12. 位运算
- Numpy中以“bitwise_”开头的函数是位运算函数。
| 函数 | 描述 |
|---|---|
| bitwise_and | 对数组元素执行位与操作。 |
| bitwise_or | 对数组元素执行位或操作。 |
| invert | 按位取反。 |
| left_shift | 向左移动二进制表示的位。 |
| right_shift | 向右移动二进制表示的位。 |
- 注:也可使用“&”、“~”、“|”和“^”等操作符进行计算。
1. bitwise_and()
- bitwise_and()函数对数组中整数的二进制形式执行位与运算。
import numpy as np
print('13和17的二进制形式:')
a, b = 13, 17
print(bin(a), bin(b))
print()
print('13和17的位与:')
print(np.bitwise_and(13, 17))
输出结果如下:
13和17的二进制形式:
0b1101 0b10001
13和17的位与:
1
以上结果说明:
| 操作数 | 1 | 1 | 0 | 1 | |
| 操作符 | AND | ||||
| 操作数 | 1 | 0 | 0 | 0 | 1 |
| 运算结果 | 0 | 0 | 0 | 0 | 1 |
位与操作运算规律如下:
| A | B | AND |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 0 | 0 |
| 0 | 1 | 0 |
| 0 | 0 | 0 |
2. bitwise_or()
- bitwise_or()函数对数组中整数的二进制形式执行位或运算。
import numpy as np
a, b = 13, 17
print('13和17的二进制形式:')
print(bin(a), bin(b))
print()
print('13和17的位或:')
print(np.bitwise_or(13, 17))
输出结果为:
13和17的二进制形式:
0b1101 0b10001
13和17的位或:
29
以上示例可以用下表说明:
| 操作数 | 1 | 1 | 0 | 1 | |
| 操作符 | OR | ||||
| 操作数 | 1 | 0 | 0 | 0 | 1 |
| 运算结果 | 1 | 1 | 1 | 0 | 1 |
位或操作运算规律如下:
| A | B | OR |
|---|---|---|
| 1 | 1 | 1 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 0 | 0 |
3. invert()
- invert()函数对数组中整数进行位取反运算,即0变成1,1变成0。
- 对于有符号整数,取该二进制数的补码,然后+1。二进制数,最高位为0表示正数,最高位为1表示负数。
- 看看~1的计算步骤:
- 将1(这里叫:原码)转二进制 = 00000001
- 按位取反 = 11111110
- 发现符号位(即最高位)为1(表示负数),将除符号位之外的其他数字取反 = 10000001
- 末位加1取其补码 = 10000010
- 转换回十进制 = -2
| 表达式 | 二进制值(2的补数) | 十进制值 |
|---|---|---|
| 5 | 00000000 00000000 00000000 00000101 | 5 |
| ~5 | 11111111 11111111 11111111 11111010 | -6 |
import numpy as np
print('13的位反转,其中ndarray的dtype是uint8:')
print(np.invert(np.array([13], dtype=np.uint8)))
print('\n')
# 比较13和242的二进制表示,我们发现了位的反转
print('13的二进制表示;')
print(np.binary_repr(13, width=8))
print('\n')
print('242的二进制表示:')
print(np.binary_repr(242, width=8))
运行的结果如下:
13的位反转,其中ndarray的dtype是uint8:
[242]
13的二进制表示;
00001101
242的二进制表示:
11110010
4. left_shift()
- left_shift()函数将数组元素的二进制形式向左移动到指定位置,右侧附加相等数量的0。
import numpy as np
print('将10左移两位:')
print(np.left_shift(10, 2))
print()
print('10的二进制表示:')
print(np.binary_repr(10, width=8))
print()
print('40的二进制表示:')
print(np.binary_repr(40, width=8))
# '00001010'中的两位移动到了左边,并在右边添加了两个0。
输出结果为:
将10左移两位:
40
10的二进制表示:
00001010
40的二进制表示:
00101000
5. right_shift()
- right_shift()函数将数组元素的二进制形式向右移动到指定位置,左侧附加相等数量的0。
import numpy as np
print('将40右移两位:')
print(np.right_shift(40, 2))
print()
print('40的二进制表示:')
print(np.binary_repr(40, width=8))
print()
print('10的二进制表示:')
print(np.binary_repr(10, width =8))
# '00001010'中的两位移动到了右边,并在左边添加了两个0。
运行结果如下:
将40右移两位:
10
40的二进制表示:
00101000
10的二进制表示:
00001010
13. 字符串函数
- 以下函数用于对dtype为numpy.string_或numpy.unicode_的数组执行向量化字符串操作。它们基于Python内置库中的标准字符串函数。
- 这些函数在字符数组类(numpy.char)中定义。
| 函数 | 描述 |
|---|---|
| add() | 对两个数组的逐个字符串元素进行连接。 |
| multiply() | 返回按元素多重连接后的字符串 |
| center() | 居中字符串。 |
| capitalize() | 将字符串第一个字母转换为大写。 |
| title() | 将字符串的每个单词的第一个字母转换为大写。 |
| lower() | 数组元素转换为小写。 |
| upper() | 数组元素转换为大写。 |
| split() | 指定分隔符对字符串进行分割,并返回数组列表。 |
| splitlines() | 返回元素中的行列表,以换行符分割。 |
| strip() | 移除元素开头或者是结尾处的特定字符。 |
| join() | 通过指定分隔符来连接数组中的元素。 |
| replace() | 使用新字符串替换字符串中的所有子字符串。 |
| decode() | 数组元素依次调用str.decode |
| encode() | 数组元素依次调用str.encode |
1. numpy.char.add()
- numpy.char.add()函数依次对两个数组的元素进行字符串连接。
import numpy as np
print('连接两个字符串:')
print(np.char.add(['hello'], ['lcx']))
print()
print('连接示例2:')
print(np.char.add(['hello', 'hi'], ['abc', 'lcx']))
print()
print('连接示例3:')
print(np.char.add(['hello'], ['abc', 'lcx']))
print(np.char.add(['hello', 'hi'], ['lcx']))
运行结果如下:
连接两个字符串:
['hellolcx']
连接示例2:
['helloabc' 'hilcx']
连接示例3:
['helloabc' 'hellolcx']
['hellolcx' 'hilcx']
2. numpy.char.multiply()
- numpy.char.multiply()函数执行多重连接。
import numpy as np
print(np.char.multiply('Runoob ', 3))
运行结果如下:
Runoob Runoob Runoob
3. numpy.char.center()
- numpy.char.center()函数用于将字符串居中,并使用指定字符在左侧和右侧进行填充。
import numpy as np
# np.char.center(str, width, fillchar):
# str:字符串,width:长度,filter:填充字符。
print(np.char.center('Runoob', 20, fillchar="*"))
输出结果为:
*******Runoob*******
4. numpy.char.capitalize()
- 将字符串的第一个字母转换为大写。
import numpy as np
print(np.char.capitalize('runoob'))
print(np.char.capitalize('runoob hello'))
print(np.char.capitalize('Runoob hello'))
运行结果如下:
Runoob
Runoob hello
Runoob hello
5. numpy.char.title()
- 将字符串的每个单词的第一个字母转换为大写。
import numpy as np
print(np.char.title('runoob'))
print(np.char.title('runoob hello'))
print(np.char.title('runoob Hello'))
print(np.char.title('runoob o'))
print(np.char.title('Runoob o'))
print(np.char.title('Runoob hello, of sure'))
print(np.char.title(['Runoob hello, of sure', "haha", 'lonely']))
运行结果如下:
Runoob
Runoob Hello
Runoob Hello
Runoob O
Runoob O
Runoob Hello, Of Sure
['Runoob Hello, Of Sure' 'Haha' 'Lonely']
6. numpy.char.lower()
- 对数组的每个元素转换为小写,对每个元素调用str.lower。
import numpy as np
# 操作数组
print(np.char.lower(['HELLO KITTY', 'Love', "DeAtH", 'Robots Yeah']))
# 操作字符串
print(np.char.lower("I will never gIve iT Up."))
