MAE-DET学习笔记
MAE-DET: Revisiting Maximum Entropy Principle in Zero-Shot NAS for Efficient Object Detection
Abstract
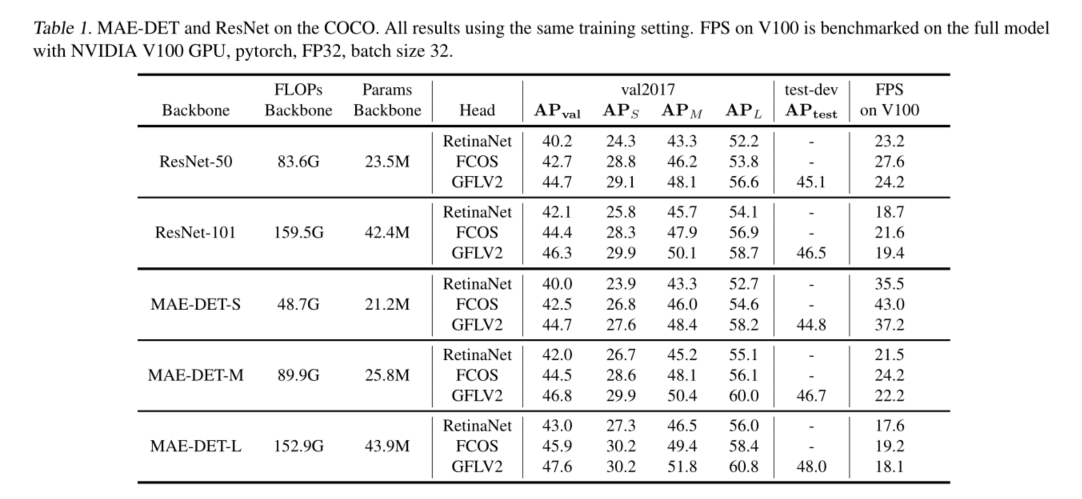
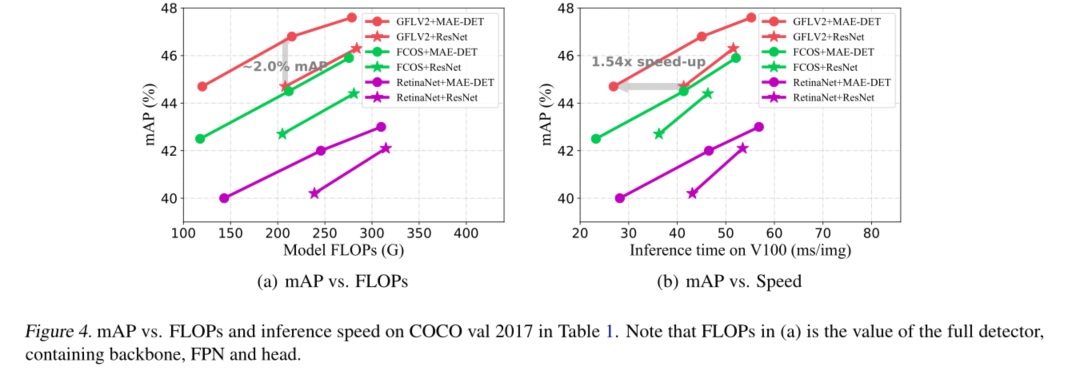
在对象检测中,检测主干消耗了整个推理成本的一半以上。最近的研究试图通过借助神经架构搜索(NAS)优化主干架构来降低这一成本。然而,现有的用于对象检测的NAS方法需要数百到数千GPU小时的搜索,这使得它们在快节奏的研究和开发中不切实际。在这项工作中,我们提出了一种新的zero-shotNAS方法来解决这个问题。所提出的方法名为MAE-DET,通过最大熵原理自动设计有效的检测主干,而无需训练网络参数,将架构设计成本降低到几乎零,同时提供最先进的(SOTA)性能。在这种情况下,MAEDET最大化了检测主干的差分熵,从而在相同的计算预算下为目标检测提供了更好的特征提取器。仅经过一天GPU的全自动设计后,MAE-DET在多个检测基准数据集上创新了SOTA检测主干,几乎不需要人工干预。与ResNet-50主干相比,MAE-DET在使用相同数量的FLOP/参数时,mAP性能提高+2.0%,在相同mAP下,在NVIDIA V100上速度提高1.54倍。代码和预训练模型可在https://github.com/alibaba/lightweight-neuralarchitecture-search.
