从零构建感知机实现手写数字二分类
了解传统编程方法与机器学习方法的本质区别;理解感知机模型的数学表达;掌握梯度下降公式的手工推导方法。
上一节,已经使用“统计非零像素占比,比较阈值” 这种基于图像分析的传统编程方法实现了手写数字0和1的二分类,它是一个很简单的实现策略。本节开始采用机器学习的方法来实现。有很多种机器学习方法可以实现二分类问题,本节先尝试采用机器学习中很简单的感知机模型,来试试分类效果如何。
感知机模型的诞生是受到了人脑神经元的启发,如下图所示是单个人脑神经元的结构,每个神经元都与其他神经元进行相连,当神经元“兴奋”时,就会向相连的神经元传递化学物质,另一个神经元就是从树突接收其他神经元的化学物质输入,化学物质会改变轴突上的电位,当电位大于一定阈值时,这个神经元也被激活到了“兴奋”状态,也通过轴突末梢向其他神经元传递化学物质。
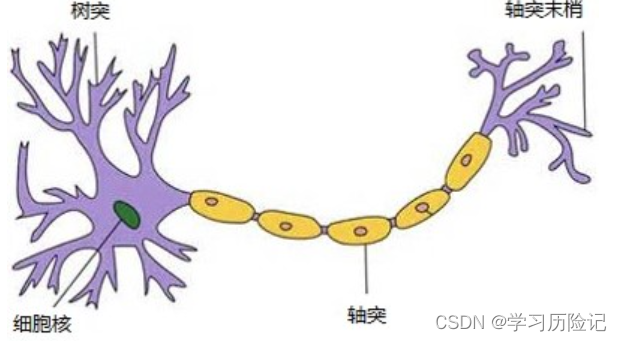
感知机模型的结构与神经元类似,如下图所示,它有一个输入层和输出层,输入层就相当于神经元的树突,用于接收输入,输出层就相当于轴突和轴突末梢,用于累计输入并判断是否激活至“兴奋状态”。

感知机可以使用的激活函数有很多种,上图中使用的是sigmoid函数,它的函数曲线如下图所示,可以看出函数的取值区间是(0.0, 1.0)。

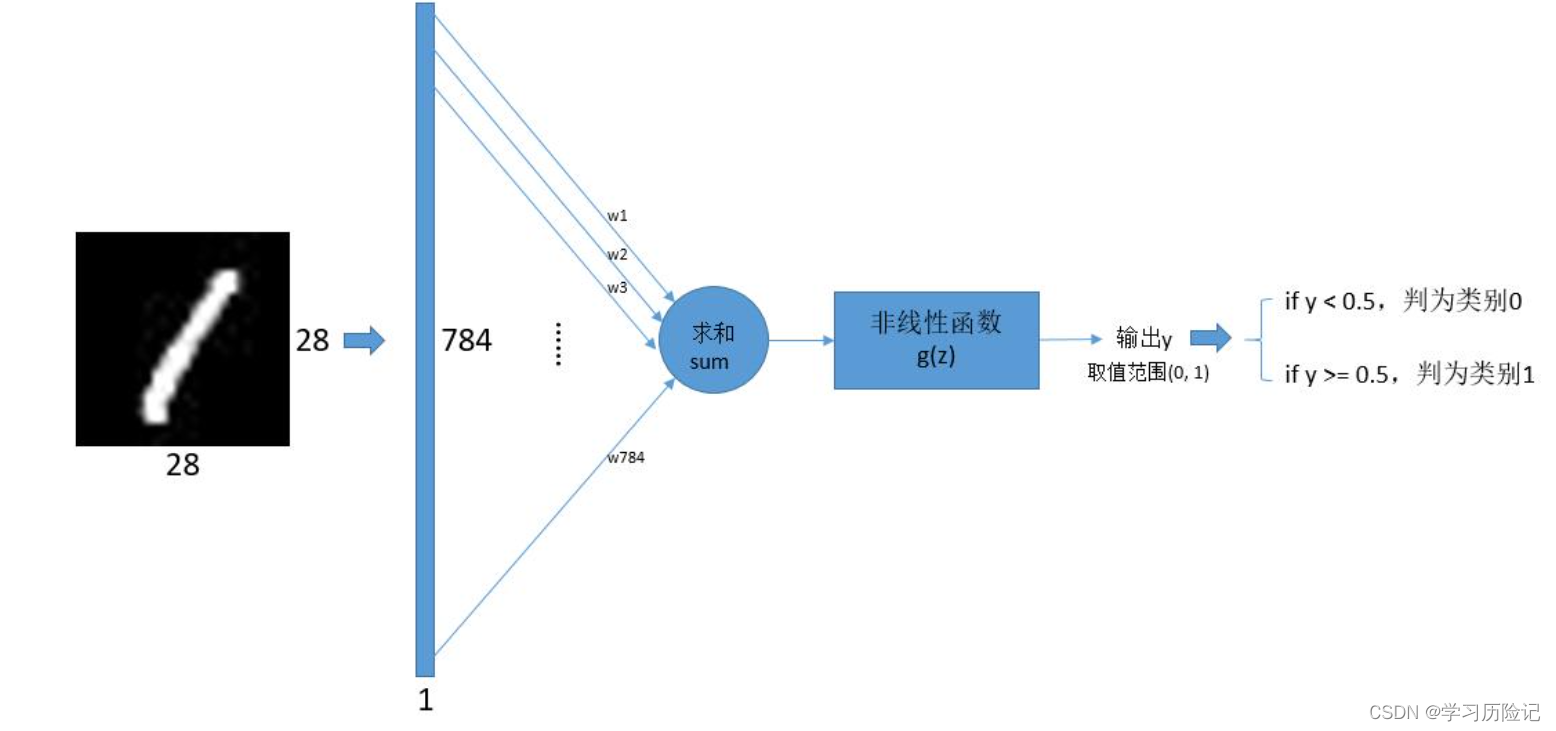
那么,如何使用感知机来实现手写数字0和1的二分类呢? 已知手写数字图片的数据可以用28*28的数组来表示,那么可以将这个数组转换为784*1的列向量,这个列向量作为感知机的输入,也就是说输入和权值都是784个。
感知机的输出是0.0到1.0之前的小数,而需要的是二分类问题,期望最终输出的结果是0或1。可以在得到感知机的输出y之后,再加一个后处理判断,如果y>0.5,则判为类别1,否则判为类别0,这就是采用感知机来实现手写数字0和1二分类的方法,可以表示为下图:
1. 传统编程方法与机器学习方法的本质区别
用感知机来实现二分类的可行性已经得到验证了,在开始具体的实现之前,先来理解传统编程方法与机器学习方法之间的区别。
传统编程方法的模式
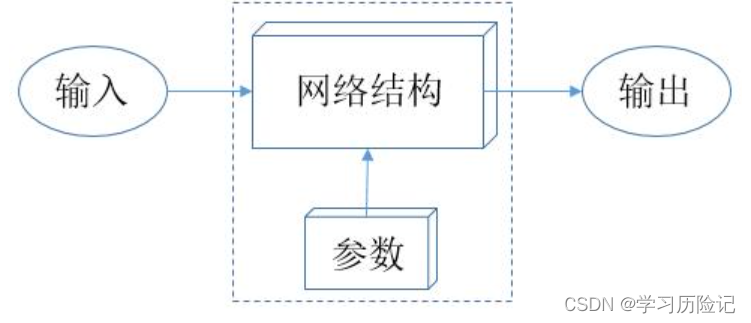
传统编程方法的模式可以用下图来表示,大多数程序都可以看成是一个盒子,给定明确的输入,得到明确的输出,而且这个程序的实现逻辑都是由程序员一行行编写出来的,人告诉计算机一步步怎么做,人完全能解释为什么给某个输入能得到某个输出。
机器学习方法的模式
机器学习方法的模式可以用下图来表示,核心在于“网络结构 + 参数”,也可以把它看成一个特殊的程序,只不过这个程序不是由程序员编写出来的,人只定义了网络结构,而参数是由计算机通过机器学习方法“学习”得来的,人无法解释为什么要取这些参数值。

机器学习方法的学习模式
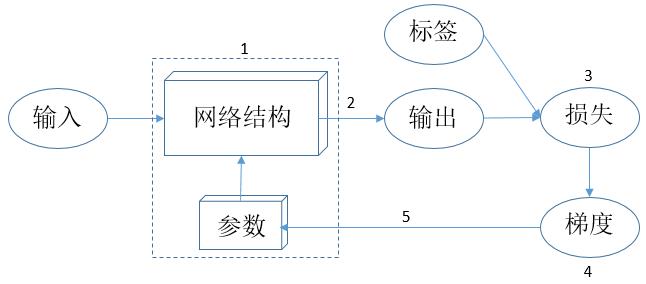
那么机器学习方法是如何“学习”的呢?思想其实很简单,可以用下图来表示:
上图的学习模式可以归纳为以下几点:
(1)定义网络结构,并给网络中的所有参数 w 赋予随机值;
(2)使用网络对一批样本进行预测,得到预测值pred_y;
(3)定义一个损失函数,如 $loss=(pred\_y-true\_y)^2$,true_y是指标签,模型训练的目的就是使得所有训练数据的损失之和尽可能地小;
(4)求得损失函数对所有参数的梯度 gradient_w;
(5)按照公式 w = w - lr * gradient_w 对所有参数w进行更新,其中lr是指学习率,常见的取值有0.01、0.001、0.0001等。
