有时候我们用Python控制浏览器进行爬虫或者自动化办公的时候,有些元素会在iframe里面(内嵌框架),如果我们的驱动器对象不切进去,会使得程序会报错,也会有很多小伙伴,觉得自己的代码没有错,但是就是获取不到元素或者直接报错,那么你就要好好观察,是不是你想获取的元素在iframe里面(内嵌框架)
驱动器下载:这篇博客我写了:点我查看
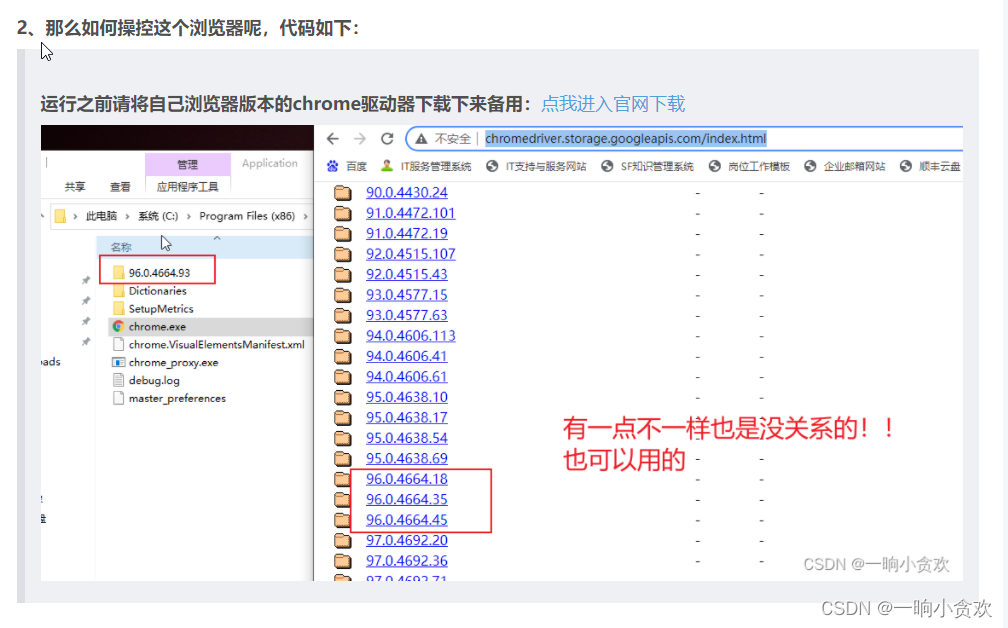
举个例子:
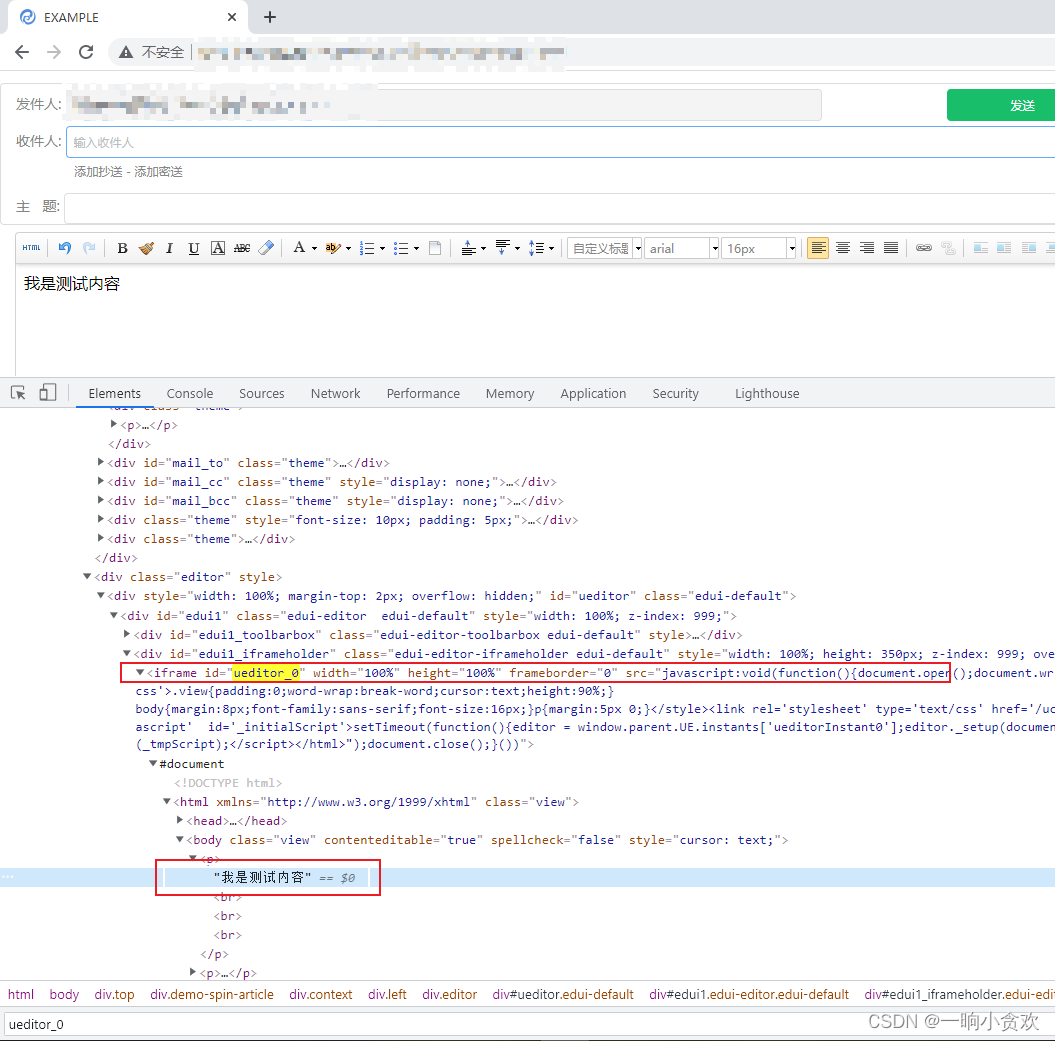
我想获取p标签里面的文本,但是我们的驱动器对象要优先切入iframe里面
记住在根据自己的实际情况切出iframe
这里的iframe的id = " ueditor_0",我们就通过它的id,切进去,代码如下
切出:driver.switch_to.default_content() 切出
import time
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_driver = "./chromedriver.exe"
driver = webdriver.Chrome()
driver.get("填写自己的网址")
