导读:需要论文和源码的可以扫码加威

算法能干什么
算法可以用来做“目标检测”、“目标实例分割”、“目标关键点检测”。
算法有什么优点
Mask R-CNN是一个非常灵活的框架,可以增加不同的分支完成不同的任务,可以完成目标分类、目标检测、语义分割、实例分割、人体姿势识别等多种任务,高速、高准确率、简单直观。
这理解是一个概念:实例分割。通常意义上的目标分割指的是语义分割,语义分割已经有很长的发展历史,已经取得了很好地进展,目前有很多的学者在做这方面的研究;然而实例分割是一个从目标分割领域独立出来的一个小领域,是最近几年才发展起来的,与前者相比,后者更加复杂,当前研究的学者也比较少,是一个有研究空间的热门领域
总体架构
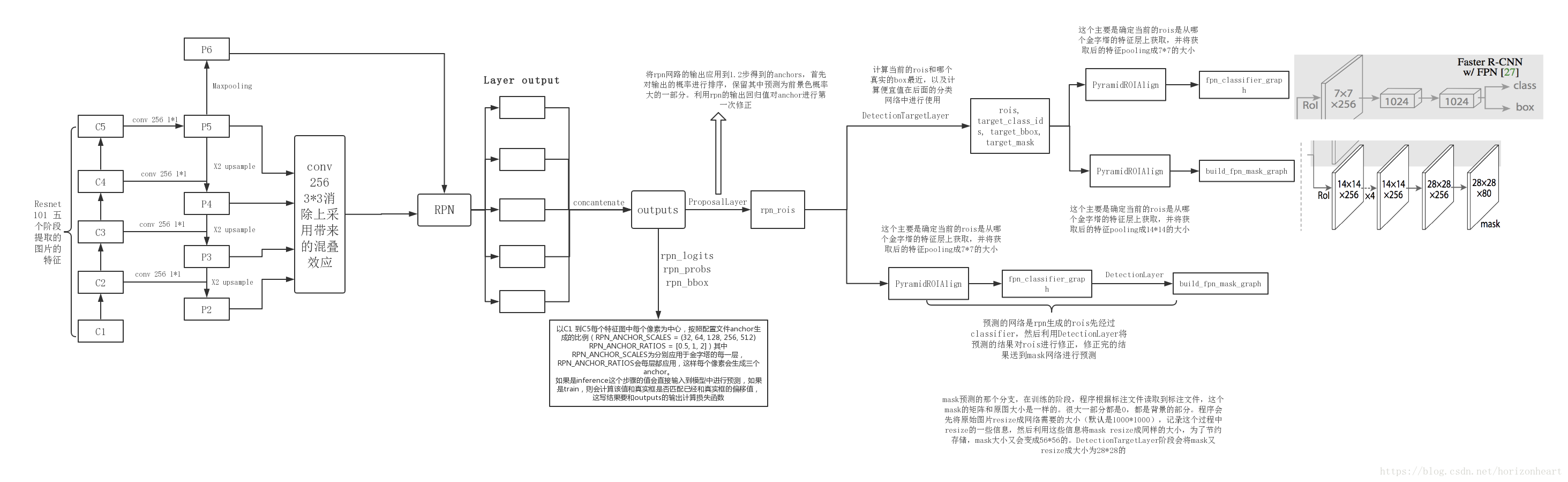
Mask-RCNN 大体框架还是 Faster-RCNN 的框架,可以说在基础特征网络之后又加入了全连接的分割子网,由原来的两个任务(分类+回归)变为了三个任务(分类+回归+分割)。Mask R-CNN 是一个两阶段的框架,第一个阶段扫描图像并生成提议即RPN部分(proposals,即有可能包含一个目标的区域),第二阶段分类提议并生成边界框和掩码即MRCNN部分。
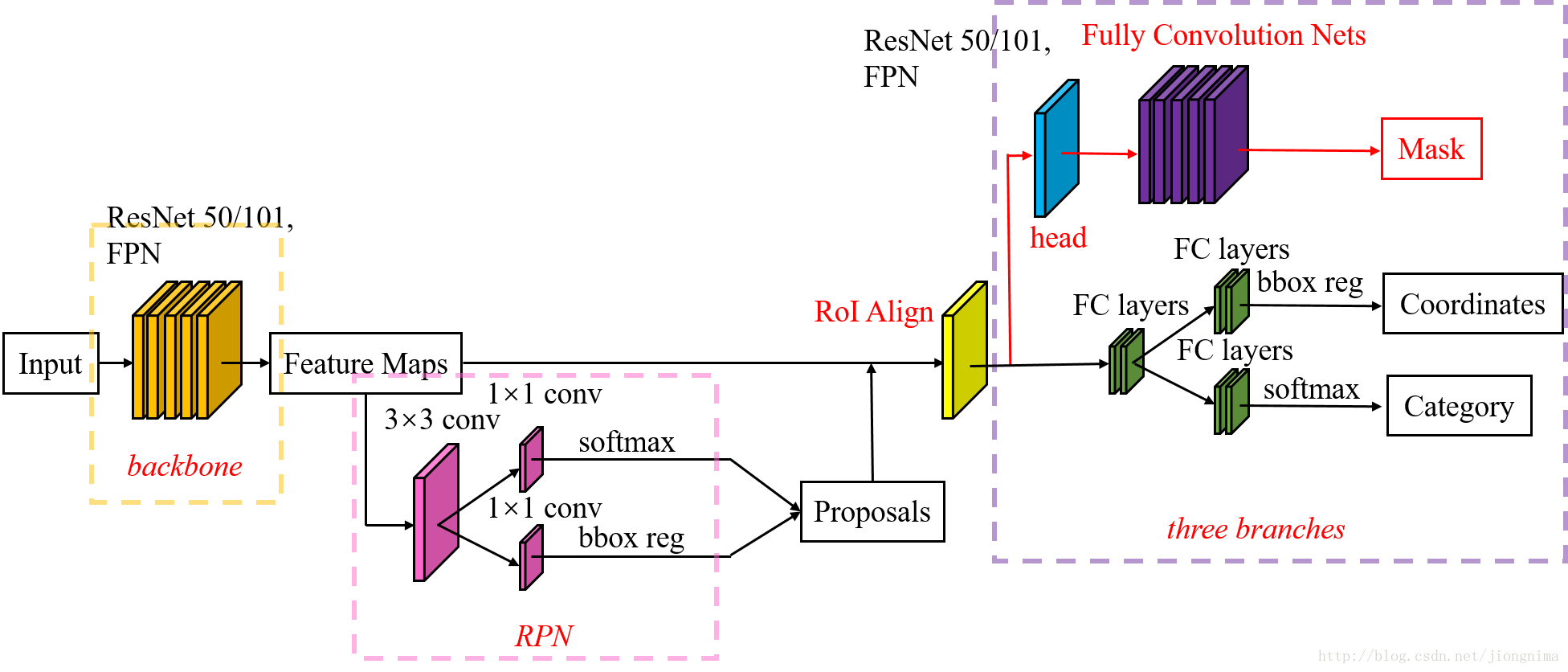
总体流程如下
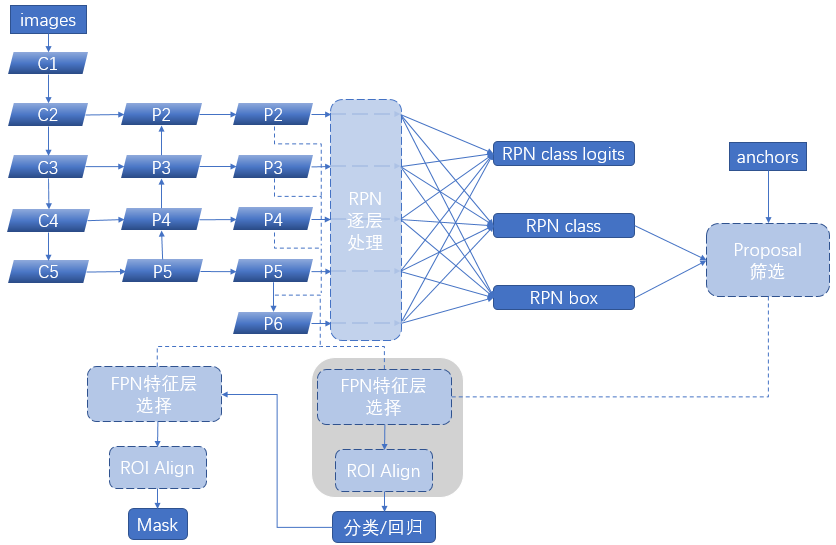
