参考[可以移步第一个参考,原创,这里只做了记录]
Inception结构详解(从V1到V4,再到xcpetion)
综述
发展
Inception v1(GoogLeNet, 2014) —> Inception v2(BN-Inception, 2015) —> Inception v3(2015) —> Inception v4(Inception-ResNet, 2016) —> Xception(2016)
对应的论文及其时间
GoogLeNet v1:《Going deeper with convolutions》, 2014.09
Inception v2:《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》, 2015.02
Inception v3:《Rethinking the Inception Architecture for Computer Vision》, 2015.12
Inception v4:《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》, 2016.02
Xception:《Xception: Deep Learning with Depthwise Separable Convolutions》, 2016.10
结构细节
Inception v1
概述
问题:网络性能提升依靠深度和宽度(隐层和各层神经元数目),但会导致参数量增多,导致过拟合/梯度消失。
解决:全连接改稀疏连接,比如卷积结构。Inception找最优卷积稀疏结构。
细节
Inception作用
增加每一步的单元数目,并且能提供多尺度特征。
Inception替代了人工确定卷积层中过滤器的类型或者是否创建卷积层和池化层,让网络自己学习它具体需要什么参数。
1*1卷积的作用
降低维度,减少计算瓶颈
增加网络层数,提高网络的表达能力

Inception v2
概述
引入BN以及改进结构
BN层解决输入相同,但同一网络层输出不同的问题(因为网络每一次更新的参数会变化)。
作用(激活函数的兴奋区梯度大,即加速网络训练,还防止了梯度消失):
加速网络训练
防止梯度消失
改进结构:把Inception-v1中5*5的卷积用2个3*3的卷积替换,这也是VGG那篇论文所提到的思想。这样做法有两个优点:
保持相同感受野的同时减少参数
加强非线性的表达能力
Inception V3
概述
提出神经网络的结构设计和优化思路以及改进结构。
设计准则
避免网络表达瓶颈,尤其在网络的前端。feature map急剧减小,这样对层的压缩过大,会损失大量信息,模型训练困难。
高维特征的局部处理更困难。
在较低维度空间聚合,不会损失表达能力。
平衡网络的宽度和深度。
改进结构
1.分解卷积核尺寸
分解为对称的小的卷积核(5*5改两个3*3)
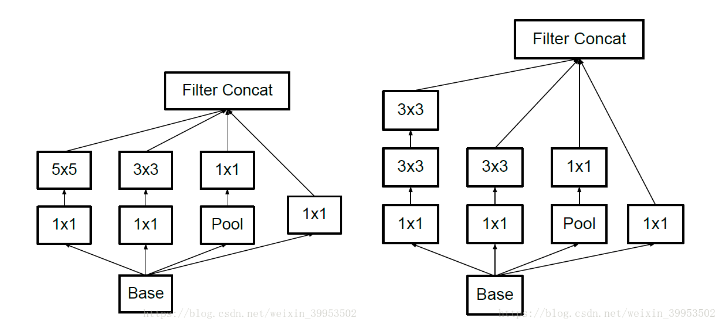
分解为不对称的卷积核(n*n的卷积核替换成 1*n 和 n*1,在12-20维度表现好,大维度表现不好。)

不对称优点
节约了大量的参数