运行结果如下:
# 操作数组
print(np.char.lower(['HELLO KITTY', 'Love', "DeAtH", 'Robots Yeah']))
# 操作字符串
print(np.char.lower("I will never gIve iT Up."))
7. numpy.char.upper()
- 对数组的每个元素转换为大写。它对每个元素调用str.upper。
import numpy as np
# 操作数组
print(np.char.upper(['runoob', 'google', 'lihao', 'Hello', 'HI Mike']))
# 操作字符串
print(np.char.upper('my name is Black JaCK.'))
运行结果:
['RUNOOB' 'GOOGLE' 'LIHAO' 'HELLO' 'HI MIKE']
MY NAME IS BLACK JACK.
8. numpy.char.split()
- 通过指定分隔符对字符串进行分割,并返回数组。默认情况下,分隔符为空格。
import numpy as np
# 分隔符默认为空格
print(np.char.split('i like runoob?'))
# 分隔符为.
print(np.char.split('www.runoob.com', sep="."))
# 操作数组
print(np.char.split(['www.cs', 'love is.1314.520', 'for.the.team. SNK'], sep="."))
运行结果:
['i', 'like', 'runoob?']
['www', 'runoob', 'com']
[list(['www', 'cs']) list(['love is', '1314', '520'])
list(['for', 'the', 'team', ' SNK'])]
9. numpy.char.splitlines()
- 以换行符作为分隔符来分割字符串,并返回数组。
- \n,\r,\r\n都可用作换行符。
import numpy as np
# 换行符为 \n和\r
print(np.char.splitlines('i\nlike runoob?'))
print(np.char.splitlines('i\rlike runoob?'))
print(np.char.splitlines(['i\rlike runoob?', 'she\nis a \rlittle Girl.']))
print(np.char.splitlines('i\r\nlike\n\rrunoob?'))
print(np.char.splitlines('i\n\rrunoob?'))
运行结果如下:
['i', 'like runoob?']
['i', 'like runoob?']
[list(['i', 'like runoob?']) list(['she', 'is a ', 'little Girl.'])]
['i', 'like', '', 'runoob?']
['i', '', 'runoob?']
10. numpy.char.strip()
- 用于移除开头或结尾处的特定字符。
import numpy as np
# 移除字符串头尾的a字符
print(np.char.strip('ashok arounooba', 'a'))
# 移除数组元素头尾的a字符
print(np.char.strip(['arunooba', 'admin', 'java'], 'a'))
运行结果如下:
shok arounoob
['runoob' 'dmin' 'jav']
11. numpy.char.join()
- 通过指定分隔符来连接数组中的元素或字符串。
import numpy as np
# 操作字符串
print(np.char.join(':', 'runoob'))
# 指定多个分隔符操作元素
print(np.char.join([':', '-'], ['runoob', 'google']))
运行结果如下:
r:u:n:o:o:b
['r:u:n:o:o:b' 'g-o-o-g-l-e']
12. numpy.char.replace()
- 使用新字符串替换字符串中的所有子字符串。
print(np.char.replace('i like runoob', 'oo', 'cc'))
运行结果如下:
i like runccb
13. numpy.char.encode()
- 对数组中的每个元素调用st.encode函数。默认编码是utf-8,可以使用Python库中的解码器。
import numpy as np
a = np.char.encode('runoob', 'cp500')
print(a)
运行结果如下:
b'\x99\xa4\x95\x96\x96\x82'
14. numpy.char.decode()
- 对编码的元素进行str.decode()解码。
import numpy as np
a = np.char.encode('runoob', 'cp500')
print(a)
print(np.char.decode(a, 'cp500'))
运行结果如下:
b'\x99\xa4\x95\x96\x96\x82'
runoob
14. 数学函数
- Numpy包含大量的各种数学运算的函数,包括三角函数、算术运算的函数、复数处理函数等。
1. 三角函数
- numpy提供了标准的三角函数:sin()、cos()、tan()。
import numpy as np
a = np.array([0, 30, 45, 60, 90])
print('不同角度的正弦值:')
# 通过乘 pi/180 转化为弧度
print(np.sin(a*np.pi/180))
print()
print('数组中角度的余弦值:')
print(np.cos(a*np.pi/180))
print()
print('数组中角度的正切值:')
print(np.tan(a*np.pi/180))
运行结果:
不同角度的正弦值:
[0. 0.5 0.70710678 0.8660254 1. ]
数组中角度的余弦值:
[1.00000000e+00 8.66025404e-01 7.07106781e-01 5.00000000e-01
6.12323400e-17]
数组中角度的正切值:
[0.00000000e+00 5.77350269e-01 1.00000000e+00 1.73205081e+00
1.63312394e+16]
2. 反三角函数
- arcsin(),arccos()、arctan()函数返回给定角度的sin、cos和tan的反三角函数。
- 这些函数的结果可以通过**numpy.degrees()**函数将弧度转换为角度。
import numpy as np
a = np.array([0, 30, 45, 60, 90])
print('含有正弦值的数组:')
sin = np.sin(a*np.pi/180)
print(sin)
print()
print('计算角度的反正弦,返回值以弧度为单位:')
inv = np.arcsin(sin)
print(inv)
print()
print('通过转化为角度制来检查结果:')
print(np.degrees(inv))
print('\n')
print('arccos和arctan函数行为类似:')
cos = np.cos(a*np.pi/180)
print(cos)
print()
print('反余弦:')
inv = np.arccos(cos)
print(inv)
print()
print('角度制单位:')
print(np.degrees(inv))
print()
print('tan函数:')
tan = np.tan(a * np.pi /180)
print(tan)
print()
print('反正切:')
inv = np.arctan(tan)
print(inv)
print()
print('角度制单位:')
print(np.degrees(inv))
运行结果如下:
含有正弦值的数组:
[0. 0.5 0.70710678 0.8660254 1. ]
计算角度的反正弦,返回值以弧度为单位:
[0. 0.52359878 0.78539816 1.04719755 1.57079633]
通过转化为角度制来检查结果:
[ 0. 30. 45. 60. 90.]
arccos和arctan函数行为类似:
[1.00000000e+00 8.66025404e-01 7.07106781e-01 5.00000000e-01
6.12323400e-17]
反余弦:
[0. 0.52359878 0.78539816 1.04719755 1.57079633]
角度制单位:
[ 0. 30. 45. 60. 90.]
tan函数:
[0.00000000e+00 5.77350269e-01 1.00000000e+00 1.73205081e+00
1.63312394e+16]
反正切:
[0. 0.52359878 0.78539816 1.04719755 1.57079633]
角度制单位:
[ 0. 30. 45. 60. 90.]
3. 舍入函数
1. numpy.round()
- numpy.around()函数返回指定数字的四舍五入值。
import numpy as np
numpy.around(a, decimals)
# a:数组
# decimals:舍入的小数位数。默认为0,如果为负,整数将四舍五入到小数点左侧的位置。
a = np.array([1.0, 5.55, 123, 0.567, 25.532])
print('原数组:')
print(a)
print()
print('舍入后:')
print(np.around(a))
print(np.around(a, decimals=1))
print(np.around(a, decimals=-1))
print(np.around(a, decimals=-2))
运行结果如下:
原数组:
[ 1. 5.55 123. 0.567 25.532]
舍入后:
[ 1. 6. 123. 1. 26.]
[ 1. 5.6 123. 0.6 25.5]
[ 0. 10. 120. 0. 30.]
[ 0. 0. 100. 0. 0.]
2. numpy.floor()
- 返回小于或者等于指定表达式的最大整数,即向下取整。
import numpy as np
a = np.array([-1.7, 1.5, -0.2, 0.6, 10])
print('提供的数组:')
print(a)
print()
print('修改后的数组:')
print(np.floor(a))
运行结果:
提供的数组:
[-1.7 1.5 -0.2 0.6 10. ]
修改后的数组:
[-2. 1. -1. 0. 10.]