Introduction
在计算机视觉中,寻找更好更快的物体检测深度模型从来都不是过时的任务。深度对象检测网络的性能在很大程度上取决于特征提取主干(Li等人,2018;Chen等人,2019b)。目前,大多数最先进的(SOTA)检测主干(He等人,2016年;谢等人,2017年;朱等人,2019年;李等人,2021a)都是由人类专家手动设计的,这可能需要数年的时间来开发。由于检测主干在许多检测框架中消耗了总推理成本的一半以上,因此优化主干架构以在不同硬件平台(从服务器端GPU到移动端芯片组)上实现更好的速度精度权衡至关重要。为了减少时间成本和人力,出现了神经架构搜索(NAS)来促进架构设计。多种NAS方法在设计SOTA图像分类模型方面已证明其有效性(Zoph等人,2018;Liu等人,2018年;Cai等人,2019年;Tan&Le,2019;Fang等人,2020年)。这些成功的故事激励了最近的研究人员使用NAS以端到端的方式设计检测主干(Chen等人,2019b;Peng等人,2019;Xiong等人,2021;Du等人,2020;Jiang等人,2020)。
迄今为止,用于检测任务的现有NAS方法都是基于训练的,这意味着它们需要训练网络参数以评估目标数据集上网络候选的性能,这一过程消耗了大量的硬件资源。这使得基于培训的NAS方法在现代快节奏的研发中效率低下。为了降低搜索成本,最近提出了无训练方法,在一些文献中也称为zero-shot NAS(Tanaka等人,2020;Mellor等人,2021;Chen等人,2021c;Lin等人,2021)。zero-shot NAS无需训练网络参数即可预测网络性能,因此比基于训练的NAS快得多。作为一种相对较新的技术,现有的zero-shot NAS方法大多在分类任务上得到验证。将zero-shot NAS应用于检测任务仍然是一个完整的挑战。
在这项工作中,我们首次尝试引入zero-shot NAS技术来设计高效的对象检测主干。我们表明,直接将现有的zero-shot NAS方法从图像分类转移到检测主干设计将遇到根本困难。虽然图像分类网络只需要预测类别概率,但对象检测网络需要额外预测多个对象的边界框直接架构传输次优。为此,提出了一种新的zero-shot NAS方法,称为MAximum-Entropy DETection (MAE-DET),用于搜索目标检测主干。MAE-DET背后的关键思想受到最大熵原理的启发(Jaynes,1957;Reza,1994;Kullback,1997;Brillouin,2013)。非正式地说,当检测网络被制定为信息处理系统时,当其熵在给定的推理预算下达到最大值时,其容量被最大化,从而导致用于对象检测的更好的特征提取器。基于这一观察,MAE-DET通过搜索网络深度和宽度的最佳配置而无需训练网络参数,最大化检测主干的差分熵(Shannon,1948)。
