问题背景
在我们将 Spark 版本从 3.0.1 升级至 3.2.1 之后,发现某个 ETL 无法正常运行了,而在升级之前运行都是正常的。

通过查询查询运维日志,发现任务几次失败的时间节点,Spark application 的 driver 日志中偶现 OutOfMemory 的报错。

问题分析
对于此类 OOM 问题,一般分为两个方向,一个是通过拿取 OOM 当时的 dump 文件结合代码进行分析占用内存较多的对象是什么,另一个就是结合内存监控定位出现问题时的任务情况,对具体的 ETL 任务进行分析并尝试复现。
排查过程
问题确认
首先在排除其他任务干扰的情况下单独运行出问题的 ETL,发现内存确实有明显的上升并导致服务不可用。
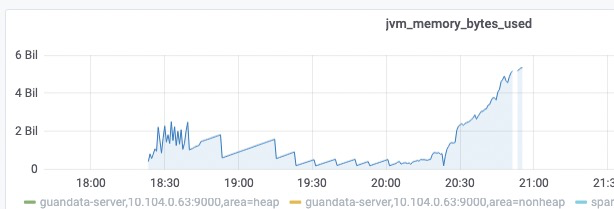
结合之前出现 OOM 时的内存监控,内存迅速上涨的表现一致。
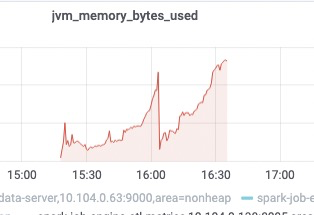
由此基本可以确定就是那个 ETL 导致的问题,下一步就是确认任务本身和升级前是否做了修改。通过查询数据库拿到任务运行的具体历史脚本并进行比较,发现 ETL 本身基本没有改动。因此我们第一时间回滚了 Spark 版本,再次尝试运行这个 ETL,果然能跑出来了。
问题推测
1. 是否是 Spark.scheduler.listenerbus.eventqueue.capacity 调大导致?
在本次升级中,我们同时调大了这个参数,用于避免高并发时的 eventqueue 处理的事件过多导致事件被丢弃从而影响一些指标的统计。会不会是因为这个参数调大了,导致这个 Listener 需要处理的事件变多了,进而加大了内存上的压力呢?我又去查询了历史的日志,并没有因为事件过多出现 dropped event 相关的日志,因此处理事件的并发之前也没达到上限,暂时排除这个影响。
2. 检查 Spark 3.2 代码逻辑上的变动。
用 Jprofile 打开 dump 文件,发现其中 SQLAppStatusListener 占用了大量内存。最大的对象是 stageMetric,存放的是 Stage 相关的 metric 信息,存放在 concurrentHashMap 里。
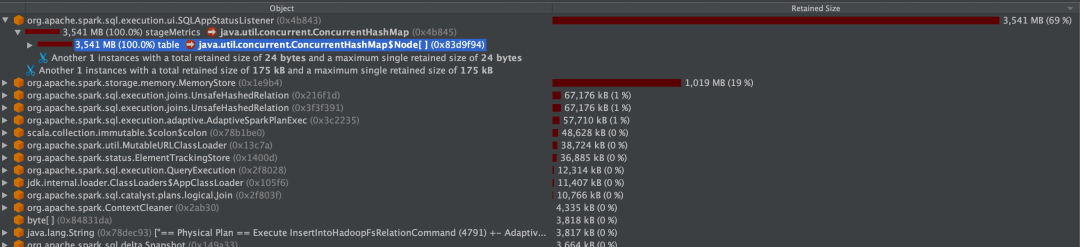
查看代码发现了一处比较怀疑的改动:
[SPARK-33016][SQL] Potential SQLMetrics missed which might cause WEB UI display issue while AQE is on
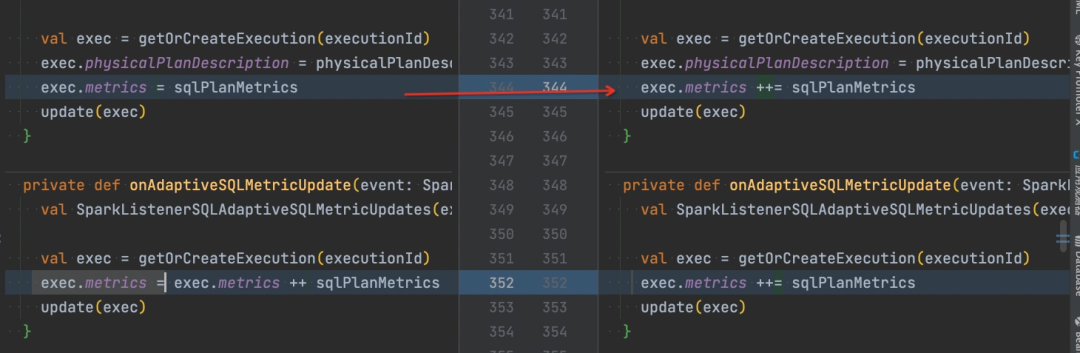
提交者说:
So decided to make a trade off of keeping more duplicate SQLMetrics without deleting them when AQE with newPlan updated.
