文章目录
前言
pandas是Python中一种开源的数据处理库,它提供了高性能、易用的数据结构和数据分析工具,使得处理和分析数据变得更加简单和快速。
pandas的主要作用包括:
-
数据输入和输出:pandas支持的数据格式非常多,包括CSV、Excel、JSON、SQL、HTML等,方便用户读取和写入数据。
-
数据清洗和预处理:pandas提供了一系列处理缺失值、重复值、异常值的函数,可以帮助用户快速清洗和预处理数据。
-
数据转换和加工:pandas支持基本的数学、逻辑和字符串操作,同时也支持数据的聚合、变换、透视等操作,方便用户进行数据加工和转换。
-
数据分析和可视化:pandas可以进行数据分析和统计分析,还支持数据可视化,方便用户进行数据分析和展示。
总的来说,pandas是一款功能强大的数据处理库,可以帮助用户高效、快速地进行数据处理、分析和可视化。
一、杂项
1.pandas读取数据库数据
1.1 读取MySql数据
import MySQLdb
import pandas as pd
conn = MySQLdb.connect(host = host,port = port,user = username,passwd = password,db = db_name)
df = pd.read_sql('select * from table_name',con=conn)
conn.close()
1.2 读取SqlServer数据
import pymssql
conn = pymssql.connect(host=host, port=port ,user=username, password=password, database=database)
df = pd.read_sql("select * from table_name",con=conn)
conn.close()
1.3 读取sqlite数据
import sqlite3
conn = sqlite3.connect('database.db')
df = pd.read_sql('SELECT * FROM table_name', conn)
conn.close()
3.Pandas转sql使用
安装第三方库pandasql
pip install pandasql
具体使用
import pandas as pd
from pandasql import sqldf
df1 = pd.read_excel("student.xlsx")
df2 = pd.read_excel("sc.xlsx")
df3 = pd.read_excel("course.xlsx")
df4 = pd.read_excel("teacher.xlsx")