下面按照以上归纳的几点来实现整个机器学习过程,等完成所有代码实现之后,回顾理解。
2.加载数据集
开始实现机器学习过程之前,仍然是要先加载数据集。由于整个MNIST数据集是包含0~9的所有图片,现在研究的是简化的0和1的二分类问题,所以先从整个数据集中将所有手写数字0和1的图片挑选出来,同样也需要区分训练集和测试集。
挑选数字0和1的训练样本和测试样本
import os
import numpy as np
import mindspore.dataset as ds
datasets_dir = '../datasets'
if not os.path.exists(datasets_dir):
os.makedirs(datasets_dir)
import moxing as mox
if not os.path.exists(os.path.join(datasets_dir, 'MNIST_Data.zip')):
mox.file.copy('obs://modelarts-labs-bj4-v2/course/hwc_edu/python_module_framework/datasets/mindspore_data/MNIST_Data.zip',
os.path.join(datasets_dir, 'MNIST_Data.zip'))
os.system('cd %s; unzip MNIST_Data.zip' % (datasets_dir))
# 读取完整训练样本和测试样本
mnist_ds_train = ds.MnistDataset(os.path.join(datasets_dir, "MNIST_Data/train"))
mnist_ds_test = ds.MnistDataset(os.path.join(datasets_dir, "MNIST_Data/test"))
items_train = mnist_ds_train.create_dict_iterator(output_numpy=True)
train_data = np.array([i for i in items_train])
images_train = np.array([i["image"] for i in train_data])
labels_train = np.array([i["label"] for i in train_data])
items_test = mnist_ds_test.create_dict_iterator(output_numpy=True)
test_data = np.array([i for i in items_test])
images_test = np.array([i["image"] for i in test_data])
labels_test = np.array([i["label"] for i in test_data])
train_zeros = np.squeeze(images_train[labels_train==0])
train_ones = np.squeeze(images_train[labels_train==1])
test_zeros = np.squeeze(images_test[labels_test==0])
test_ones = np.squeeze(images_test[labels_test==1])
print('数字0,训练集规模:', len(train_zeros), ',测试集规模:', len(test_zeros))
