先举个栗子:
动物园里来了一只不明物种,通过对比它和动物园里每只动物的相似度,我们挑出了跟它长得最像的5只动物(k=5),其中有3只是马、一只是驴、一只是牛,所以我们可以判定新来的动物是一匹马。
1、KNN概述(K Nearest Neighbors)
- 机器学习可分为:有监督学习、无监督学习、弱监督学习、强化学习。
- 有监督学习又分为:分类问题、回归问题。
- KNN主要解决的是分类问题。
- 其与K-means有相似之处,但K-means是无监督学习算法。
2、KNN原理
- 已知训练样本集中每个数据与标签的对应关系,输入没有标签的新数据,与样本集中的所有数据进行特征比较,算法提取前k个最相似(最临近)数据的标签。(再回看文章开篇的例子,就十分简单了。)
- 关于距离的计算,有多种方法:欧氏距离、曼哈顿距离…
3、代码实现:
核心代码之:KNN实现
def kNN(in_x, x_train, y_train, k):
x_train_size = x_train.shape[0]#行数
distances = (np.tile(in_x, (x_train_size, 1)) - x_train) ** 2# np.tile()行扩展,再矩阵相减
sum_distances = distances.sum(axis=1)#axis=1,是行和
sq_distances = sum_distances ** 0.5
sort_distances_index = sq_distances.argsort()#...argsort()从小到大排序,返回索引序列
classdict = {
}#存放前k个最近数据的标签:次数
for i in range(k):
vote_label = y_train[sort_distances_index[i]]#获得标签
classdict[vote_label] = classdict.get(vote_label, 0) + 1#确定次数
sort_classdict = sorted(classdict.items(), key=operator.itemgetter(1), reverse=True)
return sort_classdict[0][0]
3.1 案例:手写数字识别
将一张手写数字图片和数据集中的每个图片进行比较,所有数字按01存储,选出最为相似的数字图片,作为待分类图片对应的数字。
step1:一个图片化为一维数组,一个具有1024个特征的data
数据来源:https://www.manning.com/books/machine-learning-in-action(对应02/digits)
def img2vector(filename):
ret_vec = np.zeros((1, 1024))#转化为一笔data有1024个特征!!!
fr = open(filename)
for i in range(32):#一行一行处理
line_str = fr.readline()
for j in range(32):
ret_vec[0, i*32+j] = int(line_str[j])
return ret_vec
test_vec = img2vector('trainingDigits/0_0.txt')
print(test_vec[0, 0:31])
print(test_vec[0, 32:63])
step2:训练集喂给KNN,测试集预测结果及准确度
先处理好训练数据集和测试数据集,在训练集上对测试机的每张图片进行分类,并给出分类误差。
from os import listdir
def hw_classify():
#先训练集
training_file_list = listdir('trainingDigits')#训练集文件列表
m = len(training_file_list)#训练集数字个数
hw_x_train = np.zeros((m, 1024))#训练集处理结果
hw_y_train = []#训练集标签
for i in range(m):
file_name_str = training_file_list[i]#从文件名获取分类数字
file_name_str0 = file_name_str.split('.')[0]
class_num = file_name_str0.split('_')[0]
hw_y_train.append(class_num)#加入训练集标签y_train
hw_x_train[i, :] = img2vector('trainingDigits/%s'%file_name_str)#加入训练集x_train
#后测试集
test_file_list = listdir('testDigits')#测试集文件列表
m_test = len(test_file_list)#测试集文件数
error_count = 0.0
for i in range(m_test):
file_name_str = test_file_list[i]#从文件名获取分类数字
file_name_str0 = file_name_str.split('.')[0]
class_num = file_name_str0.split('_')[0]
in_x = img2vector('testDigits/%s'%file_name_str)
classifier_result = kNN(in_x, hw_x_train, hw_y_train, 3)#用KNN预测每笔测试数据的分类结果
print('classifier_result:{}, real_answer:{}'.format(classifier_result, class_num))
if(classifier_result != class_num):
error_count += 1.0
print('total number of error : {}'. format(error_count))
print('error rate : {}'.format(error_count/m_test))
hw_classify()
部分运行结果:
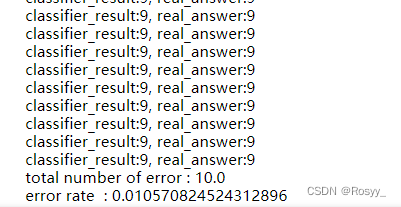
其中,error rate表示分类错误率。
4、KNN的缺陷
耗时间:每个测试数据要计算和训练集中每笔数据的距离。
占空间:要保存所有数据集。