



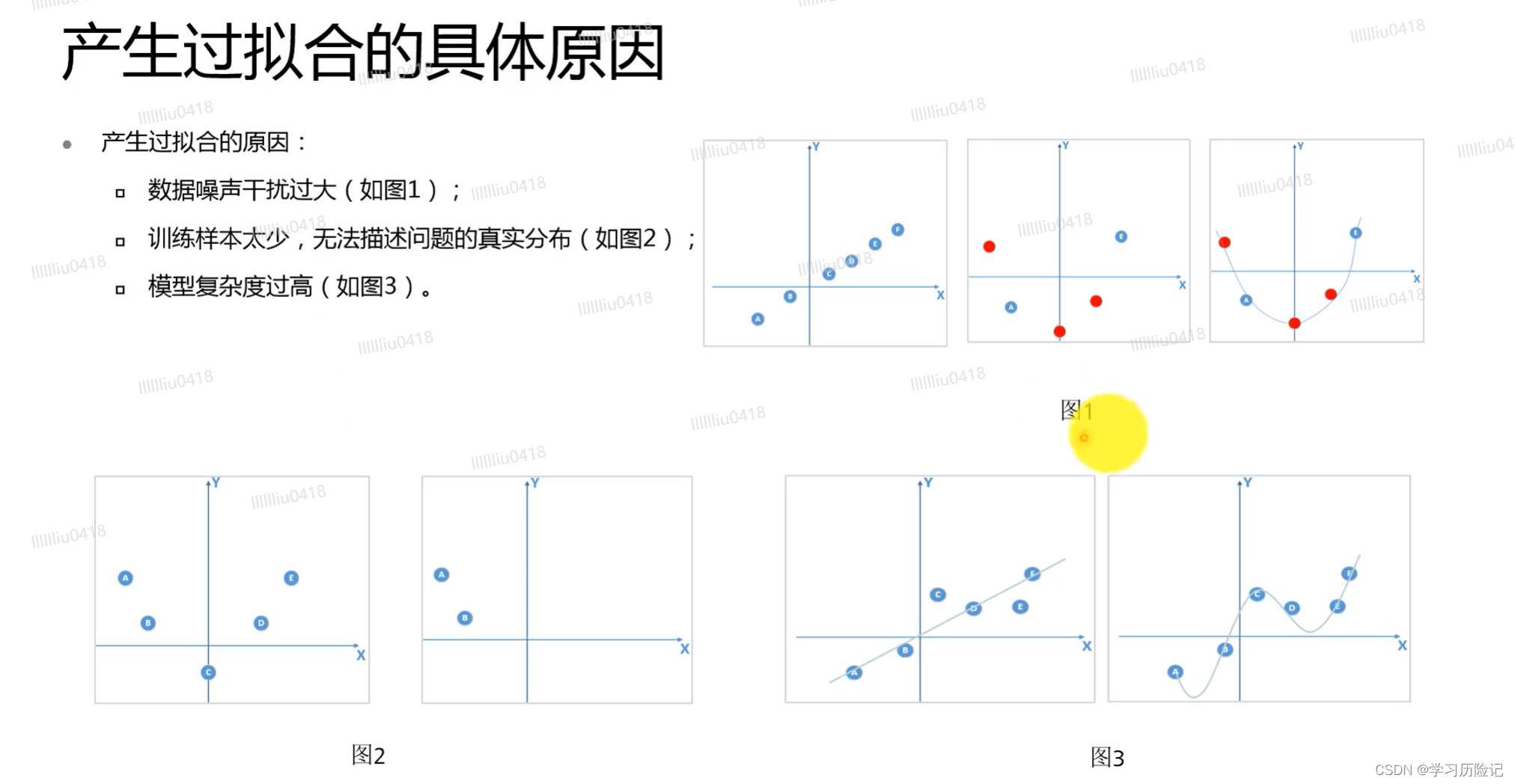


数据增强:1不要太过,否则只增加训练时间,不会增加泛化能力;2不增加无关的数据