3. numpy.ceil()
- 返回大于或者等于指定表达式的最小整数,即向上取整。
import numpy as np
a = np.array([-1.7, 1.5, -0.2, 0.6, 10])
print('提供的数组:')
print(a)
print()
print('修改后的数组:')
print(np.ceil(a))
运行结果如下:
提供的数组:
[-1.7 1.5 -0.2 0.6 10. ]
修改后的数组:
[-1. 2. -0. 1. 10.]
15. 算术函数
1. 简单的加减乘除
- numpy算术函数包含简单的加减乘除:add()、subtract()、multiply()、divide()。
- 需要注意的是数组必须具有相同的形状或符合数组广播规则。
a = np.arange(9, dtype=np.float_).reshape(3, 3)
print('第一个数组:')
print(a)
print()
print('第二个数组:')
b = np.array([10, 10, 10])
print(b)
print()
print('两个数组相加:')
print(np.add(a, b))
print()
print('两个数组相减:')
print(np.subtract(a, b))
print()
print('两个数组相乘:')
print(np.multiply(a, b))
print()
print('两个数组相除:')
print(np.divide(a, b))
运行结果如下:
第一个数组:
[[0. 1. 2.]
[3. 4. 5.]
[6. 7. 8.]]
第二个数组:
[10 10 10]
两个数组相加:
[[10. 11. 12.]
[13. 14. 15.]
[16. 17. 18.]]
两个数组相减:
[[-10. -9. -8.]
[ -7. -6. -5.]
[ -4. -3. -2.]]
两个数组相乘:
[[ 0. 10. 20.]
[30. 40. 50.]
[60. 70. 80.]]
两个数组相除:
[[0. 0.1 0.2]
[0.3 0.4 0.5]
[0.6 0.7 0.8]]
- numpy也包含了其他重要的算术函数。
2. numpy.reciprocal()求倒数
- 返回参数逐元素的倒数。如1/4倒数为4/1。
import numpy as np
a = np.array([0.25, 1.33, 1, 100])
print('我们的数组是:')
print(a)
print()
print('调用reciprocal函数:')
print(np.reciprocal(a))
运行结果如下:
我们的数组是:
[ 0.25 1.33 1. 100. ]
调用reciprocal函数:
[4. 0.7518797 1. 0.01 ]
3. numpy.power()幂运算
- 将第一个输入数组中的元素作为底数,计算它与第二个输入数组中相应元素的幂。
import numpy as np
a = np.array([10, 100, 1000])
print('我们的数组是:')
print(a)
print()
print('调用power函数:')
print(np.power(a, 2))
print()
print('第二个数组:')
b = np.array([1, 2, 3])
print(b)
print()
print('再次调用power函数:')
print(np.power(a, b))
print()
print('再调用一次:')
c= np.array([[1, 2, 3], [1, 2, 3]])
print(np.power(a, c))
运行结果如下:
我们的数组是:
[ 10 100 1000]
调用power函数:
[ 100 10000 1000000]
第二个数组:
[1 2 3]
再次调用power函数:
[ 10 10000 1000000000]
再调用一次:
[[ 10 10000 1000000000]
[ 10 10000 1000000000]]
4. numpy.mod()求余数
- 计算输入数组中相应元素的相除后的余数。
- 函数numpy.remainder()也产生相同的结果。
import numpy as np
a = np.array([10, 20, 30])
b = np.array([3, 5, 7])
print('第一个数组:')
print(a)
print()
print('第二个数组:')
print(b)
print()
print('调用mod()函数:')
print(np.mod(a, b))
print()
print('调用remainder()函数:')
print(np.remainder(a, b))
运行结果:
第一个数组:
[10 20 30]
第二个数组:
[3 5 7]
调用mod()函数:
[1 0 2]
调用remainder()函数:
[1 0 2]
16. 统计函数
- numpy提供了很多统计函数,用于从数组中查找最小元素、最大元素、百分位标准差、方差等。
1. numpy.amin()和numpy.amax()获得最小、最大值
- numpy.amin()用于计算数组中的元素沿指定轴的最小值。
- numpy.amax()用于计算数组中的元素沿指定轴的最大值。
import numpy as np
a = np.array([[3, 7, 5], [8, 4, 3], [2, 4, 9]])
print('我们的数组是:')
print(a)
print()
print('调用amin()函数:')
print(np.amin(a, 1)) # 横向对比,获得最小值
print()
print('再次调用amin()函数:')
print(np.amin(a, 0)) # 纵向对比,获得最小值
print()
print('调用amax()函数:')
print(np.amax(a))
print()
print('再次调用amax()函数:')
print(np.amax(a, axis=0)) # 纵向对比
运行结果如下:
我们的数组是:
[[3 7 5]
[8 4 3]
[2 4 9]]
调用amin()函数:
[3 3 2]
再次调用amin()函数:
[2 4 3]
调用amax()函数:
9
再次调用amax()函数:
[8 7 9]
2. numpy.ptp()(最大值-最小值)
import numpy as np
a = np.array([[3, 7, 5], [8, 4, 3], [2, 4, 9]])
print('我们的数组是:')
print(a)
print()
print('调用ptp()函数:')
print(np.ptp(a))
print()
print('沿轴1调用ptp()函数:')
print(np.ptp(a, axis=1))
print()
print('沿轴0调用ptp()函数:')
print(np.ptp(a,axis=0))
运行结果如下:
我们的数组是:
[[3 7 5]
[8 4 3]
[2 4 9]]
调用ptp()函数:
7
沿轴1调用ptp()函数:
[4 5 7]
沿轴0调用ptp()函数:
[6 3 6]
3. numpy.percentile() 百分位数
- 百分位数是统计中使用的度量,表示小于这个值的观察值的百分比。
- 函数numpy.percentile()接受以下参数:
numpy.percentile(a, q, axis)
# a:输入数组。
# q:要计算的百分位数,在0~100之间。
# axis:沿着它计算百分位数的轴。
首先明确百分位数
- 第p个百分位数是这样一个值,它使得至少有p%的数据项小于等于这个值,且至少有(100-p)%的数据项大于或等于这个值。
- 举个例子:高等院校的入学考试成绩经常以百分位数的形式报告。比如,假设某个考生在入学考试中的语文部分的原始分数为54分。相对于参加同一考试的其他学生来说,他的成绩如何并不容易知道。但是如果原始分数54分恰好对应的是第70百分位数,我们就能知道大约70%的学生的考分比他低,而约30%的学生考分比他高。
- 这里的p=70。
import numpy as np
a = np.array([[10, 7, 4], [3, 2, 1]])
print('我们的数组是:')
print(a)
print('调用percentile()函数:')
# 50%的分位数,就是a里排序之后的中位数。
print(np.percentile(a, 50))
# axis为0,在纵列上求
print(np.percentile(a, 50, axis=0))
# axis为1,在横行上求
print(np.percentile(a, 50, axis=1))
# 保持维度不变
print(np.percentile(a, 50, axis=1, keepdims=True))
运行结果:
我们的数组是:
[[10 7 4]
[ 3 2 1]]
调用percentile()函数:
3.5
[6.5 4.5 2.5]
[7. 2.]
[[7.]
[2.]]
4. numpy.median() 中位数
- numpy.median()函数用于计算数组a中元素的中位数(中值)。
import numpy as np
a = np.array([[30, 65, 70], [80, 95, 10], [50, 90, 60]])
print('我们的数组是:')
print(a)
print()
print('调用median()函数:')
print(np.median(a))
print()
print('沿轴0调用median()函数:')
print(np.median(a, axis=0))
print()
print('沿轴1调用median()函数:')
print(np.median(a, axis=1))
运行结果如下:
我们的数组是:
[[30 65 70]
[80 95 10]
[50 90 60]]
调用median()函数:
65.0
沿轴0调用median()函数:
[50. 90. 60.]