最大熵原理是物理学和信息论的基本原理之一。除了深度学习的广泛应用之外,许多理论研究试图从最大熵原理来理解深度学习的成功(Saxe等人,2018;Chan等人,2021;Yu等人,2020)。受这些先驱作品的启发,MAE-DET建立了从最大熵原理到zero-shot 目标检测NAS的联系。这导致了一个概念上简单的设计,但具有强大的经验性能。仅使用标准的单分支卷积块,MAE-DET就可以胜过以前由更复杂的工程构建的检测主干。这一令人鼓舞的结果再次验证了一个古老的学说:简单更好。
虽然最大熵原理已被应用于各种科学问题,但它在zero-shot NAS中的应用是新的。特别是,将该原理直接应用于物体检测将带来若干技术挑战。第一个挑战是如何估计深度网络的熵。熵的精确计算需要知道高维空间中深层特征的精确概率分布,这在实践中很难估计。为了解决这个问题,MAE-DET估计差分熵的高斯上界,这只需要估计特征图的方差。第二个挑战是如何有效地提取不同尺度对象的深度特征。在真实世界的物体检测数据集中,如MS COCO(Lin等人,2014),物体大小的分布依赖于数据且不均匀。为了在主干设计中引入这种先验知识,我们在熵估计中引入了多尺度熵先验(MSEP)。我们发现MSEP显著提高了检测性能。MAE-DET的总体计算需要检测主干的一个正向推断,因此与以前基于训练的NAS方法相比,其成本几乎为零。
这项工作的贡献总结如下:
•我们重新讨论了zero-shot 目标检测NAS中的最大熵原理。提出的MAE-DET概念简单,但无需华丽的点缀就可提供卓越的性能。
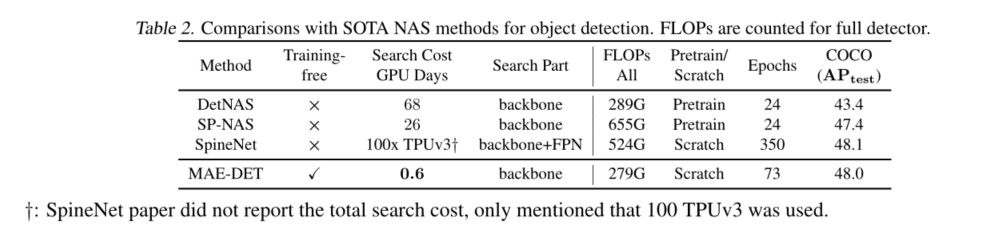
•MAEDET使用不到一天的GPU和2GB内存,在COCO上实现了比以前的NAS方法具有竞争力的性能,速度至少快50倍。
•MAE-DET是第一种在多个检测框架下的多个基准数据集上具有SOTA性能的zero-shot NAS对象检测方法。
Related work
Backbone Design for Object Detection
最近,由 backbone,neck and head 组成的物体检测模型的设计因其有效性和高性能而日益流行(Lin等人,2017a;b;Tian等人,2019;Li等人,2020;2021b;Tan等人,2020年;Jiang等人,2022)。流行的检测器直接使用为图像分类设计的主干来从输入图像中提取多尺度特征,例如ResNet(He等人,2016)、ResNeXt(Xie等人,2017)和可变形卷积网络(DCN)(Zhu等人,2019)。尽管如此,从图像分类迁移的主干在对象检测中可能是次优的(Ghiasi等人,2019)。为了解决这一问题,提出了几种针对对象检测进行优化的架构,包括Stacked Hourglass(Newell等人,2016)、FishNet(Sun等人,2018)、DetNet(Li等人,2018年)、HRNet(Wang等人,2020a)等。尽管性能良好,但这些手工构建的架构严重依赖于专家知识和繁琐的试错设计。
Neural Architecture Search