print('数字1,训练集规模:', len(train_ones), ',测试集规模:', len(test_ones))数字0,训练集规模: 5923 ,测试集规模: 980
数字1,训练集规模: 6742 ,测试集规模: 1135
train_x = np.vstack((train_zeros, train_ones)) # 将数字0和1的样本汇总起来,np.vstack表示将两个数组进行垂直拼接
train_y = np.array([0] * len(train_zeros) + [1] * len(train_ones)).astype(np.uint8)
test_x = np.vstack((test_zeros, test_ones)) # 将数字0和1的样本汇总起来,np.vstack表示将两个数组进行垂直拼接
test_y = np.array([0] * len(test_zeros) + [1] * len(test_ones)).astype(np.uint8)train_x = train_x.reshape(-1, 28*28) # 每个样本变成一个行向量,因为行向量便于计算
train_y = train_y.reshape(-1, 1)
test_x = test_x.reshape(-1, 28*28) # 每个样本变成一个行向量,因为行向量便于计算
test_y = test_y.reshape(-1, 1)print(train_x.shape, train_y.shape, test_x.shape, test_y.shape)(12665, 784) (12665, 1) (2115, 784) (2115, 1)
3.混洗数据集
因为机器学习的方法是通过训练样本的训练来获取一个具备分类能力的模型,并且这个模型会更倾向于“记住”最后一批训练样本。如果给模型的训练数据的前一段全是数字0,后一段全是数字1,那么该模型最终就会倾向于更擅长分类数字1。因此,如果要使模型获得较平衡的分类能力,需要将训练数据打乱顺序。
测试集仅用于测试,不参与训练,不强制进行混洗,是一个可选的操作。
train_data = np.hstack((train_x, train_y)) # np.hstack表示将两个数组进行水平拼接
test_data = np.hstack((test_x, test_y)) # np.hstack表示将两个数组进行水平拼接
np.random.seed(0)
np.random.shuffle(train_data) # 打乱train_data数组的行顺序
np.random.shuffle(test_data) # 打乱test_data数组的行顺序
train_x = train_data[:, :-1] # 重新取出train_x和train_y
train_y = train_data[:, -1].reshape(-1, 1)
test_x = test_data[:, :-1] # 重新取出train_x和train_y
test_y = test_data[:, -1].reshape(-1, 1)查看图片及标签是否已被打乱
from PIL import Image
batch_size = 10 # 查看10个样本
print(train_y.flatten()[:batch_size].tolist())
batch_img = train_x[0].reshape(28, 28)
for i in range(1, batch_size):
batch_img = np.hstack((batch_img, train_x[i].reshape(28, 28))) # 将一批图片水平拼接起来,方便下一步进行显示
