文章目录
摘要

https://arxiv.org/pdf/2306.14289v2.pdf
分割任何事物模型(SAM)因其令人印象深刻的零样本迁移性能和对许多视觉应用(如具有细粒度控制的图像编辑)的高通用性而引起了极大的关注。许多此类应用程序需要在资源受限的边缘设备上运行,如手机。本文旨在通过用一个轻量级的图像编码器替换重量级的图像编码器,使SAM对移动设备友好。像最初的SAM论文中那样,用一种天真的方法来训练这样一个新的SAM,会导致不满意的性能,特别是在可用的培训资源有限的情况下。这主要是由图像编码器和掩模解码器的耦合优化引起的,本文提出解耦蒸馏。具体来说,我们将知识从原始SAM中的重型图像编码器(ViT-H)提取到一个轻量级的图像编码器,该编码器可以自动兼容原始SAM中的掩模解码器。训练可以在一个GPU上在不到一天的时间内完成,由此产生的轻量级SAM被称为MobileSAM,它比原始SAM小60多倍,但性能与原始SAM相当。对于推理速度,使用单个GPU, MobileSAM在每张图像上运行约10毫秒:图像编码器上运行8毫秒,掩码解码器上运行4毫秒。由于性能优越,MobileSAM比并发的FastSAM快5倍左右,体积小7倍,更适合移动应用。此外,我们展示了MobileSAM可以在CPU上相对平稳地运行。我们项目的代码在MobileSAM中提供),其中的演示显示MobileSAM可以在CPU上相对平稳地运行。
1、简介
ChatGPT Zhang等人[2023a]彻底改变了NLP领域,标志着生成式AI (AIGC,又称人工智能生成内容)的突破。Zhang等人[2023b]。使这成为可能的是gpt系列模型Brown等人[2020],Radford等人[2018,2019],这些模型是Bommasani等人[2021]在网络规模的文本数据集上训练的基础模型。随着NLP中基础模型的成功,多项工作He等人[2020],Qiao等人[2023a], Zhang等人[2022a]通过对比学习学习了一个图像编码器和一个文本编码器He等人[2020],Zhang等人[2022b]。最近,元研究团队发布了“Segment Anything”项目Kirillov等人[2023],其中提出了一个称为SAM的快速引导视觉基金会,并被认为是视觉的GPT时刻。SAM由两个组件组成:基于vit的图像编码器和提示引导的掩码解码器,它们按顺序工作(参见图1)。
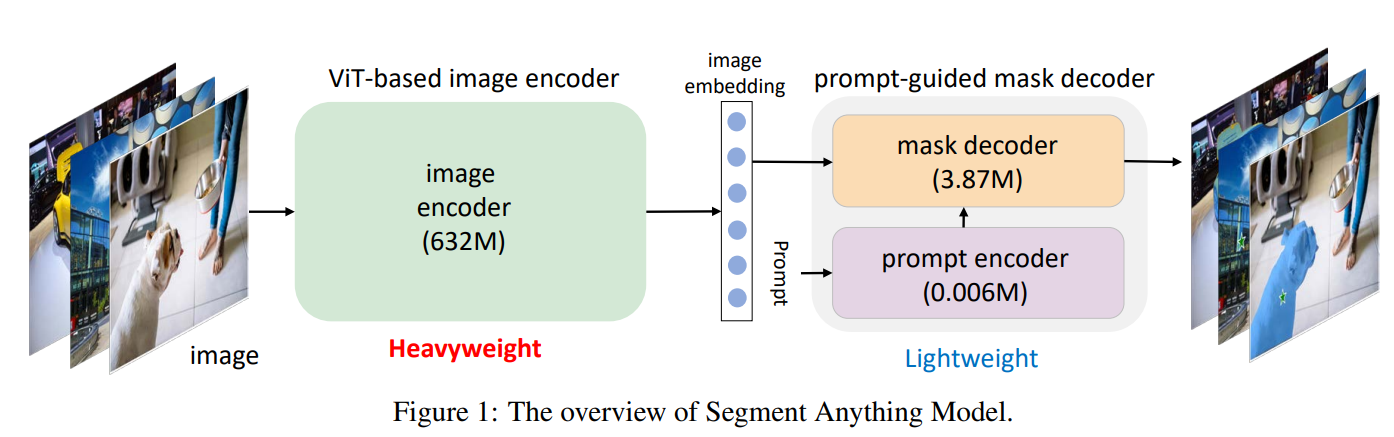
自问世以来,SAM因多种原因引起了广泛关注。首先,它首次表明,视觉可以遵循NLP来追求将基础模型与提示工程相结合的路径。其次,它第一次执行无标签分割,这是一个与标签预测并行的基本视觉任务Zhang et al. [2023c]。此外,这一基本任务使SAM与其他模型兼容,以实现高级视觉应用,如文本引导的分割和细粒度控制的图像编辑。然而,许多这样的用例需要在资源受限的边缘设备上运行,如移动应用程序。如官方演示所示,经过处理的图像嵌入后,SAM可以在资源受限的设备上工作,因为掩码解码器是轻量级的。SAM管道计算量大的原因在于庞大的图像编码器。本文研究了如何获得一种适用于资源受限移动设备的轻量级SAM,称为MobileSAM。