会不会是存放了额外的重复的 SQLMetrics 导致内存使用上涨呢?那就再尝试复现一下。
问题复现
如果是 ETL 逻辑有问题,那么我们不需要数据应该也能复现这个问题。为了便于本地 debug,我导出了有问题的 ETL 的结构,构造了一份空数据,运行了一下问题没有复现,甚至在 Spark 3.2 上表现更好。

那么想来问题和数据也是有关的。在此之前,我在 Spark ui 上观察过出问题环境的 etl 运行,有几个比较明显的特点:
-
job 很多,而且有着依赖关系,也就是一些 job 是在前序 job 运行完之后才会提交。
-
最后运行的 job 有着非常多的 task,大概有上万的量级。
-
etl 本身有着比较多的 join 和 union 计算。
通过查询数据库中记录的 Spark 任务 metric 的统计,印证了我的观察。这个任务在 Spark 3.0.1 版本运行时会生成几百个 stage,上万个 task。在 Spark 3.2 中没运行成功,因此没有准确的统计数据。

一开始我先随便造了一些数据,通过增加数据量的方式试图复现问题,但始终无法复现出异常的情况。回过头来思考,如何让 Spark 任务的表现和出问题的环境类似,主要从 stage 和 task 的数量上入手。stage 的数量和 shuffle 有关,要制造 shuffle 就需要用到宽依赖转换操作,例如在这个 etl 中就有很多的 groupBy。而 task 数量和 partition 数量有关,也就是说我需要制造更多的 partition。因此我针对 groupBy 的 key 将制造了很多不重复的数据,在限制 driver 内存的情况下不断增加数据量从而制造更多的 task,终于复现频繁 GC 的临近 OOM 状态了。此时 dump 出来的堆信息也和真实情况类似,SQLAppStatusListener 占用了堆内存的大头。
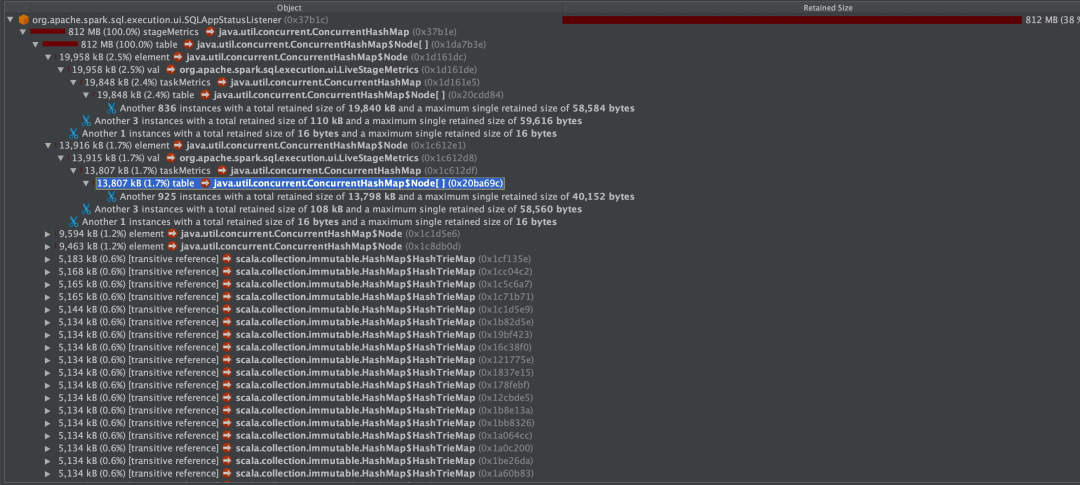
且在 webui 上能看到比较多的 task:

回归上文提到的代码改动,这里的改动是在 AQE 改变执行计划的时候,原本是用新计划的 metric 代替老计划,现在变成了叠加。而在我关闭 AQE 后,driver 内存被占满的情况没有再出现。那这能够说明问题出在累加的 metrics?尝试修改代码将 ++= 改回=,然而经过验证问题依旧存在!