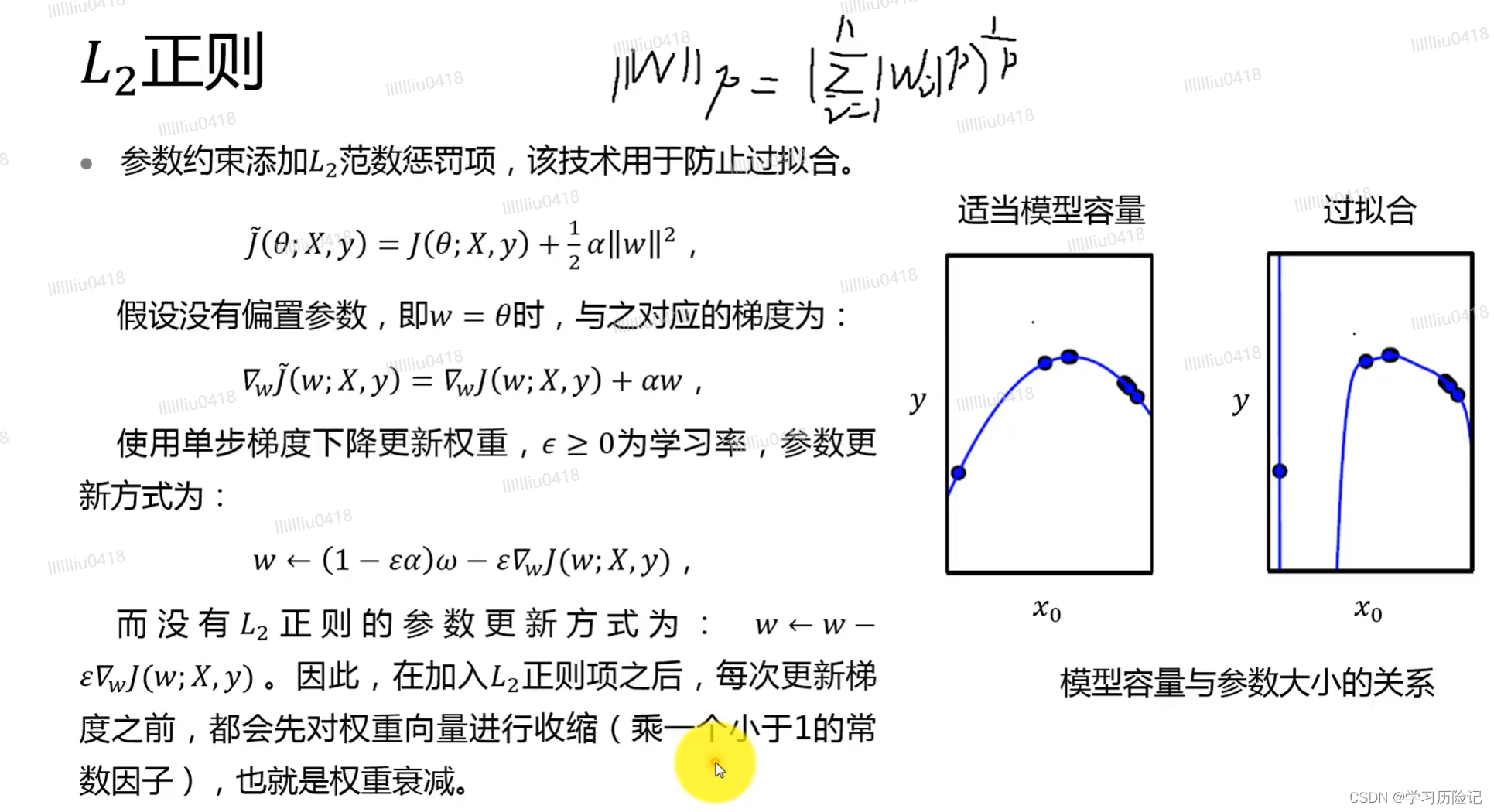
L2正则:倾向于对训练集样本共有特性的响应;使模型偏好参数小的样本,减小过拟合的风险