下图是模型每个模块的关系:
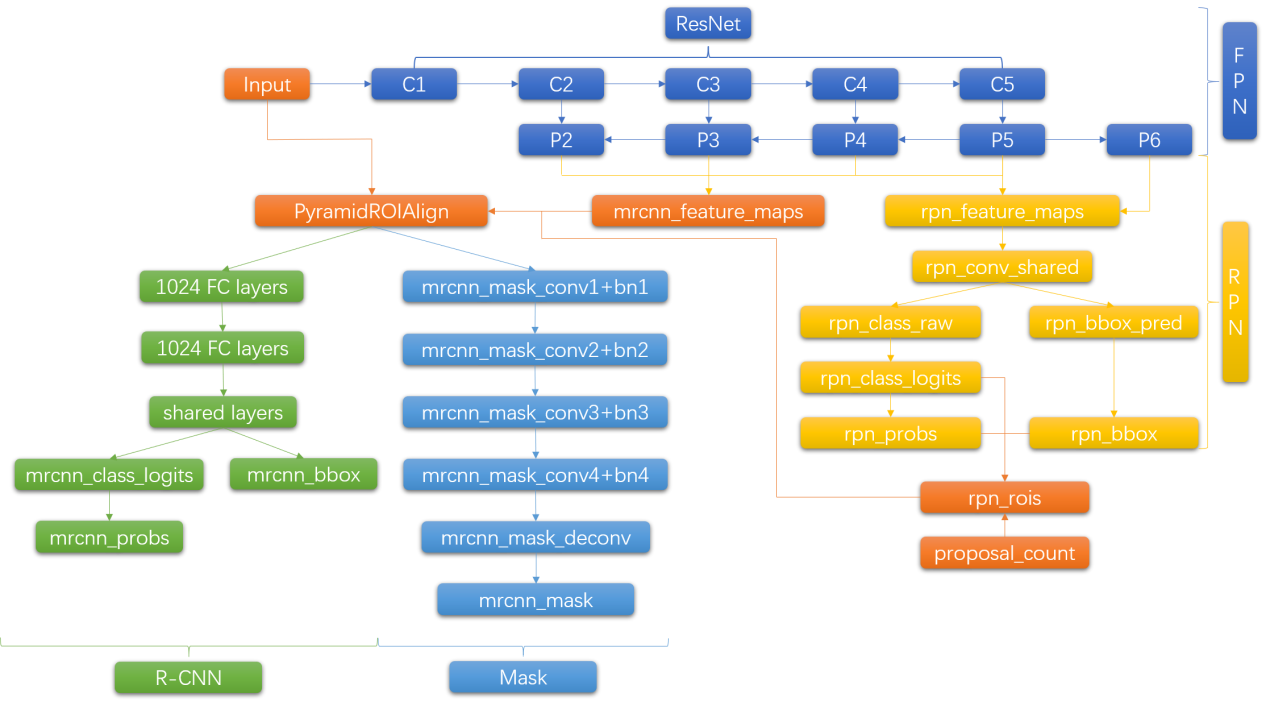
下图是源码的每一个模块这个看了源码可以看下:
1)输入图像;
以三通道图为例,下图是Resnet101的backbone,基本模块是残差模块,加入了一些跳级层和主干路的层想加
(这里相加前提是feature map通道数和尺寸相同然后逐像素相加,和darknet的跳级层add相加不太一样)
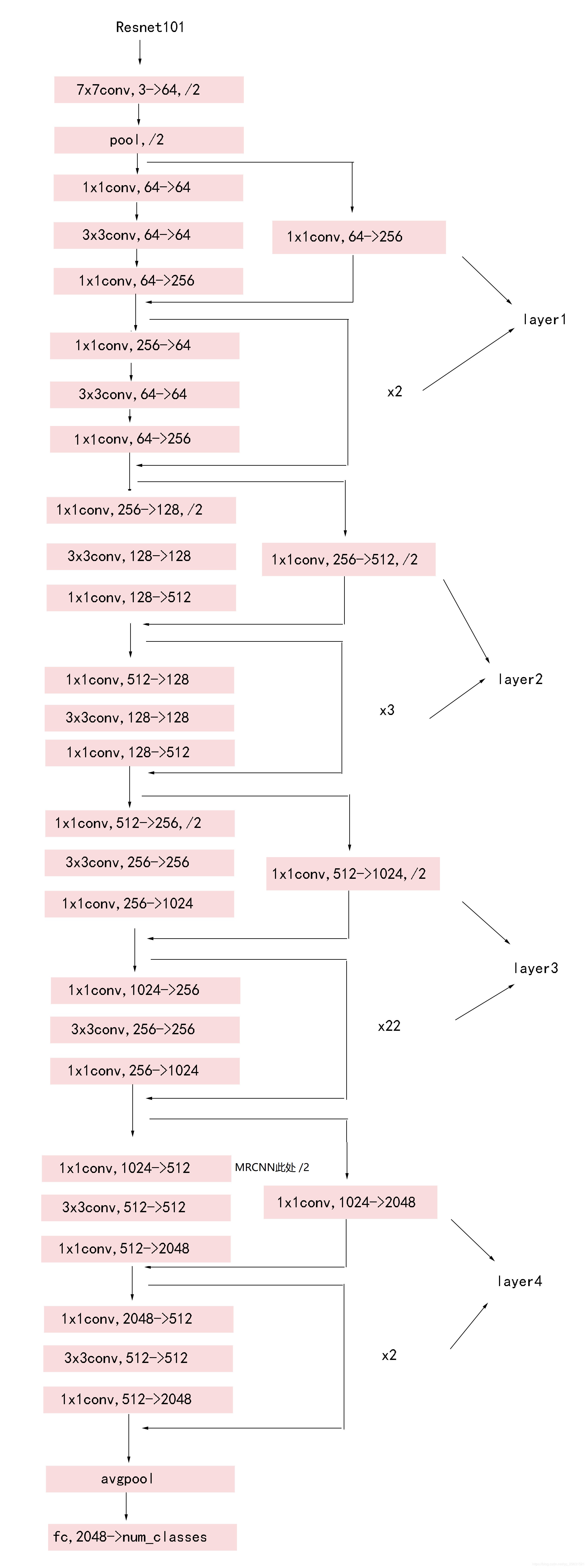
2)将整张图片输入CNN(Resnet101),FPN特征金字塔提取出C1-C5。

将C5进行1*1的卷积减少通道数至256生成P5, P5进行3*3卷积生成同通道数P5,
P5上采样*2 + C4进行1*1卷积减少通道数至256生成P4,P4进行3*3卷积生成同通道数P4,
P4上采样*2 + C3进行1*1卷积减少通道数至256生成P3,P3进行3*3卷积生成同通道数P3,
P3上采样*2 + C2进行1*1卷积减少通道数至256生成P2,P2进行3*3卷积生成同通道数P2,
P5还要进行一次最大池化尺寸/2生成P6(仅rpn使用);
【p2,p3,p4,p5,p6】-> RPN 【p2,p3,p4,p5】-> MRCNN
3)生成anchors:RPN共有5个特征尺度,anchors的基础大小也是基于这5个特征尺度,