二次排查
首先需要弄清楚 stageMetrics 为什么占用了那么大的内存,为了搞清楚内存使用的上的差别,我决定使用控制变量法比较新老版本的差异。于是我做了三件事:
-
注释掉清理 StageMetrics 的代码。
-
再运行一次 ETL 后将内存 dump 出来。
-
打开 eventLog 便于数据统计。
dump 出来的 SQLAppStatusListener 的大小大约是 800M(新版本) vs 200M(老版本)的水平。
关于这个对象的大小区别又有以下几个猜测:
-
Stage 数量 [排除]
private val stageMetrics = new ConcurrentHashMap[Int, LiveStageMetrics]()SQLAppStatusListener 中占大头的是 stageMetrics。stageMetrics 存储的是一个 stageId 和 LiveStageMetrics 的映射,也就是 stageMetrics 的 size 是由 stage 数量决定的。通过统计的 metric 信息看,问题 ETL,在新版本和老版本的 stage 数量差距不是特别大,老版本 270 个 stage,新版本 201 个 stage,比较起来还是老版本多,说明这里的问题不是 stage 数量的问题。
在存储的 LiveStageMetric 里面,有几种情况占用内存较多:
2. taskMetrics[排除]
无论是新版本还是老版本,在 stageMetrics map 里占用最多内存的几条数据占大多数内存的是 taskMetrics:

taskMetrics 存储的是【累加器 id】和【长度为任务数的列表】的映射,如何确认里面有多少条数据呢?这个数据等于 Accumulator 的数量 * task 的数量:
accumUpdates
.filter { acc => acc.update.isDefined && accumIdsToMetricType.contains(acc.id) }