沿轴1调用median()函数:
[65. 80. 60.]
5. numpy.mean() 算术平均值
- numpy.mean()函数返回数组中元素的算术平均值。
- 如果提供了轴,则沿其计算。
- 算术平均值是沿轴的元素的总和除以元素的数量。
import numpy as np
a = np.array([[1, 2, 3], [3, 4, 5], [4, 5, 6]])
print('我们的数组是:')
print(a)
print()
print('调用mean()函数:')
print(np.mean(a))
print()
print('沿轴0调用mean()函数:')
print(np.mean(a, axis=0)) # 纵向对比
print()
print('沿轴1调用mean()函数:')
print(np.mean(a, axis=1)) # 横向对比
运行结果如下:
我们的数组是:
[[1 2 3]
[3 4 5]
[4 5 6]]
调用mean()函数:
3.6666666666666665
沿轴0调用mean()函数:
[2.66666667 3.66666667 4.66666667]
沿轴1调用mean()函数:
[2. 4. 5.]
6. numpy.average() 加权平均值
- numpy.average()函数根据在另一个数组中给出的各自的权重计算数组中元素的加权平均值。
- 该函数可以接受一个轴参数。如果没有指定轴,则数组会被展开。
- 加权平均值即将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数。
- 考虑数组[1, 2, 3, 4]和相应的权重[4, 3, 2, 1],通过将相应元素的乘积相加,并将和除以权重的和,来计算加权平均值。
加权平均值 = (1*4 + 2*3 + 3*2 + 4*1) / (4 + 3 + 2 + 1)
import numpy as np
a = np.array([1, 2, 3, 4])
print('我们的数组是:')
print(a)
print()
print('调用average()函数:')
print(np.average(a))
print()
# 不指定权重时相当于mean()函数
wts = np.array([4, 3, 2, 1])
print('再次调用average()函数:')
print(np.average(a, weights=wts))
print()
# 如果returned参数设置为True,则返回权重的和
print('权重的和:')
print(np.average([1, 2, 3, 4], weights=[4, 3, 2, 1], returned=True))
运行结果如下:
我们的数组是:
[1 2 3 4]
调用average()函数:
2.5
再次调用average()函数:
2.0
权重的和:
(2.0, 10.0)
在多维数组中,可以指定用于计算的轴:
import numpy as np
a = np.arange(6).reshape(3, 2) # 3行2列
print('我们的数组是:')
print(a)
print()
print('修改后的数组:')
wt = np.array([3, 5])
print(np.average(a, axis=1, weights=wt)) # axis=1表示按行
print()
print('修改后的数组:')
print(np.average(a, axis=1, weights=wt, returned=True))
运行结果如下:
我们的数组是:
[[0 1]
[2 3]
[4 5]]
修改后的数组:
[0.625 2.625 4.625]
修改后的数组:
(array([0.625, 2.625, 4.625]), array([8., 8., 8.]))
7. 标准差
- 标准差是一组数据平均值分散程度的一种度量。
- 标准差是方差的算术平方根。
- 标准差的公式如下:
std = sqrt(mean(x - x.mean())**2)
- 如果数组是[1, 2, 3, 4],则其平均值为2.5。因此,差的平方是[2.25, 0.25, 0.25, 2.25],并且再求其平均值的平方根除以4,即sqrt(5/4),结果为1.1180339887498949。
import numpy as np
print(np.std([1, 2, 3, 4]))
输出结果为:
1.118033988749895
8. 方差
- 统计中的方差(样本方差),是每个样本值与全体样本值的平均数之差的平方值的平均数,即mean((x - x.mean()) ** 2)。
- 换句话说,标准差是方差的平方根。
import numpy as np
print(np.var([1, 2, 3, 4]))
运行结果如下:
1.25
17. 排序、条件刷选函数
- numpy提供了多种排序方法。这些排序函数实现不同的排序算法,每个排序算法的特征在于执行速度、最坏情况性能、所需的工作空间、算法的稳定性。
- 下表显示了三种排序算法的比较:
| 种类 | 速度 | 最坏情况 | 工作空间 | 稳定性 |
|---|---|---|---|---|
| ‘quicksort’(快速排序) | 1 | O( n2 ) | 0 | 否 |
| ‘mergesort’(归并排序) | 2 | O(n*log(n)) | ~n/2 | 是 |
| ‘heapsort’(堆排序) | 3 | O(n*log(n)) | 0 | 否 |
1. numpy.sort() 默认为快速排序
- numpy.sort()函数返回输入数组的排序副本。
- 函数格式如下:
numpy.sort(a, axis, kind, order)
# a:要排序的数组。
# axis:沿着它排序数组的轴,如果没有设置该值,数组会被展开,沿着最后的轴排序,axis=0按列排序,axis=1按行排序。
# kind:默认为‘quicksort’(快速排序)。
# order:如果数组包含字段,则是要排序的字段。
import numpy as np
a = np.array([[3, 7], [9, 1]])
print('我们的数组是:')
print(a)
print()
print('调用sort()函数:')
print(np.sort(a))
print()
print('按列排序:')
print(np.sort(a, axis=0))
print()
# 在sort函数中排序字段
dt = np.dtype([('name', 'S10'), ('age', int)])
a = np.array([("raju", 21), ("ani1", 25), ("rav", 17), ("amar", 27)], dtype=dt)
print('我们的数组是:')
print(a)
print()
print('按name排序:')
print(np.sort(a, order='name'))
print()
print('按age排序:')
print(np.sort(a, order='age'))
运行结果为:
我们的数组是:
[[3 7]
[9 1]]
调用sort()函数:
[[3 7]
[1 9]]
按列排序:
[[3 1]
[9 7]]
我们的数组是:
[(b'raju', 21) (b'ani1', 25) (b'rav', 17) (b'amar', 27)]
按name排序:
[(b'amar', 27) (b'ani1', 25) (b'raju', 21) (b'rav', 17)]
按age排序:
[(b'rav', 17) (b'raju', 21) (b'ani1', 25) (b'amar', 27)]
2. numpy.argsort() 返回排序索引
- numpy.argsort()函数返回的是数组值从小到大的索引值。
import numpy as np
x = np.array([3, 1, 2])
print('我们的数组是:')
print(x)
print()
print('对x调用argsort()函数:')
y = np.argsort(x)
print(y)
print()
print('以排序后的顺序重构原数组:')
print(x[y])
print()
print('使用循环重构原数组:')
for i in y:
print(x[i], end=" ")
运行结果如下:
我们的数组是:
[3 1 2]
对x调用argsort()函数:
[1 2 0]
以排序后的顺序重构原数组:
[1 2 3]
使用循环重构原数组:
1 2 3
3. numpy.lexsort() 多个序列排序
- numpy.lexsort()用于对多个序列进行排序。把它想象成对电子表格进行排序,每一列代表一个序列,排序时优先照顾靠后的列。
- 这里举一个应用场景:小升初考试,重点班录取学生按照总成绩录取。在总成绩相同时,数学成绩高的优先录取,在总成绩和数学成绩都相同时,按照英语成绩录取…这里,总成绩排在电子表格的最后一列,数学成绩在倒数第二列,英语成绩排在倒数第三列。
import numpy as np
nm = ('raju', 'anil', 'ravi', 'amar')
dv = ('f.y.', 's.y.', 's.y.', 'f.y.')
ind = np.lexsort((dv, nm))
print('调用lexsort()函数:')
print(ind)
print()
print('使用这个索引来获取排序后的数据:')
print([nm[i] + ", " + dv[i] for i in ind])
运行结果如下:
调用lexsort()函数:
[3 1 0 2]
使用这个索引来获取排序后的数据:
['amar, f.y.', 'anil, s.y.', 'raju, f.y.', 'ravi, s.y.']