Image.fromarray(batch_img)[1, 0, 0, 1, 0, 0, 1, 1, 0, 0]

4.数据预处理
大多数机器学习的方法都要先将数据进行预处理再进行学习,预处理的方法有很多种,本案例只对数据进行归一化预处理。
归一化就是指将训练数据的取值范围变成[0, 1]。数据归一化有很多的好处,既可以使学习过程更快,也可以防止某些情况下训练过程出现计算溢出。
图像数据有很多种归一化方式,本案例采用的是整个数组除以255的方式,因为图像数组的最大值是255,除以255就可以使图像数据的取值范围变成[0, 1]。
train_x = train_x.astype(np.float) / 255.0
train_y = train_y.astype(np.float)
test_x = test_x.astype(np.float) / 255.0
test_y = test_y.astype(np.float)5. 封装成load_data函数
到此,完成了训练数据的准备工作,可以将以上操作封装成load_data函数,以便后面再次用到。
%%writefile ../datasets/MNIST_Data/load_data_zeros_ones.py
def load_data_zeros_ones(datasets_dir):
import os
import numpy as np
import mindspore.dataset as ds
# 读取完整训练样本和测试样本
datasets_dir = '../datasets'
mnist_ds_train = ds.MnistDataset(os.path.join(datasets_dir, "MNIST_Data/train"))
mnist_ds_test = ds.MnistDataset(os.path.join(datasets_dir, "MNIST_Data/test"))
items_train = mnist_ds_train.create_dict_iterator(output_numpy=True)
train_data = np.array([i for i in items_train])
images_train = np.array([i["image"] for i in train_data])
labels_train = np.array([i["label"] for i in train_data])
items_test = mnist_ds_test.create_dict_iterator(output_numpy=True)
test_data = np.array([i for i in items_test])
images_test = np.array([i["image"] for i in test_data])
labels_test = np.array([i["label"] for i in test_data])
train_zeros = np.squeeze(images_train[labels_train==0])
train_ones = np.squeeze(images_train[labels_train==1])
test_zeros = np.squeeze(images_test[labels_test==0])
test_ones = np.squeeze(images_test[labels_test==1])
