MIG(Multi-Instance GPU)作为Ampere架构推出的新特性,解决了像Ampere这种大GPU在集群服务应用时的一类需求:GPU切分与虚拟化。
本文主要是介绍MIG相关的概念与使用方法,通过实际操作带读者了解该特性的基本情况,最后亲测了几个训练作业,记录了一些对比测试数据供大家参考。
列出几个问题,读者可根据需要直接跳转到对应章节:
- 为什么需要MIG?直接用vGPU不行吗?(见1 和 2.1.3)
- MIG 如何进行创建/删除/查看操作? (见3.1 )
- MIG切分后算力竞争情况如何?(见3.3测试)
- MIG 上面的GI与CI 是什么?有什么关联关系 ?(见2.2)
- MIG是不是一块完全独立的子GPU?支持NVLINK吗?
1 背景介绍
GPU的切分(虚拟化)需求基本来自于两个方面,一个是普通消费者,二个是计算/服务中心。
对于普通消费者(用户),希望使用到新推出的GPU特性,比如某些高性能的CUDA操作,而这些操作只有高版本的硬件SM才具备;同时,很多情况下消费者并不能用满一整张显卡(比如V100或者A100)的所有资源;另外“数据中心”类的GPU产品,价格都比较高(V100、A100都是wRMB为单位)。所以消费者在使用、价格方面有小资源高性能的GPU需求。

某购物平台上面的GPU价格
对于服务厂商(比如云服务),一方面需要提供价格便宜、性能稳定的GPU给用户使用。由于整卡的成本价格高,所以服务费用(租金)不会太低。另一个方面,大型的计算中心需要管理成千上万的GPU,服务厂商有提升集群利用率的诉求,小规格的GPU资源能够提升配置的细粒度,从而能够更好的提升集群GPU利用率。
目前,对于像V100这样的GPU,有些厂商会让多个用户来共用一张GPU,从而降低单个用户的费用。在共享GPU过程中,一个重要的操作就是虚拟化,但是虚拟化在安全问题、服务质量上面还有较大的进步空间。
下面先来简单看一下MIG之前虚拟化的情况:
NVIDIA 的vGPU
vGPU是NVIDIA推出的一个支持在VM应用上的虚拟GPU软件,它支持在一块物理GPU创建许多小型的虚拟GPU,并让这些虚拟GPU提供给不同的用户使用。
其内部原理如下图所示,对于物理硬件的虚拟化,主要分为两个:存储的虚拟化、运算的虚拟化。

基于时间片的vGPU
存储:通过创建专用的buf(dedicated framebuffer),事先占据方式创建虚拟GPU的存储空间;
运算:通过时间片管理器(scheduling)来控制任务对GPU物理设备引擎的使用时间;
基于时间片(time-sliced) 的vGPU本质上面还是让任务公用物理设备(引擎),通过改变虚拟GPU的时间片使用多少,来控制任务对整个物理设备上的资源的使用量。 这么方式虽然能够满足一些应用场景,但是由于物理卡上的资源是公用的,所有任务要轮着用,使得整卡切分后在算力/带宽/任务切换上面难做到好的QoS。举个例子,比如两个任务要共用Video Decode设备时会涉及任务的来回切换,相比按照比例来使用的方式(假设有4个Video Decode,每个任务使用两个)的成本更高。 同时对于每个任务而言,并不是所有任务都能够使用一张完整GPU的全部资源,单个任务运算时会产生一定的资源浪费。
国内虚拟化情况
国内GPU虚拟化的方式基本上是参考vGPU的方式,比如华为云ModelArts(mGPU)、阿里云GPU服务(cGPU)、腾讯云(qGPU)、第四范式等。GPU的虚拟化基本围绕:数据是否安全、隔离是否充分、QoS是否能够保证这三个问题来进行设计。不可否认,这些虚拟化都取得了很好的效果,而且对集群资源利用率的提升上面帮助很大。但是毕竟不能修改约束底层硬件,在安全和资源分配平衡上始终都存在局限。还有就是,软件切分隔离会带来物理卡的资源浪费,切分越多浪费越严重(有公司称小于5%,亲测远大于这个水平)。
MIG:
NVIDIA洞察到了小规格GPU的市场动向,所以干脆自己推出了一个MIG特性,从硬件设计上面就考虑到了GPU虚拟化的需求。MIG特性是在Ampere架构上面首次推出的(2020年),Ampere系列产品主要是针对数据服务中心的使用场景,数据中心(比如云应用)有为用户提供更加多样的资源规格的诉求,而MIG能够丰富资源规格。MIG使得资源的配置更加灵活,帮助数据中心提高效率,同时也给降低了用户使用GPU的成本。