鉴于SAM中的默认图像编码器是基于ViT-H的,获取MobileSAM的一种直接方法是遵循Kirillov等人[2023]的官方管道,用较小的图像编码器重新训练新的SAM,例如用较小的ViT-L或甚至更小的ViT-B替换ViT-H。不同图像编码器变体的SAM参数总结在表1中。如Kirillov等人[2023]所述,使用ViT-L或ViT-B作为图像编码器来训练一个新的SAM需要128个gpu,耗时数天。这种资源密集型的再培训可能是重现或改善其结果的一个重要负担。这种优化难点主要来自于图像编码器和掩模解码器的耦合优化。在这种理解的激励下,本文提出将图像编码器和掩模解码器的优化解耦。首先,将知识从默认图像编码器ViT- h提取到微小的ViT。然后,我们可以微调原始SAM中的掩码解码器,以更好地与蒸馏图像编码器对齐。值得强调的是,对齐优化是可选的,因为从默认图像编码器中提取的轻量级图像编码器保证了其与默认掩码解码器的固有对齐。

通过将寻找新的SAM管道的问题转化为解耦蒸馏,所提出方法具有简单、有效的优点,同时可以在低成本下重现(在单个GPU上耗时不到一天)。由此得到的MobileSAM将编码器参数减少了100倍,总参数减少了60倍。令人惊讶的是,这样一个轻量级的MobileSAM的性能与最初的重量级SAMs相当,这是推动移动应用程序使用SAM的重要一步。对于使用MobileSAM进行推断,单个图像只需要运行约10毫秒:图像编码器上运行8毫秒,掩码解码器上运行4毫秒。值得强调的是,我们的MobileSAM比并发的FastSAM Zhao等人[2023]快5倍左右,小7倍左右,同时实现了卓越的性能。
2、相关工作
SAM:通用性和多功能性。自今年4月初它问世以来,涌现了许多从不同角度研究SAM的项目和论文。鉴于SAM声称可以分割任何物体,一系列工作报告了其在现实世界中的性能,包括医学图像Ma和Wang [2023], Zhang等人[2023d],伪装物体Tang等人[2023],和透明物体Han等人[2023]。结果一致表明,SAM在一般设置中效果很好,但在上述具有挑战性的设置中效果不佳。另一个重要的研究方向是增强SAM以提高其实用性。Attack-SAM Zhang等人[2023e]表明,SAM的输出掩码可以很容易地被通过恶意生成的对抗性扰动的对抗性攻击所操纵。另一项工作Qiao et al. [2023b]进一步对SAM进行了全面的鲁棒性评估,从风格迁移和常见损坏到局部遮挡和对抗性扰动。Qiao et al. [2023b]发现SAM具有高鲁棒性,但对对抗性扰动不具有鲁棒性,这与Zhang et al. [2023e]的发现相一致。另一项工作专注于展示SAM的多功能性。