driver.switch_to.frame("ueditor_0")
content = driver.find_element(By.XPATH,'//body[@class="view"]//p[1]').text
print(content)
driver.switch_to.default_content()
注意!!
python3.8以上请修改:
chrome_options = Options()
chrome_options.add_experimental_option('debuggerAddress', '127.0.0.1:9222')
chrome_driver = './chromedriver.exe'
service = Service(chrome_driver)
driver = webdriver.Chrome(service=service, options=chrome_options)
成功获取到想要的内容
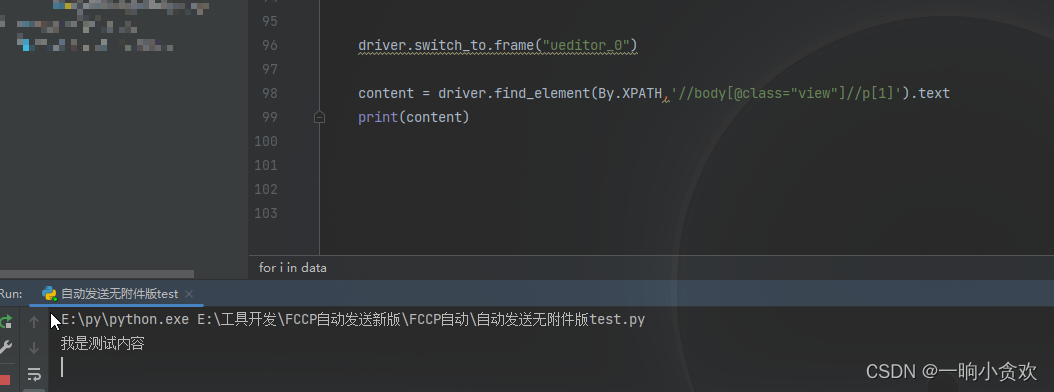
希望对大家有帮助,如有错误,欢迎指正
致力于办公自动化的小小程序员一枚
致力于写出清楚的博客
都看到这了,关注+点赞+收藏=不迷路!!