首先,登录邮件客户端进行设置,启用邮件的SMTP和POP服务,并生成授权码,这样在编程的时候用授权码代替密码进行登录。
接收邮件SMTP
#! /usr/bin/env python #coding=utf-8 from smtplib import SMTP as smtp,SMTPException as se from email.mime.text import MIMEText from email.header import Header from email.mime.multipart import MIMEMultipart HOST="smtp.163.com" #服务器 USER="[email protected]" #用户 PASSWD="XXX" #授权码 SENDOR="[email protected]" #发送方 RECEPTOR="[email protected],"+SENDOR #接受方 message=MIMEMultipart("relate") #多类型消息 message["From"]=SENDOR message["To"]=RECEPTOR message["Cc"]=SENDOR message["Subject"]=Header("这是python一个带附件的邮件测试","utf-8") #对于含有中文要用Header的utf-8编码 #上面这些属性必须都是字符串 thebody=MIMEText("python 发送邮件测试","plain","utf-8") message.attach(thebody) #加上主体文本内容 att=MIMEText(open('/home/test5_2.c','rb').read(),'base64','utf-8') att['Content-Disposition']="attchment;filename=test.c" #附件描述,文件名后不要用单引号括住 message.attach(att) #加上附件 try: s=smtp() s.connect(HOST,25) #连接服务器 s.login(USER,PASSWD) #登录 s.sendmail(SENDOR,RECEPTOR.split(","),message.as_string()) #发送邮件,注意要将字符串RECEPTOR解析成元组或者列表,message.as_string比较关键 print "邮件发送成功" except se: print "Error: 无法发送文件" s.quit() s.quit()

读取邮件POP3
#coding=utf-8
from poplib import POP3
from email.parser import Parser
from email.header import decode_header
from email.utils import parseaddr
POP3SVR="pop3.163.com"
recvSvr=POP3(POP3SVR)
print recvSvr.getwelcome()
recvSvr.user('[email protected]')
recvSvr.pass_('XXX')
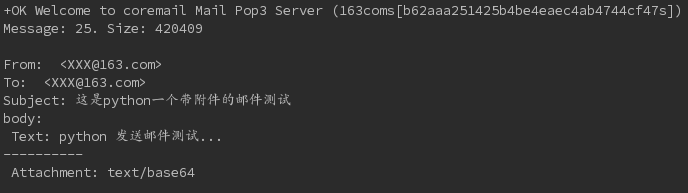
print "Message: %s. Size: %s\n" % recvSvr.stat()
resp,mails,octets=recvSvr.list() #列出所有邮件返回信息,信息总列表,信息总大小
index=len(mails) #获取最后一封邮件下标
rsp,lines,siz=recvSvr.retr(index) #获取指定邮件的返回信息,指定邮件信息的所有行列表,指定邮件大小
msg_content='\n'.join(lines) #将信息所有行列表变成字符串
msg=Parser().parsestr(msg_content) #将字符串解析成Message类型
recvSvr.quit() #退出登录
def print_info(msg,indent=0):
printLine=False
if indent==0: #如果第一次调用该函数,首先打印出message的三大属性From,To,Subject
for header in ['From','To','Subject']:
value=msg.get(header,'') #使用get方法
if value:
if header=='Subject':#解码转换
value=decode_str(value)
else: #如果是收件人和发件人,还要解析邮件地址后再解码转换
hdr,addr=parseaddr(value)
name=decode_str(hdr)
value='%s <%s>' % (name,addr)
print("%s%s: %s" % (' '*indent,header,value))
if header=="Subject":
print "body:"
if msg.is_multipart(): #第二次之后调用,如果message含有多个不同类型信息
parts=msg.get_payload() #获取所有不同类型的信息
for n,part in enumerate(parts): #迭代各种信息
print_info(part,indent+1) #递归
else:#当多类型经过分解后成为单一类型,则在此处处理
content_type=msg.get_content_type() #获取信息的类型
if content_type=='text/plain' or content_type=='text/html': #如果是文本信息或者html格式信息
content=msg.get_payload(decode=True) #获取信息并允许解码
charset=guess_charset(msg) #获取message本身的编码格式
if charset:
content=content.decode(charset) #用utf-8解码
print "%sText: %s" % (' '*indent,content+'...')
else: #如果是附件
if not printLine:
print "-"*10
printLine=not printLine
print "%sAttachment: %s" % (' '*indent,content_type) #直接打印
def decode_str(s): #合适解码
value,charset=decode_header(s)[0]
if charset:
value=value.decode(charset)
return value
def guess_charset(msg): #自身编码
charset=msg.get_charset()
if charset is None:
content_type=msg.get('Content-Type','').lower()
pos=content_type.find('charset=')
if pos>=0:
charset=content_type[pos+8:].strip()
return charset
print_info(msg)