.foreach { acc =>
// In a live application, accumulators have Long values, but when reading from event
// logs, they have String values. For now, assume all accumulators are Long and convert
// accordingly.
val value = acc.update.get match {
case s: String => s.toLong
case l: Long => l
case o => throw new IllegalArgumentException(s"Unexpected: $o")
}
val metricValues = taskMetrics.computeIfAbsent(acc.id, _ => new Array(numTasks))
metricValues(taskIdx) = value
if (SQLMetrics.metricNeedsMax(accumIdsToMetricType(acc.id))) {
val maxMetricsTaskId = metricsIdToMaxTaskValue.computeIfAbsent(acc.id, _ => Array(value,
taskId))
if (value > maxMetricsTaskId.head) {
maxMetricsTaskId(0) = value
maxMetricsTaskId(1) = taskId
}
}
}
if (finished) {
completedIndices += taskIdx
}
}在 SparkListenerStageSubmitted 事件中有记录任务数:
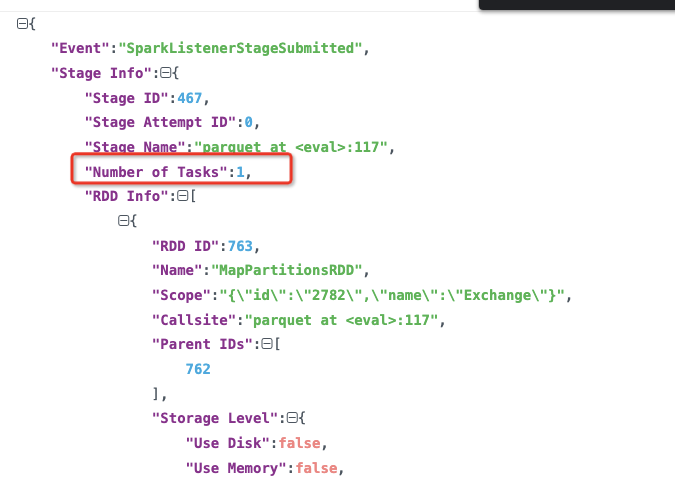
根据 JobGroupId 筛选所有的 SparkListenerStageSubmitted 事件,然后统计其中的任务数,发现老版本的 Spark 产生的任务数更多,每个 stage 大多有 128 个任务,新版本则大多是 1 个,最后几个 stage 有上千个任务。
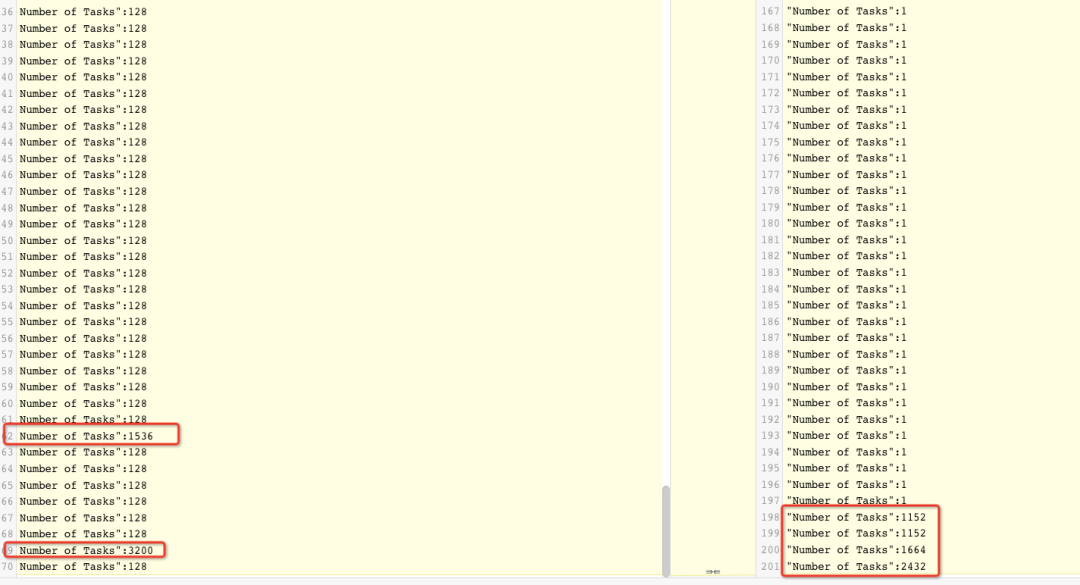
左边是老版本,右边是新版本
但是 Accumulator 的数量不好统计,因为 eventLog 中没有打出来。于是我修改了代码,将这个数据塞进 eventLog
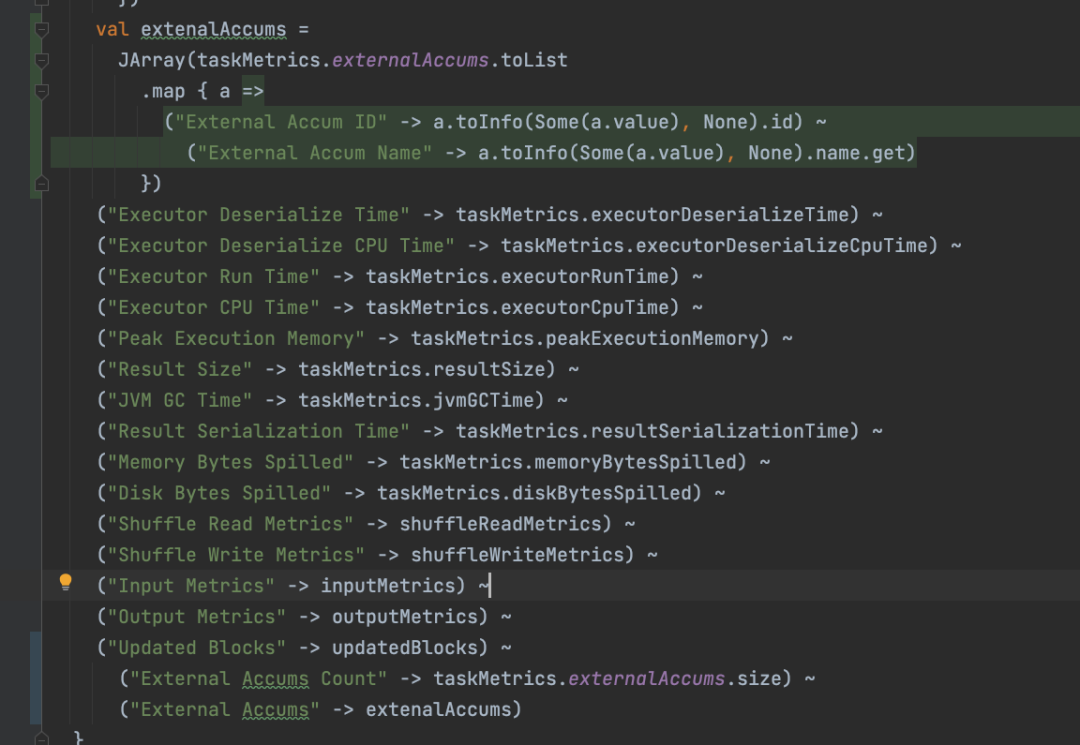
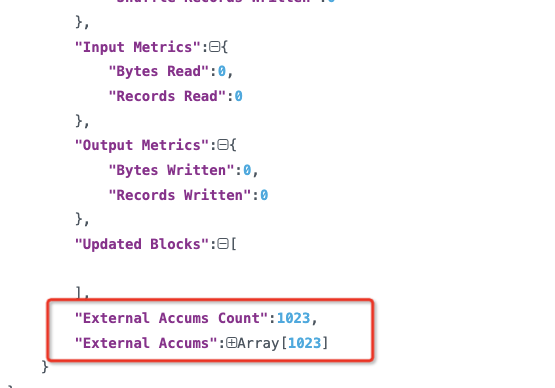
打出来发现新老版本的 Accums Count 数数量差别也不大,而且老版本的数量还更多些,因此这一因素也被排除。
统计了个几个 task 数量比较多的 stage 中的 task 关联的 accums
Spark 3.0.1
Number of Tasks:3200 Number of Accums:4038
Number of Tasks:128 Number of Accums:5632
Spark 3.2.1
Number of Tasks:1152 Number of Accums:1023
Number of Tasks:1152 Number of Accums:1009
Number of Tasks:1664 Number of Accums:1031
Number of Tasks:2432 Number of Accums:10163. accumIdsToMetricType[可疑]
在 Spark 3.2 中,还存在着大量 内存大多数被 accumIdsToMetricType 占用的 LiveStageMetric 对象,大小是 2-5M 左右,而 Spark 3.0.1 则大多是几百 K。
