redis的背景了解:
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。从2010年3月15日起,Redis的开发工作由VMware主持。(来源于网络)
其最大的优势在于能够建立缓存,使得其以一种非关系型数据库的方式存在于互联网的工程应用之中,相比较传统的硬盘读写,其能够有较快的响应速度,不过也不是所有的业务都需要使用redis来做缓存,主要从以下三个方面来考虑:
(1)业务数据是不是经常被用到,命中率如何?命中率低的话就没必要做缓存了。
(2)该业务的读取和写入那种操作比较多,如果频繁写入数据库的话,其实redis作用也不是很大。
(3)该业务的数据大小如何,如果存储几百兆的字段,将会给缓存带来很大的压力,考虑是否有必要?更详细的Redis参考则可以参考本人以后再Redis栏目下的博文。
Redis的安装:
本次试验实在Linux环境下安装的,Linux版本为Centos 7.0,安装的Redis版本为3.0版本。选择的版本为edis3.0版本。3.0版本主要增加了redis集群功能。
假如是新安装的Linux系统的话,可能缺少安装时的编译环境需要安装 gcc编译器:
需要安装gcc:yuminstall gcc-c++
1、下载redis的源码包。
2、把源码包上传到linux服务器,可以通过SecurtyCRT的SFtp来进行上传,上传后解压压缩包
3、解压源码包(tar -zxvf “”文件名“”)tar -zxvf redis-3.0.0.tar.gz
4、Make 找到解压的文件夹,并进入:
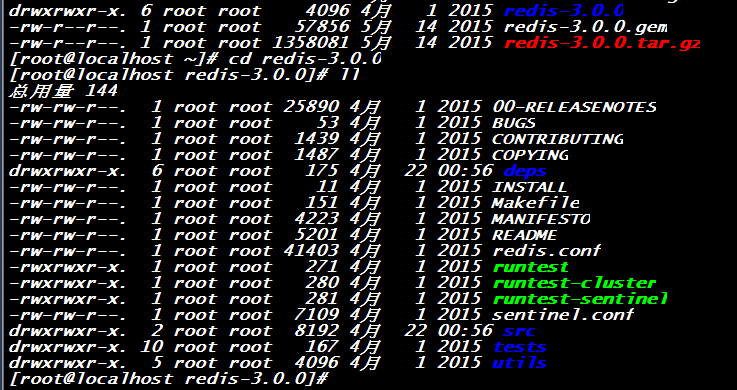
可以看到里面有个Makefile,这个是待执行的编译文件。使用MakeInstall 命令来进行安装
5、Make install 命令为:[root@localhost redis-3.0.0]# make installPREFIX=/usr/local/redis,此命令则告诉安装进程将redis安装到/usr/lcoal/redis文件夹下面。进入上面的文件夹可以看到:
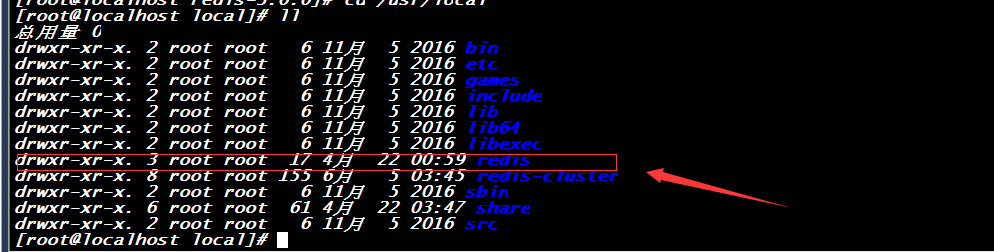
默认的是前端启动,在redis/bin目录中执行命令:./redis-server,则进入了前端启动,这个也可以检验是否安装成功:
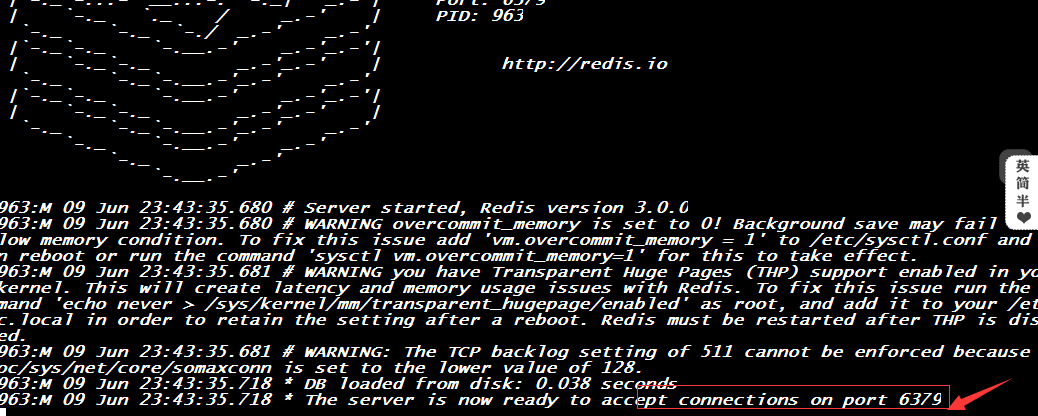
可以看到其在默认的端口6379端口监听,所以,此时我们的redis服务就能够成功的启动了。再此界面下如果想退出,则可以使用组合建Ctrl + c来退出,此时,redis服务也相应的停止。