增加一层非线性,提高模型的表达能力
可以处理更丰富的空间特征,增加特征的多样性
2.使用辅助分类器
GoogLeNet(Inception)中使用了辅助分类器2个,优势:
把梯度有效的传递回去,不会有梯度消失问题,加快了训练
中间层的特征也有意义,空间位置特征比较丰富,有利于提成模型的判别力
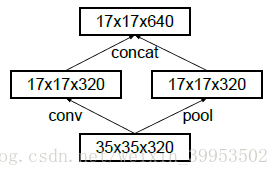
改变降低特征图尺寸的方式
传统的卷积神经网络的做法,当有pooling时(pooling层会大量的损失信息),会在之前增加特征图的厚度(就是双倍增加滤波器的个数)。下图是本论文提出观点。
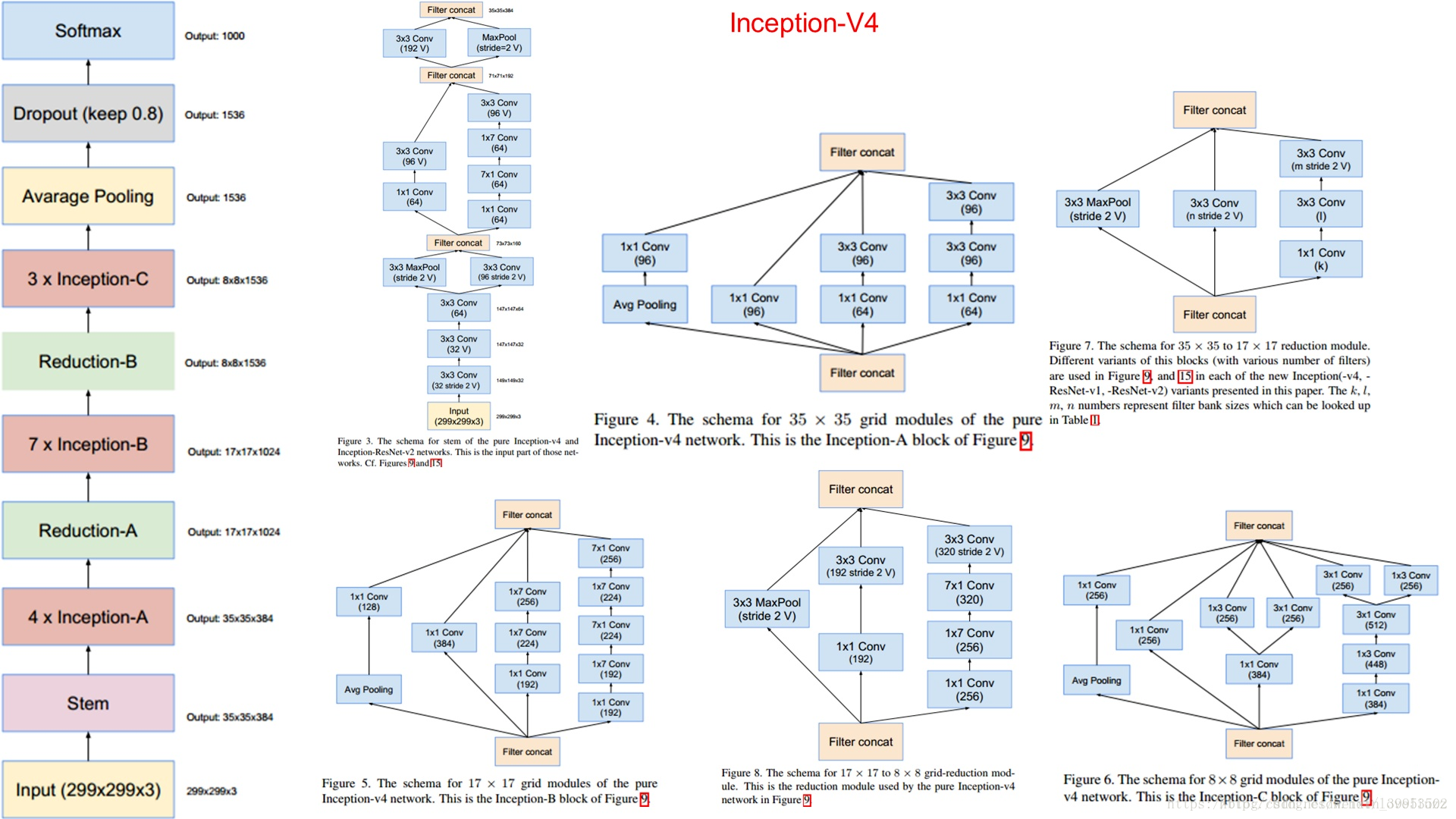
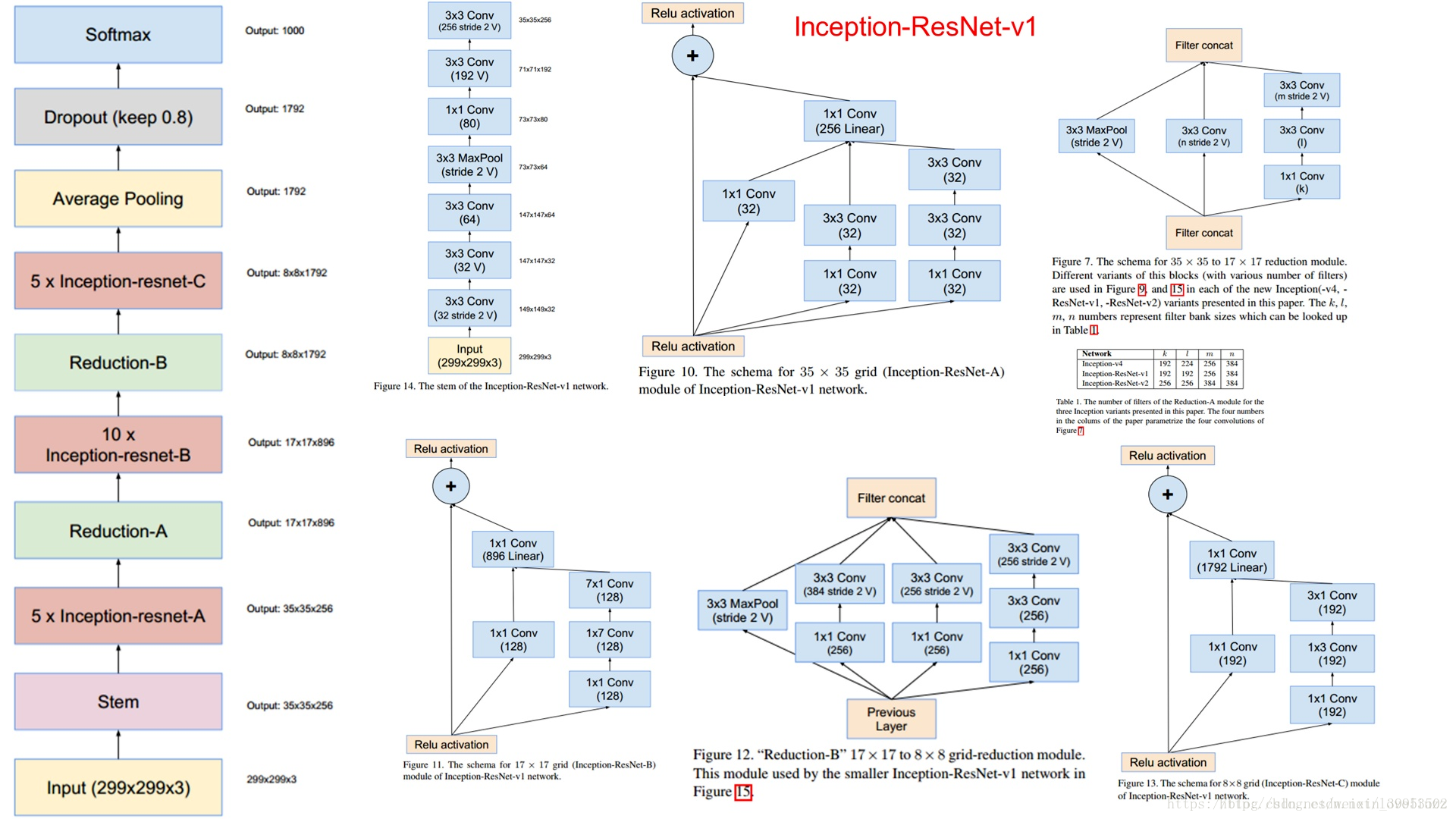
Inception V4
概述
残差网络并不是加深网络层的必须,因为有好的初始化和BN
Residual Inception Block
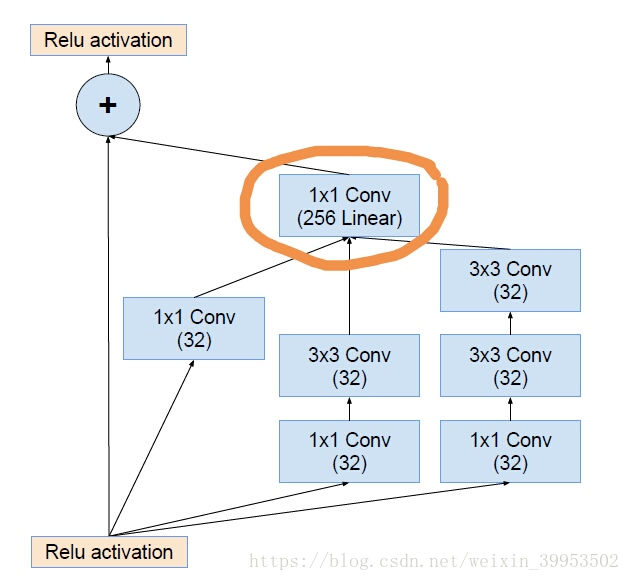
Scaling of the Residual
当过滤器的数目超过1000个的时候,会出现问题,网络会“坏死”,即在average pooling层前都变成0。即使降低学习率,增加BN层都没有用。这时候就在激活前缩小残差可以保持稳定。即下图
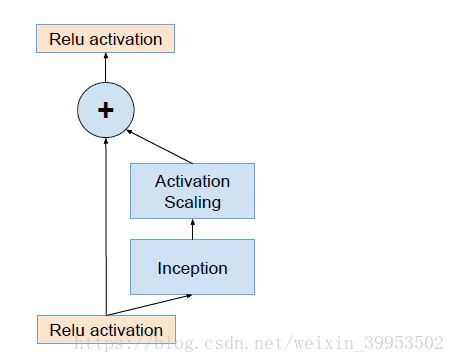
网络精度提高原因
残差连接只能加速网络收敛,真正提高网络精度的还是“更大的网络规模”。