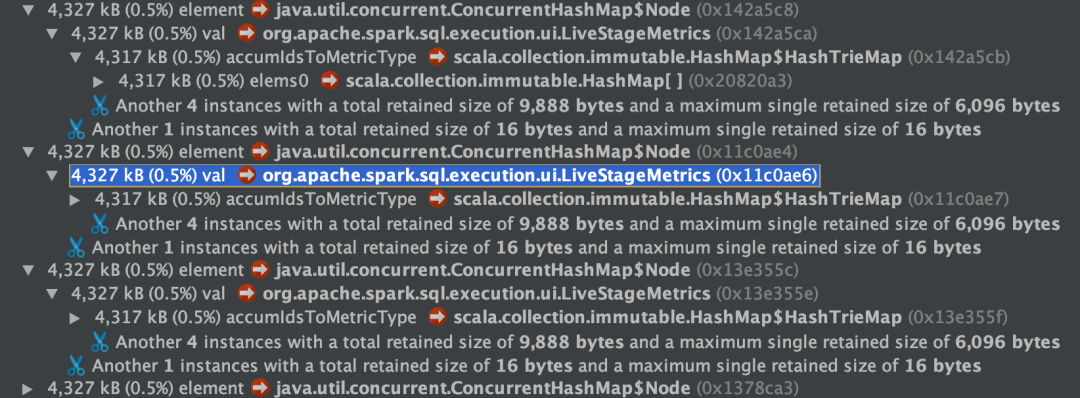
根据代码,能够使得 metrics 增加的事件只有两个,SparkListenerSQLAdaptiveExecutionUpdate 和 SparkListenerSQLAdaptiveSQLMetricUpdates。在 eventLog 中能够看到 SparkListenerSQLAdaptiveExecutionUpdate 触发的次数确实不是很多,但是每一次添加的量却不少。
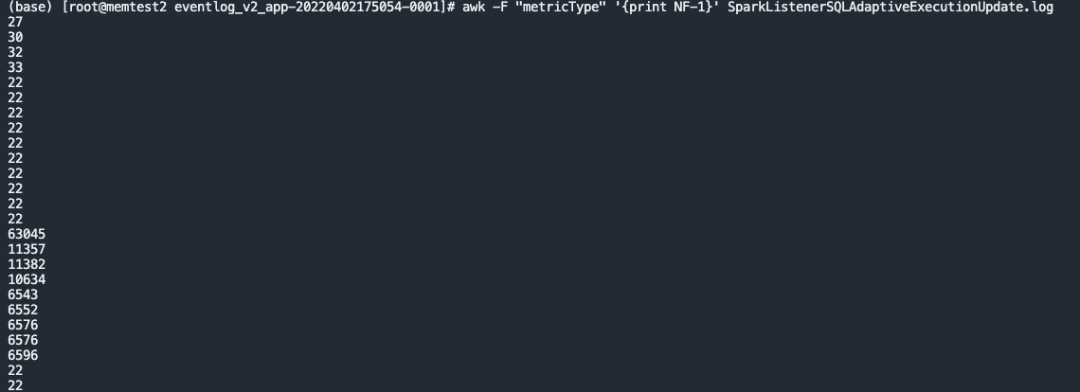
使用 Spark 3.0.1 查看发现结果有很大区别:

区别在于:
-
新版本 SparkListenerSQLAdaptiveExecutionUpdate 触发次数变多;
-
新版本每个 SparkListenerSQLAdaptiveExecutionUpdate 包含的 metrics 变多。
结合 Spark 的 change log 可以推断出一点:Spark 新版本优化了 AQE 的实现,对于部分场景能够更加智能地动态生成新的执行计划,同时也增加了一些指标的统计。部分新生成的执行计划包含多层嵌套的树节点,因此也带来了大量的 Metrics 指标加大了内存的压力。
但是这两点我们都无法轻易改动,再看看还有什么不同。
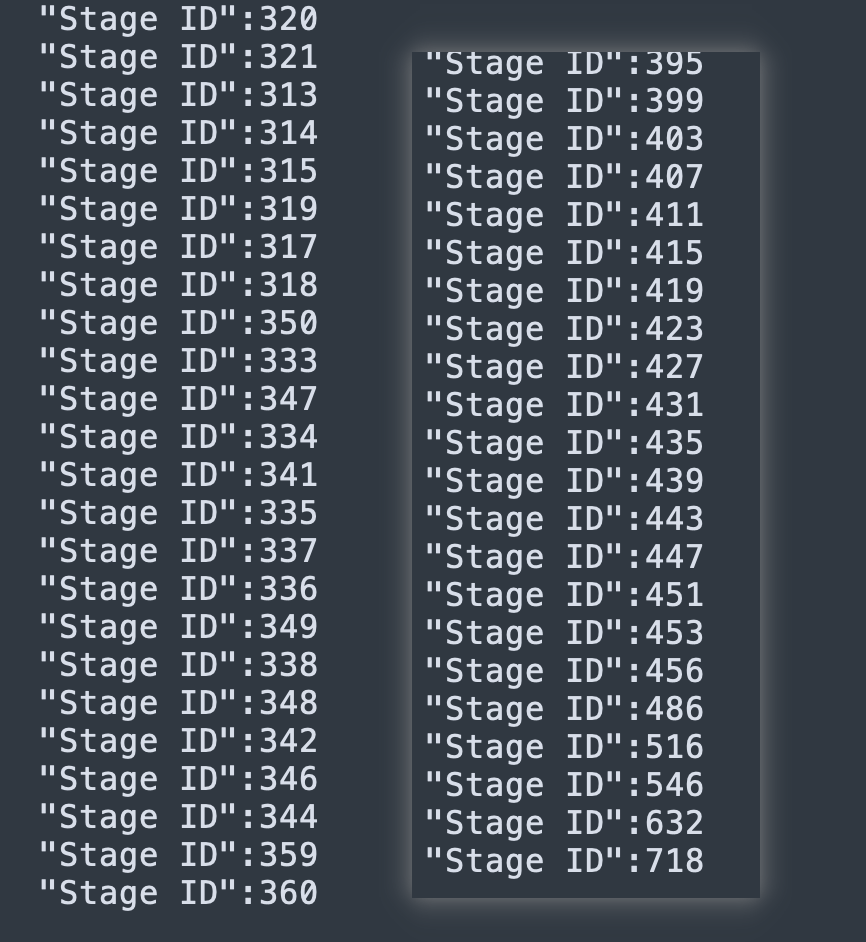
根据内存 dump 和 event log 的统计,这个 case 新版本生成的 StageMetrics 的数量相差了接近两倍,从 stageId 上也能看出新版本生成的最大 ID 序号(从 0 开始)也是两倍的关系,那么关注点就在不连续的这部分 ID 上面。在 eventLog 中对 stage Id 进行搜索,发现有些 stage 在 SparkListenerJobStart 事件中存在,但没有触发 SparkListenerStageSubmitted 事件,想必这就是 skipped stage。那 skipped stage 对 StageMetric 的影响是什么呢?