此时,我们如果想通过后端启动的话则可以将redis从redis的源码目录中复制redis.conf到redis的安装目录。然后修改配置文件:
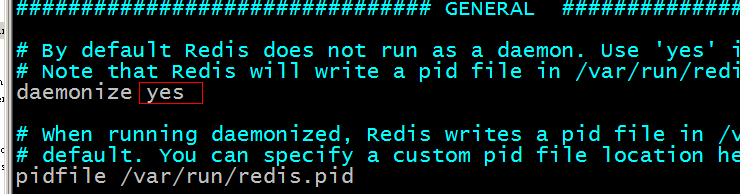
此时,在redis/bin目录下执行:./redis-server redis.conf 命令就可以使用后端方式启动reids。可以通过./redis-cli进入redis客户端。
Redis集群搭建:
redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value。Redis 集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对 key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点。
redis-cluster投票:容错

(1)领着投票过程是集群中所有master参与,如果半数以上master节点与master节点通信超过(cluster-node-timeout),认为当前master节点挂掉.
(2):什么时候整个集群不可用(cluster_state:fail)?
a:如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完成时进入fail状态. ps : redis-3.0.0.rc1加入cluster-require-full-coverage参数,默认关闭,打开集群兼容部分失败.
b:如果集群超过半数以上master挂掉,无论是否有slave集群进入fail状态.
ps:当集群不可用时,所有对集群的操作做都不可用,收到((error) CLUSTERDOWN The cluster is down)错误。
模拟集群结构建立:
集群中有三个节点的集群,每个节点有一主一备。需要6台虚拟机。搭建一个伪分布式的集群,使用6个redis实例来模拟。这六个实力在同一个虚拟机上。
所需要的环境:
搭建集群需要使用到官方提供的ruby脚本。需要安装ruby的环境。如果没有Ruby的话则需要首先安装Ruby,使得虚拟机有一个Ruby环境:安装ruby
yum install ruby
yum install rubygems 自最b主要的是使用redis-trib.rb来管理集群,所以这里需要我们先有一个Ruby环境。之后上传到Linux服务器Ruby需要的脚本包:

之后安装:[root@localhost ~]# gem install redis-3.0.0.gem
集群环境搭建:
第一步:创建6个redis实例,端口号从7001~7006。

实际上就是先在/usr/local文件夹下面建立一个redis-cluster文件夹,文件夹里面分别建立六个文件夹,Redis01-06,然后将原来安装的Redis文件夹里面的内容分别复制到这六个文件夹中。
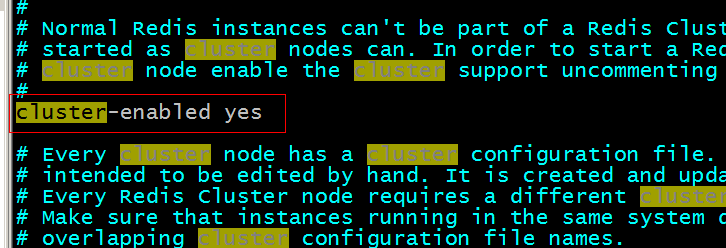
第二步:然后分别修改其对应的运行的端口,并将集群形式的选项设置为yes:修改端口,以redis01为例;
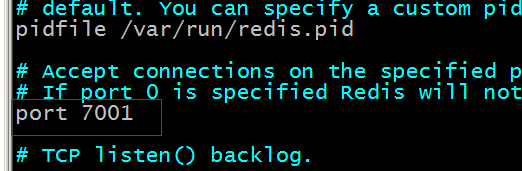
修改集群选项:
第三步:把创建集群的ruby脚本复制到redis-cluster目录下。