ground SAM IDEA-Research[2023]是将ground DINO Liu等人[2023a]与SAM相结合的开创性工作,用于分割任何具有文本输入的内容。具体来说,它依赖于接地迪诺从文本中生成边界框,然后生成的框可以用作分割掩码的提示。Chen等人[2023],Park[2023]将SAM与其他模型(如CLIP Radford等人[2021])结合起来,以对任何内容进行语义分割。除了对象分割之外,多项工作也在其他领域显示了其通用性,包括图像编辑Rombach等人[2022],以及修复任务Yu等人[2023],视频中的目标跟踪Yang等人[2023],Zxyang[2023]。除了2D视觉,SAM的研究也扩展到3D物体重建Shen等人[2023],Kang等人[2022],展示了它从单一图像辅助3D模型生成的能力。关于SAM的完整综述,建议读者参考Zhang et al. [2023c]。
ViT:轻量级和高效。早期的移动视觉应用主要由轻量级的CNNs,如MobileNet Howard等。[2017]和改进的varinats Sandler等。[2018],霍华德等。[2019年]。MobileNet的核心思想在于将一个正常的卷积块分离成深度卷积和点上卷积,大大减少了模式参数和计算时间。从ViT的出现到Dosovitskiy等。(2021年),许多作品都试图使它变得轻量级和高效。在原始ViT纸中,与玻璃-大(vith)、vita - large(vitl)、vita - base(vitb - b)相补充。[2021],在Touvron et al中引入了较小的ViTs。[2020],它被表示为小的(s)和小的(t)小的和玻璃的小的。MobileViT Mehta和Rastegari[2021]是一项开创性的工作,将ViT与标准的卷积结合起来,以提高其性能,该性能优于MobileNet v2 Sandler等。[2018]。主要的动机是利用CNN的当地代表性能力,该实践遵循多个后续工作,目的是提高模型速度,包括效率等。[2022a],刘先生等。[2023b],下一个vit Li等。[2022b]和Tiny-ViT Wu等。[2022]。在轻量级和更快的ViT中,最近的进展是互补的,我们提出了一种解耦的精化,使下一代的SAM适合于资源受限的移动设备。
3、适合移动设备的SAM
3.1、背景和项目目标
SAM的背景。在这里,我们首先总结SAM的结构及其工作原理。SAM由基于vit的图像编码器和提示引导的掩码解码器组成。图像编码器将图像作为输入并生成嵌入,然后将其提供给掩码解码器。掩码解码器生成一个掩码,根据点(或框)等提示从背景中剪切出任何物体。此外,SAM允许为同一个提示生成多个掩码,以解决歧义问题,这提供了宝贵的灵活性。鉴于此,维护SAM的流水线,首先采用基于vit的编码器来生成图像嵌入,然后采用提示引导的解码器来生成所需的掩码。该管道是为“分段任何东西”而优化设计的,它可以用于“分段所有东西”的下游任务(更多讨论参见第4.3节)。
