第九章 卷积神经网络(CNN)
本章不按照书本的顺序讲,但是会涉及到书本的大多数内容:-)
特别鸣谢吴恩达大佬的视频课程:-)视频课程传送门
1.深度学习的主要领域
计算机视觉、语音识别、自然语言处理、推荐系统等。随着数据量巨规模的增大,这些领域在发生很大的变化。而在计算机视觉领域,我们更多要用到卷积神经网络。那么卷积神经网络能做些什么呢?(以下用CNN代替卷积神经网络)
2.计算机视觉中常见的问题
图像分类、目标检测、图像风格转换(前面两个大家应该比较熟悉)等问题都可以利用CNN来解决。当然还有很多其它的计算机视觉方向可以使用CNN。

3.既然名字叫CNN,那为什么要卷积呢?什么是卷积操作?
想想我们之前怎么做的?
一般的神经网络,我们都是全部连接。
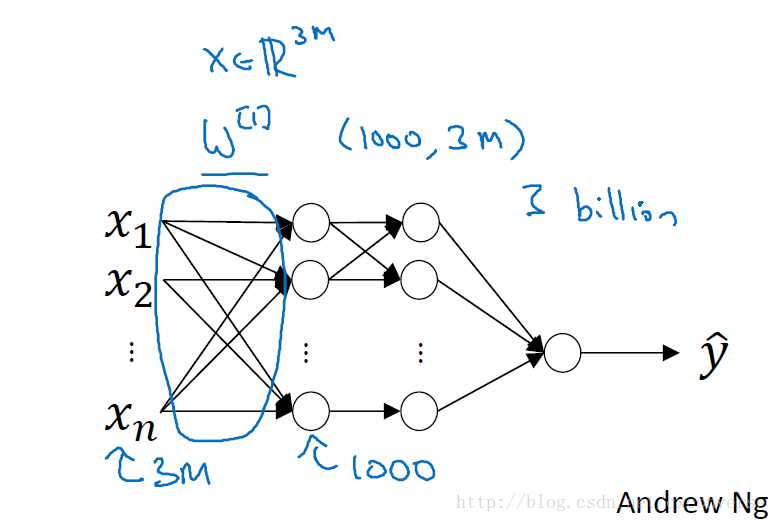
想象这样的一个网络,如果第一层的输入有3000个节点(神经元),而第二层(隐藏层)有1000个节点,那么连接的数目会达到300万。也就有300万个权重。而如果是对于一张比较大的图像来说,就会更多。
于是就引入了卷积操作,其主要思想在于:参数共享、稀疏连接,在讲完了基础知识后,会总结这两个主要特性,相信大家对其理解会更加深入。
4.边缘检测问题
什么是边缘检测?CNN之前是怎么做的?其实边缘检测也是特征提取的一种,在利用CNN之前,一般都是手动去设计提取特征的算法。比如设计一个卷积核(也叫作算子)。比如sobel算子等。
下面看垂直边缘检测的示意图。
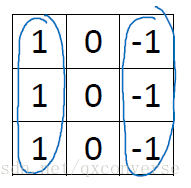
这个算子可以检测到垂直边缘。那么现在的问题是,我们可以不用手动设置这里面的值,而是通过BP算法学习到。也就是说学习到类似于边缘的特征,当然还有其它的很多无法命名的特征。这个就是从数据中学习的例子。

5.Padding卷积
从上面的例子可以看到,6
我们会发现图像越来越小,而且丢失掉一些信息(因为边缘点很少被卷积到),基于这两个问题,需要进行padding操作。
示例padding操作。
- Valid Convolutions
- Same Convolutions
6.Strided卷积
那么刚刚我们只是一步一步地移动,如果每次移动多步呢?
因此就引入了stride(步长)的概念。
但需要注意的是,在加入了padding后,卷积核在向右或向下移动的过程中不能越界。所以下面给出总结:

7.多维度、多卷积核进行卷积
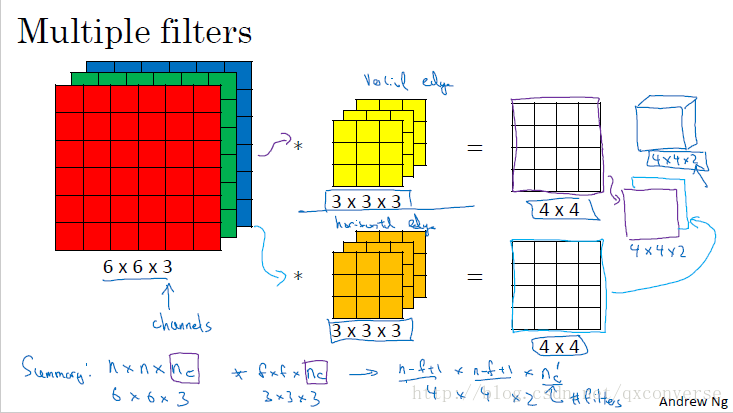
我们知道,现实中的图像往往更多是RGB格式的,不仅仅是2D的。而上面的示例都是在二维平面上进行的。
当引入到多维(比如在这里就是3维,即3个channel)后,卷积操作就会做一点点的改变。这时一张图像(或卷积核或特征映射)可以表示成这样的一个张量:
(m, height, width, channels),比如5张32
具体看示例。
通过使用多个不同的核,这样我们可以学习到多个特征。
8.单层卷积网络
看示例。
问题:如果有10个卷积核,其大小为
共有
这里可以看出,不管图像有多大,参数个数是不变的,当核的尺寸和个数确定下来后。
总结:

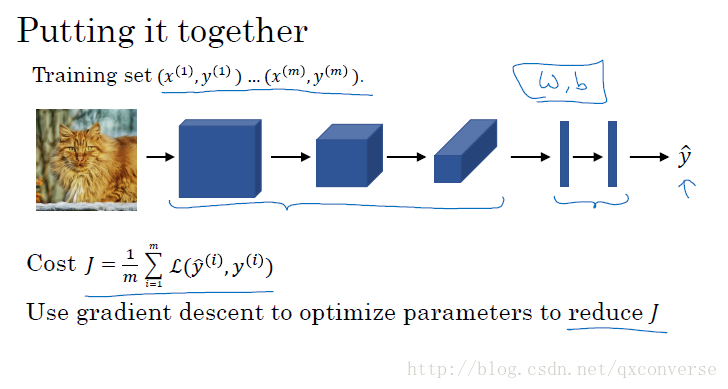
9.卷积网络示例
画图示例
通常在一个卷积网络中,包含3个类型:
- Convolution(Conv)卷积
- Pooling(Pool)池化
- Fully connected(FC)全连接
10.池化
池化函数使用某一个位置的相邻输出的总体统计特征来代替网络在该位置的输出。
常见的池化有两种
- Max Pooling
- Average Pooling
画图示例
需要注意的是,池化操作是分别独立地在每一个Channel里面运算,而且往往Max池化更常见。
而且池化层中是不会学习任何参数的。
对池化层的总结。
举例子,LeNet-5网络
11.为什么会使用卷积
想想如果使用全连接会是怎样。
回想之前提到的两个关键词:参数共享、系数连接,这两个特性就是CNN的精髓。下面的一段文字,是我之前对CNN的理解。大概是说的一个道理。