print('数字0,训练集规模:', len(train_zeros), ',测试集规模:', len(test_zeros))
print('数字1,训练集规模:', len(train_ones), ',测试集规模:', len(test_ones))
train_x = np.vstack((train_zeros, train_ones)) # 将数字0和1的样本汇总起来,np.vstack表示将两个数组进行垂直拼接
train_y = np.array([0] * len(train_zeros) + [1] * len(train_ones)).astype(np.uint8)
test_x = np.vstack((test_zeros, test_ones)) # 将数字0和1的样本汇总起来,np.vstack表示将两个数组进行垂直拼接
test_y = np.array([0] * len(test_zeros) + [1] * len(test_ones)).astype(np.uint8)
train_x = train_x.reshape(-1, 28*28) # 每个样本变成一个行向量,因为行向量便于计算
train_y = train_y.reshape(-1, 1)
test_x = test_x.reshape(-1, 28*28) # 每个样本变成一个行向量,因为行向量便于计算
test_y = test_y.reshape(-1, 1)
train_data = np.hstack((train_x, train_y)) # np.hstack表示将两个数组进行水平拼接
test_data = np.hstack((test_x, test_y)) # np.hstack表示将两个数组进行水平拼接
np.random.seed(0)
np.random.shuffle(train_data) # 打乱train_data数组的行顺序
np.random.shuffle(test_data) # 打乱test_data数组的行顺序
train_x = train_data[:, :-1] # 重新取出train_x和train_y
train_y = train_data[:, -1].reshape(-1, 1)
test_x = test_data[:, :-1] # 重新取出train_x和train_y
test_y = test_data[:, -1].reshape(-1, 1)
train_x = train_x.astype(np.float) / 255.0
train_y = train_y.astype(np.float)
test_x = test_x.astype(np.float) / 255.0
test_y = test_y.astype(np.float)
return train_x, train_y, test_x, test_y6. 定义网络结构
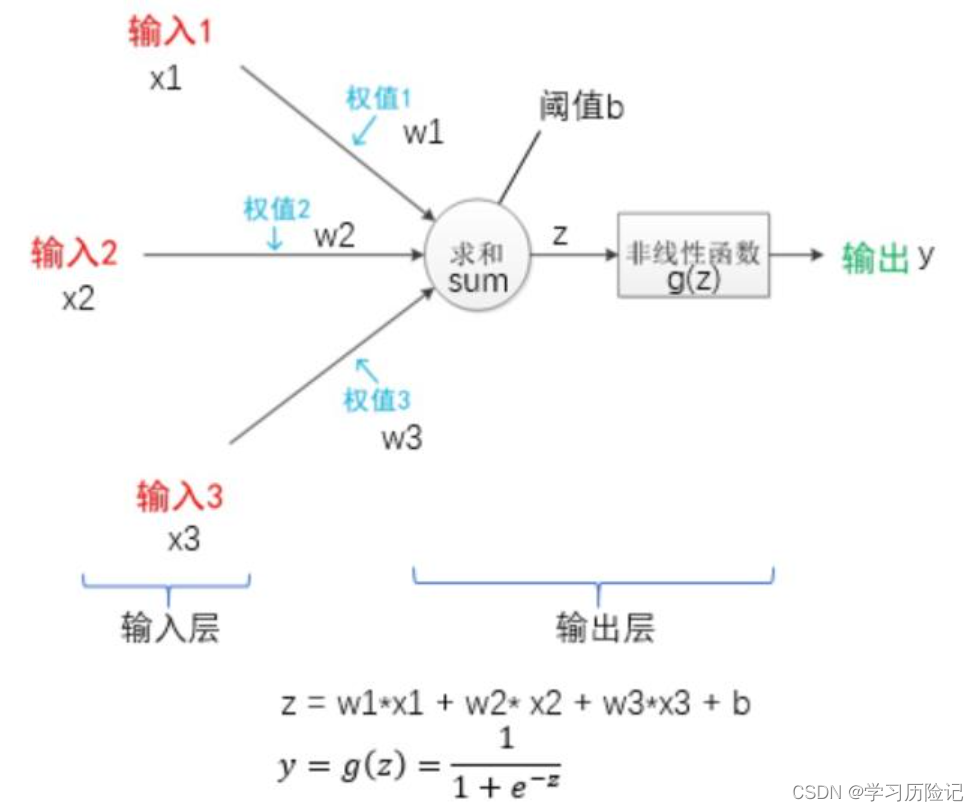
本案例的网络采用如上图所示的感知机结构,除去输入X和输出y之外,图中的权值W、阈值b、加权求和函数单元、非线性函数单元都需要定义,通过下面的代码来实现网络结构的定义。
np.random.seed(0)class Network(object):
def __init__(self, num_of_weights):
self.w = np.random.randn(num_of_weights, 1) # 使用np.random.randn随机生成一个 num_of_weights*1 的列向量,该向量即为权值w
self.b = 0.