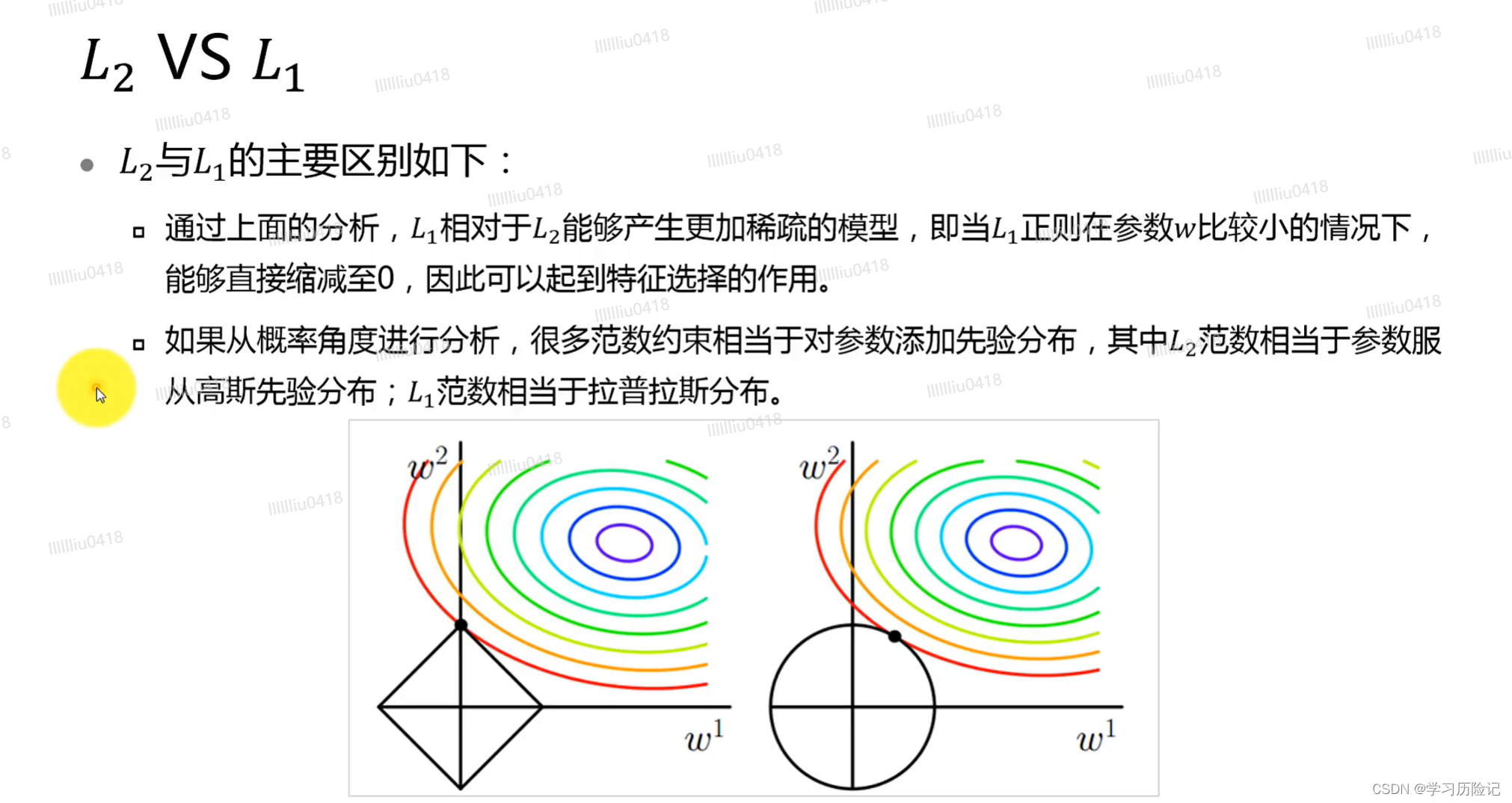



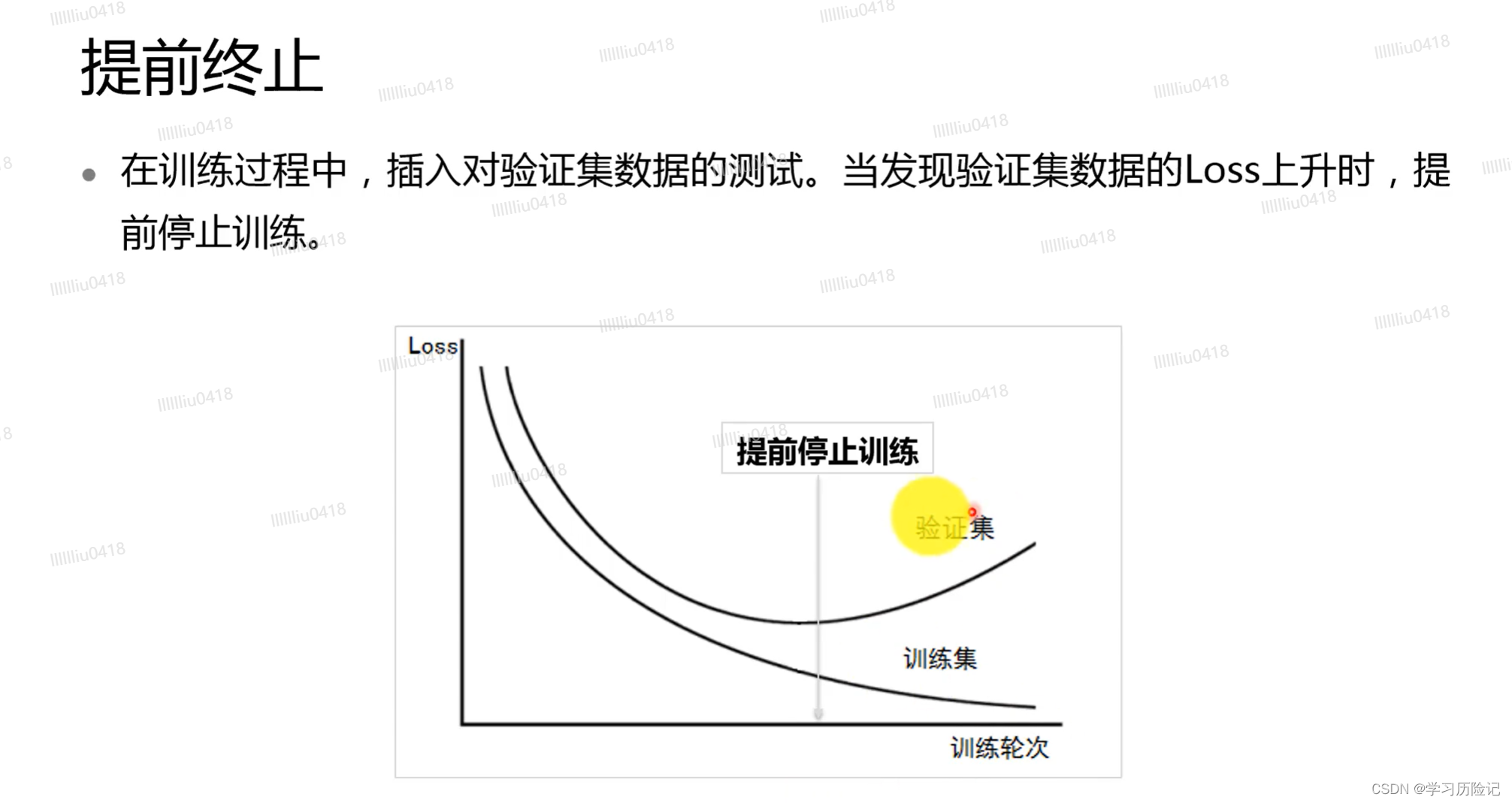


几种常见的优化器


对于稀疏数据,尽量选用学习率可自适应的优化方法,不需要手动调节,最好采用默认值。
随机梯度下降算法通常训练时间更长,容易陷入鞍点,但是在好的初始化和学习率调度方案情况下,结果更可靠。
整体来说,Adam是目前最好选择。

数据增强:1不要太过,否则只增加训练时间,不会增加泛化能力;2不增加无关的数据
L2正则:倾向于对训练集样本共有特性的响应;使模型偏好参数小的样本,减小过拟合的风险
几种常见的优化器
对于稀疏数据,尽量选用学习率可自适应的优化方法,不需要手动调节,最好采用默认值。
随机梯度下降算法通常训练时间更长,容易陷入鞍点,但是在好的初始化和学习率调度方案情况下,结果更可靠。
整体来说,Adam是目前最好选择。