b=pd.pivot_table(df,index=['dashboard_title','username'],values='pv',aggfunc=['sum','max'],sort=True)
b.columns=['cishu','zuida']
b.sort_values('cishu',ascending=False).to_excel(pathstart+'toushi4.xlsx')
b.to_excel(pathstart+'toushi5.xlsx')
b.reset_index().sort_values(['dashboard_title','cishu'],ascending=[1,0]).to_excel(pathstart+'toushi6.xlsx')
b.reset_index().sort_values(['dashboard_title','cishu'],ascending=[1,0]).reset_index().to_excel(pathstart+'toushi7.xlsx')
b.reset_index().sort_values(['dashboard_title','cishu'],ascending=[1,0]).set_index(['dashboard_title','username']).to_excel(pathstart+'toushi8.xlsx')- 透视表改名字后方便排序,如上:b.columns=[];
- 透视表仍是Dataframe格式,可以直接sort_values()排序;
- 对索引排序,需要先用reset_index()重置索引为数字索引(0,1,2,3。。。),原有的索引会变成列,直接用sort_values()里边添加索引转换后的列名即可;
- 步骤3操作添加reset_index则可以对排序结果重置数字索引;
- 步骤3操作添加set_index()则会还原为按索引聚合的情形,方便观看(但不方便筛选,因为会聚合后会有空白)。
- 结果展示如下,透视4:

- 透视5:

- 透视6:

- 透视7:
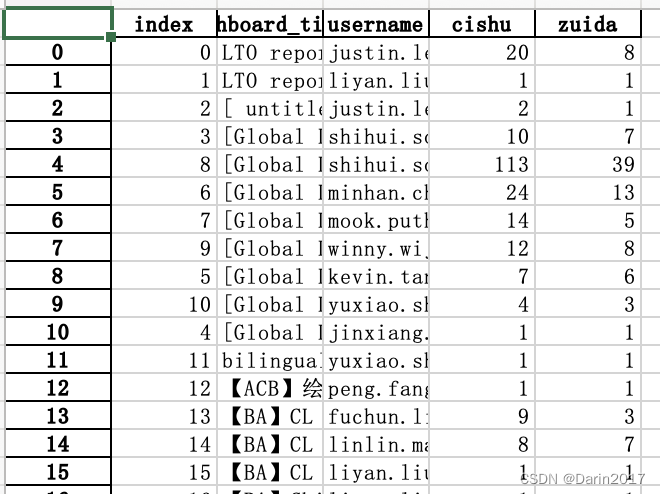
- 透视8:
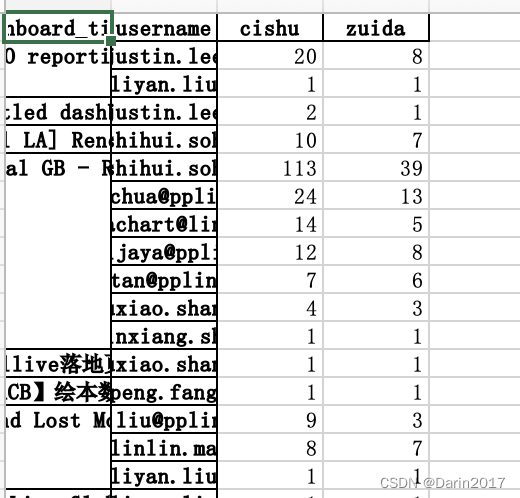
- 对透视表结果的查询,用query()函数:

- 多条件查询用&连接:

- df.query("not (Quantity == 95)") 获取不是95的所有行数据
- 使用Query()函数在日期时间值上进行查询的唯一要求是,包含这些值的列应为数据类型dateTime64 [ns],
df["OrderDate"] = pd.to_datetime(df["OrderDate"], format="%Y-%m-%d")
-
获得八月份的所有记录
df.query("OrderDate.dt.month == 8")
-
可以用in来查询:

- 用str.contains()可以实现like匹配,找到包含特定字符串的全部数据:
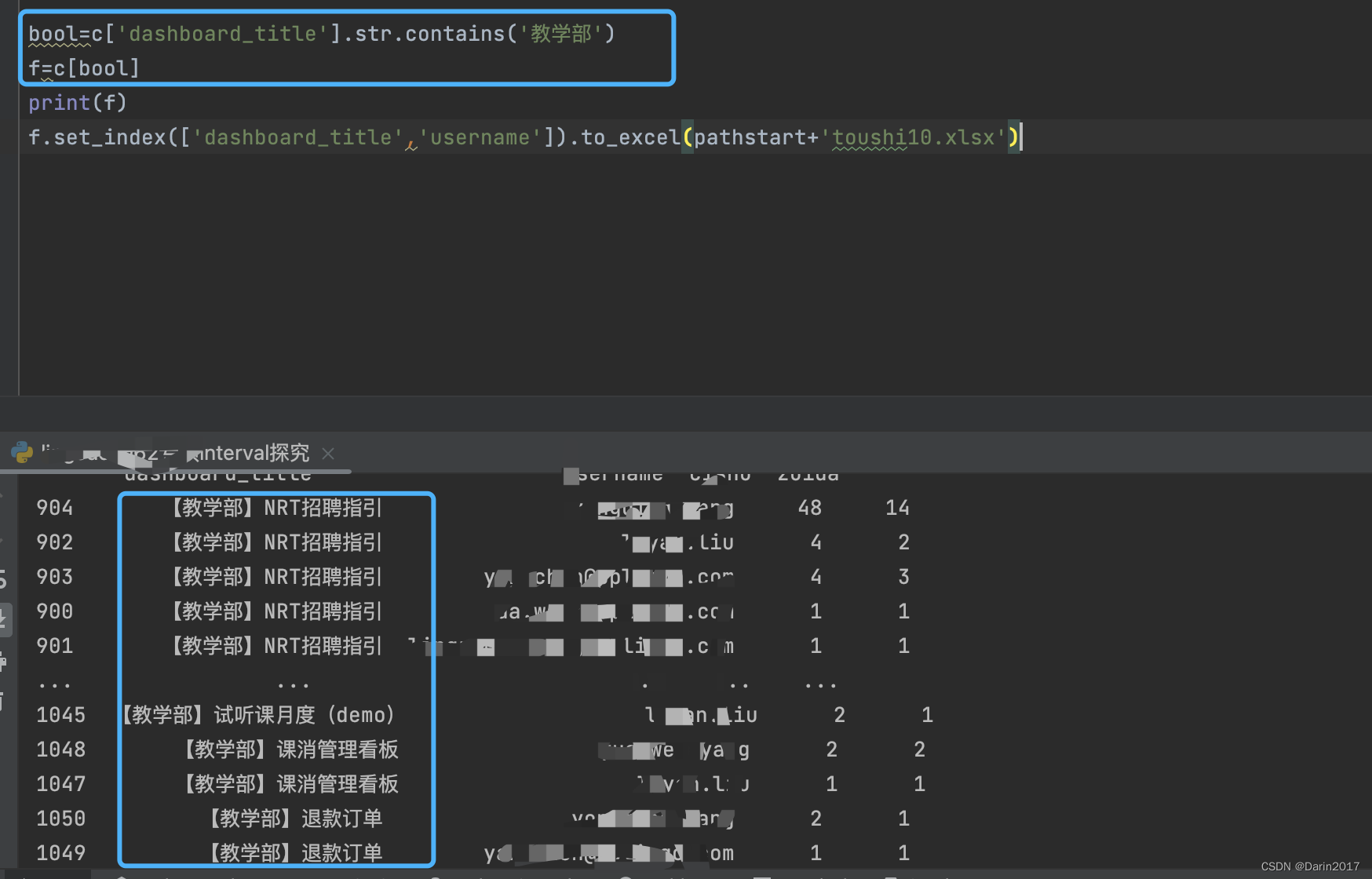
- 列重命名三种方法:一,重命名指定列

二,全部重名名 df.columns=['','','',...],三,修改一部分列名,
df.columns = df.columns.str.replace('动物', '爬行动物')
分析完整案例代码:
import pandas as pd
import numpy as np
pathstart='/Users/kangyongqing/Documents/kangyq/202303/分析模版/Superset看板浏览量分析/'
path1=pathstart+'20230306_100429.csv'
df=pd.read_csv(path1)
print(df.columns)
table=df.pivot_table(index=['dashboard_title','username'],values='pv',aggfunc=('sum','max','count'))
print(table.shape)
table.reset_index().sort_values(['dashboard_title','sum'],ascending=[1,0]).set_index(['dashboard_title','username']).rename(columns={'count':'月活跃天数','max':'单天最大活跃次数','sum':'月度累计活跃次数'}).to_excel(pathstart+'公司看板分析.xlsx')
table1=table.reset_index()
table1[table1['dashboard_title'].str.contains('教学部')].sort_values(['dashboard_title','sum'],ascending=[1,0]).set_index(['dashboard_title','username']).rename(columns={'count':'月活跃天数','max':'单天最大活跃次数','sum':'月度累计活跃次数'}).to_excel(pathstart+'教学部看板分析.xlsx')
df.pivot_table(index='username',values='pv',aggfunc=('sum','max','count')).sort_values('sum',ascending=False).rename(columns={'count':'月活跃天数&看板数','max':'单天最大活跃次数','sum':'月度累计活跃次数'}).to_excel(pathstart+'公司最热用户分析.xlsx')
df.pivot_table(index='dashboard_title',values='pv',aggfunc=('sum','max','count')).sort_values('sum',ascending=False).rename(columns={'count':'月活跃天数&人次','max':'单天单人最大活跃次数','sum':'月度累计活跃次数'}).to_excel(pathstart+'公司最热看板分析.xlsx')
df[df['dashboard_title'].str.contains('教学部')].pivot_table(index='username',values='pv',aggfunc=('sum','max','count')).sort_values('sum',ascending=False).rename(columns={'count':'月活跃天数&看板数','max':'单天单人最大活跃次数','sum':'月度累计活跃次数'}).to_excel(pathstart+'教学部最热用户分析.xlsx')
df[df['dashboard_title'].str.contains('教学部')].pivot_table(index='dashboard_title',values='pv',aggfunc=('sum','max','count')).sort_values('sum',ascending=False).rename(columns={'count':'月活跃天数&人次','max':'单天单人最大活跃次数','sum':'月度累计活跃次数'}).to_excel(pathstart+'教学部最热看板分析.xlsx')