项目的目标。这个项目的目标是生成一个移动友好的SAM (MobileSAM),以轻量级的方式实现令人满意的性能,并且比原来的SAM快得多。原始SAM中提示引导的掩码解码器参数小于4M,因此被认为是轻量级的。给定一个由编码器处理的图像嵌入,如他们的公开演示所示,SAM可以在资源受限的设备中工作,因为掩码解码器是轻量级的。然而,原始SAM中默认的图像编码器是基于参数超过6亿的ViT-H,这是非常重量级的,使得整个SAM管道与移动设备不兼容。因此,获得移动友好的SAM的关键在于用轻量级的图像编码器取代重量级的图像编码器,并自动保持原SAM的所有功能和特性。下面,我们将详细阐述我们提出的实现这个项目目标的方法。
3.2、提出方法
耦合的蒸馏。实现我们项目目标的一种直接方法是遵循Kirillov等人[2023]的官方管道,用较小的图像编码器重新训练新的SAM。如Kirillov等人所述。[2023],使用ViT-H图像编码器训练SAM需要在256个A100 gpu上花费68小时。将ViT-H替换为ViT-L或ViT-B,将所需的gpu减少到128个,对于社区中的许多研究人员来说,这仍然是一个重要的负担,以重现或改进他们的结果。按照他们的方法,我们可以进一步采用更小的图像编码器,并使用他们提供的11-T分割数据集重新训练新的SAM。请注意,所提供数据集中的掩码由预训练的SAM(使用ViT图像编码器)给出。本质上,这种再训练过程是知识蒸馏Hinton等人[2015],将知识从基于vit - h的SAM转移到具有较小图像编码器的SAM(见图2左)。
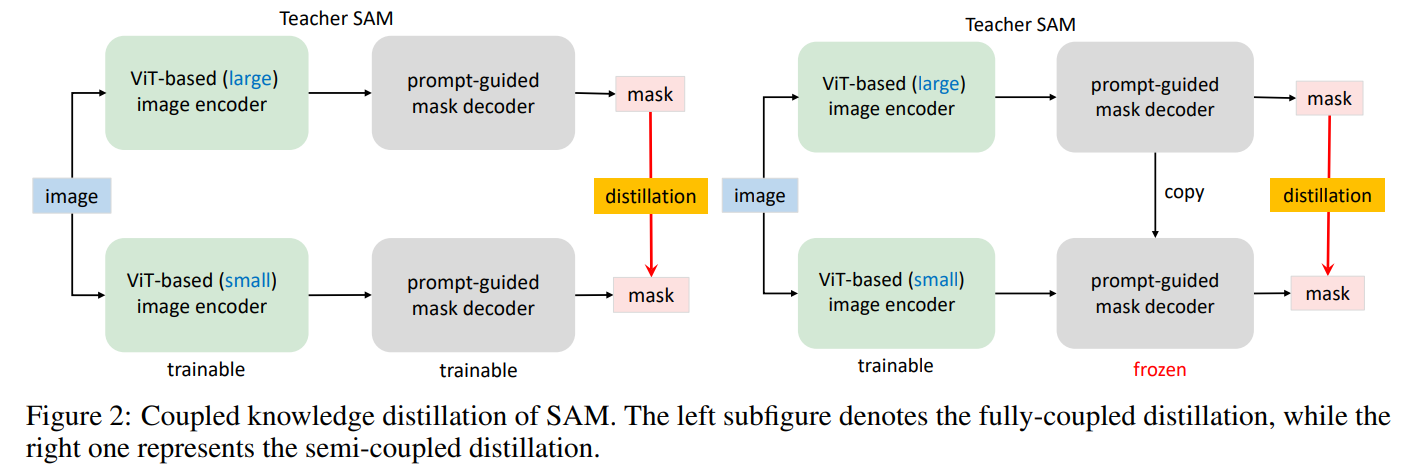
从半耦合到解耦蒸馏。将原始SAM转换为较小图像编码器的KD时,难点主要在于图像编码器和组合解码器的耦合优化。直观地说,图像编码器的优化取决于图像解码器的质量,反之亦然。当SAM中的两个模块都处于不好的状态时,将它们都训练到好的状态更具挑战性。受分治算法Zhang等人[2022c]的启发,本文建议将KD任务划分为两个子任务:图像编码器蒸馏和掩码解码器微调。首先,通过将知识从ViT-H迁移到较小的编码器,对图像编码器进行KD计算。由于原始SAM中的掩码解码器已经是轻量级的,我们计划保留它的架构。这带来了易于使用的组合解码器的好处,可以进行微调,而不是从头开始训练它。为了缓解耦合蒸馏的优化问题,一种直接的方法是使用复制和冻结的掩码解码器优化图像编码器(见右图2)。冻结操作有助于防止掩模解码器的质量因图像编码器质量差而下降。我们称这种蒸馏为半耦合,因为图像编码器的优化仍然没有完全与掩码解码器解耦。经验上,发现这种优化仍然具有挑战性,因为提示的选择是随机的,这使得掩码解码器是可变的,从而增加了优化的难度。因此,我们建议直接从原始SAM中的ViT-H中提取小图像编码器,而不借助于组合的解码器,这称为解耦蒸馏(见图3)。对图像嵌入进行蒸馏的另一个优点是,我们可以采用简单的MSE损失,而不是使用focal损失Lin等人[2017]和dice损失Milletari等人[2016]的组合来进行掩码预测,正如Kirillov等人[2023]所做的那样。
