特征选择之Relief算法与Relief-F算法
一、背景介绍
Relief算法是由Kira提出的一种经典的过滤式特征选择算法,其通过相关统计量度量特征的重要程度,只适用于二分类问题。相应的,针对多分类问题,Kononeill对Relief算法进行了改进,得到了适用于多分类问题的Relief-F算法。
二、Relief算法
Relief算法步骤如下:
- 给定训练样本集{(x1,y1),(x2,y2),…(xm,ym)},
- 对于每个样本xi:
- (1)先在其同类样本中寻找最近邻xi,nh,称为“猜中近邻”(near-hit);
- (2)再在其异类样本中寻找最近邻xi,nm,称为“猜错近邻”(near-miss);
- (3)计算相关统计量对应于属性j的分量:
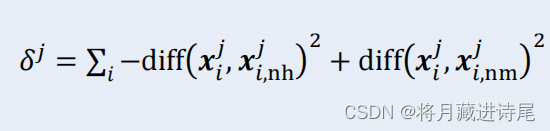
其中diff(xja,xjb)取决于属性j的类型:
①若属性j为离散型,则 xja=xjb 时,diff(xja,xjb)=0,否则为1;
②若属性j为连续型,则 diff(xja,xjb)=|xja-xjb|,且xja,xjb已规范化到[0,1]区间。 - (4)将基于不同样本得到的估计结果取均值。
有益特征和有害特征的区别
有益特征:diff(xji,xji,nh)<diff(xji,xji,nm)
有害特征:diff(xji,xji,nh)>diff(xji,xji,nm)
Relief算法的python实现见https://www.jianshu.com/p/679232633a1e
三、Relief-F算法
Relief-F算法对δj的计算方式进行了扩展。
Relief-F算法步骤如下:
- 假定数据集D中样本共有|Y|个类别,
- 其中样本xi属于第k类:
- (1)先在第k类样本中寻找最近邻xi,nh,称为“猜中近邻”;
- (2)再在第k类样本外寻找最近邻xi,nm,称为“猜错近邻”;
- (3)计算相关统计量对应于属性j的分量:
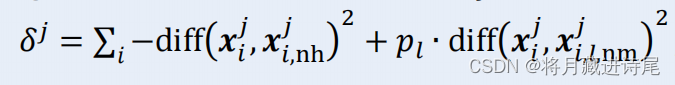
其中,pl为第l类样本在数据集D中所占比例。 - (4)将基于不同样本得到的估计结果取均值。
Relief-F算法的python实现见单标签Relief-F算法和多标签Relief-F算法
参考资料
1、周志华-机器学习-清华大学出版社
2、特征选择算法-Relief(转)
3、Relief算法python实现