MIG concept
2 MIG的介绍
2.1 MIG结构
2.1.1 基本原理
Ampere架构通过硬件上面的设计使得GPU能够创建子GPU(GI),GI在计算、内存带宽、故障隔离、错误计算、错误恢复方面都相对独立,其服务质量(QoS)能够较好的保证。MIG的基本方法(原理)就是能完成资源的分块+组合,即对物理卡上能用的物理资源进行切分,这些资源包括:系统通道、控制总线、算力单元(TPC)、全局显存、L2 cache、数据总线等;然后将分块后的资源重新组合,让每个切分后的子GPU 能够做到数据保护、故障隔离独立、服务稳定。
过程1--分块
一个完整的Ampere架构上面资源主要包括运算引擎和存储,对于这些资源可以进行划分,如下图所示,将一个A100 40GB的GPU进行资源划分,将算力均分为了7份,显存分割为了8份。相同的资源,在硬件上面可以认为有较高的匀质性。

资源分块
过程2--组合
组合是指将分块的资源进行重组搭配,主要是组合算力引擎和存储单元,如下所示,可以将1个算力单位和一个存储单位进行组合,从而够成了一个1g.5gb的GPU实例(子GPU)。当然,我们还以进行其它规格的组合,这个由profile来确定,具体参看后面章节。

资源组合
上图的分块组合的过程中没有展示一些资源,如系统通道,L2 cache等,MIG也能够完成对这些资源分块与组合。操作结束后,可以认为在物理GPU上面建立了一系列的子GPU,这些子GPU能够配合上层应用满足不同场景下的用户需求。下图中例出了7个GI实例,每个用户实例都相对独立,每个子GPU都支持一个上层用户使用Ampere架构的大部分特性。

GPU的切分为7个实例
当然,资源也可以进行不等切分。根据使用场景的需求,可以增加/减少配置的资源,如下图所示,展示了几个应用场景下同时使用一块物理GPU的例子。

实例1:四个CUDA进程共用了一个子GPU,每个进程消耗1个算力单元,其它单元共用。
实例2和3:应用/任务拥有独立的资源。
2.1.2 配置过程
MIG的配置过程是相对灵活的,支持算力、存储、其它引擎(CE、DEC等)的“格式化”组合。创建MIG过程可以分为两个大的步骤:从物理GPU上圈资源建立GI(GPU Instance),然后从创建的GI上面创建CI(Compute Instance)。
step1:创建GI实例。 从物理GPU上面,将需要的分块好的单元选取出来,组合成一个小的GPU。
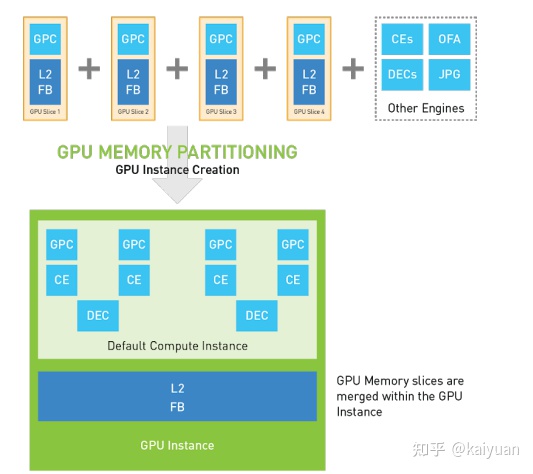
GI创建过程
step2:创建计算实例。在上一步基础上面,创建CI。如果按照默认方式,GI上的所有GPC可以作为一个整体使用;但是GI还能够进一步的划分,即对计算单元进行再次分割,这样创建出来的子GPU在一个GI上面的算力独立,其它单元在GI内部是共享。如下图所示,step1的GI基础上面切割出了两个CI,每个CI拥有两个GPC。

CI 创建过程
总体来说,MIG的资源创建存在两次划分过程,先划分GI资源,再划分CI资源,这样通过排列组合,增加了配置的多样性。但是这些组合并不是随意的,必须遵循一定的规则,按照MIG设定的(profile)进行配置,具体看2.2节。
2.1.3 配备MIG的vGPU
MIG和vGPU目标都是对物理GPU进行虚拟化来满足应用需求。vGPU能够结合MIG使用,什么意思? 就是在MIG的基础上可以进一步使用vGPU。MIG出现之前,vGPU底层的实现用的是时间分片模式(time-sliced),我们比较MIG和vGPU,一般是对比“时间分片模式vGPU”和“MIG版的vGPU”,如下图,例举两者在架构上面的差异:

文章开头抛出了一个问题"有vGPU了,为什么还要MIG?",背景介绍时提到了“算力/带宽/任务切”等概念,这里我们可以通过分析一组测试数据(数据出处看文末),对比数据可得到MIG相比“时间分片”模式vGPU的优势。 测试使用的是Mask R-CNN training网络,对比列出了训练的时间,训练的吞吐,推理的时间,推理的吞吐的对比。
训练(时间-左,吞吐-右):

训练性能差异
推理(时间-左,吞吐-右):