神经架构搜索(NAS)最初是为了自动设计图像分类的网络架构而开发的(Zoph等人,2018年;Liu等人,2018;Real等人,2019;Cai等人,201九;Chu等人,2021;Lin等人,2020年;Tan&Le,2019年;Chen等人,2021a;Lin等,2021)。使用NAS设计对象检测模型还没有得到很好的探索。目前,现有的检测NAS方法都是基于训练的方法。一些方法侧重于搜索检测主干,如DetNAS(Chen等人,2019b)、SpineNet(Du等人,2020)和SP-NAS(Jiang等人,2020),而其他方法侧重于查找FPN颈部,如NAS-FPN(Ghiasi等人,2019)、NASFCOS(Wang等人,2020b)和OPANet(Liang等人等人,2021)。这些方法需要对目标数据集进行训练和评估,这需要大量的计算。MAE-DET是第一种用于目标检测主干设计的零炮NAS方法。
Preliminary
在本节中,我们首先将深度网络表述为具有连续状态空间的系统。然后我们定义了这个系统的微分熵,并展示了如何估计该熵通过其高斯上界。最后,我们介绍了香草网络搜索空间的基本概念,以设计我们的检测主干。
Continuous State Space of Deep Networks
深度网络 F ( ⋅ ) : R d → R F(·):R^d → R F(⋅):Rd→R将输入图像 x ∈ R d x∈R^d x∈Rd映射到其标签 y ∈ R y∈R y∈R。网络的拓扑可以抽象为图 G = ( V , E ) \mathcal{G}=(\mathcal{V}, \mathcal{E}) G=(V,E),其中顶点集 V \mathcal{V} V由神经元组成,边缘集 E \mathcal{E} E由神经元之间的尖峰组成。对于任何 v ∈ V v∈\mathcal{V} v∈V和 e ∈ E e∈\mathcal{E} e∈E, h ( v ) ∈ R h(v)∈R h(v)∈R和 h ( e ) ∈ R h(e)∈R h(e)∈R分别表示赋予每个顶点v和每个边e的值。集合 S = h ( v ), h ( e ): ∀ v ∈ V , e ∈ E S={h(v),h(e):∀v∈\mathcal{V},e∈\mathcal{E}} S=h(v),h(e):∀v∈V,e∈E定义了网络F的连续状态空间。
根据最大熵原理,我们希望在给定的计算预算下最大化网络F的差分熵。集合S的熵H(S)测量系统(网络)F中包含的总信息,包括潜在特征 H ( S v )= h ( v ) : v ∈ V H(S_v)={h(v):v∈\mathcal{V}} H(Sv)=h(v):v∈V和网络参数 H ( S e )= h ( e ): e ∈ E H(S_e)={h(e):e∈ \mathcal{E}} H(Se)=h(e):e∈E中包含的信息。对于目标检测主干设计,我们只关心潜在特征 H ( S v ) H(S_v) H(Sv)的熵,而不关心网络参数 H ( S e ) H(S_e) H(Se)的熵值。非正式地说, H ( S v ) H(S_v) H(Sv)度量F的特征表示能力,而 H ( S e ) H(S_e) H(Se)度量F的模型复杂性。因此,在本工作的剩余部分中,F的差分熵默认指熵 H ( S v ) H(S_v) H(Sv)。
