gStore: Answering SPARQL Queries via Subgraph Matching
论文翻译,仅作为个人保存用
ABSTRACT
由于对RDF数据的使用越来越多,对RDF数据集上的SPARQL查询的高效处理已经成为一个重要的问题。然而,现有的解决方案有两个限制:
1)它们不能以可伸缩的方式用通配符回答SPARQL查询;
2)它们不能有效地处理RDF存储库中的频繁更新。
因此,它们中的大多数必须从头开始重新处理数据集。在本文中,我们提出了一种基于图的方法来存储和查询RDF数据。我们不像大多数现有的方法那样将RDF三元组映射到关系数据库中,而是将RDF数据存储为一个大图。然后将一个SPARQL查询转换为一个相应的子图匹配查询。为了加快查询处理速度,我们开发了一种新的索引,以及一些有效的剪枝规则和有效的搜索算法。我们的方法可以用统一的方式回答精确的SPARQL查询和使用通配符的查询。我们还提出了一种有效的维护算法来处理RDF存储库上的在线更新。大量的实验证实了我们的解决方案的效率和有效性。
1. INTRODUCTION
作为开发的一部分,提出了RDF(资源描述框架)数据模型,用于Web对象的建模。它已被用于各种应用程序中。例如,Yago和DBPedia自动从维基百科中提取事实,并以RDF格式存储,以支持维基百科[19,3]上的结构性查询。生物学家还建立了RDF数据集合,如Bio2RDF(bio2rdf.org)和Uniprot RDF(dev.isb-sib.ch/项目/Uniprot-rdf),用于记录实验数据。
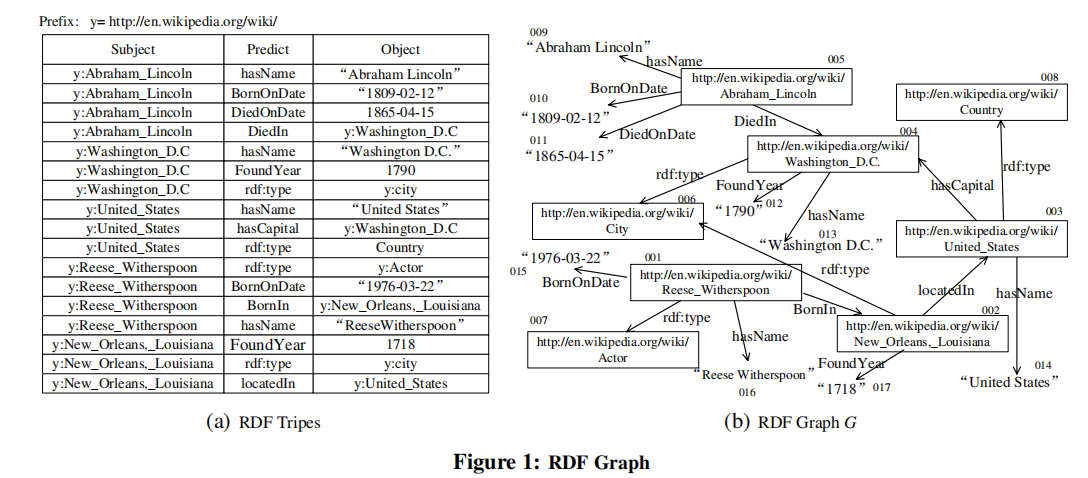
一般来说,RDF数据可以表示为SPO(主题、属性、对象)。图1(a).中给出了一个正在运行的示例请注意,一个RDF数据集也可以被建模为一个图(称为RDF图),如图1(b).所示为了查询RDF存储库,W3C提出了SPARQL查询语言[16]。例如,我们可以通过以下SPARQL查询从RDF数据集中检索出生于1809年2月12日并于1865年4月15日死亡的个人的名字:
Q1: Select ?name Where { ?m <hasName> ?name. ?m <BornOn Date >
“1809-02-12”. ?m <DiedOnDate> “1865-04-15”. }
尽管在过去的十年中已经对RDF数据管理进行了研究,但大多数现有的解决方案都不能扩展到大型RDF存储库,也不能有效地回答复杂的查询。最近的研究主要集中在大型RDF存储库(如[2,12,13,25,22])的可伸缩技术上。尽管这些现有的RDF查询引擎,如RDF-3x [12]、六进制[22]和SPARQL存储[1],旨在解决SPARQL查询的可伸缩性,但它们有一些共同的限制:

(1)它们不能以可伸缩的方式支持带有通配符的SPARQL;
(2)一些现有系统很难处理RDF存储库中的频繁更新,迫使它们在出现更新时从头重新处理数据集。x-RDF-3x [15]是RDF-3x系统的高级版本,它可以支持更新,但它仍然不支持通配符查询。
1.1带有通配符的SPARQL查询
在实际应用中,拥有对查询对象的全面了解可能不实用;因此,也许不可能指定精确的查询条件。例如,我们可能知道一位重要的政治家出生于2月12日,死于4月15日,但我们不知道他的确切出生和死亡年份。在这种情况下,我们必须使用通配符执行一个查询,如下图所示:
Q2:Select ?name Where { ?m <hasName> ?name. ?m <BornOnDate> ?bd.