def forward(self, x): # 加权求和单元和非线性函数单元通过定义计算过程来实现
z = np.dot(x, self.w) + self.b # 加权求和
pred_y = 1.0 / (1.0 + np.exp(-z)) # 非线性函数sigmoid
return pred_y随机初始化两个网络,并对同一个样本进行预测
net1 = Network(28*28)
sample = train_x[0]
true_y = train_y[0]
pred_y_1 = net1.forward(sample)
print('true_y:', true_y, 'pred_y:', pred_y_1)true_y: [1.] pred_y: [0.00037376]
net2 = Network(28*28)
sample = train_x[0]
true_y = train_y[0]
pred_y_2 = net2.forward(sample)
print('true_y:', true_y, 'pred_y:', pred_y_2)true_y: [1.] pred_y: [0.96392999]
7.定义损失函数
上面的两个网络对同一个标签为1的样本进行了预测,net1的预测值是0.00006124,net2的预测值是0.99999943,显然net2的预测值更接近真实值,可以做出评价:net2对train_x[0]这个样本的预测效果比net1更好。
要设计出一个能自我学习、自我改进的网络,就得告诉计算机当前这个网络到底好不好,并且要有一个量化的指标来衡量“好”或“不好”的程度,这个量化的指标在机器学习当中就称为损失值loss。
计算loss有很多种方法,常用的一种方法就是均方误差,公式:$loss=(pred\_y-true\_y)^2$ 于是,可以计算上面net1和net2两个网络在train_x[0]这个样本上的损失值,可以看到loss2比loss1小 。
loss1 = (pred_y_1 - true_y)**2
loss2 = (pred_y_2 - true_y)**2
print('loss1:', loss1, 'loss2:', loss2)loss1: [0.99925262] loss2: [0.00130105]
但是,评价某个网络好不好,不是在单个样本上进行评价,而是要在一批样本上进行评价,所以就要计算一批样本的损失值。对上面单个样本的损失值计算公式进行改进,就可以得到一批样本的损失值计算公式,具体如下: $ loss=\frac{1}{N}\sum^{N}_{i=0}{(pred\_y-true\_y)^2} $
于是,我们可以使用如下代码来定义网络的损失函数 :
class Network(object):
def __init__(self, num_of_weights):
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1) # 使用np.random.randn随机生成一个 num_of_weights*1 的列向量,该向量即为权值W
self.b = 0.
def forward(self, x): # 加权求和单元和非线性函数单元通过定义计算过程来实现
z = np.dot(x, self.w) + self.b # 加权求和
pred_y = 1.0 / (1.0 + np.exp(-z)) # 非线性函数sigmoid
return pred_y
def loss_fun(self, pred_y, true_y):
"""
pred_y:网络对一批样本的预测值组成的列向量
true_y:一批样本的真实标签
"""
error = pred_y - true_y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost下面我们可以计算十个样本的总体损失值:
net3 = Network(28*28)
sample = train_x[0:10]
true_y = train_y[0:10]
pred_y = net3.forward(sample)
print('loss:', net3.loss_fun(pred_y, true_y))loss: 0.39990529371765265
8.定义评价函数
定义好损失函数之后,还要定义评价函数。这两个函数都是用来评估模型的表现,容易混淆它们的含义,下面来解释两者的区别:
(1)损失函数是用于衡量模型的预测值和真实值之间的偏差,偏差越大,梯度就越大,对参数更新的幅度就越大,整个机器学习过程的目标就是是损失函数的值尽可能地小;
(2)评价函数有多种评价指标,常用的指标是准确率,它是用于统计模型预测结果的正确率,比如有100个测试样本,其中有99个都预测正确了,准确率就是99%;
言而简之,损失函数是作用于梯度下降过程的,评价函数是统计模型的评价指标给人看的。
class Network(object):
def __init__(self, num_of_weights):
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1) # 使用np.random.randn随机生成一个 num_of_weights*1 的列向量,该向量即为权值W
self.b = 0.