推理性能差异
从数据可知MIG-vGPU 的表现优于 Time-sliced vGPU。
插一句:连NVIDIA自己的vGPU (Time-sliced)在实测条件下的表现都这样,国内的XXX厂商造出来的虚拟GPU效果可想而知。2.1.4 MIG与MPS以及Stream的对比
在Nvidia的显卡中,并行/并发机制主要是Stream和MPS,Stream可以看成是GPU与CPU互动的运行进程,多个Stream任务可以并发来使用GPU;MPS则是通过融合context方式让多任务来使用GPU;MIG通过隔离让多个任务同时使用GPU。三种并发机制存在着差异,如下表所示:
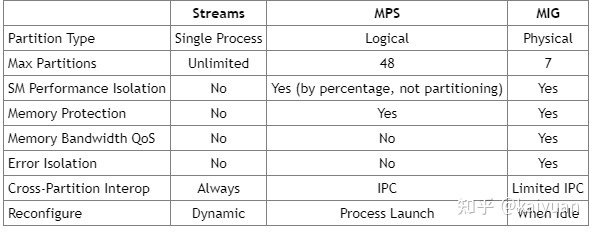
多任务机制的对比
我们主要看一下并发的数量、算力隔离、以及隔离的情况的差异,可以看到MIG 的配置灵活性有所下降,分片的数量较小(只有7),而在其它方面的表现较Stream和MPS好。
2.2 操作过程涉及的概念
要了解MIG的操作过程,首先要理解这个过程涉及到的概念。与MIG相关的概念有些是既有的,有些是根据MIG的需求提出的,主要看一下相关专业术语:
> 引擎与存储:
- SM/TPC/GPC:在GPU中,SM是计算的基本块(里面包含了core、L1cache等),TPC和GPC则是SM组合的更大计算块,详细概念可参考:
kaiyuan:GPU硬件分析---Tesla 架构245 赞同 · 12 评论文章正在上传…重新上传取消
- CE:拷贝引擎(Copy Engine)工作是数据搬运。很多情况下,数据搬运会成为GPU处理的瓶颈,所以进行GPU切分时,对CE的合理分配也相当重要。
- DEC/ENC:NVDEC/ENC是视频加解码引擎,这个模块对于很多计算为非必须的。 A100配有 5DEC。
- JPG: 针对图像的nvJPEG引擎。A100上一种JPEG解码器硬件,每个A100配有一个。
- OFA:光流加速器(Optical Flow Accelerator),每个A100配有一个。
- Memory:主要是Global Memory、L2cache存储,其它存储在SM中。
> 分片:
- Slice:对引擎/存储进行分片,为后续的GPU组合提供基础单元模块。
- GPU Instance:子GPU的实例,简称GI。可以独立的运性,并且拥有完整GPU所支持的大部分特性。
- Computer Instance:子GPU里面的计算实例,简称CI。 在MIG的GI实例中,还可以对算力进行进一步的划分。
MIG的编号/名称
MIG-device的编号有两种,第一种:把GI上面的CI作为一个整体,不对算力进行进一步的划分时,MIG的编号只有两位,如:3g.20gb,其中3g表示算力有3个单位(一个A100有7个单位),20gb表示内存有20个单位(一个A100有80gb)。如下例出3个组合命名格式:

GI 示例
第二种:在GI的基础上,进一步划分CI,此时需要用一个新单位c,用来表示分片GPU占据的计算单元数量,如:1c.3g.20gb ,其中1c表示占用了1个单位的计算量(一共是3g)。如下表所示,展示了3g算力的两种划分,一种是建立3个同样算力的1c规格,另一种是建立一个2c + 1c的规格。

CI 示例
注意一个关键问题:CI的切分的只是算力,也就是除了GPC算力单元,其它单元是共享的。
- Profile:GPU切分支持的类型/格式。子GPU并不是能够随意组合GPU中的资源,必须按照固定的格式进行组合,这些组合格式可以通过命令行查看(nvidia-smi mig -lgip,具体参看3.1节)。
- Placement:子GPU的创建顺序/起始位置。子GPU的排列的位置并不是任意的,有一定的要求。
如下例出了(A100)支持的配置方式:

