2021SC@SDUSC
一、数据来源
根据对相关内容论文的阅读[1] Yu Zheng, Furui Liu, Hsun-Ping Hsie. U-Air: When Urban Air Quality Inference Meets Big Data. 19th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2013).
[2] Yu Zheng, Xuxu Chen, Qiwei Jin, Yubiao Chen, Xiangyun Qu, Xin Liu, Eric Chang, Wei-Ying Ma, Yong Rui, Weiwei Sun. A Cloud-Based Knowledge Discovery System for Monitoring Fine-Grained Air Quality. MSR-TR-2014-40.
[3]Yu Zheng, Xiuwen Yi, Ming Li, Ruiyuan Li, Zhangqing Shan, Eric Chang, Tianrui Li. Forecasting Fine-Grained Air Quality Based on Big Data. In the Proceeding of the 21th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2015).
结合实际情况,我计划从多种渠道获取数据来源。初步计划包括但不限于AQI实时数据,天气相关数据(风速,温度,气压,湿度),路网数据(路网密度),poi(Point of Interest兴趣点)。
二、数据的获取
首先最需要获得的数据就是实时的现有站点的AQI数据,经过多方查找,终于找到了一个非常权威的网站,http://fb.sdem.org.cn:8801/AirDeploy.Web/AirQuality/MapMain.aspx。这是山东省生态环境厅的官方数据发布。我们在此简单使用。介绍使用方法,首先针对一个网页想要爬取,首先应该右键检查元素,但是我们发现这个界面右键没有反应。不用担心,非常简单。
只需要在浏览器中禁用JavaScript,重新进入网页就可以开始使用右键了。
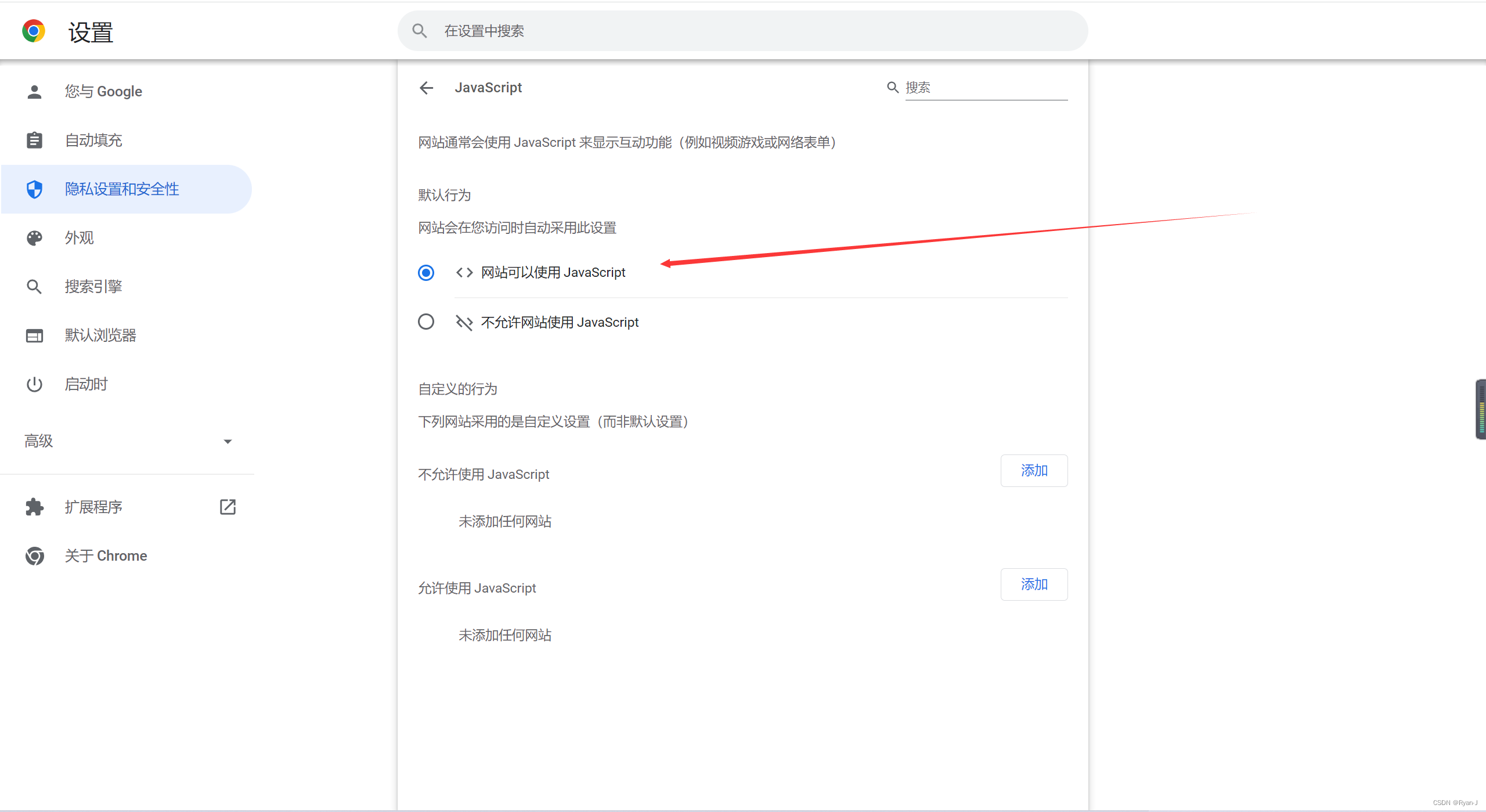
但是很不好的事情是我们发现地图不显示,然后我们不要关闭页面,重新启用JavaScript刷新就成功了。
该网页是aspx格式,所有数据动态相应,所以我们看一看这些数据是怎么得到的。

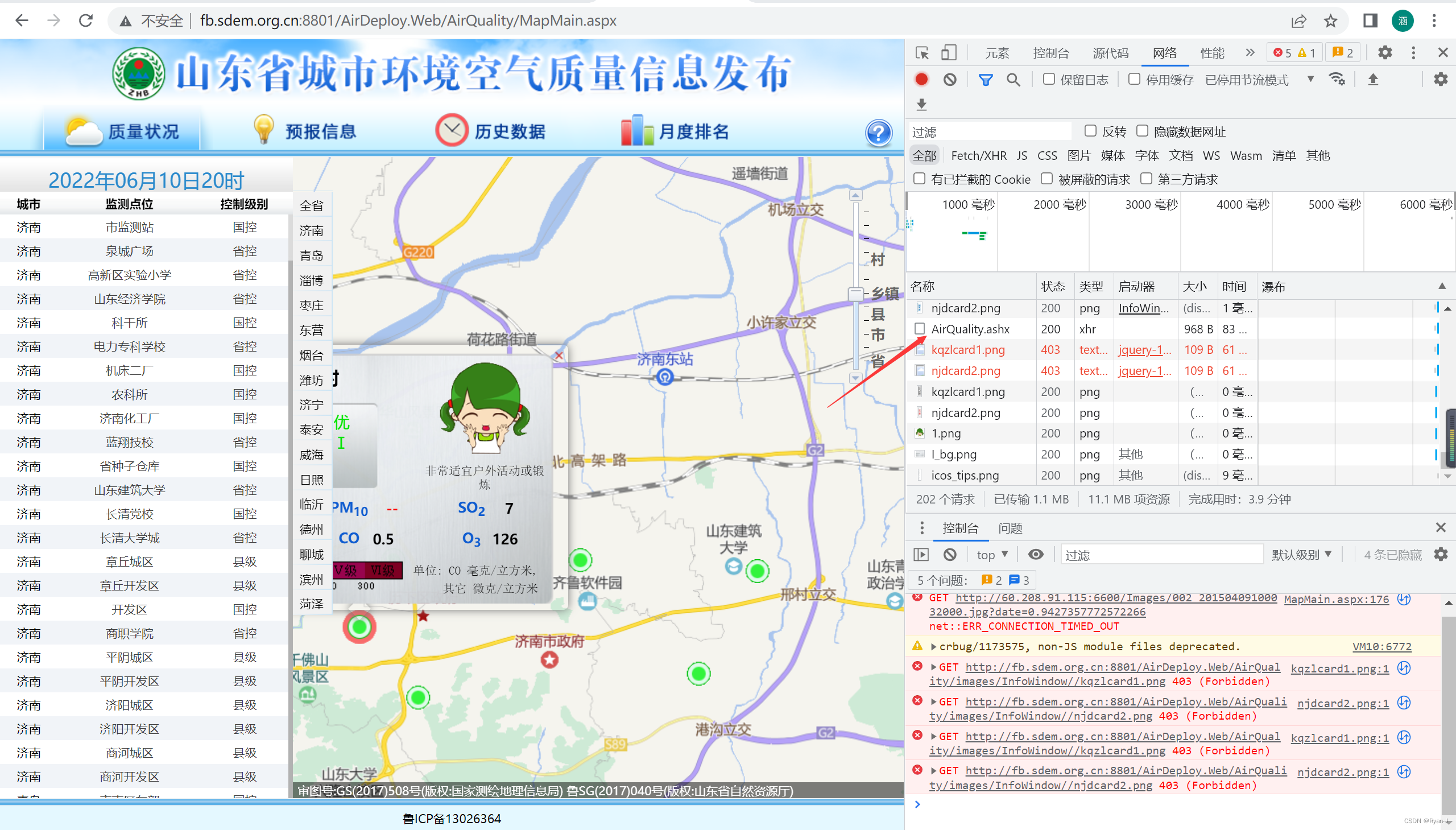
通过查找发现每次点击会产生请求并且返回可用值。我们模拟这个请求就可以完成爬取了。
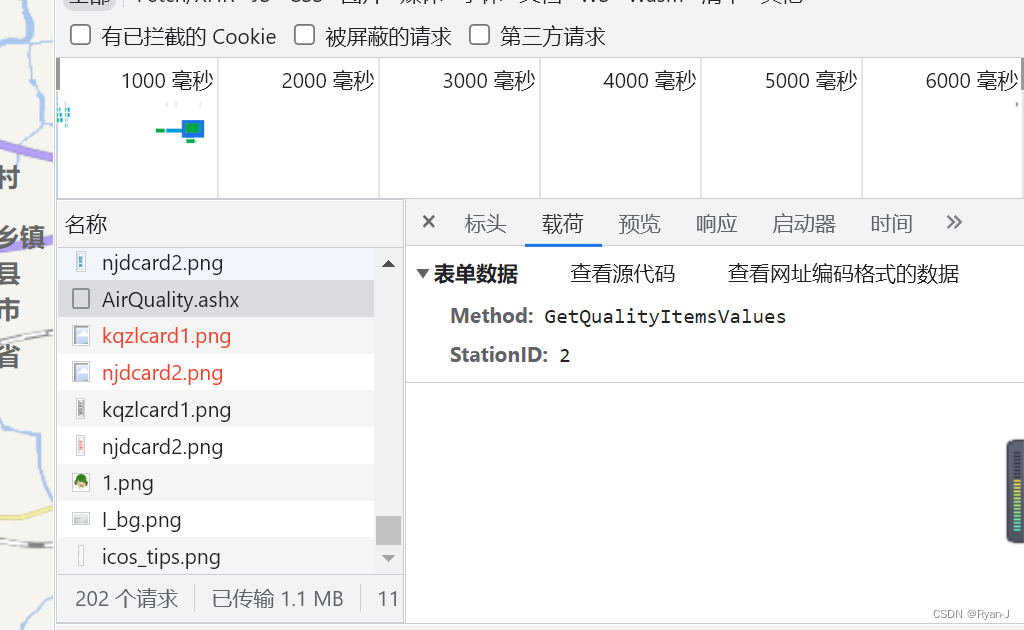
from urllib.parse import urlencode
import random
import requests
import traceback
from time import sleep
import json
import csv
import pandas as pd
from lxml import etree
import datetime
base_url = 'http://fb.sdem.org.cn:8801/AirDeploy.Web/Ajax/AirQuality/AirQuality.ashx?' #这里要换成对应Ajax请求中的链接 每小时20分