- 上面传入numpy.lexsort()的是一个元组,排序时首先排nm,顺序为:amar、anil、raju、ravi。综上排序索引结果为[3 1 0 2]。
4. msort()、sort_complex()、partition()、argpartition()
| 函数 | 描述 |
|---|---|
| msort(a) | 数组按第一个轴(按列)排序,返回排序后的数组副本。np.msort(a)相当于np.sort(a, axis=0) |
| sort_complex(a) | 对复数按照先实部后虚部的顺序进行排序。 |
| partition(a, kth[, axis, kind, order]) | 指定一个数,对数组进行分区。 |
| argpartition(a, kth[, axis, kind, order]) | 可以通过关键字kind指定算法沿着指定轴对数组进行分区。 |
1. 复数排序
import numpy as np
print('只有实部的复数排序:')
print(np.sort_complex([5, 4, 3, 2, 1]))
print('实部和虚部均有的复数排序:')
print(np.sort_complex([1+2j, 2-1j, 3-2j, 3-3j, 3+5j]))
运行结果:
只有实部的复数排序:
[1.+0.j 2.+0.j 3.+0.j 4.+0.j 5.+0.j]
实部和虚部均有的复数排序:
[1.+2.j 2.-1.j 3.-3.j 3.-2.j 3.+5.j]
2. partition()分区排序
import numpy as np
a = np.array([3, 4, 2, 1])
# 将数组a中所有元素(包括重复元素)从小到大排列,3表示的是排序数组索引为3的数字,比该数字小的排在该数字前面,比该数字大的排在该数字的后面
print(np.partition(a, 3))
# 小于1的在前面,大于3的在后面,1和3之间的在中间。
print(np.partition(a, (1, 3)))
运行结果如下:
[2 1 3 4]
[1 2 3 4]
3. 找到数组的第3小(index=2)的值和第2大(index=-2)的值
import numpy as np
arr = np.array([46, 57, 23, 39, 1, 10, 0, 120])
print('数组的所有值:')
print(arr)
print('第3小的值:')
print(arr[np.argpartition(arr, 2)[2]])
print('第2大的值:')
print(arr[np.argpartition(arr, -2)[-2]])
运行结果如下:
数组的所有值:
[ 46 57 23 39 1 10 0 120]
第3小的值:
10
第2大的值:
120
4. 同时找到第3和第4小的值
- 注意:这里用[2, 3]同时将第3和第4小的排序好,然后可以分别通过下标[2]和[3]取得。
import numpy as np
arr = np.array([46, 57, 23, 39, 1, 10, 0, 120])
print('数组的所有值:')
print(arr)
print('数组中第3小的值:')
print(arr[np.argpartition(arr, [2, 3])[2]])
print('数组中第4小的值:')
print(arr[np.argpartition(arr, [2, 3])[3]])
运行结果:
数组的所有值:
[ 46 57 23 39 1 10 0 120]
数组中第3小的值:
10
数组中第4小的值:
23
5. numpy.argmax()和numpy.argmin()最小最大元素索引
- numpy.argmax()和numpy.argmin()函数分别沿给定轴返回最大和最小元素的索引。
import numpy as np
a = np.array([[30, 40, 70], [80, 20, 10], [50, 90, 60]])
print('我们的数组是:')
print(a)
print()
print('调用argmax()函数:')
print(np.argmax(a))
print()
print('展开数组:')
print(a.flatten())
print()
print('沿轴0的最大值索引:')
maxindex = np.argmax(a, axis=0) # 以列为轴
print(maxindex)
print()
print('沿轴1的最大值索引:')
maxindex = np.argmax(a, axis=1) # 以行为轴
print(maxindex)
print()
print('调用argmin()函数:')
minindex = np.argmin(a)
print(minindex)
print()
print('展开数组中的最小值:')
print(a.flatten()[minindex])
print()
print('沿轴0的最小值索引:')
minindex = np.argmin(a, axis=0)
print(minindex)
print()
print('沿轴1的最小值索引:')
minindex = np.argmin(a, axis=1)
print(minindex)
运行结果如下:
我们的数组是:
[[30 40 70]
[80 20 10]
[50 90 60]]
调用argmax()函数:
7
展开数组:
[30 40 70 80 20 10 50 90 60]
沿轴0的最大值索引:
[1 2 0]
沿轴1的最大值索引:
[2 0 1]
调用argmin()函数:
5
展开数组中的最小值:
10
沿轴0的最小值索引:
[0 1 1]
沿轴1的最小值索引:
[0 2 0]
6. numpy.nonzero() 返回非零元素索引
- numpy.nonzero()函数返回输入数组中非零元素的索引。
import numpy as np
a = np.array([[30, 40, 0], [0, 20, 10], [50, 0, 60]])
print('我们的数组是:')
print(a)
print()
print('调用nonzero()函数:')
print(np.nonzero(a)) # 返回的前一个数组为行索引,后一个数组为列索引
运行结果如下:
我们的数组是:
[[30 40 0]
[ 0 20 10]
[50 0 60]]
调用nonzero()函数:
(array([0, 0, 1, 1, 2, 2], dtype=int64), array([0, 1, 1, 2, 0, 2], dtype=int64))
7. numpy.where() 返回满足给定条件的元素的索引
- numpy.where()函数返回输入数组中满足给定条件的元素的索引。
import numpy as np
x = np.arange(9.).reshape(3, 3)
print('我们的数组是:')
print(x)
print('大于3的元素的索引:')
y = np.where(x > 3)
print(y)
print('使用这些索引来获取满足条件的元素:')
print(x[y])
运行结果:
我们的数组是:
[[0. 1. 2.]
[3. 4. 5.]
[6. 7. 8.]]
大于3的元素的索引:
(array([1, 1, 2, 2, 2], dtype=int64), array([1, 2, 0, 1, 2], dtype=int64))
使用这些索引来获取满足条件的元素:
[4. 5. 6. 7. 8.]
8. numpy.extract()
- numpy.extract()函数根据某个条件从数组中抽取元素,返回满足条件的元素。
import numpy as np
x = np.arange(9.).reshape(3, 3)
print('我们的数组是:')
print(x)
# 定义条件,选择偶数元素。
condition = np.mod(x, 2) == 0
print('按元素的条件值:')
print(condition)
print('使用条件提取元素:')
print(np.extract(condition, x))
运行结果:
我们的数组是:
[[0. 1. 2.]
[3. 4. 5.]
[6. 7. 8.]]
按元素的条件值:
[[ True False True]
[False True False]
[ True False True]]
使用条件提取元素:
[0. 2. 4. 6. 8.]