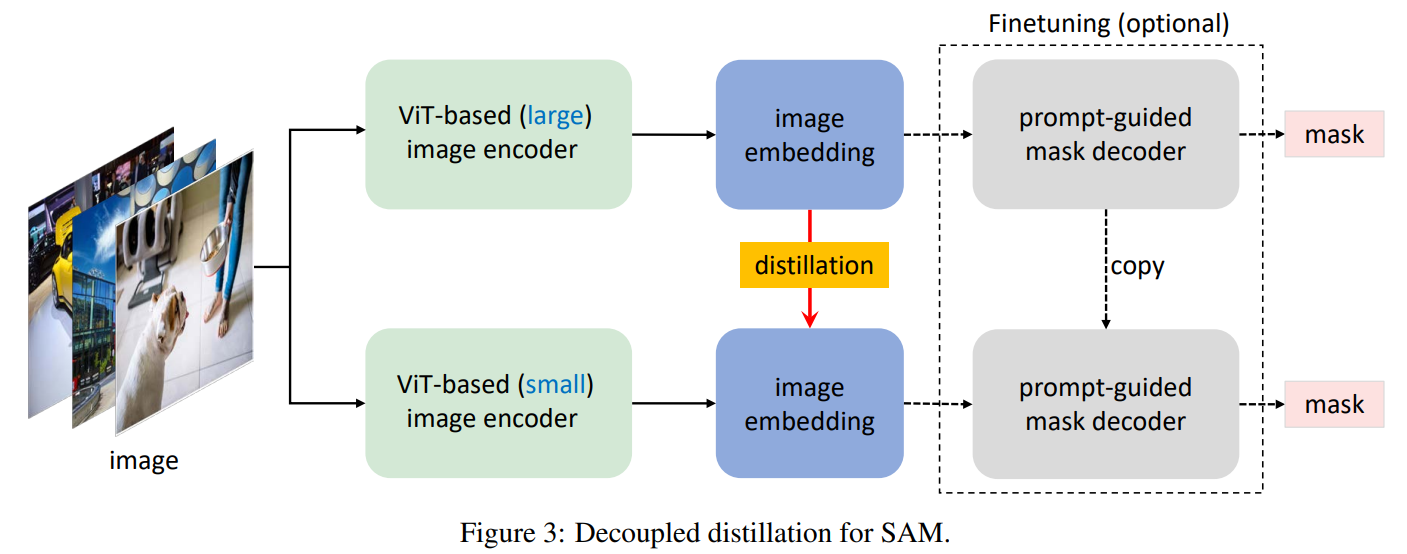
掩码解码器微调的必要性。与半耦合蒸馏不同,上述解耦蒸馏产生了一个轻量级的图像编码器,可能与原始冻结的掩码解码器不匹配。从经验上看,这是不正确的,因为从学生图像编码器生成的图像编码可以足够接近原始教师编码器的图像编码,这使得第二阶段对组合解码器的微调是可选的。在冻结的轻量级图像编码器上微调掩码解码器或将它们联合微调可能会进一步提高性能。
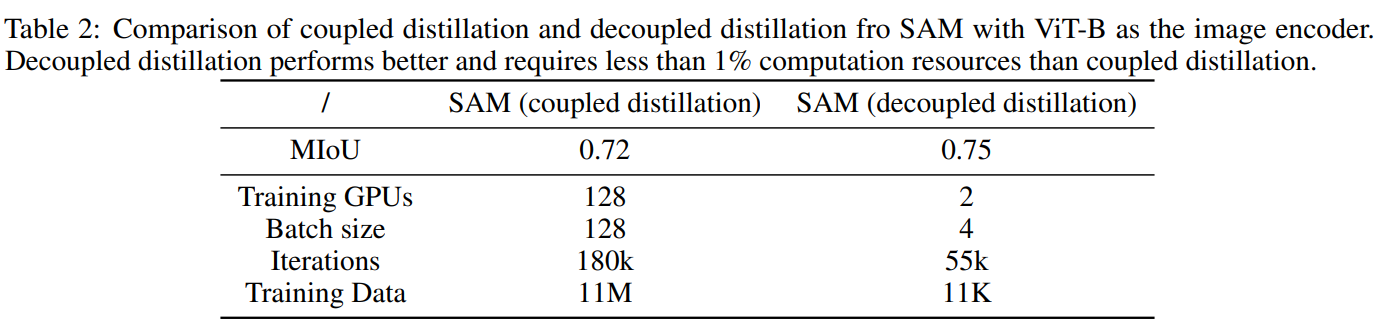
初步评估。本文进行了初步研究,以比较耦合蒸馏和解耦蒸馏。为了进行性能评估,我们计算教师SAM和学生SAM在同一个提示点上生成的两个掩码之间的mIoU。直观上,假设ViT-H生成的掩码是真实掩码,较高的mIoU表明较高的掩码预测性能。对于耦合蒸馏,我们采用原始SAM Kirillov等人[2023]中提供的带有ViT-B的SAM。它在SA-1B (11M图像)上128个GPU(每个GPU 1个样本)上进行180k迭代。相比之下,在解耦蒸馏设置中,我们在2个GPU上(每个GPU两个样本,以节省计算资源)对0.1%的SA-1B数据集(11k)图像样本进行55k迭代训练模型。总体而言,解耦蒸馏比耦合蒸馏占用不到1%的计算资源,而耦合sit的平均mIoU为0.75比0.72(在200个样本上取平均值)。由于ViT-B对移动设备来说仍然是一个重要的负担,因此在下面的实验中,我们使用TinyViT(具有5M参数)Wu等人[2022]基于我们提出的解耦蒸馏。
轻量级图像编码器。我们项目的目标是通过将默认的ViT-H替换为用于移动设备的轻量级图像编码器来获得高效的SAM。作为一个基于vit的骨干,ViT-Tiny具有与Deit-Tiny相似的参数,但性能更好。例如,在ImageNet-1K上,Deit-Yiny达到了72.2%的准确率,而ViT-Tiny达到了79.1%。采用ViT-Tiny进行概念证明,以证明所提出的解耦蒸馏用于训练轻量级MobileSAM的有效性,可以比原始SAM快得多。所采用的轻量级图像编码器由4个阶段组成,逐步降低分辨率。第一阶段由Sandler等人[2018]构建的卷积块,而其余三个阶段由transformer块组成。在模型开始时,有2个步幅为2的卷积块,用于对分辨率进行下采样。不同阶段之间的下采样操作采用步长为2的卷积块进行处理。与Wu等人[2022]不同,我们将最后一次下采样卷积的步长2设置为1,以使最终分辨率与原始SAM的ViT-H图像编码器的分辨率匹配。表3总结了MobileSAM的参数推断速度。注意,第2节中讨论的其他有效的图像编码器也可以用作图像编码器。

4、实验
4.1、实验设置
