本文为博主自学笔记整理,内容来源于互联网,如有侵权,请联系删除。
个人笔记:https://www.dbses.cn/technotes
关于如何处理请求,我们很容易想到的方案有两个。
- 顺序处理请求
伪代码大概是这个样子:
while (true) {
Request request = accept(connection);
handle(request);
}
这种方式的吞吐量太差,每个请求都必须等待前一个请求处理完毕才能得到处理。适用于请求发送非常不频繁的系统。
- 异步处理请求
伪代码大概是这个样子:
while (true) {
Request = request = accept(connection);
Thread thread = new Thread(() -> handle(request););
thread.start();
}
这个方法的好处是,它是完全异步的,每个请求的处理都不会阻塞下一个请求。
缺陷是开销极大,在某些场景下甚至会压垮整个服务。这个方法也只适用于请求发送频率很低的业务场景。
Kafka 处理请求的方式
Kafka 使用的是 Reactor 模式。
简单来说,Reactor 模式是事件驱动架构的一种实现方式,特别适合应用于处理多个客户端并发向服务器端发送请求的场景。Reactor 模式的架构图如下:

根据上图,Reactor 模式主要特点是分发。
Reactor 有个请求分发线程 Dispatcher,也就是图中的 Acceptor,它会将不同的请求下发到多个工作线程中处理。
Acceptor 线程只是用于请求分发,不涉及具体的逻辑处理,非常轻量级,因此有很高的吞吐量表现。而这些工作线程可以根据实际业务处理需要任意增减,从而动态调节系统负载能力。
Kafka 的处理请求模型类似:
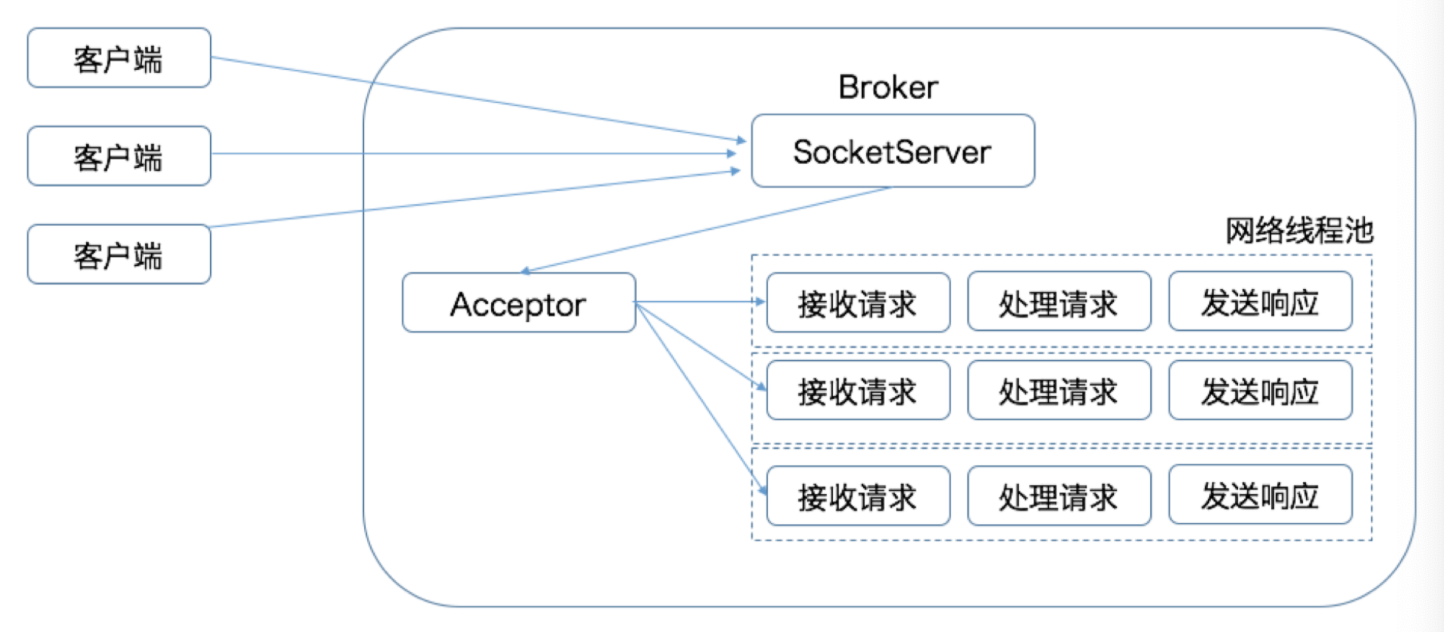
SocketServer 组件:它也有对应的 Acceptor 线程和一个网络线程池。
Acceptor 线程:采用轮询的方式将入站请求公平地发到所有网络线程中。
网络线程池:处理 Acceptor 线程分发的工作任务。