切片支持的配置方式
配置方式可能造成算力浪费,比如先创建了一个3g 的GI后只能创建 2g+ 1g实例,或者1g+1g+1g实例,或者3g实例,还有1g的算了无法用于创建新的GI实例。
3 实践与测试
本节重点简述一下MIG在linux机器上面的使用与测试,带大家看一下A100显卡上面怎么划分GPU,以及MIG测试效果。
测试机器的关键硬件: Intel(R) Xeon(R) Platinum 8378A CPU @ 3.00GHz * 128 显卡:NVIDIA A100-SXM4-80GB * 8 (机器很贵,市场价估计得150w,堪比豪华跑车,所以本次测试采用的机器是云服务机器,从享有“民族之光”XX企业的云服务上找的。租用云服务机器相对来说还是比较划算!)
测试用例1:torchvision.models.resnext101_32x8d
测试用例2:swin-transformer
3.1 MIG的基本操作
MIG的shell操作主要包括:查看命令、创建命令和删除命令。MIG的操作都要用root权限,所以如果是非root用户,操作命令要加上sudo字符,下面操作示例中默认用户是root。 首先将这些操作例出来,然后对一些创建与删除操作进行讲解。
| 功能 | 命令 | 说明 |
|---|---|---|
| 【开】指定某卡 开启MIG | nvidia-smi -i 0 -mig 1 | -i 指定的GPU编号 可以是0,1,3 |
| 【关】指定某卡 关闭MIG | nvidia-smi -i 0 -mig 0 | |
| 【开】全部卡的MIG功能 | nvidia-smi -mig 1 | 1 打开; 0 关闭; |
| 【查看】子GPU实例的profile | nvidia-smi mig -lgip | 获得子GPU可创建的情况 |
| 【查看】子GPU实例的placement | nvidia-smi mig -lgipp | 获得子GPU可以创建的位置 |
| 【查看】子GPU上CI的profile | nvidia-smi mig -lcip | 添加 -gi指定特定的子GPU,如指定子GPU 2查看上面的CI实例: nvidia-smi mig -lci -gi 2 |
| 【查看】已创建的子GPU的情况 | nvidia-smi mig -lgi | |
| 【创建】子GPU + 对应的CI | nvidia-smi mig -i 0 -cgi 9 -C | -i: 指定父GPU -cgi:列出需要创建的子GPU的类型 格式:9 或者 3g.20gb 或者 MIG 3g.20gb -C :连同一起创建CI |
| 【创建】子GPU | nvidia-smi mig -i 0 -cgi 9 | 创建一个profile为9的GI实例: 3个计算单元 + 20gb显存。 |
| 【创建】子GPU上面的CI | nvidia-smi mig -cci 0,1 -gi 1 | -cci:创建的CI实例的编号 -gi:指定子GPU |
| 【删除】子GPU | nvidia-smi mig -dgi -i 0 -gi 1 | -i:指定父GPU -gi:待删除的子GPU |
| 【删除】子GPU上面的CI 实例 | nvidia-smi mig -dci -i 0 -gi 1 -ci 0 | -i:指定父GPU -gi:待操作的子GPU -ci: 待删除的CI实例 |
| 【查看】 整个MIG实例情况 | nvidia-smi -L |
MIG的操作顺序概况为:
功能MIG -> 创建GI实例 -> 创建CI实例 -> 删除CI实例 -> 删除GI实例 -> 关闭MIG。
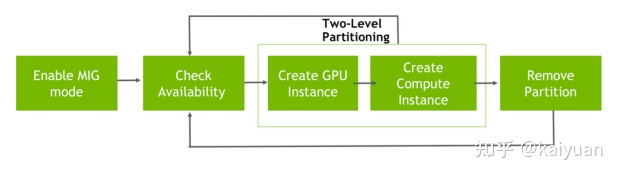
MIG的工作流
需要注意的是:
- GI实例创建可以伴随CI实例的创建,删除也是一样;
- CI实例的创建必须是在GI的基础之上;
- 一个物理卡可以创建多个GI(即子GPU),一个GI可以创建多个CI(计算实例),其对应关系:GPU包含GI,GI包含CI。
- 只创建GI 不创建CI,子GPU无法运行。
- 3.1.1 功能操作
默认情况下MIG功能是关闭的,使用前需要通过命令行打开。我们随意选取一张GPU进行测试。
## 产看7号GPU的状态,此时MIG功能处于Disabled的状态
# nvidia-smi -i 7
## 启动MIG功能:
# nvidia-smi -i 7 -mig 1
Enabled MIG Mode for GPU 00000000:F9:00.0
All done.
## 再次查看,可以看到 MIG 位置变为了Enabled,并且多了一行MIG devices信息。
# nvidia-smi -i 7
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.43.04 Driver Version: 515.43.04 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 7 NVIDIA A100-SXM... On | 00000000:F9:00.0 Off | On |
| N/A 31C P0 51W / 400W | 0MiB / 81920MiB | N/A Default |
| | | Enabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| MIG devices: |
+------------------+----------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG|
| | | ECC| |
|==================+======================+===========+=======================|
| No MIG devices found |
+-----------------------------------------------------------------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
## 关闭操作:
# nvidia-smi -i 7 -mig 0
Disabled MIG Mode for GPU 00000000:F9:00.0
All done.MIG的功能可能会遇到一些问题,会有pending的错误提示:
$ sudo nvidia-smi -i 0 -mig 1
Warning: MIG mode is in pending enable state for GPU 00000000:00:03.0:Not Supported
Reboot the system or try nvidia-smi --gpu-reset to make MIG mode effective on GPU 00000000:00:03.0
All done.可能的原因:
- GPU正在被某些程序使用;
- docker容器挂载了这个GPU;
- 某些server(比如nvsm dcgm)占用了GPU;
解决方案:
# nvidia-smi --gpu-reset
# systemctl stop nvsm
# systemctl stop dcgm
# docker stop [container] # 停止运行的容器当然实在找不到原因,考虑重启一下机器。
- 3.1.2 创建GI实例
在上面的功能MIG的基础上面,我们进一步来创建GI实例,即我们所需要的子GPU,首先我们产看一下可以创建些什么样的子GPU:
# nvidia-smi mig -i 7 -lgip
对这个profiles主要参数说明:
ID:子GPU的类型编号,等下创建GI实例时将用到;
Instances : FREE/TOTAL FREE,还能够创建的GI个数,TOTAL:最多创建的个数; 各个类型之间的Free数量是耦合的,比如创建了一个MIG 7g.80gb 那么再次查看时,其它Free数量都会变为0。
我们尝试创建一个MIG 3g.40gb 的实例:
## 创建
# nvidia-smi mig -i 7 -cgi 9
Successfully created GPU instance ID 1 on GPU 7 using profile MIG 3g.40gb (ID 9)
## 查看
# nvidia-smi mig -i 7 -lgi
+-------------------------------------------------------+
| GPU instances: |
| GPU Name Profile Instance Placement |
| ID ID Start:Size |
|=======================================================|
| 7 MIG 3g.40gb 9 1 4:4 |
+-------------------------------------------------------+MIG 3g.40gb 这个子GPU即创建成功了,也可以同时创建3个GI的示例:

示例的创建命令:nvidia-smi mig -i 7 -cgi 5,14,19
如果只创建了GI,这些GI并不能直接使用,因为它没有创建对应的计算实例CI,可以查看此时物理卡的状态:
# nvidia-smi -i 7
可以看到“No MIG devices found ” 说明子GPU还没有创建成功。
- 3.1.3 创建CI实例
CI的创建依赖GI。 CI可以只使用GI的部分算力,上面3.1.2步骤中我们创建了一个MIG 3g.40gb 的GI,它包含了3c的算力,对这个算力再次进行切分。首先,可通过查看CI的profile来获得CI的profiles:
# nvidia-smi mig -i 7 -lcip
+--------------------------------------------------------------------------------------+
| Compute instance profiles: |
| GPU GPU Name Profile Instances Exclusive Shared |
| Instance ID Free/Total SM DEC ENC OFA |
| ID CE JPEG |
|======================================================================================|
| 7 1 MIG 1c.3g.40gb 0 3/3 14 2 0 0 |
| 3 0 |
+--------------------------------------------------------------------------------------+
| 7 1 MIG 2c.3g.40gb 1 1/1 28 2 0 0 |
| 3 0 |
+--------------------------------------------------------------------------------------+
| 7 1 MIG 3g.40gb 2* 1/1 42 2 0 0 |
| 3 0 |
+--------------------------------------------------------------------------------------+可以看到该GI支持的CI类型有三种: MIG 1c.3g.40gb、MIG 2c.3g.40gb、 MIG 3g.40gb
每个类型所占的算力分别是1, 2, 3。 这些类型的创建是耦合的,比如创建了一个MIG 1c.3g.40gb 后,剩下的算力就只能创建 2c或者1c的CI实例了。
我们尝试创建一个 1c.3g.40gb 和一个2c.3g.40gb ,这样刚好把GI上面的3个算力都用完:
# nvidia-smi mig -i 7 -cci 0,1 -gi 1
Successfully created compute instance ID 0 on GPU 7 GPU instance ID 1 using profile MIG 1c.3g.40gb (ID 0)
Successfully created compute instance ID 1 on GPU 7 GPU instance ID 1 using profile MIG 2c.3g.40gb (ID 1)
## 查看创建的设备
# nvidia-smi -i 7
此时查看子GPU的UUID,会看到类似如下的格式(替换数字:XXX):
# nvidia-smi -L
GPU 7: NVIDIA A100-SXM4-80GB (UUID: GPU-XXXXXXXX-XXXX-XXXX-d94d-0653a519232f)
MIG 1c.3g.40gb Device 0: (UUID: MIG-XXXXXXXX-XXXX-XXXX-937b-d7d1304c37e5)
MIG 2c.3g.40gb Device 1: (UUID: MIG-XXXXXXXX-XXXX-XXXX-825f-d0b7d9521771)在GPU7 上面出现了两个子设备 “Device 0” 和“Device 1”。
- 3.1.4 直接创建GI + CI 实例
如果要直接创建一个子GPU 并且将其可用的运算单元都挂载上,在创建GI的时候添加-C参数即可完成。
# nvidia-smi mig -i 7 -cgi 5 -C
Successfully created GPU instance ID 2 on GPU 7 using profile MIG 4g.40gb (ID 5)
Successfully created compute instance ID 0 on GPU 7 GPU instance ID 2 using profile MIG 4g.40gb (ID 3)- 3.1.5 删除操作
MIG的删除操作设置得比较灵活,可以独立的删除GI或者CI,也可以一起删除。
以2.1.3 节里面创建的MIG删除为例:先删除CI,再删除GI:
# nvidia-smi mig -i 7 -dci
Successfully destroyed compute instance ID 0 from GPU 7 GPU instance ID 1
Successfully destroyed compute instance ID 1 from GPU 7 GPU instance ID 1
# nvidia-smi mig -i 7 -dgi
Successfully destroyed GPU instance ID 1 from GPU 7注意:当CI在使用时,直接尝试删除GI,会出现如下错误:
# nvidia-smi mig -i 7 -dgi
Unable to destroy GPU instance ID 1 from GPU 7: In use by another client
Failed to destroy GPU instances: In use by another client也可以只删除某个CI。比如在GPU7上面创建 一个MIG 4g.40gb的GI实例,并创建两个算力为1的 1c.4g.40gb,可以删除其中一个:
## 删除GPU卡7上面GI 2的 CI 1
# nvidia-smi mig -i 7 -dci -ci 1 -gi 2
Successfully destroyed compute instance ID 1 from GPU 7 GPU instance ID 2
# nvidia-smi -i 7
再次查看CI的情况,可以看到Free的MIG 1c.4g.40gb有3个。
nvidia-smi mig -i 7 -lcip
+--------------------------------------------------------------------------------------+
| Compute instance profiles: |
| GPU GPU Name Profile Instances Exclusive Shared |
| Instance ID Free/Total SM DEC ENC OFA |
| ID CE JPEG |
|======================================================================================|
| 7 2 MIG 1c.4g.40gb 0 3/4 14 2 0 0 |
| 4 0 |
+--------------------------------------------------------------------------------------+
| 7 2 MIG 2c.4g.40gb 1 1/2 28 2 0 0 |
| 4 0 |
+--------------------------------------------------------------------------------------+
| 7 2 MIG 4g.40gb 3* 0/1 56 2 0 0 |
| 4 0 |
+--------------------------------------------------------------------------------------+3.2 MIG的使用
MIG切分操作完成之后,我们可以通过nvidia-smi -L操作看到子GPU的device情况,比如:
# nvidia-smi -L
GPU 0: NVIDIA A100-SXM4-80GB (UUID: GPU-XXXXXXXX-XXXX-XXXX-5560-53df7b497d19)
MIG 4g.40gb Device 0: (UUID: MIG-XXXXXXXX-XXXX-XXXX-95e8-d57c8496c80c)
MIG 3g.40gb Device 1: (UUID: MIG-XXXXXXXX-XXXX-XXXX-84f6-3d95e0189339)
GPU 1: NVIDIA A100-SXM4-80GB (UUID: GPU-XXXXXXXX-XXXX-XXXX-2289-80e23288996e)
MIG 1g.10gb Device 0: (UUID: MIG-XXXXXXXX-XXXX-XXXX-8fd0-02af37e60f46)
GPU 3: NVIDIA A100-SXM4-80GB (UUID: GPU-XXXXXXXX-XXXX-XXXX-b5e3-e8e5164bcbdf)
MIG 2g.20gb Device 0: (UUID: MIG-XXXXXXXX-XXXX-XXXX-8887-7e3549d86c26)
GPU 4: NVIDIA A100-SXM4-80GB (UUID: GPU-XXXXXXXX-XXXX-XXXX-168d-a4c4ed4aecc6)
MIG 3g.40gb Device 0: (UUID: MIG-XXXXXXXX-XXXX-XXXX-aaed-1060f461744a)
GPU 5: NVIDIA A100-SXM4-80GB (UUID: GPU-XXXXXXXX-XXXX-XXXX-59d1-3639fbef1d6a)
GPU 6: NVIDIA A100-SXM4-80GB (UUID: GPU-XXXXXXXX-XXXX-XXXX-d31f-612b342f8481)
GPU 7: NVIDIA A100-SXM4-80GB (UUID: GPU-XXXXXXXX-XXXX-XXXX-d94d-0653a519232f) 3.2.1 主机上面使用
如果是在主机节点上面使用MIG,操作非常简单,直接设置对应的MIG device即可。比如,需要使用上述列表里面的GPU-4上面创建的MIG设备(Device 0):
# export CUDA_VISIBLE_DEVICES=MIG-XXXXXXXX-XXXX-XXXX-aaed-1060f461744a
# python train.py3.2.2 容器/docker
docker容器内操作主要涉及设备挂载,首先你得安装了nvidia-docker2 >= v2.3,然后启动时候需要挂载对应的MIG-device。
挂载运行:
docker run --gpus '"device=0:1"' ....device=0:1,表示挂载了GPU0的 1号MIG设备, 即如下所示中的第二个设备。