培训和评估细节。对于图像编码器上的解耦KD,我们使用1%的SA-1B数据集Kirillov等人[2023]在单个GPU上训练8个epoch的轻量级编码器。我们观察到,考虑到教师图像编码器的前向过程比我们采用的学生图像编码器要重得多(见上文),因此教师图像编码器的前向过程花费了更多的计算。为了使蒸馏更快,我们遵循Wu等人[2022]的做法预先保存图像嵌入,以便我们只需要运行一次正向过程。使用单个GPU,我们可以在不到一天的时间内获得我们的MobileSAM。长时间使用更多的gpu训练我们的MobileSAM,预计可以产生更好的性能。对掩码解码器进行微调的初步研究进一步提高了MobileSAM的性能,然而,为了简单起见,我们在本文的这个版本中省略了这一步。为了定量评估蒸馏后的SAM,我们计算了原始SAM和MobileSAM预测的掩码之间的mIoU。
4.2、MobileSAM的性能与原版SAM相当
对于主要结果,报告了带有两种类型提示的预测掩码:点和框。我们没有报告文本提示的结果,因为SAM的官方github项目没有提供文本引导掩码解码器的预训练模型。以point作为提示的结果如图4所示,以box作为提示的结果如图5所示。MobileSAM做出了令人满意的掩码预测,与原始SAM类似。

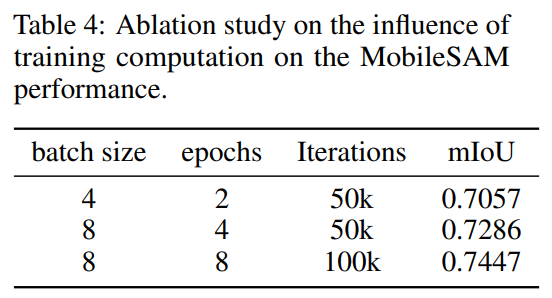
消融实验。本文对训练计算对SAM性能的影响进行了消融研究。表4的结果表明,在相同的迭代次数下,增加批量大小可以提高模型性能。此外,在批量大小下,通过增加训练步数,更多的更新迭代也有利于性能的提升。注意,所有实验都是在单个GPU上进行的。我们期望增加gpu的数量来允许更大的批处理大小或进一步增加迭代次数可以进一步提高性能。

4.3、MobileSAM优于FastSAM
分割一切vs .分割一切。请注意,原始的SAM论文Kirillov等人[2023]的标题是“segment anything”而不是“segment everything”。正如Kirillov等人[2023]强调的那样,SAM执行提示分割的任务,它“在给定任何分割提示时返回一个有效的分割掩码”(引自Kirillov等人[2023])。提示符的作用是指定要在图像中分割的内容。理论上,只要正确设置提示符,任何对象都可以被分割,因此被称为“segment anything”。相比之下," segment everything"本质上是Kirillov等人[2023]生成的对象建议,对其来说,提示是不必要的。在Kirillov等人[2023]中,“分割一切”(对象建议生成)被选择为下游任务之一,以演示其零样本迁移性能。总而言之," segment anything"解决了对任何对象进行可提示分割的基础任务,而" segment everything"解决了对所有对象生成掩模建议的下游任务。由于“segment everything”并不一定需要提示,因此FastSAM以无提示的方式直接使用YOLO v8生成掩码建议。为了实现快速分割,设计了一种映射算法从建议掩码集合中选择掩码。值得强调的是,后续评估其泛化性/鲁棒性或研究其通用性的工作主要集中在anything模式,而不是everything模式,因为前者解决的是基础任务。因此,与FastSAM的比较主要集中在“segment anything”,但为了完整性,我们也提供了“segment everything”的比较。