那么我们看看如何用CNN来进行深度学习:
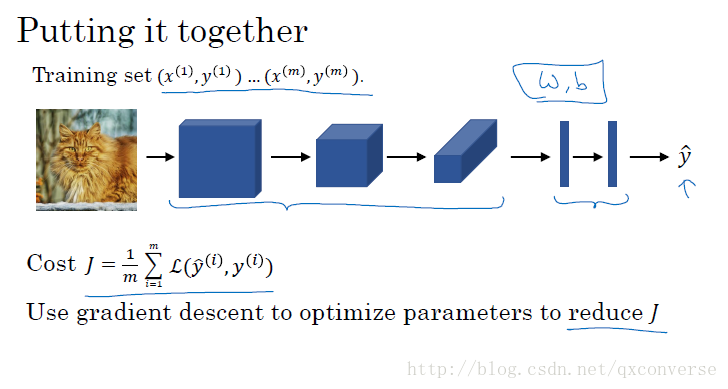
我们的目的就是让数据来学习参数,而不是通过手工去设计参数以获得特征。这就是为什么深度学习也叫作特征学习的原因。
12.常见网络的简单分析
那么到目前为止,我们对CNN有了一个初步的认识了,至少可以看懂很多论文了。我们可以去分析一些经典的网络比如
- LeNet-5 Lécun Y, Bottou L, Bengio Y, et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998, 86(11):2278-2324.
- AlexNet Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
- VGG Simonyan K, Zisserman A. Very Deep Convolutional Networks for Large-Scale Image Recognition[J]. Computer Science, 2014.
以及一些比较新的网络,如残差网络:
He K, Zhang X, Ren S, et al. Deep Residual Learning for Image Recognition[J]. 2015:770-778.
对这些网络进行分析。
13.迁移学习
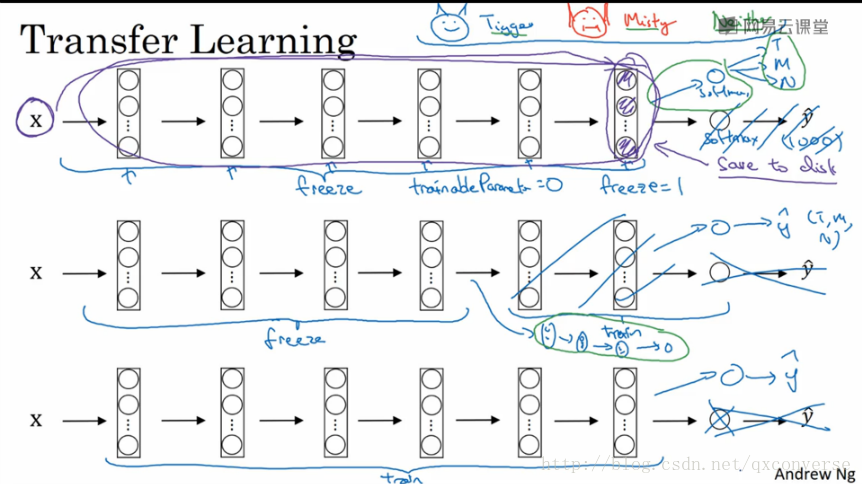
其主要的思想是我们可以利用别人训练好的模型(即权重)来作为我们自己的初始权重。拿分类作为一个例子:
第一种情况:当我们的数据集很少的时候,可以将网络冻结(即在训练的过程中,不再学习参数,直接使用现成的参数),这可以把它理解为一个函数。我们要做的就是更改后面的输出分类。比如从1000个分类,改成3个分类,利用Softmax输出层。
第二种情况:我们的数据不多,可以冻结前面的一部分,而在后面加入一些自己的网络结构设计,再训练,分类。
第三种情况:我们的数据很多,那么我们完全使用这个模型来训练。(不冻结任何的网络部分)。
14.数据增强
数据增强前面第7章有提到过,这里举一些常见的例子:
- 镜像
- 随机裁剪
- 旋转
- 色彩位移(Color shifting)
- PCA Color Augmentation(网上有现成的代码)
15.计算机视觉的现状
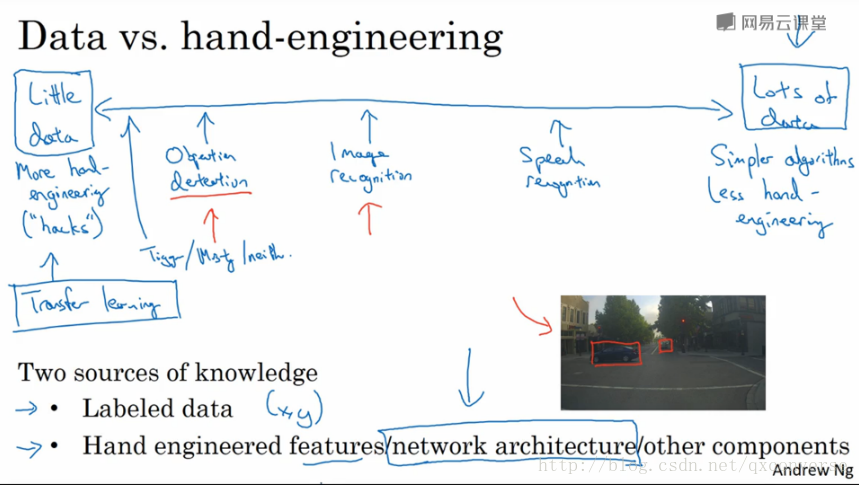
16.目标检测及人脸识别(选讲)
如果时间足够,可以提一下,当然也可以去吴恩达的视频里看。