Kafka 提供了 Broker 端参数 num.network.threads,用于调整该网络线程池的线程数。其默认值是 3,表示每台 Broker 启动时会创建 3 个网络线程,专门处理客户端发送的请求。
Kafka 网络线程处理请求的具体过程
客户端发来的请求会被 Broker 端的 Acceptor 线程分发到任意一个网络线程中,Kafka 在这个环节又做了一层异步线程池的处理,我们一起来看一看下面这张图。
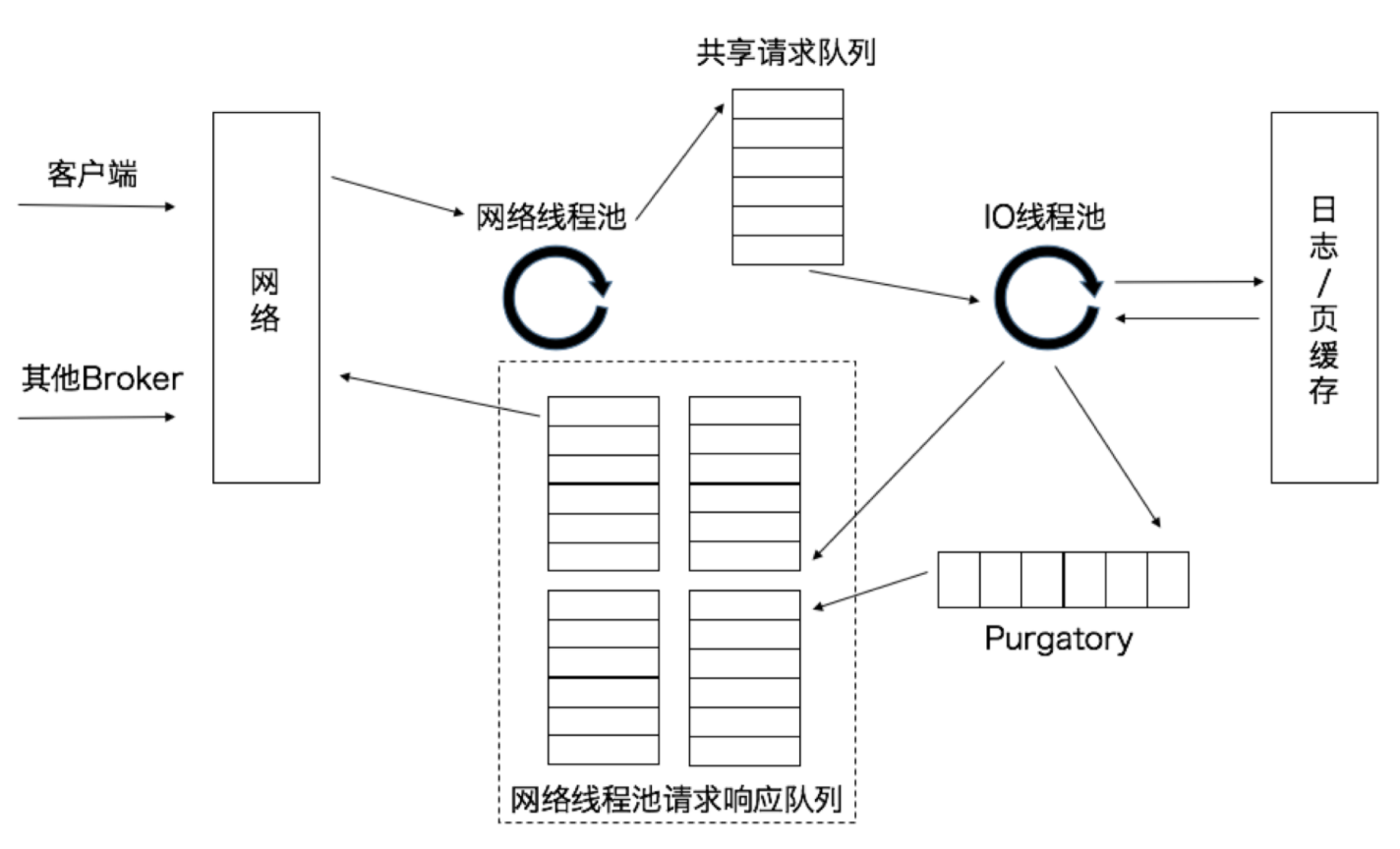
主要步骤如下:
-
当网络线程拿到请求后,会将请求放入到一个共享请求队列中。
-
Broker 端有个 IO 线程池,负责从该队列中取出请求,执行真正的处理。
Broker 端参数 num.io.threads 控制了这个线程池中的线程数。 目前该参数默认值是 8,表示每台 Broker 启动后自动创建 8 个 IO 线程处理请求。
-
处理请求。如果是 PRODUCE 生产请求,则将消息写入到底层的磁盘日志中;如果是 FETCH 请求,则从磁盘或页缓存中读取消息。
-
IO 线程处理完请求后,会将生成的响应发送到网络线程池的响应队列中,然后由对应的网络线程负责将 Response 返还给客户端。
为什么网络线程不直接处理?即为什么要有 2、3 步骤?
请求队列与响应队列的差别
请求队列是所有网络线程共享的,而响应队列则是每个网络线程专属的。
这么设计的原因就在于,Dispatcher 只是用于请求分发而不负责响应回传,因此只能让每个网络线程自己发送 Response 给客户端,所以这些 Response 也就没必要放在一个公共的地方。
Purgatory 组件
图中还有一个叫 Purgatory 的组件,这是 Kafka 中著名的“炼狱”组件。它是用来缓存延时请求(Delayed Request)的。
所谓延时请求,就是那些一时未满足条件不能立刻处理的请求。比如设置了 acks=all 的 PRODUCE 请求,一旦设置了 acks=all,那么该请求就必须等待 ISR 中所有副本都接收了消息后才能返回,此时处理该请求的 IO 线程就必须等待其他 Broker 的写入结果。当请求不能立刻处理时,它就会暂存在 Purgatory 中。稍后一旦满足了完成条件,IO 线程会继续处理该请求,并将 Response 放入对应网络线程的响应队列中。