法、AES算法、Hash算法、类DMA数据搬移。关于进一步用法,见痞子衡两篇旧文 《i.MXRT10xx DCP使用时密钥注意事项》、《i.MXRT10xx DCP使用时Cache注意事项》 。

2.2 i.MXRT11xx系列上的CAAM
**CAAM 是 Cryptographic Acceleration and Assurance Module 的简称,是个超全功能的安全算法加速器。**在 i.MXRT1170 Security Reference Manual 中有一张系统整体安全架构简图,这个简图中标出了 CAAM 模块的主要功能,其在 DCP 已有功能上做了进一步扩展,丰富了算法支持。

三、对比常见算法的软硬件实现性能差异
3.1 官方SDK例程简介
想要在 MCU 上跑 MbedTLS 算法,正常是需要先移植 MbedTLS 源码的。但是恩智浦 i.MXRT 官方 SDK 包里已经做好了移植,源码就放在 \SDK_2.11.0_MIMXRT1xxx-EVK\middleware\mbedtls 下面,所以我们省去了移植步骤。注:在 SDK 2.11 版本里移植的是 MbedTLS 2.27.0。
此外官方 SDK 里还提供给了如下两个关于 MbedTLS 的基础例程,其中 mbedtls_selftest 是遍历全部算法,检测算法执行正确性;mbedtls_benchmark 则是提供全部算法的实际运行性能数据(编解码速率 KB/s)。
\SDK_2.11.0_MIMXRT1xxx-EVK\boards\evkmimxrt1xxx\mbedtls_examples\mbedtls_selftest
\SDK_2.11.0_MIMXRT1xxx-EVK\boards\evkmimxrt1xxx\mbedtls_examples\mbedtls_benchmark
3.2 在i.MXRT1060上实测
我们现在在 MIMXRT1060-EVK 板子上实测算法性能,就用 mbedtls_benchmark 例程,选择 debug build,即让代码跑在 TCM 里,这样可以达到最好性能,不让存储器性能成瓶颈从而影响算法性能数据。此外 i.MXRT1060 内核频率也是配到了最高 600MHz。
mbedtls_benchmark 例程默认是启用硬件加速器 DCP 来实现算法的,因为我们要对比 MbedTLS 纯软件实现和 DCP 硬件实现性能差异,所以在测试纯软件方式时需要在工程源文件 MIMXRT1062_features.h 里将下面这个宏临时设为 0,这时候工程可能会编译不通过(代码链在 128KB ITCM 里),因为纯软件方式代码相比硬件驱动方式代码要大得多,此时可以在 benchmark.c 或者 ksdk_mbedtls_config.h 注释掉一些算法执行来减少最终代码体(保留你感兴趣的算法)。
/* @brief DCP availability on the SoC. */
#define FSL_FEATURE_SOC_DCP_COUNT (0)
算法性能数据跟 IDE 以及编译优化选项也有关系,我们这里选择了 IAR,优化选项分别测试了 None 以及 High Speed,No Size constraints 两种,因为算法特别多,我们就摘比较常用的 SHA 和 AES。
3.3 在i.MXRT1170上实测
与上一节同样的方法,在 MIMXRT1170-EVK 板子上也测一下,同样 mbedtls_benchmark 例程 debug build,注意 i.MXRT1170 是双核芯片,我们在 Cortex-M7 下做测试,将内核频率配到最高 996MHz。
测试 i.MXRT1170 上纯软件方式时仅需要在工程选项预编译宏里将 CRYPTO_USE_DRIVER_CAAM 去掉即可,当然也可以在 MIMXRT1176_cm7_features.h 里将下面这个宏临时设为 0,这时候没有代码空间顾虑,i.MXRT1170 上默认 ITCM 是 256KB。
/* @brief CAAM availability on the SoC. */
#define FSL_FEATURE_SOC_CAAM_COUNT (0)
3.4 性能测试总结
- 结论1:使用硬件加速器CAAM模块/DCP模块,相比 MbedTLS 纯软件实现,对于大部分算法性能都会有提升,但具体提升比例因算法本身复杂度而异。
- 结论2:硬件加速器方式提升比例较大的是 3DES/DES(近10倍)、AES/ECDSA/ECDHE(近7倍)、RSA(3-5倍)、SHA-1/256(近2倍)。
- 结论3:硬件加速器方式对于部分算法,测试数据长度越大(默认1KB buffer,比如调到10KB),性能提升更明显。
- 结论4:编译器优化等级设置对 MbedTLS 纯软件和硬件加速器方式都有一定影响。
- 结论5:CAAM模块比DCP模块在算法支持度上要高很多,但编解码速度性能上并没有显著提升。
以上又跟着痞子叔学习到了蛮多的。