此时,可以分别启动这六个实例,这样就可以模拟出运行在六个不同的服务器上的Redis服务了。
第五步:创建集群。
启动命令:./redis-trib.rb create --replicas 1 192.168.25.153:7001 192.168.25.153:7002 192.168.25.153:7003 192.168.25.153:7004 192.168.25.153:7005 192.168.25.153:7006 ;之后在启动集群的时候就不在需要这个命令了,这个命令执行一次就可以了,如果集群不发生变化的情况下。
集群启动成功后出现的输出内容:
>>> Creating cluster Connecting to node 192.168.25.153:7001: OK Connecting to node 192.168.25.153:7002: OK Connecting to node 192.168.25.153:7003: OK Connecting to node 192.168.25.153:7004: OK Connecting to node 192.168.25.153:7005: OK Connecting to node 192.168.25.153:7006: OK >>> Performing hash slots allocation on 6 nodes... Using 3 masters: 192.168.25.153:7001 192.168.25.153:7002 192.168.25.153:7003 Adding replica 192.168.25.153:7004 to 192.168.25.153:7001 Adding replica 192.168.25.153:7005 to 192.168.25.153:7002 Adding replica 192.168.25.153:7006 to 192.168.25.153:7003 M: 5a8523db7e12ca600dc82901ced06741b3010076 192.168.25.153:7001 slots:0-5460 (5461 slots) master M: bf6f0929044db485dea9b565bb51e0c917d20a53 192.168.25.153:7002 slots:5461-10922 (5462 slots) master M: c5e334dc4a53f655cb98fa3c3bdef8a808a693ca 192.168.25.153:7003 slots:10923-16383 (5461 slots) master S: 2a61b87b49e5b1c84092918fa2467dd70fec115f 192.168.25.153:7004 replicates 5a8523db7e12ca600dc82901ced06741b3010076 S: 14848b8c813766387cfd77229bd2d1ffd6ac8d65 192.168.25.153:7005 replicates bf6f0929044db485dea9b565bb51e0c917d20a53 S: 3192cbe437fe67bbde9062f59d5a77dabcd0d632 192.168.25.153:7006 replicates c5e334dc4a53f655cb98fa3c3bdef8a808a693ca Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join..... >>> Performing Cluster Check (using node 192.168.25.153:7001) M: 5a8523db7e12ca600dc82901ced06741b3010076 192.168.25.153:7001 slots:0-5460 (5461 slots) master M: bf6f0929044db485dea9b565bb51e0c917d20a53 192.168.25.153:7002 slots:5461-10922 (5462 slots) master M: c5e334dc4a53f655cb98fa3c3bdef8a808a693ca 192.168.25.153:7003 slots:10923-16383 (5461 slots) master M: 2a61b87b49e5b1c84092918fa2467dd70fec115f 192.168.25.153:7004 slots: (0 slots) master replicates 5a8523db7e12ca600dc82901ced06741b3010076 M: 14848b8c813766387cfd77229bd2d1ffd6ac8d65 192.168.25.153:7005 slots: (0 slots) master replicates bf6f0929044db485dea9b565bb51e0c917d20a53 M: 3192cbe437fe67bbde9062f59d5a77dabcd0d632 192.168.25.153:7006 slots: (0 slots) master replicates c5e334dc4a53f655cb98fa3c3bdef8a808a693ca [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
其中,ip地址根据自己的主机的地址进行修改,在这里仅仅是一个例子,不一定是就是这个地址对应下的端口。其实可以为第五步和第四步写一个脚本,可以仅通过这个脚本就可以启动redis集群。如启动六个实例的shell脚本(startall.sh)
cd redis01 ./redis-server redis.conf cd .. cd redis02 ./redis-server redis.conf cd .. cd redis03 ./redis-server redis.conf cd .. cd redis04 ./redis-server redis.conf cd .. cd redis05 ./redis-server redis.conf cd .. cd redis06 ./redis-server redis.conf cd ..
全部停止的shell脚本(shutdown.sh),其中每一个都为关闭一个实例的执行的命令。
redis01/redis-cli -p 7001 shutdown redis02/redis-cli -p 7002 shutdown redis03/redis-cli -p 7003 shutdown redis04/redis-cli -p 7004 shutdown redis05/redis-cli -p 7005 shutdown redis06/redis-cli -p 7006 shutdown
当执行./startall.sh后就会启动这个集群,我们可以查看有关redis的进程,则可以发现,其运行在7001-7006端口,那么这么才能够说明我们建立的集群能够正确运行呢。