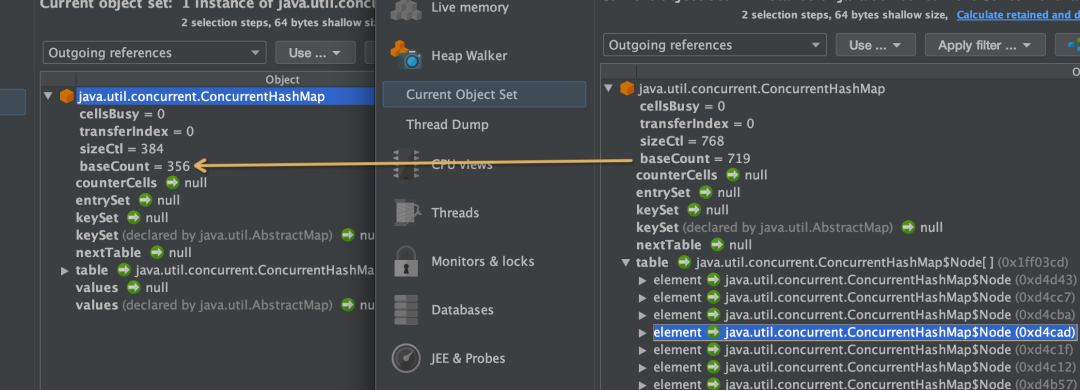
StageMetric 初始化是在处理 SparkListenerJobStart 事件时,更新是在处理 onStageSubmitted 事件时:
// Record the accumulator IDs and metric types for the stages of this job, so that the code
// that keeps track of the metrics knows which accumulators to look at.
val accumIdsAndType = exec.metrics.map { m => (m.accumulatorId, m.metricType) }.toMap
if (accumIdsAndType.nonEmpty) {
event.stageInfos.foreach { stage =>
stageMetrics.put(stage.stageId, new LiveStageMetrics(stage.stageId, 0,
stage.numTasks, accumIdsAndType))
}
}
override def onStageSubmitted(event: SparkListenerStageSubmitted): Unit = {
if (!isSQLStage(event.stageInfo.stageId)) {
return
}
// Reset the metrics tracking object for the new attempt.