pysqldf = lambda q: sqldf(q, globals())
query1 = "select * from df1 limit 5"
query2 = "select * from df2 limit 5"
query3 = "select * from df3"
query4 = "select * from df4"
sqldf(query1)
sqldf(query2)
sqldf(query3)
sqldf(query4)
4.Pandas读取JSON文件
4.1 基本使用
1、读取文本
import pandas as pd
df = pd.read_json('sites.json')
print(df.to_string())
to_string() 用于返回 DataFrame 类型的数据,我们也可以直接处理 JSON 字符串。
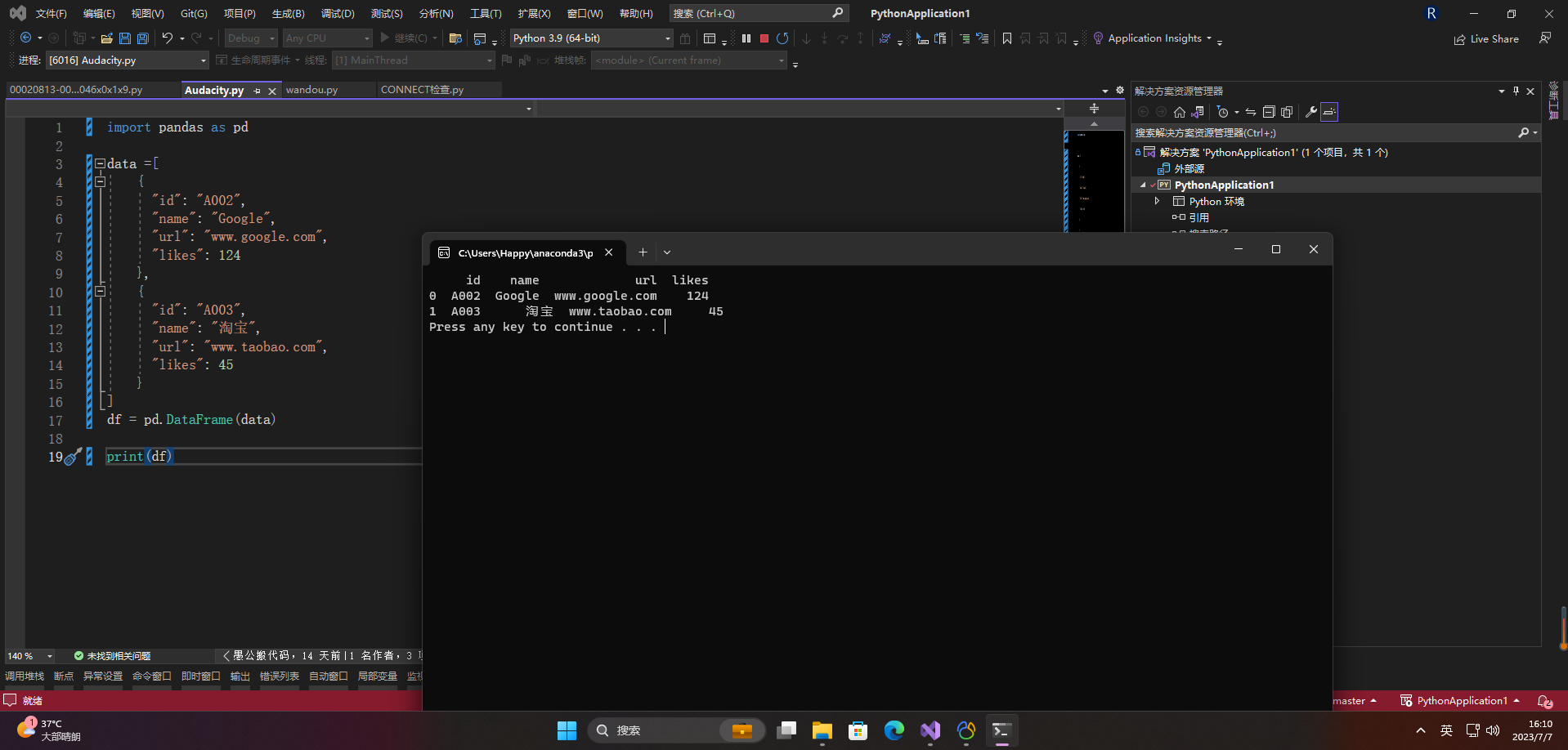
2、读取字符串
import pandas as pd
data =[
{
"id": "A002",
"name": "Google",
"url": "www.google.com",
"likes": 124
},
{
"id": "A003",
"name": "淘宝",
"url": "www.taobao.com",
"likes": 45
}
]
