最近发现做办公自动化表格匹配的时候还是csv格式的文件最快、效率是最高的
今天接到一个需求就是大致内容之这样的
1、给我一张表格直邮一列A列,内容是运单号
2、需要用相同的单号去另外一张表格匹配数据
3、其实就是Excel中的常见的vlookup
但是想要匹配的表格有几十个,所以这样你还觉得用vlookup方便么

解决方案
1、将想要匹配的表格(Excel转换成CSV),如果你的表格本身就是csv可以跳过此步骤
文件夹【数据源】,作用:存放你想要转换csv的表格——请提前创建好
文件夹【数据源(csv)】,作用:存放你转换好之后的csv文件——请提前创建好
代码
import os,time
import pandas as pd
def xlsx2csv_mh():
for f in os.listdir("./数据源/"):
t1 = time.time()
data = pd.read_excel("./数据源/" + f, index_col=0)
data.to_csv("./数据源(csv)/" + f + '.csv', encoding='utf-8')
print(f"{
f}转换完成......")
t2 = time.time()
print(t2 - t1)
xlsx2csv_mh()
2、 做匹配项,保存为json文件
我做的匹配项可一键多值,就是如:A列作为建:[B列+C列+D列。。。],以这样的形式
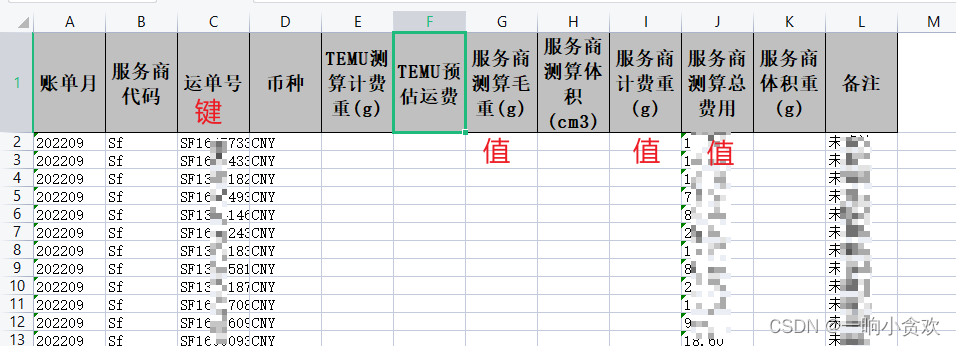
如图,我就想以C列为键,G列、I列、J列为值
读取上一步转换好csv的文件夹
list_a.append((row[2],row[6]+"="+row[8]+"="+row[9])),这行就是我做的列表,row[2]就是键,row[6]+“=”+row[8]+“=”+row[9],这个就是值,中间我用=等于号隔开了
文件夹【json文件】,作用:存放做好的json文件——请提前创建好
代码(接上一步):
import json
import os
from collections import defaultdict
import csv
for f in os.listdir('./数据源(csv)/')[:1]:
list_a = []
d = defaultdict(list)
with open('./数据源(csv)/'+ f, newline='', encoding='utf-8') as csvfile:
reader = csv.reader(csvfile, delimiter=',', quotechar='"')
for row in reader:
list_a.append((row[2],row[6]+"="+row[8]+"="+row[9]))
for key, value in list_a:
d[key].append(value)
with open(f"./json文件/{
f}.json","w",encoding="utf-8") as f_w:
f_w.write(json.dumps(d,ensure_ascii=False))
print(f"{
f},转换json成功")
查看做好的json文件
读取json,进行测试
代码
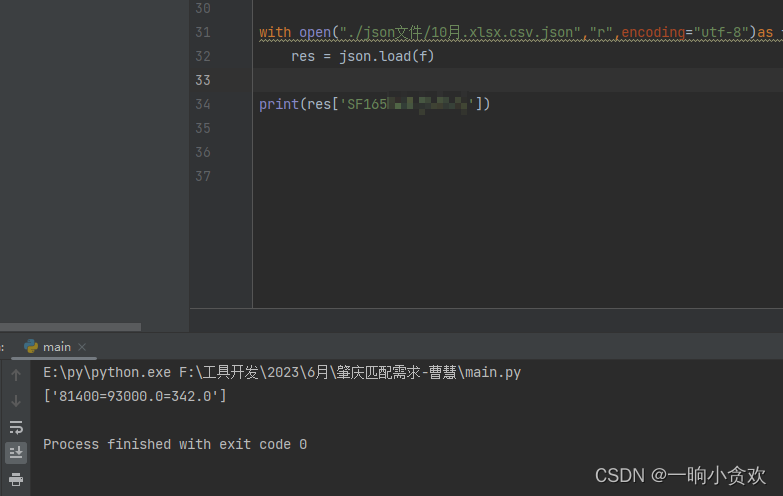
with open("./json文件/10月.xlsx.csv.json","r",encoding="utf-8")as f:
res = json.load(f)
print(res['SF16xxxxxxx'])
成功!!
好了,分享结束,希望能够帮助到你
更多关于办公自动化的知识,请关注我吧
更多关乎Excel操作请关注我的专栏吧