18. 字节交换
几乎在所有的机器上,多字节对象都被存储为连续的字节序列。字节顺序,是跨越多字节的程序对象的存储规则。
1. 大端模式
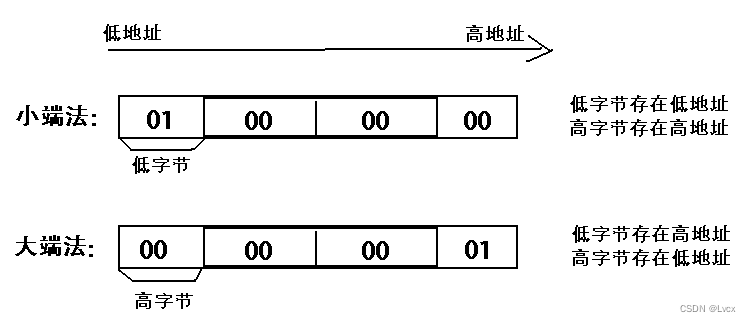
- 指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
2. 小端模式
- 指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。
例如在C语言中,一个类型为int的变量x的地址为0x100,那么其对应地址表达式&x的值为0x100。且x的四个字节将被存储在存储器的0x100、0x101、0x102、0x103位置。
3. numpy.ndarray.byteswap() 将每个元素中的字节进行大小端转换
- numpy.ndarray.byteswap()函数将ndarray中每个元素中的字节进行大小端转换。
1. 示例一
import numpy as np
a = np.array([1, 256, 8755], dtype=np.int16)
print('我们的数组是:')
print(a)
print('以十六进制表示内存中的数据:')
print(map(hex, a))
# byteswap()函数通过传入True来原地交换
print('调用byteswap()函数:')
print(a.byteswap(True))
print('十六进制形式:')
print(map(hex, a))
# 我们可以看到字节已经交换了
运行结果:
我们的数组是:
[ 1 256 8755]
以十六进制表示内存中的数据:
<map object at 0x0000023F6E84E370>
调用byteswap()函数:
[ 256 1 13090]
十六进制形式:
<map object at 0x0000023F6E168130>
2. 示例二
import numpy as np
A = np.array([1, 256, 8755], dtype=np.int16)
print(A)
print(list(map(hex, A)))
print(A.byteswap(inplace=True))
print(list(map(hex, A)))
运行结果:
[ 1 256 8755]
['0x1', '0x100', '0x2233']
[ 256 1 13090]
['0x100 ', '0x1', '0x3322']
- 可以看到对于数组中每个元素,都是np.int16类型,故有2个字节,可以发现高字节与低字节发生调换。
19. 副本和视图
- 副本是一个数据的完整拷贝,如果我们对副本进行修改,它不会影响到原始数据,物理内存不在同一位置。
- 视图是数据的一个别称或引用,通过该别称或引用就可以访问、操作原有数据,但原有数据不会产生拷贝。如果我们对视图进行修改,它会影响到原始数据,物理内存在同一位置。
视图一般发生在
- numpy的切片操作返回原数据的视图。
- 调用ndarray的view()函数产生一个视图。
副本一般发生在
- Python序列的切片操作,调用deepCopy()函数。
- 调用ndarray的copy()函数产生一个副本。
1. 无复制
- 简单的赋值不会创建数组对象的副本。相反,它使用原始数组的相同id()来访问它。id()返回Python对象的通用标识符,类似于C语言中的指针。
- 此外,一个数组的任何变化都反映在另一个数组上。例如,一个数组的形状改变也会改变另一个数组的形状。
import numpy as np
a = np.arange(6)
print('我们的数组是:')
print(a)
print('调用id()函数:')
print(id(a))
print('a赋值给b:')
b = a
print(b)
print('b拥有相同的id():')
print(id(b))
print('修改b的形状:')
b.shape = 3, 2
print(b)
print('a的形状也修改了:')
print(a)
运行结果如下:
我们的数组是:
[0 1 2 3 4 5]
调用id()函数:
1860028360048
a赋值给b:
[0 1 2 3 4 5]
b拥有相同的id():
1860028360048
修改b的形状:
[[0 1]
[2 3]
[4 5]]
a的形状也修改了:
[[0 1]
[2 3]
[4 5]]
2. 视图或浅拷贝
1. ndarray.view()函数创建新数组(不影响原数组)
- ndarray.view()函数会创建一个新的数组对象,该方法创建的新数组的维数变化不会改变原始数据的维数。
import numpy as np
a = np.arange(6).reshape(3, 2)
print('数组 a:')
print(a)
print('创建a的视图——b:')
b = a.view()
print(b)
print('两个数组的id()不同:')
print('a的id():')
print(id(a))
print('b的id():')
print(id(b))
# 修改b的形状,不会修改a
b.shape = 2, 3
print('b的形状:')
print(b)
print('a的形状:')
print(a)
运行结果如下:
数组 a:
[[0 1]
[2 3]
[4 5]]
创建a的视图——b:
[[0 1]
[2 3]
[4 5]]
两个数组的id()不同:
a的id():
3046205964528
b的id():
3046205964624
b的形状:
[[0 1 2]
[3 4 5]]
a的形状:
[[0 1]
[2 3]
[4 5]]
2. 使用切片创建视图(会影响原数组)
- 使用切片创建视图修改数据会影响到原始数组。
import numpy as np
arr = np.arange(12)
print('我们的数组:')
print(arr)
print('创建切片:')
a = arr[3:]
b = arr[3:]
a[1] = 123
b[2] = 234
print(arr)
print(id(a), id(b), id(arr[3:]))
运行结果如下:
我们的数组:
[ 0 1 2 3 4 5 6 7 8 9 10 11]
创建切片:
[ 0 1 2 3 123 234 6 7 8 9 10 11]
1996649752016 1996649751920 1996649456528
- 变量a、b都是arr的一部分视图,对视图的修改会直接反映到原数据中。但是我们观察a、b的id,它们是不同的,也就是说,视图虽然指向原数据,但他们和赋值引用还是有区别的。
3. 副本或深拷贝
- ndarray.copy()函数创建一个副本。对副本数据进行修改,不会影响到原始数据,它们的物理内存不在同一位置。
import numpy as np
a = np.array([[10, 10], [2, 3], [4, 5]])
print('数组 a:')
print(a)
print('创建a的深层副本:')
b = a.copy()
print('数组b:')
print(b)
# b与a不共享任何内容
print('我们能够写入b来写入a吗?')
print(b is a)
print('修改b的内容:')
b[0, 0] = 100
print('修改后的数组b:')
print(b)
print('a保持不变:')
print(a)
运行结果如下:
数组 a:
[[10 10]
[ 2 3]
[ 4 5]]
创建a的深层副本:
数组b:
[[10 10]
[ 2 3]
[ 4 5]]
我们能够写入b来写入a吗?
False
修改b的内容:
修改后的数组b:
[[100 10]
[ 2 3]
[ 4 5]]
a保持不变:
[[10 10]
[ 2 3]
[ 4 5]]
4. append()与深拷贝和浅拷贝
- 在Python中,对象赋值实际上是对象的引用。当创建一个对象,然后把它赋给另一个变量的时候,Python并没有拷贝这个对象,而只是拷贝了这个对象的引用,我们称之为浅拷贝。
- 在Python中,为了使当前进行赋值操作时,两个变量互不影响,可以使用copy模块中的deepcopy()方法,称之为深拷贝。
append()函数
- 当list类型的对象进行append操作时,实际上追加的是该对象的引用。
- id()函数:返回对象的唯一标识,可以类比成该对象在内存中的地址。
alist = []
num = [2]
alist.append(num)
print('alist:')
print(alist)
print()
print(num)
print(id(num) == id(alist[0]))
运行结果如下:
alist:
[[2]]
[2]
True
- 如上例所示,当num发生变化时(前提是id(num)不发生变化),alist的内容随之会发 生变化。
- 这样往往会带来意想不到的后果,想避免这种情况,可以采用深拷贝解决:
alist.append(copy.deepcopy(num))
20. 矩阵库(Matrix)
- numpy中包含了一个矩阵库numpy.matlib,该模块中的函数返回的是一个矩阵,而不是ndarray对象。
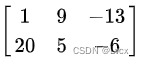
- 一个mxn的矩阵是一个由m行(row)n列(column)元素排列组成的矩形阵列。
- 矩阵里的元素可以是数字、符号或数学式。以下是一个由6个数字元素构成的2行3列的矩阵:
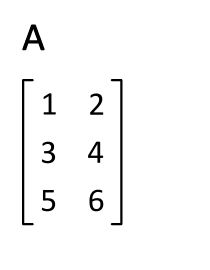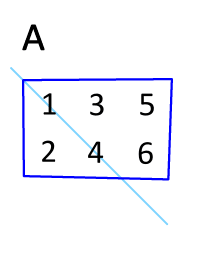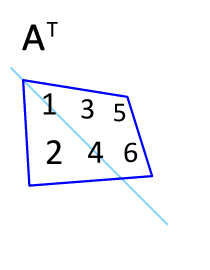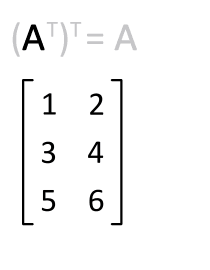
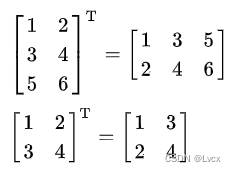
1. 转置矩阵
- Numpy中除了可以使用numpy.transpose()函数来对换数组的维度,还可以使用T属性。
- 例如,有个m行n列的矩阵,使用t()函数就能转换为n行m列的矩阵。
import numpy as np
a = np.arange(12).reshape(3, 4)
print('原数组:')
print(a)
print()
print('转置数组:')
print(a.T)
运行结果如下:
原数组:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
转置数组:
[[ 0 4 8]
[ 1 5 9]
[ 2 6 10]
[ 3 7 11]]
2. numpy.matlib.empty()返回随机填充矩阵
- numpy.matlib.empty()函数返回一个新的矩阵,语法格式为:
numpy.matlib.empty(shape, dtype, order)
# shape:定义新矩阵形状的整数或整数元组。
# dtype:可选参数,数据类型。
# order:C为行序优先,F为列序优先。
import numpy as np
import numpy.matlib
print(np.matlib.empty((2, 2))) # 填充为随机数据
运行结果如下:
[[1.1259614e-311 1.1259614e-311]
[1.1259614e-311 1.1259614e-311]]
3. numpy.matlib.zeros() 创建以0填充的矩阵
- numpy.matlib.zeros()函数创建一个以0填充的矩阵。
import numpy.matlib
import numpy as np
print(np.matlib.zeros((2, 2)))
运行结果如下:
[[0. 0.]