3.3.3 利用DCGM查看MIG性能指标
需要知道的是:MIG运行后无法通过nvidia-smi查看GPU的util ,整卡的util会显示为N/A:

如果需要查看,需要使用DCGM。Getting Started - NVIDIA DCGM Documentation latest documentation
这里给出一个使用DCGM查看GPU整卡以及MIG的各项运行指标的例子。先安装好DCGM(安装教程),接下来的大致步骤是:
- 确认MIG正常,确认DCGM正常。
- 创建DCGM的group,绑定对应的MIG设备;
- 选择需要查看的group,配置Metrics参数,自动打印相关数据。
确认MIG正常:假设还没有MIG设备先创建MIG设备。这里我们利用0号GPU创建 profile 为5,9的实例,并同时创建对应的CI实例。
# nvidia-smi mig -i 0 -cgi 5,9 -C
Successfully created GPU instance ID 1 on GPU 0 using profile MIG 4g.40gb (ID 5)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 1 using profile MIG 4g.40gb (ID 3)
Successfully created GPU instance ID 2 on GPU 0 using profile MIG 3g.40gb (ID 9)
Successfully created compute instance ID 0 on GPU 0 GPU instance ID 2 using profile MIG 3g.40gb (ID 2)确认DCGM正常:利用dcgmi的 discovery 产看刚才创建的设备。
# dcgmi discovery -c
+-------------------+--------------------------------------------------------------------+
| Instance Hierarchy |
+===================+====================================================================+
| GPU 0 | GPU GPU-******-******-*****-53df7b497d19 (EntityID: 0) |
| -> I 0/1 | GPU Instance (EntityID: 1) |
| -> CI 0/1/0 | Compute Instance (EntityID: 1) |
| -> I 0/2 | GPU Instance (EntityID: 0) |
| -> CI 0/2/0 | Compute Instance (EntityID: 0) |
+-------------------+--------------------------------------------------------------------+创建GROUP:在dcgmi中创建对应的group绑定MIG设备。
## 创建:
# dcgmi group -c mig-metric -a 0,i:0,i:1
Successfully created group "mig-metric" with a group ID of 2
Add to group operation successful.
## 查看:
# dcgmi group -l
参数说明:-c 创建group,后面“mig-metric”是名称(随意);-a 绑定(添加的设备)0号卡 MIG实例0,MIG实例1。
# 用-h 打印可看到英文解释:
-c --create groupName (OR required) Create a group on the remote host.
-a --add entityId Add device(s) to group. (csv gpuIds or entityIds
simlar to gpu:0, instance:1, compute_instance:2,
nvswitch:994)查看MIG需要观测的指标:利用dmon将需要的metric 打印出来,比如我们要看SM的使用数量,SM的占用量,tensor的使用量等,操作如下:
# dcgmi dmon -e 1001,1002,1003,1004,1005 -g 2
- 说明1: -e 后面的参数(1001,1002等)即指定了需要查看的数据,对应的可以设置的参数我们能查到:
# dcgmi profile -l -i 0
监测的数据
- 说明2:打印的参数包括了 GPU0总的数据(GPU 0)以及MIG 0(GPU-I 0) 和MIG 1(GPU-I 1)设备上面的单独情况。本例中在MIG 1号上面跑了一个任务,MIG 0设备闲置,所以MIG 0的输出数据都是0。
# Entity GRACT SMACT SMOCC TENSO DRAMA
Id
GPU 0 0.429 0.429 0.364 0.011 0.400
GPU-I 0 0.000 0.000 0.000 0.000 0.000
GPU-I 1 0.750 0.750 0.637 0.020 0.800- 说明3:Metric的百分比整卡和MIG是可以折算的。比如例子中,MIG 1设备上面 SMACT(SM_Active)显示了0.75,而整卡的只有0.429。因为MIG显示的数量是自己的占比,整卡统计的是所有的用量占比。
3.3 MIG的测试
