实验准备:
create table dd1(id varchar2(50) primary key,name varchar2(10),sal number(9,2)); create table dd2(id varchar2(50) primary key,name varchar2(10),sal number(9,2)); insert into dd1 values(get_uuid,'tina',5000); insert into dd1 values(get_uuid,'monica',6000); insert into dd1 values(get_uuid,'jojo',8000); insert into dd2 values(get_uuid,'sany',4000); insert into dd2 values(get_uuid,'selina',6000); insert into dd2 values(get_uuid,'monica',7000); insert into dd2 values(get_uuid,'jojo',9000); commit;
说明:get_uuid是我程序里建的生成主键的函数,可以根据自己实际情况自行设定。下面附上我生成主键的函数语句
CREATE OR REPLACE FUNCTION get_uuid RETURN VARCHAR IS guid VARCHAR(50); BEGIN guid := lower(RAWTOHEX(sys_guid())); RETURN substr(guid, 1, 8) || '-' || substr(guid, 9, 4) || '-' || substr(guid, 13, 4) || '-' || substr(guid, 17, 4) || '-' || substr(guid, 21, 12); END get_uuid;
然后执行merge into table 语句:
merge into dd1 using dd2 on (dd2.name = dd1.name) when matched then update set dd1.sal = dd2.sal when not matched then insert (dd1.id, dd1.name, dd1.sal) values ((select get_uuid from dual), dd2.name, dd2.sal);
报错:
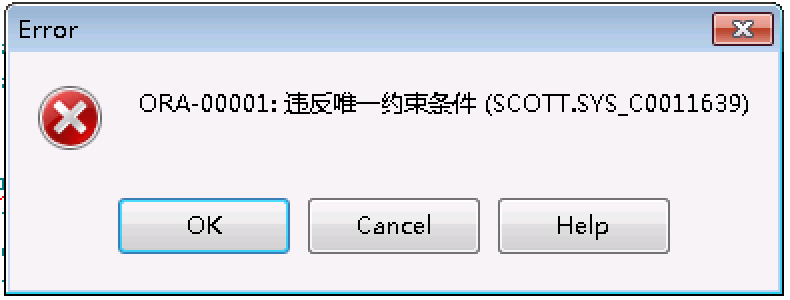
解决方法:
merge into dd1 using dd2 on (dd2.name = dd1.name) when matched then update set dd1.sal = dd2.sal when not matched then insert (dd1.id, dd1.name, dd1.sal) values (get_uuid, dd2.name, dd2.sal);
调整了insert values后面的函数调用方法之后问题得到解决,看了一些网站或书籍介绍说是merge into 语句是通过一次两表扫描之后完全更新操作,那么我的理解是子查询只是调用一次,不会是需要插入N条记录调用N次,所有这个时候通过函数调用获得主键即是一个键值,这样我们往被更新表插入记录的时候就会报错违反主键唯一性约束。这里就要说到标量子查询了吧,我对这块还不是特别了解,会继续对个这个问题进行分析。(这是个人理解,欢迎朋友提出意见或讨论)