比赛链接
在kaggle上跑的baseline,记录一下过程和遇到的问题。
环境:可以选择比赛官方Aistudio,或者colab/kaggle等,因为数据集比较大。
官方给出的baseline代码:github地址
官方代码基本没改,改动的地方:因为kaggle支持markdown所以无需导包,训练参数直接在代码里改,不用每次执行都输入一遍。
一、配置环境
先选择好gpu T4x2->start session接下来就可以放入代码,实际上只支持单卡。
配置环境,下载适配的包:(如果下载的版本不对,会一直报错:找不到paddle或者**.so文件存在)
每次进都要重配下环境,如果下载各种包出错就conda init --user清理下环境
paddlepaddle-gpu下载地址:新版本和旧版本都在这里
!pip install paddlepaddle-gpu==2.x.x #根据需要下载对应版本
!pip install paddlenlp
二、导入数据
提前+Dataset上传数据集,数据在官网baseline->数据集可找到,注意测试集不要下载A榜数据,A榜数据只有实际测试集的一半。
# 查看数据集
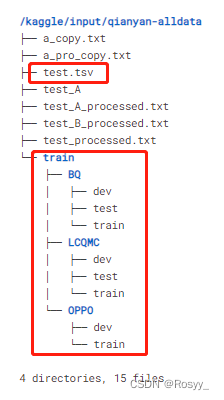
!tree -L 3 /kaggle/input/qianyan-alldata
红框内文件是必须的:
# 解压过后无需解压
# !unzip -o /kaggle/input/qianyan-alldata/train.zip -d data
# 将LCQMC、BQ、OPPO三个数据集的训练集和验证集合并
!cat /kaggle/input/qianyan-alldata/train/LCQMC/train /kaggle/input/qianyan-alldata/train/BQ/train /kaggle/input/qianyan-alldata/train/OPPO/train > train.txt
!cat /kaggle/input/qianyan-alldata/train/LCQMC/dev /kaggle/input/qianyan-alldata/train/BQ/dev /kaggle/input/qianyan-alldata/train/OPPO/dev > dev.txt
三、处理数据
对应官方代码data.py
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# 训练样本的数据读取、转换逻辑
import paddle
import numpy as np
from paddlenlp.datasets import MapDataset
def create_dataloader(dataset,
mode='train',
batch_size=1,
batchify_fn=None,
trans_fn=None):
if trans_fn:
dataset = dataset.map(trans_fn)
shuffle = True if mode == 'train' else False
if mode == 'train':
batch_sampler = paddle.io.DistributedBatchSampler(dataset,
batch_size=batch_size,
shuffle=shuffle)
else:
batch_sampler = paddle.io.BatchSampler(dataset,
batch_size=batch_size,
shuffle=shuffle)
return paddle.io.DataLoader(dataset=dataset,
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
return_list=True)
def read_text_pair(data_path, is_test=False):
"""Reads data."""
with open(data_path, 'r', encoding='utf-8') as f:
for line in f:
data = line.rstrip().split("\t")
if is_test == False:
if len(data) != 3:
continue
yield {
'query1': data[0], 'query2': data[1], 'label': data[2]}
else:
if len(data) != 2:
continue
yield {
'query1': data[0], 'query2': data[1]}
def convert_example(example, tokenizer, max_seq_length=512, is_test=False):
query, title = example["query1"], example["query2"]
encoded_inputs = tokenizer(text=query,
text_pair=title,
max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if not is_test:
label = np.array([example["label"]], dtype="int64")
return input_ids, token_type_ids, label
else:
return input_ids, token_type_ids
四、模型
对应官方代码:model.py
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License"
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# 匹配模型组网
import paddle
import paddle.nn as nn
import paddle.nn.functional as F
import paddlenlp as ppnlp
class QuestionMatching(nn.Layer):
def __init__(self, pretrained_model, dropout=None, rdrop_coef=0.0):
super().__init__()
self.ptm = pretrained_model
self.dropout = nn.Dropout(dropout if dropout is not None else 0.1)
# num_labels = 2 (similar or dissimilar)
self.classifier = nn.Linear(self.ptm.config["hidden_size"], 2)
self.rdrop_coef = rdrop_coef
self.rdrop_loss = ppnlp.losses.RDropLoss()
def forward(self,
input_ids,
token_type_ids=None,
position_ids=None,
attention_mask=None,
do_evaluate=False):
_, cls_embedding1 = self.ptm(input_ids, token_type_ids, position_ids,
attention_mask)
cls_embedding1 = self.dropout(cls_embedding1)
logits1 = self.classifier(cls_embedding1)
# For more information about R-drop please refer to this paper: https://arxiv.org/abs/2106.14448
# Original implementation please refer to this code: https://github.com/dropreg/R-Drop
if self.rdrop_coef > 0 and not do_evaluate:
_, cls_embedding2 = self.ptm(input_ids, token_type_ids,
position_ids, attention_mask)
cls_embedding2 = self.dropout(cls_embedding2)
logits2 = self.classifier(cls_embedding2)
kl_loss = self.rdrop_loss(logits1, logits2)
else:
kl_loss = 0.0
return logits1, kl_loss
五、训练模型
对应官方代码:train.py
修改了训练参数,直接赋值训练要用的文件
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# 模型训练评估
from functools import partial
import argparse
import os
import random
import time
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.transformers import AutoModel, AutoTokenizer
from paddlenlp.data import Stack, Tuple, Pad
from paddlenlp.datasets import load_dataset
from paddlenlp.transformers import LinearDecayWithWarmup
# from datas import create_dataloader, read_text_pair, convert_example
# from data import read_text_pair, convert_example, create_dataloader #导入文件函数,上面的文件
# from model import QuestionMatching
# yapf: disable
parser = argparse.ArgumentParser()
parser.add_argument("--train_set", default="/kaggle/working/train.txt", type=str, help="The full path of train_set_file")
parser.add_argument("--dev_set", default="/kaggle/working/dev.txt", type=str, help="The full path of dev_set_file")
parser.add_argument("--save_dir", default='./checkpoint', type=str, help="The output directory where the model checkpoints will be written.")
parser.add_argument("--max_seq_length", default=256, type=int, help="The maximum total input sequence length after tokenization. "
"Sequences longer than this will be truncated, sequences shorter will be padded.")
parser.add_argument('--max_steps', default=-1, type=int, help="If > 0, set total number of training steps to perform.")
parser.add_argument("--train_batch_size", default=32, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument("--eval_batch_size", default=128, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument("--learning_rate", default=5e-5, type=float, help="The initial learning rate for Adam.")
parser.add_argument("--weight_decay", default=0.0, type=float, help="Weight decay if we apply some.")
parser.add_argument("--epochs", default=3, type=int, help="Total number of training epochs to perform.")
parser.add_argument("--eval_step", default=100, type=int, help="Step interval for evaluation.")
parser.add_argument('--save_step', default=10000, type=int, help="Step interval for saving checkpoint.")
parser.add_argument("--warmup_proportion", default=0.0, type=float, help="Linear warmup proption over the training process.")
parser.add_argument("--init_from_ckpt", type=str, default=None, help="The path of checkpoint to be loaded.")
parser.add_argument("--seed", type=int, default=1000, help="Random seed for initialization.")
parser.add_argument('--device', choices=['cpu', 'gpu'], default="gpu", help="Select which device to train model, defaults to gpu.")
parser.add_argument("--rdrop_coef", default=0.0, type=float, help="The coefficient of"
"KL-Divergence loss in R-Drop paper, for more detail please refer to https://arxiv.org/abs/2106.14448), if rdrop_coef > 0 then R-Drop works")
args = parser.parse_args(args=[]) #加参数args=[]
# yapf: enable
def set_seed(seed):
"""sets random seed"""
random.seed(seed)
np.random.seed(seed)
paddle.seed(seed)
@paddle.no_grad()
def evaluate(model, criterion, metric, data_loader):
"""
Given a dataset, it evals model and computes the metric.
Args:
model(obj:`paddle.nn.Layer`): A model to classify texts.
data_loader(obj:`paddle.io.DataLoader`): The dataset loader which generates batches.
criterion(obj:`paddle.nn.Layer`): It can compute the loss.
metric(obj:`paddle.metric.Metric`): The evaluation metric.