由于MIG切分后的子GPU跟一块独立的GPU相似,有理相信NVIDIA在安全和隔离方面的能力。这里我们注重看一下QoS的情况。测试两个比较流行的算法,看一下经过MIG切分后训练端到端的时间的变化。
Case 1: 用假数据,Resnext模型,模拟多训练Job 抢占GPU。
Case 2/3: 用ImageNet数据,swin-transformer模型。
3.3.1 均匀抢占测试
均匀抢占是指:让相同的job训练放入MIG device中,观测每个job的运行时间变化,以及所有job平均时间的变化。本测试的算法直接用的torchvision.models.resnext101_32x8d这个模板,测试代码如下:
import torch
import time
import torchvision
from torchvision import transforms
def main():
trans = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5,), (1.0,))])
data_set = torchvision.datasets.FakeData(size=1000, image_size=(3, 28, 28), num_classes=10, transform=trans)
data_loader_train = torch.utils.data.DataLoader(dataset=data_set,
batch_size=1024,
num_workers=0,
pin_memory=True)
net = torchvision.models.resnext101_32x8d(num_classes=10)
net.conv1 = torch.nn.Conv2d(3, 64, (7, 7), (2, 2), (3, 3), bias=False)
net = net.cuda()
criterion = torch.nn.CrossEntropyLoss()
opt = torch.optim.Adam(net.parameters(), lr=0.001)
data = next(iter(data_loader_train))
images, labels = data
images = torch.tensor(images).cuda()
labels = torch.tensor(labels).cuda()
for epoch in range(1):
for i in range(100):
opt.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
opt.step()
if i % 10 == 0:
print("loss: {}".format(loss.item()))
if __name__ == "__main__":
t1 = time.time()
main()
t2 = time.time()
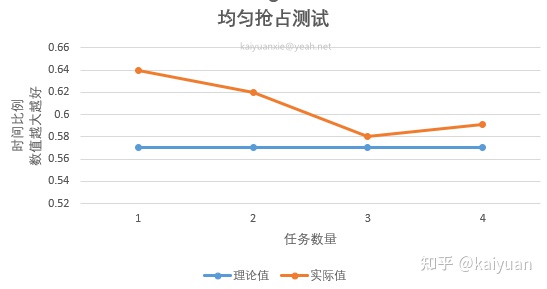
print("t2 - t1:{}".format(t2 - t1))通过用重复起多个训练来模拟多个用户使用同一个GPU设备,这里我们拿MIG 4g.40gb 和 整块GPU训练做对比。理论上讲 MIG 4g.40gb 的算力应该是整卡的4/7 大概是:57%。
| 训练Job的数量 | 整卡 | MIG 4g.40gb | 时间比:整卡/MIG |
|---|---|---|---|
| 1 x | Job0: 25s | Job0: 39s | 0.64 |
| 2 x | Job0: 49s Job1: 50s |
Job0: 80s Job1: 78s |
0.62 |
| 3 x | Job0: 60s Job1: 72s Job2: 71s |
Job0: 113s Job1: 117s Job2: 118s |
0.58 |
| 4 x | Job0: 94s Job1: 94s Job2: 91s Job3: 87s |
Job0: 157s Job1: 156s Job2: 154s Job3: 152s |
0.591 |
由于训练任务是手动起的,抛开这个时间误差,可以看到在多Job的情况下,训练时间的变化比例与算力切分比例非常相近。
3.3.2 不同算力测试
本测试代码采用开源的swin-transformer 代码来源CODE,算法主要参数设置:
swin-transformer :
DATA: Imagenet-mini (276M)
configs: swin_large_patch4_window7_224_22k.yaml
/swin_base_patch4_window7_224/default
data-size: 128
epoch: 1
#启动方式:
CUDA_VISIBLE_DEVICES=<GPU UUID> python -m torch.distributed.launch\
--nproc_per_node 1 --master_port 25566 main.py \
--cfg configs/swin/swin_base_patch4_window7_224.yaml \
--data-path ./Imagenet \
--batch-size 128我们通过改变GI的切片大小来改变算力,并测试训练作业端到端的时间变化。训练包含train,test两个步骤,时间变化主要计算train的时间变化。
另外,由于128的batch_size 内存消耗比较大(如果选256 的batch_size,40gb显存兜不住,会OOM,如下图),所以切分的时候,显存都是采用了40gb的规格。