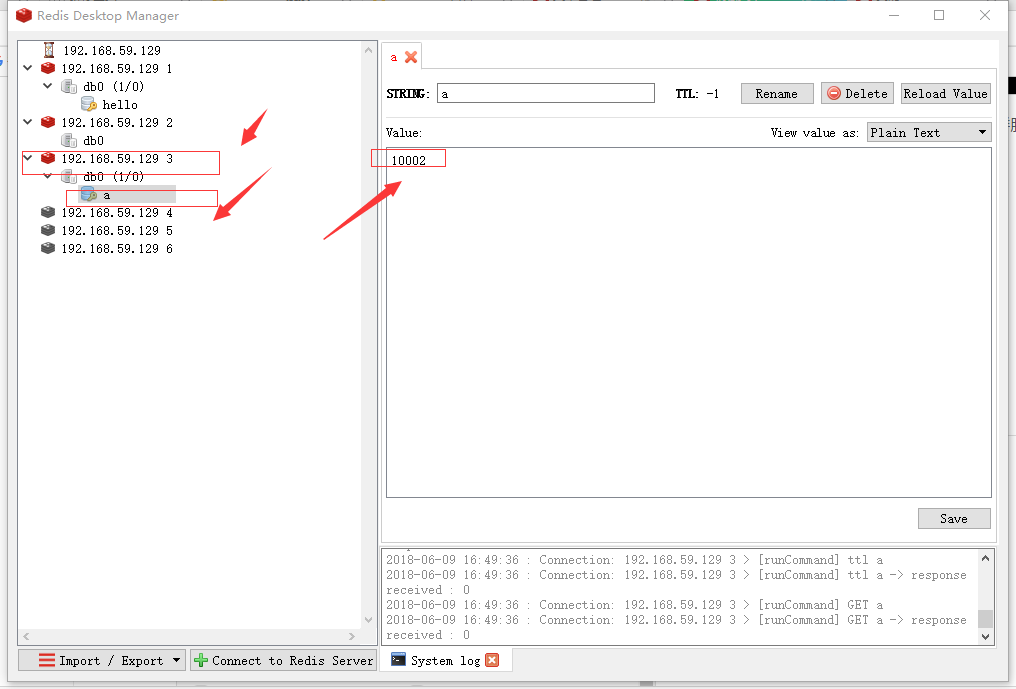
首选,我们可以先登录端口7002的客户端:

可以看到我们设置了a的值为10002,通过计算,其被重新分配到7003端口的15495槽口中,如果还原模拟,则相当于在集群服务器中其从一个服务器跳转到了另一台服务器。说明我们建立的集群是可以正确执行的。
Redis客户端:
1.自带的客户端,如上面登录端口7002的客户端。
2.图形化界面的Redis客户端。(单机版)
3.Jedis客户端,为Java代码执行的客户端。
需要把jedis的jar包添加到工程中,如果是maven需要添加jar包的坐标。
之后就可以在建立的工程中使用了:
1.单机版
public class JedisTest {
@Test
public void testJedisSingle() {
//创建一个jedis的对象。
Jedis jedis = new Jedis("192.168.25.153", 6379);
//调用jedis对象的方法,方法名称和redis的命令一致。
jedis.set("key1", "jedis test");
String string = jedis.get("key1");
System.out.println(string);
//关闭jedis。
jedis.close();
}
/**
* 使用连接池
*/
@Test
public void testJedisPool() {
//创建jedis连接池
JedisPool pool = new JedisPool("192.168.25.153", 6379);
//从连接池中获得Jedis对象
Jedis jedis = pool.getResource();
String string = jedis.get("key1");
System.out.println(string);
//关闭jedis对象
jedis.close();
pool.close();
}
}
2.集群版:
public void testJedisCluster() {
HashSet<HostAndPort> nodes = new HashSet<>();
nodes.add(new HostAndPort("192.168.25.153", 7001));
nodes.add(new HostAndPort("192.168.25.153", 7002));
nodes.add(new HostAndPort("192.168.25.153", 7003));
nodes.add(new HostAndPort("192.168.25.153", 7004));
nodes.add(new HostAndPort("192.168.25.153", 7005));
nodes.add(new HostAndPort("192.168.25.153", 7006));
JedisCluster cluster = new JedisCluster(nodes);
cluster.set("key1", "1000");
String string = cluster.get("key1");
System.out.println(string);
cluster.close();
}