"""
model.eval()
metric.reset()
losses = []
total_num = 0
for batch in data_loader:
input_ids, token_type_ids, labels = batch
total_num += len(labels)
logits, _ = model(input_ids=input_ids,
token_type_ids=token_type_ids,
do_evaluate=True)
loss = criterion(logits, labels)
losses.append(loss.numpy())
correct = metric.compute(logits, labels)
metric.update(correct)
accu = metric.accumulate()
print("dev_loss: {:.5}, accuracy: {:.5}, total_num:{}".format(
np.mean(losses), accu, total_num))
model.train()
metric.reset()
return accu
def do_train():
paddle.set_device(args.device)
rank = paddle.distributed.get_rank()
if paddle.distributed.get_world_size() > 1:
paddle.distributed.init_parallel_env()
set_seed(args.seed)
train_ds = load_dataset(read_text_pair,
data_path=args.train_set,
is_test=False,
lazy=False)
dev_ds = load_dataset(read_text_pair,
data_path=args.dev_set,
is_test=False,
lazy=False)
pretrained_model = AutoModel.from_pretrained('ernie-3.0-medium-zh')
tokenizer = AutoTokenizer.from_pretrained('ernie-3.0-medium-zh')
trans_func = partial(convert_example,
tokenizer=tokenizer,
max_seq_length=args.max_seq_length)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # text_pair_input
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # text_pair_segment
Stack(dtype="int64") # label
): [data for data in fn(samples)]
train_data_loader = create_dataloader(train_ds,
mode='train',
batch_size=args.train_batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
dev_data_loader = create_dataloader(dev_ds,
mode='dev',
batch_size=args.eval_batch_size,
batchify_fn=batchify_fn,
trans_fn=trans_func)
model = QuestionMatching(pretrained_model, rdrop_coef=args.rdrop_coef)
if args.init_from_ckpt and os.path.isfile(args.init_from_ckpt):
state_dict = paddle.load(args.init_from_ckpt)
model.set_dict(state_dict)
model = paddle.DataParallel(model)
num_training_steps = len(train_data_loader) * args.epochs
lr_scheduler = LinearDecayWithWarmup(args.learning_rate, num_training_steps,
args.warmup_proportion)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=args.weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
criterion = paddle.nn.loss.CrossEntropyLoss()
metric = paddle.metric.Accuracy()
global_step = 0
best_accuracy = 0.0
tic_train = time.time()
for epoch in range(1, args.epochs + 1):
for step, batch in enumerate(train_data_loader, start=1):
input_ids, token_type_ids, labels = batch
logits1, kl_loss = model(input_ids=input_ids,
token_type_ids=token_type_ids)
correct = metric.compute(logits1, labels)
metric.update(correct)
acc = metric.accumulate()
ce_loss = criterion(logits1, labels)
if kl_loss > 0:
loss = ce_loss + kl_loss * args.rdrop_coef
else:
loss = ce_loss
global_step += 1
if global_step % 10 == 0 and rank == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %.4f, ce_loss: %.4f., kl_loss: %.4f, accu: %.4f, speed: %.2f step/s"
%
(global_step, epoch, step, loss, ce_loss, kl_loss, acc, 10 /
(time.time() - tic_train)))
tic_train = time.time()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
if global_step % args.eval_step == 0 and rank == 0:
accuracy = evaluate(model, criterion, metric, dev_data_loader)
if accuracy > best_accuracy:
save_dir = os.path.join(args.save_dir,
"model_%d" % global_step)
if not os.path.exists(save_dir):
os.makedirs(save_dir)
save_param_path = os.path.join(save_dir,
'model_state.pdparams')
paddle.save(model.state_dict(), save_param_path)
tokenizer.save_pretrained(save_dir)
best_accuracy = accuracy
if global_step == args.max_steps:
return
if __name__ == "__main__":
do_train()
跑起来了…
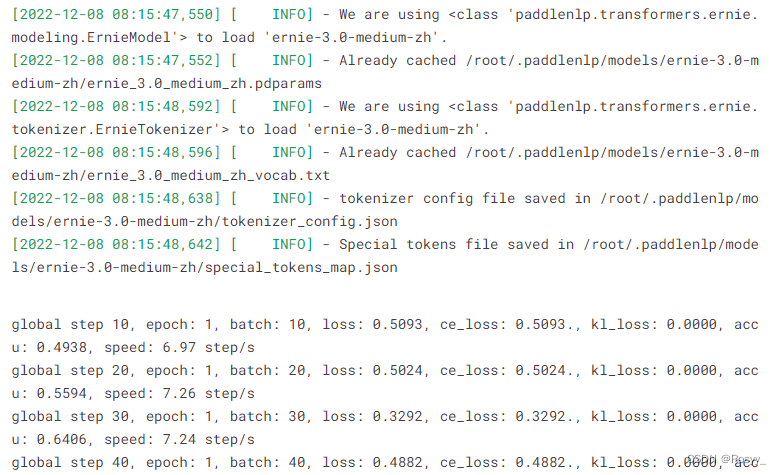
A few years later…
训练大概需要5-8小时,取决于机器。
训练需要看着,静默1小时好像会自动stop session。
训练过程中保存的模型是一次比一次好的,所以最后一次保存的模型即为后面预测要是用的模型。
六、打包模型
把最后一次保存的模型/kaggle/working/checkpoint/model_42000打包,以便下载使用:(不同的机器跑出来的最终模型其实也不太一样。。)
# pip install paddlepaddle-gpu
# pip install paddlenlp
import os
import zipfile
import datetime
def file2zip(packagePath, zipPath):
zip = zipfile.ZipFile(zipPath, 'w', zipfile.ZIP_DEFLATED)
for path, dirNames, fileNames in os.walk(packagePath):