headers = {
输入自己的请求头
}
StationID_list = [68,67,4579]
col_name = []
for i in range(len(StationID_list)+1):
col_name.append(i)
aqi=[['t1']]
for i in range(len(StationID_list)):
sleep(random.uniform(2, 3))
data = {
'Method': 'GetQualityItemsValues',
'StationID': StationID_list[i] #2,4,7,6,10470,3,2987,5,56,54,55
}
url = base_url + urlencode(data)
response = requests.request("POST",url, headers = headers)
#print(response)
re = response.content.decode('utf-8')
#print(re)
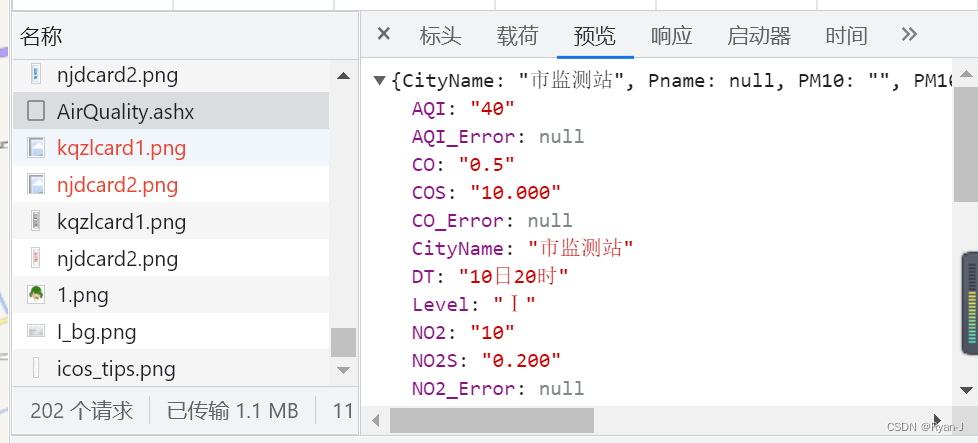
re = json.loads(re)
aqi[0].append(re['AQI'])
df = pd.DataFrame(columns=col_name, data=aqi)
df.to_csv('./input/aqi.csv',index=False,columns=None, header=None)
这里注意获取到的数据格式其实是json形式的,我们通过json.loads()完成编码就可以轻松通过索引访问。