越小的特征尺度对应着越大的anchors,反之亦然。基于这五个尺度的图片,每个尺度的特征图中每个像素点生成三个anchors,比例分别是【0.5,1,2】。组后将五个尺度的anchors
叠加成为RPN所使用的anchors,注意:生成的anchors坐标是归一化坐标;
4)用RPN生成预选框(proposals):同anchors的生成也是在五个特征尺度上进行,每个特
征图经过RPN网络生成两个结果一个是rpn_class_logits(每个anchors对应的BG/FG类别logits
注:给损失函数用的)---softmax---> rpn_class_prob(每个anchors的类别置信度), 另一个结
果是rpn_bbox(每个anchors的偏移量[dy, dx, log(dh), log(dw)] ),得到每个尺度的类别和偏移
后将五个尺度叠加合成RPN网络输出的类别和偏移;
接下来判定需要生成的预选框,将RPN网络生成的偏移量更新给anchors,并生成经过细化/nms(非极大抑制)后的归一化预选框,为之后的训练(2000个)/预测(1000个)使用;
5)【训练】接下来训练和预测会有一些不同这里分开来,先说训练。
训练会对生成的预选框进行处理,将实际打标的bbox和预选框做IOU计算,IOU大于0.5的记为正样本,IOU小于0.5的记为负样本,负样本最终随机选取两倍于正样本数的bbox,然后将正样本和负样本叠加,若叠加后的样本不足100,则不足的地方填充0,这样便生成了训练专用的预选框;