[0. 0.]]
4. numpy.matlib.ones()创建以1填充的矩阵
- numpy.matlib.ones()函数创建一个以1填充的矩阵。
import numpy.matlib
import numpy as np
print(np.matlib.ones((2, 2)))
运行结果如下:
[[1. 1.]
[1. 1.]]
5. numpy.matlib.eye() 创建对角线上为1的矩阵
- numpy.matlib.eye()函数返回一个矩阵,对角线元素为1,其他位置为零。
numpy.matlib.eye(n, M, k, dtype)
# n:返回矩阵的行数。
# M:返回矩阵的列数,默认为n。
# k:对角线的索引。
# dtype:数据类型。
import numpy as np
import numpy.matlib
print(np.matlib.eye(n=3, M=4, k=0, dtype=float))
运行结果如下:
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]]
6. numpy.matlib.identity() 创建单位矩阵
- numpy.matlib.identity()函数返回给定大小的单位矩阵。
- 单位矩阵是个方阵,从左上角到右下角的对角线(称为主对角线)上的元素均为1,初次之外全都为0。
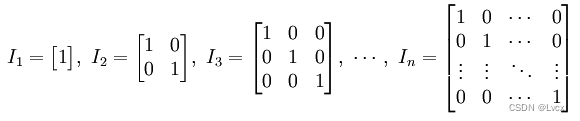
import numpy as np
import numpy.matlib
# 大小为5,类型为浮点型
print(np.matlib.identity(5, dtype=float))
运行结果如下:
[[1. 0. 0. 0. 0.]
[0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1.]]
7. numpy.matlib.rand() 创建随机填充矩阵
1. numpy.matlib.rand()
- numpy.matlib.rand()函数创建一个给定大小的矩阵,数据是随机填充的。
import numpy.matlib
import numpy as np
print(np.matlib.rand(3, 3))
运行结果如下:
[[0.1592812 0.62829692 0.13857603]
[0.73422539 0.92199863 0.37758507]
[0.58057287 0.85725645 0.71712612]]
2. numpy.matrix()创建矩阵
- 矩阵总是二维的,而ndarray是一个n维数组。两个对象都是可互换的。
import numpy as np
import numpy.matlib
i = np.matrix('1, 2; 3, 4')
print(i)
运行结果如下:
[[1 2]
[3 4]]
3. 利用numpy.asarray()将矩阵转换为数组
import numpy as np
import numpy.matlib
i = np.matrix('1, 2; 3, 4')
j = np.asarray(i)
print(j)
运行结果如下:
[[1 2]
[3 4]]
4. 利用numpy.asmatrix()将数组转换为矩阵
import numpy as np
import numpy.matlib
i = np.matrix('1, 2; 3, 4')
j = np.asarray(i)
k = np.asmatrix(j)
print(k)
运行结果如下:
[[1 2]
[3 4]]
21. 线性代数
- Numpy提供了线性代数函数库linalg,该库包含了线性代数所需要的所有功能,说明如下:
| 函数 | 描述 |
|---|---|
| dot() | 两个数组的点积,即元素对应相乘。 |
| vdot() | 两个向量的点积。 |
| inner() | 两个数组的内积。 |
| matmul() | 两个数组的矩阵积。 |
| determinant() | 数组的行列式。 |
| solve() | 求解线性矩阵方程。 |
| inv() | 计算矩阵的乘法逆矩阵。 |
1. numpy.dot()
- numpy.dot()对于两个一维的数组,计算的是这两个数组对应下标元素的乘积和(数学上称之为内积);对于二维数组,计算的是两个数组的矩阵乘积;对于多维数组,它的通用计算公式如下,即结果数组中的每个元素都是:数组a的最后一维上的所有元素与数组b的倒数第二位上的所有元素的乘积和:
dot(a, b)[i, j, k, m] = sum(a[i, j, :] * b[k, :, m])
numpy.dot(a, b, out=None)
# a:ndarray数组。
# b:ndarray数组。
# out:ndarray,可选参数,用来保存dot()的计算结果。
import numpy.matlib
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = np.array([[11, 12], [13, 14]])
print(np.dot(a, b))
运行结果如下:
[[37 40]
[85 92]]
计算式为:
[[1*11+2*13, 1*12+2*14], [3*11+4*12, 3*13+4*14]]
2. numpy.vdot()
- numpy.vdot()函数是两个向量的点积。如果第一个参数是复数,那么它的共轭复数会用于计算。如果参数是多维数组,它会被展开。
import numpy as np
a = np.array([[1, 2], [3, 4]])
b = np.array([[11, 12], [13, 14]])
# vdot()将数组展开计算内积
print(np.vdot(a, b))
运行结果如下:
130
计算式为:
1*11 + 2*12 + 3*13 +4*14 = 130
3. numpy.inner()
- numpy.inner()函数返回一维数组的向量内积。对于更高的维度,它返回最后一个轴上的和的乘积。
1. 针对一维数组
import numpy as np
print(np.inner(np.array([1, 2, 3]), np.array([0, 1, 0])))
# 等价于 1*0+2*1+3*0
运行结果如下:
2
2. 针对多维数组
import numpy as np
a = np.array([[1, 2], [3, 4]])
print('数组 a:')
print(a)
b = np.array([[11, 12], [13, 14]])
print('数组b:')
print(b)
print('内积:')
print(np.inner(a, b))
运行结果如下:
数组 a:
[[1 2]
[3 4]]
数组b:
[[11 12]
[13 14]]
内积:
[[35 41]
[81 95]]
内积计算式为:
1*11 + 2*12 , 1*13 + 2*14
3*11 + 4*12 , 3*13 + 4*14
4. numpy.matnul()
- numpy.matmul()函数返回两个数组的矩阵乘积。虽然它返回二维数组的正常乘积,但如果任一参数的维度大于2,则将其视为存在于最后两个索引的矩阵的栈,并进行相应广播。
- 另一方面,如果任一参数是一维数组,则通过在其维度上附加1来将其提升为矩阵,并在乘法之后被去除。
1. 对于二维数组,它就是矩阵乘法:
import numpy as np
a = [[1, 0], [0, 1]]
b = [[4, 1], [2, 2]]
print(np.matmul(a, b))
运行结果:
[[4 1]
[2 2]]
2. 二维和一维运算:
import numpy.matlib
import numpy as np
a = [[1, 0], [0, 1]]
b = [1, 2]
print(np.matmul(a, b))
print(np.matmul(b, a))
运行结果如下:
[1 2]
[1 2]
3. 维度大于二的数组:
import numpy.matlib
import numpy as np
a = np.arange(8).reshape(2, 2, 2)
b = np.arange(4).reshape(2, 2)
print(np.matmul(a, b))
输出结果为:
[[[ 2 3]
[ 6 11]]
[[10 19]
[14 27]]]
5. numpy.linalg.det()
- numpy.linalg.det()函数计算输入矩阵的a行列式。
- 行列式在线性代数中是非常有用的值。它从方阵的对角元素计算。对于2 x 2矩阵,它是左上和右下元素的乘积与其他两个的乘积的差。