Entropy of Gaussian Distribution
高斯分布的微分熵可以在许多教科书中找到,例如(Norwich,1993)。假设x从高斯分布 N (µ, σ 2 ) N(µ,σ^2) N(µ,σ2)采样。那么x的微分熵由下式给出
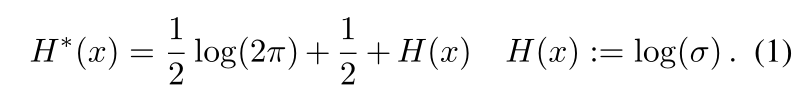
从等式1中,高斯分布的熵仅取决于方差。在下文中,我们使用H(x)代替H*(x),因为常数在我们的讨论中无关紧要。
Gaussian Entropy Upper Bound
由于概率分布 P ( S v ) P(S_v) P(Sv)是一个高维函数,因此很难直接计算其熵的精确值。相反,我们建议估计熵的上限,由以下众所周知的定理给出(Cover&Thomas,2012):
Theorem 1.对于平均值µ和方差 σ 2 σ^2 σ2的任何连续分布 P ( x ) P(x) P(x),当 P ( x ) P(x) P(x)为高斯分布 N ( µ, σ 2 ) N(µ,σ^2) N(µ,σ2)时,其微分熵最大化。
定理1说,一个分布的微分熵是由具有相同均值和方差的高斯分布上界的。将此与方程(1)相结合,我们可以通过简单地计算特征图方差,然后使用方程(2)获得网络的高斯熵上界,从而容易地估计网络熵 H ( S v ) H(S_v) H(Sv)。
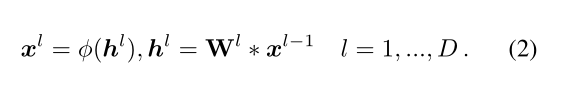
Vanilla Network Search Space
根据之前的工作,我们在香草卷积网络空间中设计了骨干网(Li等人,2018;Chen等人,2019b;Du等人,2020;Lin等人,2021)。该空间是深度学习早期提出的最简单的空间之一,现在被广泛用于检测主干。它也是许多理论研究中的流行原型(Poole等人,2016;Serra等人,2018;Hanin& Rolnick,2019)。
香草网络由多个卷积层堆叠而成,随后是RELU激活。考虑具有D层权重 W 1 、 … 、 … W D W^1、…、… W^D W1、…、…WD的香草卷积网络,输出图像是 x 1 、 … 、 … x D x^1、…、… x^D x1、…、…xD 输入图像为 x 0 x^0 x0。设φ(·)表示RELU激活函数。然后,正向推断由(2)式给出
为了简单起见,我们将卷积层的偏差设置为零。
Simple is Better