6)【训练】特征金字塔RoiAlign:把预选框映射到FPN对应的feature map[p2,p3,p4,p5]上。
这里需要使用一个映射公式来求预选框究竟对应了哪个尺度的feature map,公式如下:
k0 + log2(sqrt(w*h) / 224)
W/H为预选框对应原图尺寸的宽高;
这里k0取4,表示若预选框的面积为224个像素则此预选框映射到P4的feature map;
224和K0这个数值是可以改动的,具体数据取决于数据集中实例的大小,本公式的意思就是面积224的实例占多数并将其映射到p4,这样小于224的实例可以映射到p3p2,大于224的实例可以映射到p5(我们要将大的实例映射到小的feature map如p5,将小的实例映射到大的feature map如p2)
得到了映射的feature map后使用RoiAlign将对应的feature map区域抠出来resize到7*7,100个rois生成了;
7)【训练】将rois带入MRCNN网络,网络有两个,第一个是全连接网络生成两个结果一个是类别回归mrcnn_class_logits(每个rois对应的多分类类别logits,注:给损失函数用)---softmax---> mrcnn_class_prob(每个rois的类别置信度),第二个结果是坐标回归mrcnn_bbox(每个rois的偏移量[dy, dx, log(dh), log(dw)]);第二个是全卷积语义分割网络生成一个结果mrcnn_mask,大小为28*28的mask图,通道数为分类数。至此开始进行loss函数的计算,训练就此开始迭代;