- 换句话说,对于矩阵[[a, b], [c, d]],行列式计算为ad-bc。较大的方阵被认为是2 x 2矩阵的组合。
1. 示例一
import numpy as np
a = np.array([[1, 2], [3, 4]])
print(np.linalg.det(a))
输出的结果为:
-2.0000000000000004
2. 示例二
import numpy as np
b = np.array([[6, 1, 1], [4, -2, 5], [2, 8, 7]])
print(b)
print(np.linalg.det(b))
print(6*(-2*7 - 5*8) - 1*(4*7 - 5*2) + 1*(4*8 - -2*2))
输出结果为:
[[ 6 1 1]
[ 4 -2 5]
[ 2 8 7]]
-306.0
-306
6. numpy.linalg.solve()
- numpy.linalg.solve()函数给出了矩阵形式的线性方程的解。
考虑以下线性方程:
x + y + z = 6
2y + 5z = -4
2x + 5y -z = 27
可以使用矩阵表示为:
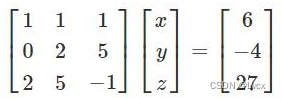
如果矩阵称为A、X和B,方程变为:
AX=B
或
X=A(-1)B
7. numpy.linalg.inv()
- numpy.linalg.inv()函数计算矩阵的乘法逆矩阵。
- 逆矩阵(inverse matrix):设A是数域上的一个n阶矩阵,若在相同数域上存在另一个n阶矩阵B,使得:AB= BA=E,则我们称B是A的逆矩阵,而A则被称为可逆矩阵。注:E为单位矩阵。
import numpy as np
x = np.array([[1, 2], [3, 4]])
y = np.linalg.inv(x)
print(x)
print(y)
print(np.dot(x, y))
运行结果:
[[1 2]
[3 4]]
[[-2. 1. ]
[ 1.5 -0.5]]
[[1.0000000e+00 0.0000000e+00]
[8.8817842e-16 1.0000000e+00]]
现在创建一个矩阵A的逆矩阵:
import numpy as np
a = np.array([[1, 1, 1], [0, 2, 5], [2, 5, -1]])
print('数组a:')
print(a)
ainv = np.linalg.inv(a)
print('a的逆矩阵:')
print(ainv)
print('矩阵 b:')
b = np.array([[6], [-4], [27]])
print(b)
print('计算:A^(-1)B:')
x = np.linalg.solve(a, b)
print(x)
# 这就是线性方向x = 5, y = 3, z = -2的解
运行结果如下:
数组a:
[[ 1 1 1]
[ 0 2 5]
[ 2 5 -1]]
a的逆矩阵:
[[ 1.28571429 -0.28571429 -0.14285714]
[-0.47619048 0.14285714 0.23809524]
[ 0.19047619 0.14285714 -0.0952381 ]]
矩阵 b:
[[ 6]
[-4]
[27]]
计算:A^(-1)B:
[[ 5.]
[ 3.]
[-2.]]
结果也可以用以下函数获取:
x = np.dot(ainv, b)
结果如下:
[[ 5.]
[ 3.]
[-2.]]
22. IO
- numpy可以读写磁盘上的文本数据或二进制数据。
- numpy为ndarray对象引入了一个简单的文件格式:npy。
- npy文件用于存储重建ndarray所需的数据、图形、dtype和其他信息。
- 常用的IO函数有:
- load()和save()函数是读写文件数组数据的两个主要函数,默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为.npy的文件中。
- savez()函数用于将多个数组写入文件,默认情况下,数组是以未压缩的原始二进制格式保存在扩展名为.npz的文件中。
- loadtxt()和savetxt()函数处理正常的文本文件(txt等)。
1. numpy.save()
- numpy.save()函数将数组保存到以.npy为扩展名的文件中。
numpy.save(file, arr, allow_pickle=True, fix_imports=True)
# file:要保存的文件,扩展名为.npy,如果文件路径末尾没有扩展名.npy,该扩展名会被自动加上。
# arr:要保存的数组。
# allow_pickle:可选参数,布尔值,允许使用Python pickles保存对象数组,Python中的pickle用于在保存到磁盘文件或从磁盘文件读取之前,对对象进行序列化和反序列化。
# fix_imports:可选参数,为了方便Python2中读取Python3保存的数据。
import numpy as np
a = np.array([1, 2, 3, 4, 5])
# 保存到outfile.npy文件上
np.save('outfile.npy', a)
# 保存到outfile2.npy文件上,如果文件路径末尾没有扩展名.npy,该扩展名会被自动加上
np.save('outfile2', a)
在Windows中查看文件内容使用命令:type filename(类似于Linux中的cat命令)
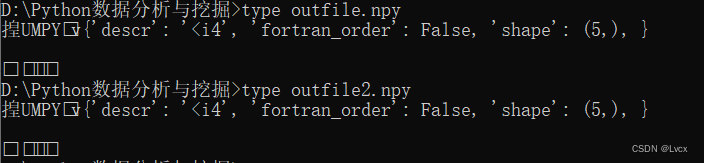
- 可以看出文件是乱码的,因为它们是Numpy专用的二进制格式后的数据。
- 我们可以使用load()函数来读取数据就可以正常显示了。
import numpy as np
b = np.load('outfile.npy')
print(b)
运行结果如下:
[1 2 3 4 5]
2. numpy.savez()
- numpy.savez()函数将多个数组保存到以npz为扩展名的文件中。
numpy.savez(file, *args, **kwds)
# file:要保存的文件,扩展名为.npz,如果文件路径末尾没有扩展名.npz,该扩展名会被自动加上。
# args:要保存的数组,可以使用关键字参数为数组起一个名字,非关键字参数传递的数组会自动起名为arr_0,arr_1,...。
# kwds:要保存的数组使用关键字名称。
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.arange(0, 1.0, 0.1)
c = np.sin(b)
# c使用了关键字参数sin_array
np.savez("runoob.npz", a, b, sin_array=c)
r = np.load('runoob.npz')
print(r.files) # 查看各个数组名称
print(r["arr_0"]) # 数组a
print(r["arr_1"]) # 数组b
print(r["sin_array"]) # 数组c
运行结果如下:
['sin_array', 'arr_0', 'arr_1']
[[1 2 3]
[4 5 6]]
[0. 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9]
[0. 0.09983342 0.19866933 0.29552021 0.38941834 0.47942554
0.56464247 0.64421769 0.71735609 0.78332691]
3. numpy.savetxt()
- savetxt()函数是以简单的文本文件格式存储数据,对应的使用loadtxt()函数来获取数据。
np.loadtxt(FILENAME, dtype=int, delimiter='')
np.savetxt(FILENMAE, a, fmt='%d', delimiter=",")
- 参数delimiter可以指定各种分隔符、针对特定列的转换器函数、需要跳过的行数等。
import numpy as np
a = np.array([1, 2, 3, 4, 5])
np.savetxt('out.txt', a)
b = np.loadtxt('out.txt')
print(b)
运行结果为:
[1. 2. 3. 4. 5.]
- 使用delimiter参数:
import numpy as np
a = np.arange(0, 10, 0.5).reshape(4, -1)
np.savetxt('out2.txt', a, fmt="%d", delimiter=",") # 改为保存为整数,以逗号分隔
b = np.loadtxt("out.txt", delimiter=",") # load时也要指定为逗号分隔
print(b)
运行结果如下:
[1. 2. 3. 4. 5.]