fpath = path.replace(packagePath, '')
for name in fileNames:
fullName = os.path.join(path, name)
name = fpath + '\\' + name
zip.write(fullName, name)
zip.close()
if __name__ == "__main__":
# 文件夹路径
packagePath = '/kaggle/working/checkpoint/model_42000'
zipPath = '/kaggle/working/output.zip'
if os.path.exists(zipPath):
os.remove(zipPath)
file2zip(packagePath, zipPath)
print("打包完成")
print(datetime.datetime.utcnow())

七、测试
对应官方代码:predict.py,也是文件参数、模型参数直接在代码里赋值了。注意预测结果可直接写入csv文件,如果先写入txt再转csv文件格式有问题。
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from functools import partial
import argparse
import sys
import os
import random
import time
import numpy as np
import paddle
import paddle.nn.functional as F
from paddlenlp.transformers import AutoModel, AutoTokenizer
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Stack, Tuple, Pad
# from data import create_dataloader, read_text_pair, convert_example
# from model import QuestionMatching
# yapf: disable
parser = argparse.ArgumentParser()
parser.add_argument("--input_file", default="/kaggle/input/qianyan-alldata/test_A", type=str, help="The full path of input file")
parser.add_argument("--result_file",default="predict_A.csv", type=str, help="The result file name")
parser.add_argument("--params_path", default="/kaggle/working/checkpoint/model_42000/model_state.pdparams", type=str, help="The path to model parameters to be loaded.")
parser.add_argument("--max_seq_length", default=256, type=int, help="The maximum total input sequence length after tokenization. "
"Sequences longer than this will be truncated, sequences shorter will be padded.")
parser.add_argument("--batch_size", default=32, type=int, help="Batch size per GPU/CPU for training.")
parser.add_argument('--device', choices=['cpu', 'gpu'], default="gpu", help="Select which device to train model, defaults to gpu.")
args = parser.parse_args(args=[])
# yapf: enable
def predict(model, data_loader):
"""
Predicts the data labels.
Args:
model (obj:`QuestionMatching`): A model to calculate whether the question pair is semantic similar or not.
data_loaer (obj:`List(Example)`): The processed data ids of text pair: [query_input_ids, query_token_type_ids, title_input_ids, title_token_type_ids]
Returns:
results(obj:`List`): cosine similarity of text pairs.
"""
batch_logits = []
model.eval()
with paddle.no_grad():
for batch_data in data_loader:
input_ids, token_type_ids = batch_data
input_ids = paddle.to_tensor(input_ids)
token_type_ids = paddle.to_tensor(token_type_ids)
batch_logit, _ = model(input_ids=input_ids, token_type_ids=token_type_ids)
batch_logits.append(batch_logit.numpy())
batch_logits = np.concatenate(batch_logits, axis=0)
return batch_logits
if __name__ == "__main__":
paddle.set_device(args.device)
pretrained_model = AutoModel.from_pretrained("ernie-3.0-medium-zh")
tokenizer = AutoTokenizer.from_pretrained("ernie-3.0-medium-zh")
trans_func = partial(convert_example, tokenizer=tokenizer, max_seq_length=args.max_seq_length, is_test=True)
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # segment_ids
): [data for data in fn(samples)]
test_ds = load_dataset(read_text_pair, data_path=args.input_file, is_test=True, lazy=False)
test_data_loader = create_dataloader(
test_ds, mode="predict", batch_size=args.batch_size, batchify_fn=batchify_fn, trans_fn=trans_func
)
model = QuestionMatching(pretrained_model)
if args.params_path and os.path.isfile(args.params_path):
state_dict = paddle.load(args.params_path)
model.set_dict(state_dict)
print("Loaded parameters from %s" % args.params_path)
else:
raise ValueError("Please set --params_path with correct pretrained model file")
y_probs = predict(model, test_data_loader)
y_preds = np.argmax(y_probs, axis=1)
with open(args.result_file, "w", encoding="utf-8") as f:
for y_pred in y_preds:
f.write(str(y_pred) + "\n")
将生成的csv文件下载并上传到比赛官网就可以查看评分结果了。
八、保存完整版本
save version->起个名(后面还能改)->quick save(save all会再训练一编!)->advanced set->save output for this version->save.
会把每个code块、执行结果、输入输出Data都保存起来。