Option(stageMetrics.get(event.stageInfo.stageId)).foreach { stage =>
if (stage.attemptId != event.stageInfo.attemptNumber) {
stageMetrics.put(event.stageInfo.stageId,
new LiveStageMetrics(event.stageInfo.stageId, event.stageInfo.attemptNumber,
stage.numTasks, stage.accumIdsToMetricType))
}
}
}也就是这里的差值会造成 StageMetric 中存储了许多 skipped 的 stage,从 ui 上看 skipped stages 大约是 completed stage 的两倍多。
如果我们在 JobEnd 的时候把 skipped 的 stage 删除掉呢?
override def onJobEnd(event: SparkListenerJobEnd): Unit = {
liveExecutions.values().asScala.foreach { exec =>
if (exec.jobs.contains(event.jobId)) {
val result = event.jobResult match {
case JobSucceeded => JobExecutionStatus.SUCCEEDED
case _ => JobExecutionStatus.FAILED
}
exec.jobs = exec.jobs + (event.jobId -> result)
exec.endEvents.incrementAndGet()
update(exec)
// 在 JobEnd 的时候筛选出 pendingStage,从 stageMetrics 中移除
val finishedStages = Option.apply(pendingStages.remove(event.jobId))
if (finishedStages.isDefined) {
for (stageId <- finishedStages.get -- activeStages) {
stageMetrics.remove(stageId)
}
}
}
}
}从结果上看,修改后 etl 能够顺利排查出来,修改前 JobEngine 处于频繁 fullgc 的状态。
从监控看,修改后老年代没有做 fullgc,修改前则比较频繁:
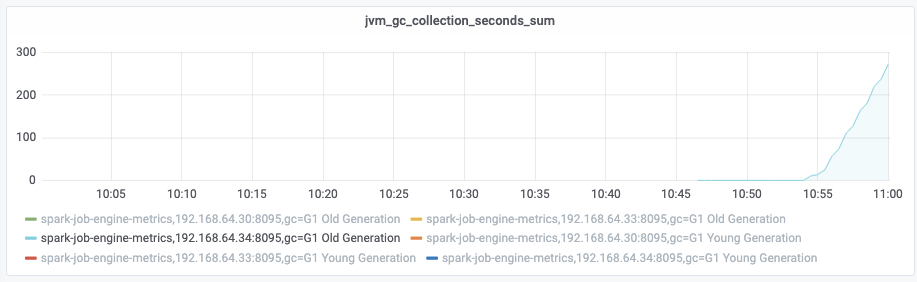
修改前
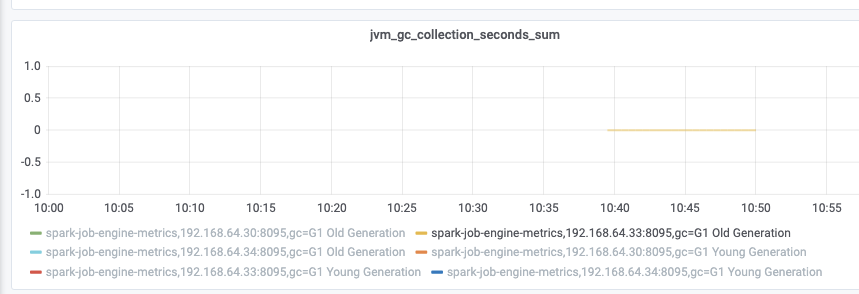
修改后
排查结论
虽然定位到问题和 AQE 相关的优化有关,但是为了个别 CASE 放弃 AQE 带来的性能提升必然也是不可取的。而通过减少 skipped stage 相关数据的存储,虽然没能解决这个问题的 root cause,但也能一定程度上能够减小内存的压力,属于是另辟蹊径的一种做法。在接下来的时间里,我们也将继续研究 AQE 相关的代码逻辑,针对每一个 corner case 刨根问底,持续为企业级服务的稳定性保驾护航。