1、环境准备
mysql服务器使用Thinkpad T480,客户端使用Mac pro;mysql版本为8.0.33
准备存放不同数量的几张表,表结构和行内容示例如下,为每个表的‘key2’列创建索引
create table test_100
(
id bigint auto_increment primary key,
name varchar(32) not null,
key1 varchar(32) not null,
key2 varchar(32) not null,
key3 varchar(32) not null,
key4 varchar(32) not null
);
create index idx_key2
on test_100 (key2);

以下为所有表,数字代表表内存放的行记录数:
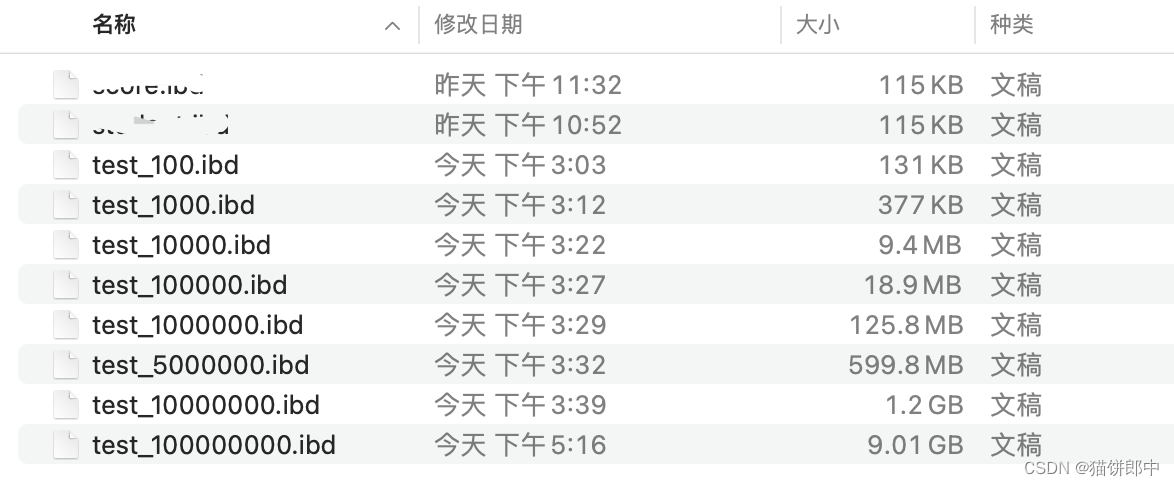
每张表在插入完数据后所占的空间大小如下:
2、开始测试
为每张表创建entity和mapper,我在这使用Mbaits-plus操作数据库
编写测试类,考虑到篇幅,这里只放一个100行数据表的测试方法,其他的都类似:
public void test100_all() {
// 100行数据
LambdaQueryWrapper<Test100> wrapper = new LambdaQueryWrapper<>();
// 非索引列查询
wrapper.eq(Test100::getKey1, "CbBxYcvaCq");
long now = System.currentTimeMillis();
test100Mapper.selectList(wrapper);
System.out.println("100行-全表扫描:" + (System.currentTimeMillis() - now) + "ms");
}
public void test100_ref() {
// 100行数据
LambdaQueryWrapper<Test100> wrapper = new LambdaQueryWrapper<>();
// 索引列查询
long now = System.currentTimeMillis();
wrapper.clear();
wrapper.eq(Test100::getKey2, "aXQBEneQDA");
test100Mapper.selectList(wrapper);
System.out.println("100行-命中索引:" + (System.currentTimeMillis() - now) + "ms");
}因为对同一张表的两个方法同时调,考虑到mysql对页数据缓存会影响查询结果,所以按照两种顺序都调用一下,测试结果如下:
| 表名 | 先全表再索引 | 先索引再全表 | 结论|效率 |
|---|---|---|---|
test100 |
100行-全表扫描:165ms 100行-命中索引:39ms |
100行-命中索引:171ms 100行-全表扫描:38ms |
差不多 |
| test1000 | 1000行-全表扫描:142ms 1000行-命中索引:61ms |
1000行-命中索引:175ms 1000行-全表扫描:74ms |
差不多 |
test10000 |
一万行-全表扫描:269ms 一万行-命中索引:67ms |
一万行-命中索引:148ms 一万行-全表扫描:32ms |
差不多 |
test100000 |
十万行-全表扫描:194ms 十万行-命中索引:40ms |
十万行-命中索引:225ms 十万行-全表扫描:226ms |
出现差别 |
test1000000 |
一百万行-全表扫描:837ms 一百万行-命中索引:99ms |
一百万行-命中索引:162ms 一百万行-全表扫描:593ms |
明显差别 |
test5000000 |
五百万行-全表扫描:3237ms 五百万行-命中索引:49ms |
五百万行-命中索引:142ms 五百万行-全表扫描:2866ms |
差别很大 |
test10000000 |
一千万行-全表扫描:5796ms 一千万行-命中索引:72ms |
一千万行-命中索引:187ms 一千万行-全表扫描:5639ms |
差别很大 |
test100000000 |
一亿行-全表扫描:超时 一亿行-命中索引:192ms |
一亿行-命中索引:164ms 一亿行-全表扫描:超时 |
差别非常大 |