以上是训练部分的基本结构,预测部分结构如下:
8) 【预测】上接第四步,将预测要使用的1000个预选框进行RoiAlign生成1000个rois,带入MRCNN全连接网络中的类别,位置回归,生成mrcnn_class_prob和mrcnn_bbox(偏移量);
9) 【预测】将mrcnn层预测的偏移量更新至1000个预选框得到1000个bbox标准化坐标
根据预测的图片中存在的实例类别逐类NMS处理,高于置信度阈值并且非背景类的roi的n个数据保留,然后将处理过的bbox填0至100,得到了预测boxes;
10)【预测】将得到的100个预测boxes带入MRCNN 全卷积语义分割网络生成mrcnn_mask大小为28*28的mask图,通道数为分类数。
总的结构附上一个图
很详细:
需要论文源码资料的可以加薇即可免费获取
![]()
还有整理的网上杂乱的人工智能学习资料,网盘已经罗列清晰一共500G-
❶ 人工智能课程及项目(含有课件源码)能写进简历的企业级项目实战
❷人工智能优质必看书籍(“圣经”花书等)+人工智能论文合集
❸ 国内外知名大佬教程及配套zi料(女神李飞飞、吴恩达、李沐)
❹ 超详解人工智能学习路+系统学习zi料
❺优质人工智能资源网站整理 、人工智能行业报告
如果对大家有帮助的话记得点赞收藏~