def forward(self, x): # 加权求和单元和非线性函数单元通过定义计算过程来实现
z = np.dot(x, self.w) + self.b # 加权求和
pred_y = 1.0 / (1.0 + np.exp(-z)) # 非线性函数sigmoid
return pred_y
def loss_fun(self, pred_y, true_y):
"""
pred_y:网络对一批样本的预测值组成的列向量
true_y:一批样本的真实标签
"""
error = pred_y - true_y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def evaluate(self, pred_y, true_y, threshold=0.5):
pred_y[pred_y < threshold] = 0 # 预测值小于0.5,则判为类别0
pred_y[pred_y >= threshold] = 1
acc = (pred_y == true_y).float().mean()
return acc9. 手工推导实现梯度下降算法
实现梯度下降算法就是两个步骤:
(1)求得损失函数对所有参数的梯度 gradient_w;
(2)按照公式 w = w - lr * gradient_w 对所有参数w进行更新
关键的步骤在第一步,如果需从零实现损失函数对所有参数的梯度计算方法,则需要一定的数学基础进行公式推导,可以查看下面代码中的 gradient 函数。第二步的实现很简单,见下面代码中的 update 函数。
class Network(object):
def __init__(self, num_of_weights):
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1) # 使用np.random.randn随机生成一个 num_of_weights*1 的列向量,该向量即为权值W
self.b = 0.
def forward(self, x): # 加权求和单元和非线性函数单元通过定义计算过程来实现
z = np.dot(x, self.w) + self.b # 加权求和
pred_y = 1.0 / (1.0 + np.exp(-z)) # 非线性函数sigmoid
return pred_y
def loss_fun(self, pred_y, true_y):
"""
pred_y:网络对一批样本的预测值组成的列向量
true_y:一批样本的真实标签
"""
error = pred_y - true_y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def evaluate(self, pred_y, true_y, threshold=0.5):
pred_y[pred_y < threshold] = 0 # 预测值小于0.5,则判为类别0
pred_y[pred_y >= threshold] = 1
acc = (pred_y == true_y).float().mean()
return acc
def gradient(self, x, y, pred_y):
gradient_w = (pred_y-y)*pred_y*(1-pred_y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (pred_y - y)*pred_y*(1-pred_y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, eta = 0.01):
self.w = self.w - eta * gradient_w
self.b = self.b - eta * gradient_b10.实现训练函数

训练函数的过程,就是把上图中的2、3、4、5点子过程串起来,详情查看下面代码中的 train 函数。
class Network(object):
def __init__(self, num_of_weights):
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1) # 使用np.random.randn随机生成一个 num_of_weights*1 的列向量,该向量即为权值W
self.b = 0.
def forward(self, x): # 加权求和单元和非线性函数单元通过定义计算过程来实现
z = np.dot(x, self.w) + self.b # 加权求和
pred_y = 1.0 / (1.0 + np.exp(-z)) # 非线性函数sigmoid
return pred_y
def loss_fun(self, pred_y, true_y):
"""
pred_y:网络对一批样本的预测值组成的列向量
true_y:一批样本的真实标签
"""
error = pred_y - true_y
num_samples = error.shape[0]
cost = error * error
cost = np.sum(cost) / num_samples
return cost
def evaluate(self, pred_y, true_y, threshold=0.5):
pred_y[pred_y < threshold] = 0 # 预测值小于0.5,则判为类别0
pred_y[pred_y >= threshold] = 1
acc = np.mean((pred_y == true_y).astype(np.float))
return acc
def gradient(self, x, y, pred_y):
gradient_w = (pred_y-y)*pred_y*(1-pred_y)*x
gradient_w = np.mean(gradient_w, axis=0)
gradient_w = gradient_w[:, np.newaxis]
gradient_b = (pred_y - y)*pred_y*(1-pred_y)
gradient_b = np.mean(gradient_b)
return gradient_w, gradient_b
def update(self, gradient_w, gradient_b, lr = 0.01):
self.w = self.w - lr * gradient_w
self.b = self.b - lr * gradient_b
def train(self, train_x, train_y, test_x, test_y, max_epochs=100, lr=0.01):
train_losses = []
