归并排序的Java实现,与希尔排序的效率对比
归并排序是分治法的一种典型应用
其主要的思路是将一个数组不断的一分为二(两路归并),直到不可再分的时候,调整两个数字之间的位置,再将各部分调整好的序列合并,即得到一个整体有序的数组。
其具体流程参照百科归并排序
一种归并排序的Java实现:
package com.ryo.algorithm.sort;
import com.ryo.algorithm.sort.Sort;
/**
* 归并排序
* @author shiin
*/
public class MergeSort implements Sort{
private int[] result;
private int temp;
@Override
public int[] sort(int[] arr) {
result = new int[arr.length];
sort(arr , 0 ,arr.length-1);
return result;
}
public void sort(int[] arr ,int begin ,int end) {
if(end - begin <= 1) {
if(arr[begin] > arr[end]) {
temp = arr[begin];
arr[begin] = arr[end];
arr[end] = temp;
}
}
else {
int mid = (begin + end)/2;//这里取中间值最开始我使用了Math.floor,在10万个0-100000随机整数的测试中平均要多消耗3-4ms
sort(arr ,begin ,mid);
sort(arr ,mid+1 ,end);
mergeSort(arr ,begin ,mid ,end);
}
}
public void mergeSort(int[] arr ,int begin ,int mid ,int end) {
int i = begin;
int j = mid+1;
int index = begin;
//比较要合并的两个数组
//将较小的数移入临时储存的数组
while(i <= mid && j <= end) {
if(arr[i] > arr[j]) {
result[index++] = arr[j++];
}
else {
result[index++] = arr[i++];
}
}
//将还剩余的部分移入result
if(j > end) {
for(;i < mid+1;i++) {
result[index++] = arr[i];
}
}
else {
for(;j < end+1;j++) {
result[index++] = arr[j];
}
}
//将数组复制回原数组
for(i=begin ;i<end+1 ;i++) {
arr[i] = result[i];
}
}
}
归并排序的实际效率
测试环境:Jdk1.8.0_161 eclipse Version: Oxygen.3a Release (4.7.3a)
对100000个0-100000随机整数进行排序结果:
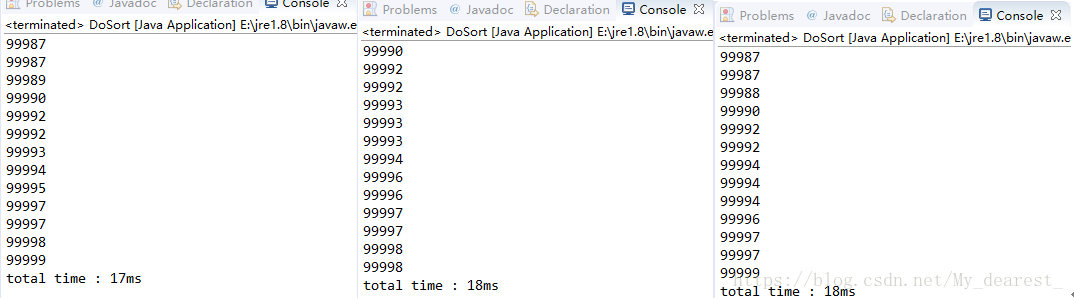
相同环境下使用希尔排序的测试结果:
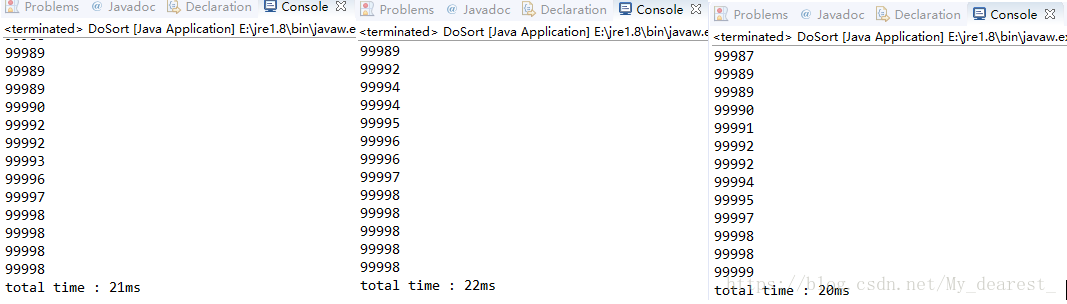
两种算法在十万个数据的情况下只相差了3ms左右,不过即便同是希尔排序或者归并排序的Java实现,根据其代码不同,效率也可能会有差距,而且这种差距完全可能是3ms级别的。
而且希尔排序的效率跟其步长取值有很大关系,这里的步长取值为: private int[] steplist ={1607,733,373,181,83,37,17,7,3,1};
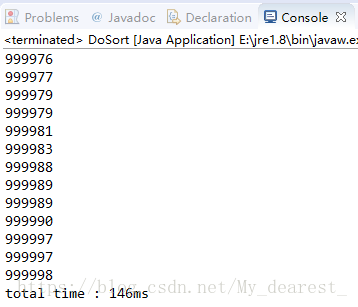
由于两种算法在十万个数据的测试下看不出明显的差距,这里扩大到一百万进行测试,取多次运行后的稳定结果:
归并排序结果:
希尔排序结果:
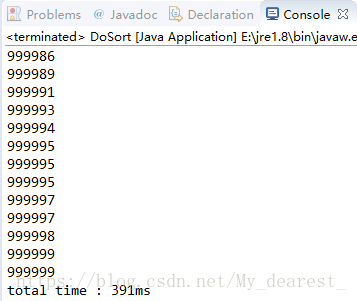
在一百万的数据量下,由于数据量的增大,具体代码细节造成的误差影响就相对减小了,可以看到归并排序的效率达到了希尔排序的两倍以上。