VSM是一个比较经典的机器学习模型,有很多比较好的文章已经对这个模型进行了详细的介绍,在此就不在赘述相关的背景及其原理,个人将一些写的比较好的文章整理放在了参考资料:
构建流程:
- 数据预处理:将准备用于输入的文档进行去噪、分词、编码格式转换、以及去除停用词等等。
计算每个文档中每个term的TF值,然后使用公式进行归一化处理:
再分别计算每个文档中每个term的IDF值:
最后将每个term的tf值和idf值合并为tf-idf值,为了保证权值不偏向长文档,建议在tfidf值计算后再乘上文档长度的倒数进行归一化处理:
将每个文档按照权值排序后构建向量,并计算两两向量之间的余弦值(也就是文档相相似度)
最后,个人编写的样例工程:
VSM样例工程
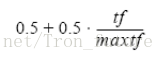
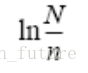
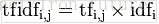
参考资料
https://blog.csdn.net/quicmous/article/details/71263844
https://blog.csdn.net/flying_all/article/details/77152409
http://www.ruanyifeng.com/blog/2013/03/tf-idf.html
http://www.ruanyifeng.com/blog/2013/03/cosine_similarity.html
扫描二维码关注公众号,回复:
1548245 查看本文章

https://blog.csdn.net/aspirinvagrant/article/details/41250887
http://www.cnblogs.com/biyeymyhjob/archive/2012/07/17/2595249.html
http://www.cnblogs.com/haippy/archive/2011/10/04/2199144.html