香草卷积网络的实现非常简单。大多数深度学习框架(Paszke等人,2019;Abadi等人,2015)在GPU上提供了优化良好的卷积算子。卷积网络的训练得到了很好的研究,例如添加残差链路(He等人,2016)和批量归一化(BN)(Ioffe&Szegdy,2015)将大大提高收敛速度和稳定性。虽然我们有意坚持简单的香草设计,但MAEDET中使用的构建块可以与其他辅助组件相结合,以“现代化”主干以提高性能,例如挤压和激励(SE)块(Hu等人,2018)或自我关注块(Zhao等人,2020)。由于MAE-DET的简单性,这些辅助组件可以很容易地插入主干,而无需特别修改。再次,我们故意避免使用这些辅助组件,以保持我们的设计简单和通用。默认情况下,我们只使用残余链路和BN层来加速收敛。这样,很明显,MAE-DET的改进确实来自于更好的主干设计。
Maximum Entropy Zero-Shot NAS for Object Detection
在本节中,我们首先描述如何计算深度网络的差分熵。然后,我们引入多尺度熵先验(MSEP)来更好地捕捉真实世界图像中对象大小的先验分布。最后,我们提出了通过定制进化算法(EA)设计的完整MAE-DET主干。
4.1. Differential Entropy for Deep Networks
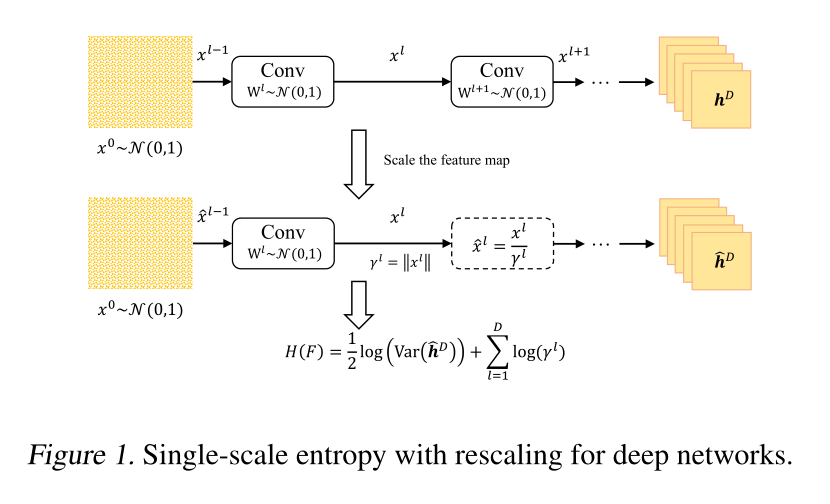
在本小节中,我们介绍了由深度网络生成的最终特征图的差分熵计算。首先,所有参数由标准高斯分布N(0,1)初始化。然后,我们随机生成一幅充满标准高斯噪声的图像,并执行前向推理。基于第3节中的讨论,网络F的(高斯上界)熵H(F)由下式给出
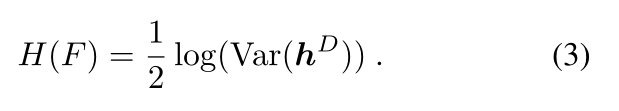
请注意,方差是在最后一个预激活特征图 h D h^D hD上计算的
对于深度香草网络,直接使用方程(3)可能会导致数值溢出。这是因为每一层都以一个大的因子放大输出范数。Zen-NAS也报告了同样的问题(Lin等人,2021)。受Zen NAS中提出的BN重新缩放技术的启发,我们提出了一种没有BN层的替代解决方案。在推断过程中,我们通过一些常数 γ l γ^l γl直接重新缩放每个特征图 x l x^l xl,即 x l = φ ( h l ) / γ l x^l=φ(h^l)/γ^l xl=φ(hl)/γl,然后通过以下方式补偿网络的熵
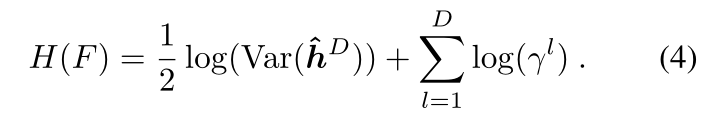
γ l γ^l γl的值可以任意给定,只要正向推理不上溢或下溢。在实践中,我们发现简单地将 γ l γ^l γl设置为特征图的欧几里德范数效果很好。该过程如图1所示。最后,H(F)乘以特征图的大小作为该特征图的熵估计。
Compare with Zen-NAS
MAEDET和Zen NAS背后的原则根本不同。Zen NAS使用输入图像的梯度范数作为排名得分,并提出使用两个前馈推断来近似用于分类的梯度范数。相比之下,MAEDET使用基于熵的分数,这只需要一个前馈推理。有关更多实证比较,请参见实验部分。
4.2. Multi-Scale Entropy Prior (MSEP) for Object Detection