记录运算的时间如下:
| 规格 | 训练时间 | 时间变化(整卡/MIG) |
|---|---|---|
| 整卡A100(7c) | train: 95s test: 12s |
1 |
| 4/7算力:MIG 4g.40gb | train:157s test: 14s |
实际值:0.605 理论值:0.571 |
| 3/7算力:MIG 3g.40gb | train:189s test: 18s |
实际值:0.502 理论值:0.428 |
| 2/7算力:MIG 2c.3g.40gb | train: 255s test: 25s |
实际值:0.372 理论值:0.285 |
| 1/7算力:MIG 1c.3g.40gb | train:475s test:48s |
实际值:0.200 理论值:0.142 |
从运行的数据来看:
- 实际值比理论值要大,可能是训练对core的使用没有达到极限,所以往小调节算力的时候时间增加的量比理论值少。
- 算力降低后,时间变化的比例基本上与算力缩减的比例相近。

3.3.3 非均匀切分测试
在前面的背景介绍中,我们提到了算力切分的QoS,所以非均切分测试主要解答前面提到的问题:
对于一张物理卡A100,如果按照不等比例进行切分算力,运行相同任务,其时间变化会如何?任务会互相影响吗?
还是利用swin-transformer这个例子,本次我们直接用一个GPU上面的两个GI实例,算力分别配置3:4。

然后运行两个相同的训练Job。同时开始运行,并记录端到端的时间:
| 规格 | 训练时间 | 时间变化 |
|---|---|---|
| GPU0:MIG 3g.40gb | train:190s test: 17s |
单独训练/混合训练:0.994 整卡/混合训练:0.500 |
| GPU0:MIG 4g.40gb | train:157s test: 14s |
单独训练/混合训练:1.00 整卡/混合训练:0.605 |
从非均匀切分的测试数据来看,MIG确实保证了QoS能力,混合训练和单独训练的时间一基本致。这样用户不用担心相同硬件GPU上非自身任务(其它MIG device)运行会影响自己任务。
4 总结
最后总结一下,MIG作为一种虚拟化GPU的方法,在隔离、安全、QoS上都有好的表现。相比以前的Time-sliced模式,其在带宽均衡、计算损失、故障处理方面都能做到更优。当然,MIG并不是完全拥有GPU的所有特性,比如P2P(NVLINK)暂时就不支持,而且当切分得比较多时,如子GPU数量大于2时,子GPU可能没有一些专用的引擎(如OFA、NVJPG、NVDEC);目前MIG的配置并不是太灵活(排序固定,最多7切分),相信随着技术的发展,后面的切分细粒度会更好。总体来看MIG这种技术是一种云服务器GPU发展的方向,支持了更多的用户需求。
文中的不对之处欢迎指正。如果大家还想看MIG其它测试,欢迎点赞、关注、留言。
参考:
https://docs.nvidia.com/grid/13.0/grid-vgpu-user-guide/index.html
NVIDIA Multi-Instance GPU(MIG)
ISC 2020: Running Multiple Workloads on a Single A100 GPU
https://docs.nvidia.com/datacenter/tesla/mig-user-guide/#nvidia-docker