?m <DiedOnDate> ?dd. FILTER regex(str(?bd), “02-12”), regex(str(?dd),
“04-15”) }
尽管有一些技术可以支持使用通配符的SPARQL查询和管理大型RDF数据集,但据我们所知,没有任何技术可以支持这两种功能,即,能够以可伸缩的方式使用通配符执行SPARQL查询。现有的RDF存储系统,如Jena [23]、Yars2 [11]和Sesame 2.0 [5],不能在大型RDF数据集(如Yago数据集)中正常工作。SW-store[1]、RDF-3x [12]、x-RDF-3x [15]和六核[22]是设计用来解决可伸缩性的,但是,它们只能支持精确的SPARQL查询,因为它们使用映射字典用id替换所有文字(在RDF三元组中)。
1.2在RDF存储库上的频繁更新
在某些应用程序中,RDF存储库并不是静态的。例如,Yago和DBpedia的数据集正在不断扩展,以包括从维基百科中新提取的知识。社交网络中的RDF数据,如FOAF项目(foaf-project.org),也经常被更新,以代表个人不断变化的关系。为了支持对这种动态RDF数据集的查询,查询引擎应该能够处理频繁的更新,而不需要花费太多的维护开销。
1.3我们的方法
在这项工作中,我们从图形数据库的角度来处理RDF数据集。一个SPARQL查询被转换为一个大型RDF图上的子图匹配查询。具体来说,我们可以将一个RDF数据集(一个三元组的集合)建模为一个有标记的、有向的多边图(RDF图),其中每个顶点对应于一个主题或一个对象。每个三重边表示从主题到对应对象的有向边。给定一个主题和一个对象,在它们之间可能存在多个属性,即在两个顶点之间可能存在多条边。因此,RDF图是一个多边图。给定一个SPARQL查询,我们也可以用一个查询图q来表示它。因此,一个SPARQL查询可以被转换为RDF图上的一个子图匹配查询。
例如,图1(b)显示了与图1(a).中的RDF三元组对应的RDF图我们在定义2.1中正式定义了一个RDF图。请注意,图1(b)中方框旁边的数字不是顶点标签,而是我们为简化描述而引入的顶点id。一个SPARQL查询也可以被表示为一个有向标记的图Q(在定义2.2中称为查询图)。图2(a)显示了与SPARQL查询Q2对应的查询图。在这种情况下,回答SPARQL查询Q简化为在RDF图G中找到Q的匹配项。
然而,RDF图的特征与现有图数据库文献中所考虑的典型图有三个方面的不同。
首先,RDF图的大小(即顶点和边的数量)比典型图数据库中所考虑的大小要大一个数量级。
其次,RDF图中的顶点和边标签的基数比传统的图数据库中要大得多。例如,在现有的图形数据库工作[17,24]中使用的一个典型数据集(即艾滋病数据集)有10,000个数据图,每个数据图平均有20个顶点和25条边。不同的顶点标签的总数为62个。数据集的总大小约为5M字节。然而,Yago RDF图有大约500M的顶点,总大小约为3.1GB。因此,I/O成本成为RDF查询处理中的一个关键问题。然而,大多数现有的子图查询算法都是基于内存的。
第三,SPARQL查询结合了几个属性,比如同一实体的属性,因此,它们往往包含星星作为子查询[12]。星形查询是指由一个中心顶点及其相邻顶点组成的星形查询图。
考虑到RDF图的三个特性,我们提出了一种新的索引模式来加快查询处理速度。首先,我们将一个RDF图存储为一个基于磁盘的邻接列表表t。然后,对于RDF图中的每个实体或类顶点(定义2.1),根据其相邻的边标签和相邻的顶点标签(定义2.1),我们分配一个位字符串作为其顶点签名。这样,RDF图就被转换为数据签名图G∗(定义4.3)。然后,我们提出了一个新的索引(称为VS∗-tree)。在运行时,我们还将Q的所有顶点编码为顶点签名,然后将Q转换为相应的查询签名图Q∗。找到Q∗对G∗的所有匹配将导致所有候选匹配(表示为CL)没有任何假阴性。注意,我们提出了一个新的滤波规则(定理5.1)来减少寻找CL的搜索空间。最后,根据CL,我们可以通过检查邻接列表表T的一小部分来修复结果。
我们的方法的优点在于: 1)以统一的方式支持精确的SPARQL查询和使用通配符的查询;2)像其他高度平衡树(如B±tree和R-tree)一样,对我们的索引VS∗-tree有轻微的维护开销。
综上所述,在本工作中,我们做出了以下贡献。
1.我们采用图模型作为RDF数据的物理存储方案。具体来说,我们将RDF数据存储在基于磁盘的邻接列表中。
2.我们通过编码每个实体和类顶点,我们将RDF图转换为数据签名图。在此基础上,提出了一种具有光维护开销的数据签名图的新的索引(VS∗-tree)。
3.我们为数据签名图上的子图查询开发了一个过滤规则,它可以无缝地嵌入到我们的查询算法中,以统一的方式回答精确的SPARQL查询和使用通配符的查询。
4.我们通过实验证明,我们的方法在回答精确的SPARQL查询和通配符查询方面优于现有的方法,我们的解决方案很好地支持在线更新。