在真实世界的图像中,对象大小的分布并不均匀。为了引入这种先验知识,检测主干有5个阶段,其中每个阶段将特征分辨率降采样到一半。MSEP从每个阶段的最后一层收集特征图,并将相应的特征图熵加权和作为新的测量。我们将这种新的度量命名为多尺度熵。该过程如图2所示。在该图中,主干提取不同分辨率的多尺度特征C=(C1,C2,…,C5)。然后,FPN颈部熔断器C作为检测头的输入特征P=(P1,P2,…,P7)。然后,主干F的多尺度熵Z(F)由下式定义:
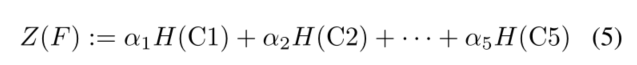
其中H(Ci)是i=1,2,··,5时Ci的熵。权重α=(α1,α2,··,α5)在平衡不同尺度特征的表现力之前存储多尺度熵。

How to choose α
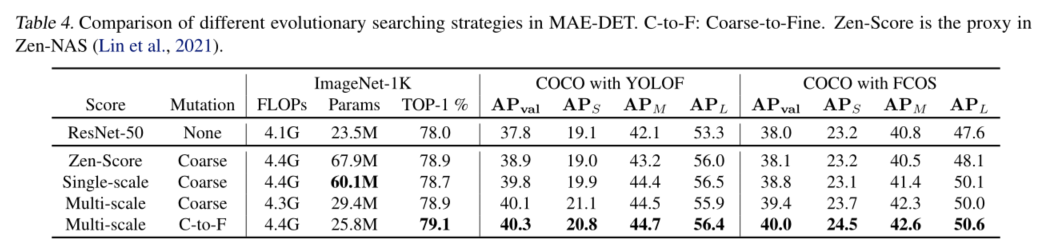
作为图2中的具体示例,P3和P4的部分由P5的上采样生成,P6和P7由P5(由C5生成)的下采样直接生成。同时,基于C5携带足够的上下文来检测各种尺度上的对象这一事实(Chen等人,2021b),C5在主干搜索中很重要,因此最好为权重α5设置更大的值。然后,在附录D中探索了α和相关分析的不同组合,表明**α=(0,0,1,1,6)**对于FPN结构足够好。
4.3. Evolutionary Algorithm for MAE-DET
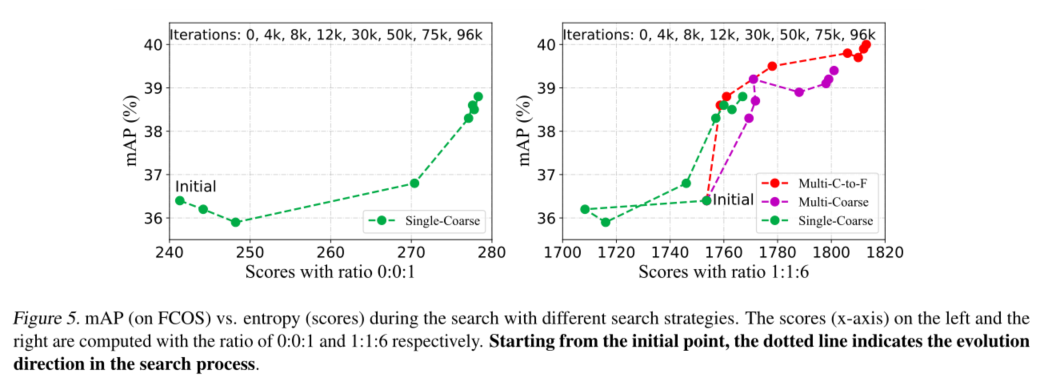
结合以上所有内容,我们在算法1中提出了MAE-DET的NAS算法。MAE-DET使用定制进化算法(EA)。为了提高进化效率,提出了一种从粗到细的策略来逐步减少搜索空间。首先,我们随机生成N个种子架构来填充种群P。如图3所示,种子架构Ft由一系列构建块组成,例如ResNet块(He等人,2016)或MobileNet块(Sandler等人,2018)。然后我们随机选择一个区块并用其突变版本替换它。我们在EA的早期阶段使用粗突变,并在T/2 EA迭代后切换到精细突变。在粗突变中,块类型、内核大小、深度和宽度被随机突变。在精细突变中,只有内核大小和宽度发生突变。

在突变之后,如果新结构的推断成本不超过预算(例如,FLOP、参数和延迟),并且其深度小于预算L,则将把Ft附加到群体P中。最大深度L防止算法生成过深的结构,这将具有不合理结构的高熵,性能将更差。在EA迭代期间,通过丢弃最小多尺度熵的最差候选,将总体保持在一定大小。在进化结束时,返回具有最高多尺度熵的主干。
5. Experiments
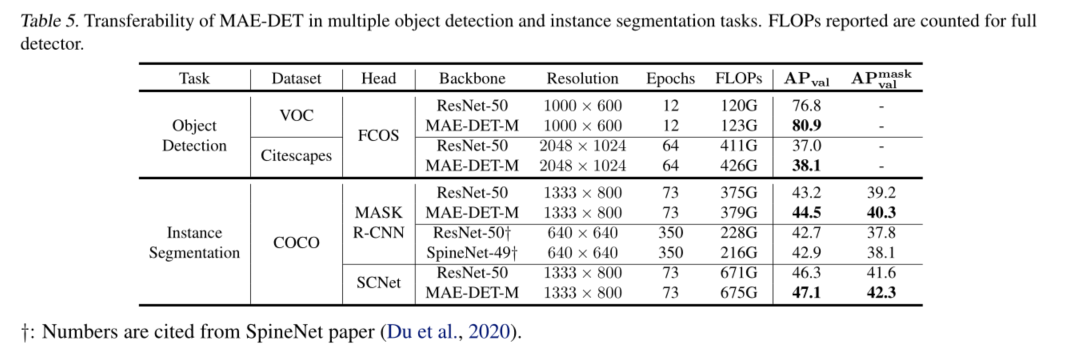
6.Conclusion
在本文中,我们重新讨论了用于目标检测的zero-shot NAS中的最大熵原理。所提出的MAEDET以比先前基于训练的NAS方法快几个数量级的搜索速度实现了具有竞争力的检测精度。虽然现代对象检测主干涉及更复杂的构建块和网络拓扑,但MAE-DET的设计在概念上简单且易于实现,展示了“简单就是更好”的理念。在各种数据集上的大量实验和分析验证了其优异的可移植性。