MobileSAM更快、更小。FastSAM由一个基于yolov8的检测分支和一个基于yolact的分割分支组成,用于执行无提示的掩码建议生成。它有68M个参数,处理一幅图像需要40ms。相比之下,MobileSAM的参数少了10M,这要小得多。对于推理速度,在单个GPU上,处理一个图像需要40ms,而我们只需要10ms,这是FastSAM的4倍(见表6)。

mIoU比较下分段任何模式。进一步比较预测掩码与原始SAM之间的mIoU。建议FastSAM用多个点来预测掩模,我们选择一个作为前景,另一个作为背景。表7的结果显示,FastSAM的mIoU比MobileSAM小得多,表明FastSAM的掩码预测与原始SAM有很大的不同。此外,当两个提示点之间的距离增大时,FastSAM的mIoU减小得很快。这主要是由于当前景提示点设置得太靠近背景提示点时,FastSAM经常无法预测目标。

分割一切的结果。“segment everything”的结果如图6所示。为了完整性,我们还报告了原始SAM的结果,它生成了一个令人满意的目标建议。我们有两个主要的观察结果。首先,MobileSAM的结果与原来的SAM惊人地吻合。相比之下,FastSAM的结果往往不那么令人满意。例如,FastSAM经常无法预测一些物体,例如第一张图像中的屋顶。此外,遮罩方案有时很难解释(参见第一张图片中舞台的遮罩和第二张图片中天空的遮罩)。其次,FastSAM通常生成具有非平滑边界的掩码,我们建议读者放大以查看图6中的细节。例如,第三张图中的柱子边界不平滑,而原始的SAM和我们的MobileSAM就没有这个问题。
5、结论
本文旨在通过用一个轻量级的图像编码器替换重量级的图像编码器,使SAM对移动设备友好。本文发现,像原始SAM论文中那样训练新SAM的天真方法会导致不满意的性能,特别是在训练来源有限的设置下。原因是图像编码器和掩模解码器的耦合优化,因此本文提出解耦蒸馏,将知识从原始SAM中的图像编码器ViT-H蒸馏到一个轻量级的图像编码器。由此产生的轻量级图像编码器可以自动与原始SAM中的掩码解码器兼容。我们的MobileSAM体积是原来的60倍多,但性能与原来的SAM相当。此外,我们还将MobileSAM与并发的FastSAM进行了比较,结果表明MobileSAM具有更好的性能。我们的MobileSAM比并发的FastSAM速度快4倍,体积小7倍,更适合移动应用。因为我们的MobileSAM保留了原始SAM的所有管道,只是替换了图像编码器,所以它可以即插即用,让现有的基于SAM的项目几乎不用花什么精力就从重量级的SAM迁移到轻量级的SAM。