test_losses = []
train_accs = []
test_accs = []
for epoch in range(1, max_epochs + 1):
pred_y_train = self.forward(train_x)
gradient_w, gradient_b = self.gradient(train_x, train_y, pred_y_train)
self.update(gradient_w, gradient_b, lr)
if (epoch == 1) or (epoch % 200 == 0):
pred_y_test = self.forward(test_x)
train_loss = self.loss_fun(pred_y_train, train_y)
test_loss = self.loss_fun(pred_y_test, test_y)
train_acc = self.evaluate(pred_y_train, train_y)
test_acc = self.evaluate(pred_y_test, test_y)
print('epoch: %d, train_loss: %.4f, test_loss: %.4f, train_acc: %.4f, test_acc: %.4f' % (epoch, train_loss, test_loss, train_acc, test_acc))
train_losses.append(train_loss)
test_losses.append(test_loss)
train_accs.append(train_acc)
test_accs.append(test_acc)
return train_losses, test_losses, train_accs, test_accs11.开始训练
训练耗时约615秒
import time
start_time = time.time()
# 创建网络
net = Network(28*28)
max_epochs = 3000
# 启动训练
train_losses, test_losses, train_accs, test_accs = net.train(train_x, train_y, test_x, test_y, max_epochs=max_epochs, lr=0.01)
print('cost time: %.1f s' % (time.time() - start_time))epoch: 1, train_loss: 0.5230, test_loss: 0.5282, train_acc: 0.4707, test_acc: 0.4652
epoch: 200, train_loss: 0.5216, test_loss: 0.5268, train_acc: 0.4715, test_acc: 0.4652 epoch: 400, train_loss: 0.5199, test_loss: 0.5251, train_acc: 0.4726, test_acc: 0.4657 epoch: 600, train_loss: 0.5177, test_loss: 0.5228, train_acc: 0.4736, test_acc: 0.4681 epoch: 800, train_loss: 0.5148, test_loss: 0.5199, train_acc: 0.4753, test_acc: 0.4704 epoch: 1000, train_loss: 0.5109, test_loss: 0.5161, train_acc: 0.4776, test_acc: 0.4733 epoch: 1200, train_loss: 0.5057, test_loss: 0.5110, train_acc: 0.4815, test_acc: 0.4761 epoch: 1400, train_loss: 0.4987, test_loss: 0.5039, train_acc: 0.4870, test_acc: 0.4813 epoch: 1600, train_loss: 0.4891, test_loss: 0.4938, train_acc: 0.4949, test_acc: 0.4870 epoch: 1800, train_loss: 0.4752, test_loss: 0.4787, train_acc: 0.5047, test_acc: 0.4983 epoch: 2000, train_loss: 0.4532, test_loss: 0.4548, train_acc: 0.5197, test_acc: 0.5191 epoch: 2200, train_loss: 0.4166, test_loss: 0.4169, train_acc: 0.5529, test_acc: 0.5499 epoch: 2400, train_loss: 0.3610, test_loss: 0.3630, train_acc: 0.5998, test_acc: 0.6014 epoch: 2600, train_loss: 0.2896, test_loss: 0.2913, train_acc: 0.6692, test_acc: 0.6638 epoch: 2800, train_loss: 0.2191, test_loss: 0.2173, train_acc: 0.7447, test_acc: 0.7428 epoch: 3000, train_loss: 0.1631, test_loss: 0.1582, train_acc: 0.8032, test_acc: 0.8061
cost time: 615.7 s
12.训练过程可视化
将训练过程中的train_loss, test_loss, train_acc, test_acc绘制成曲线图,分析这些指标的变化趋势
import matplotlib.pyplot as plt
%matplotlib inline
# 画出各指标的变化趋势
plot_x = np.arange(0, max_epochs+1, 200)
plot_y_1 = np.array(train_losses)
plot_y_2 = np.array(test_losses)
plot_y_3 = np.array(train_accs)
plot_y_4 = np.array(test_accs)
plt.plot(plot_x, plot_y_1)
plt.plot(plot_x, plot_y_2)
plt.plot(plot_x, plot_y_3)
plt.plot(plot_x, plot_y_4)
plt.show() 