df = pd.DataFrame(data)
print(df)
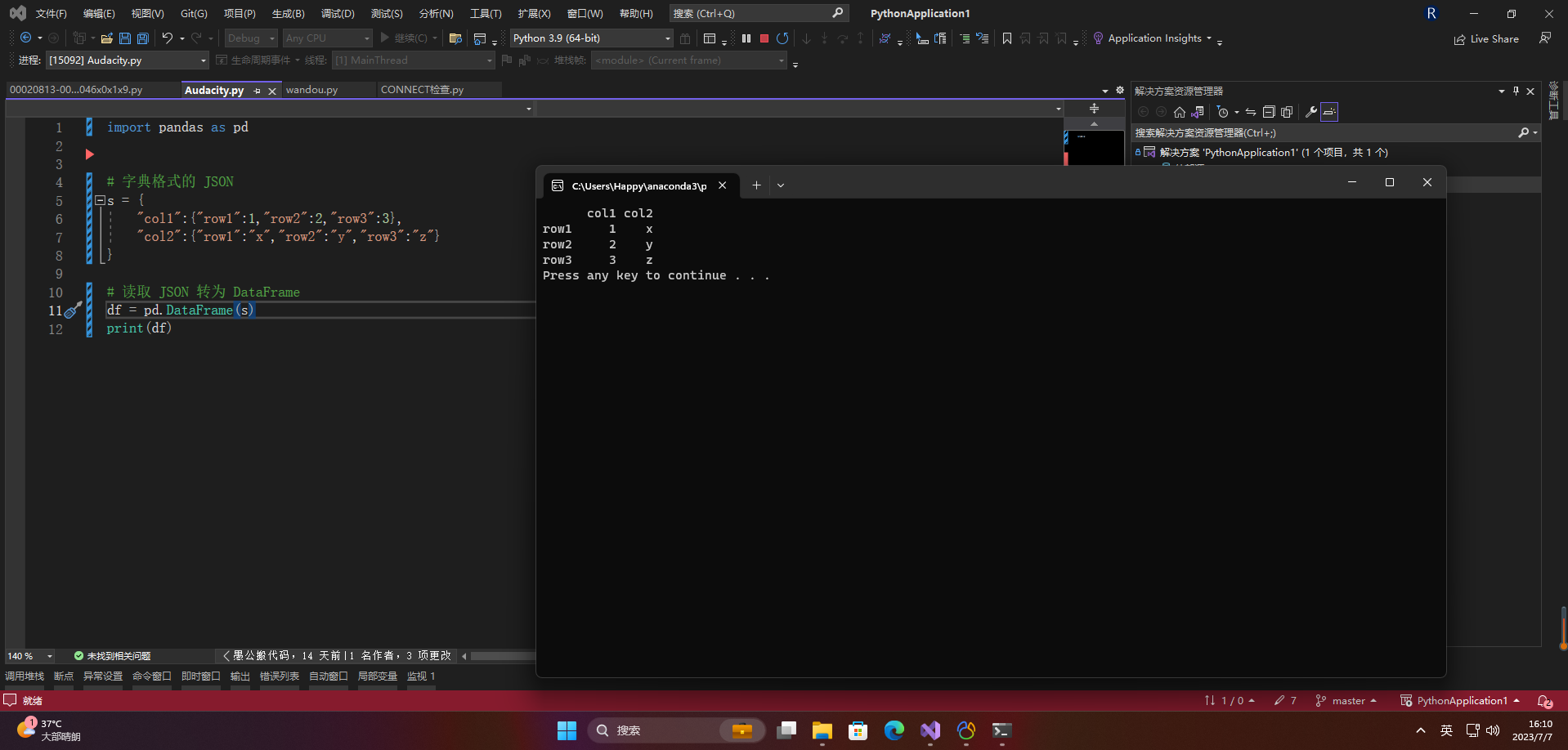
import pandas as pd
# 字典格式的 JSON
s = {
"col1":{
"row1":1,"row2":2,"row3":3},
"col2":{
"row1":"x","row2":"y","row3":"z"}
}
# 读取 JSON 转为 DataFrame
df = pd.DataFrame(s)
print(df)
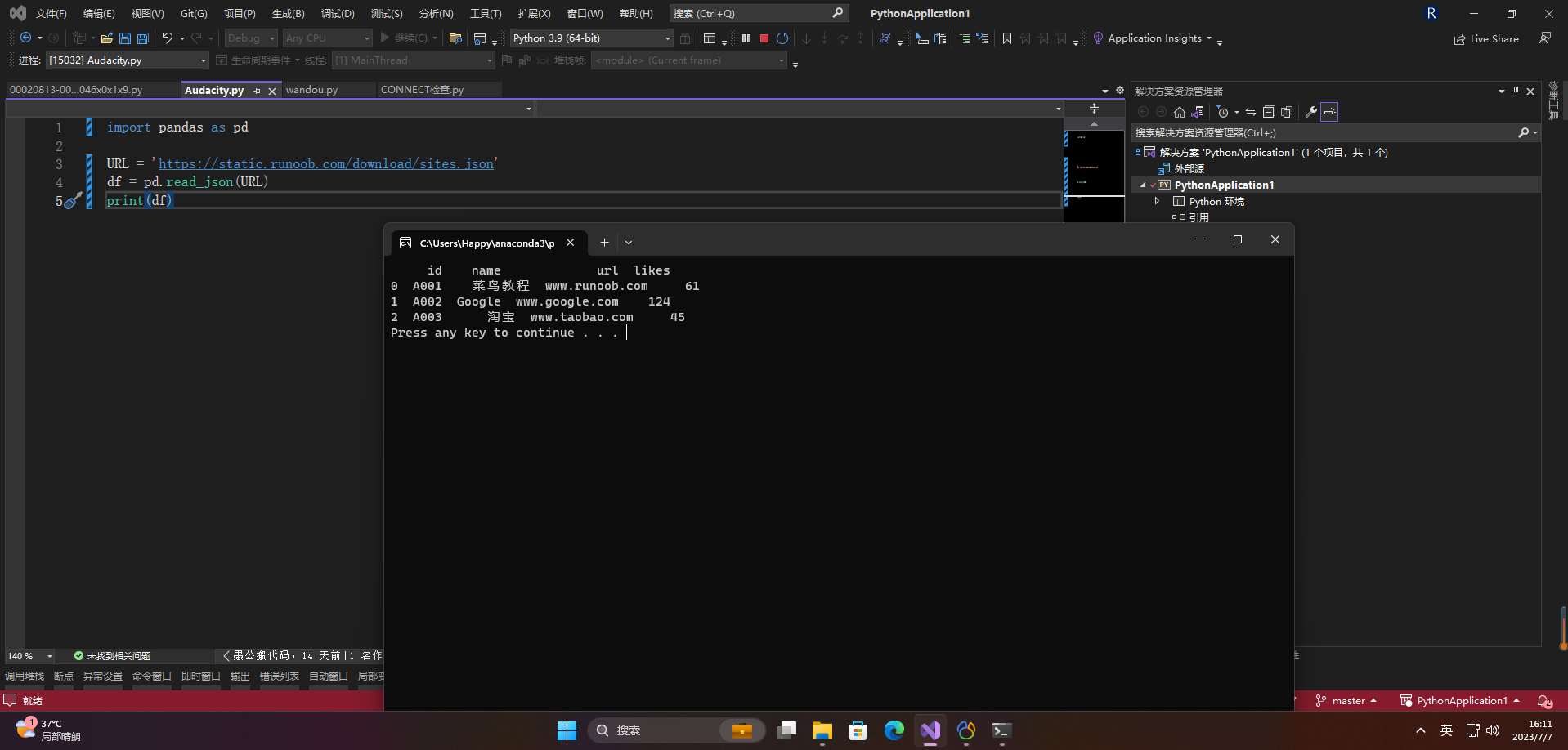
3、读取远程json
import pandas as pd
URL = 'https://static.runoob.com/download/sites.json'
df = pd.read_json(URL)
print(df)
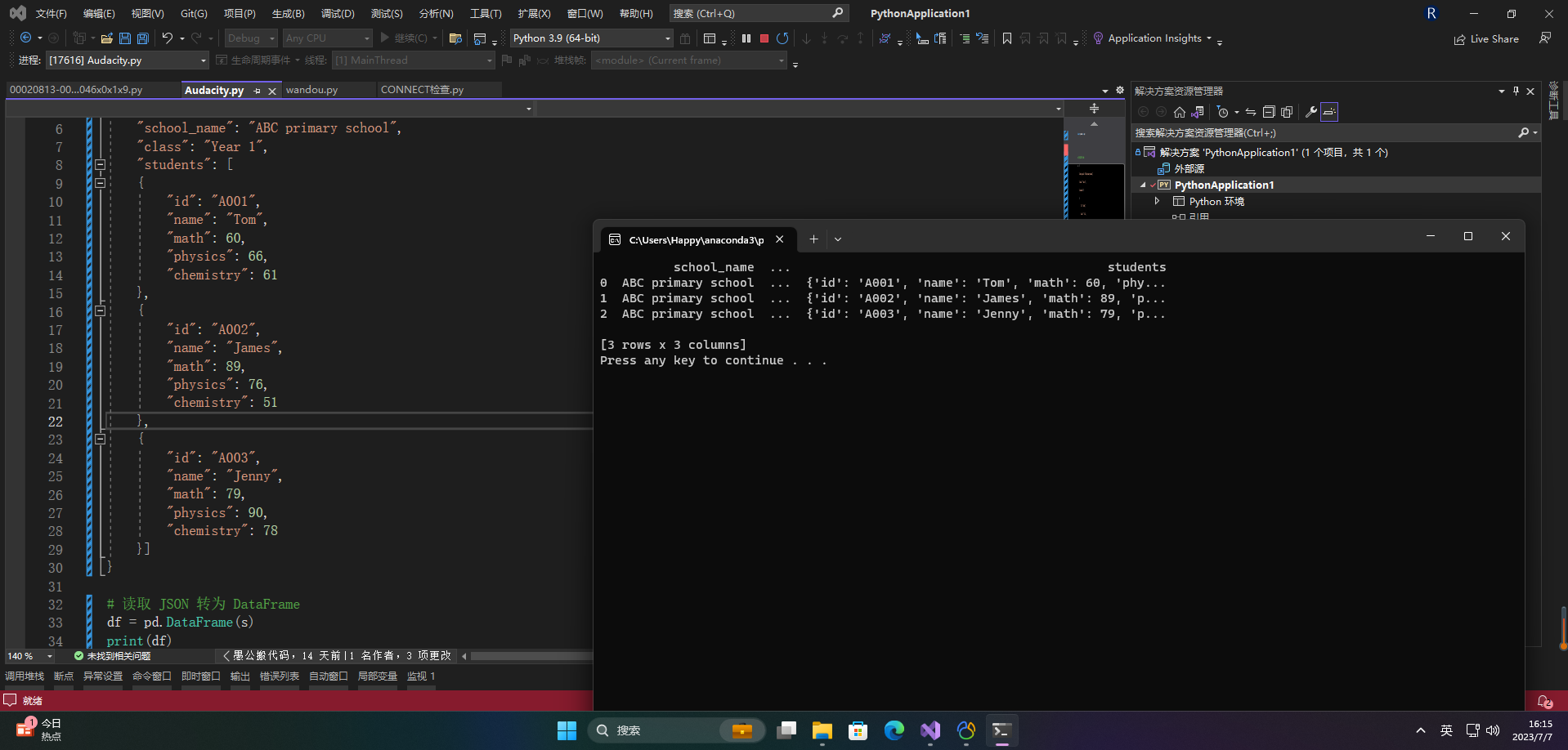
4.2 内嵌的 JSON 数据
import pandas as pd
# 字典格式的 JSON
s = {
"school_name": "ABC primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
# 读取 JSON 转为 DataFrame
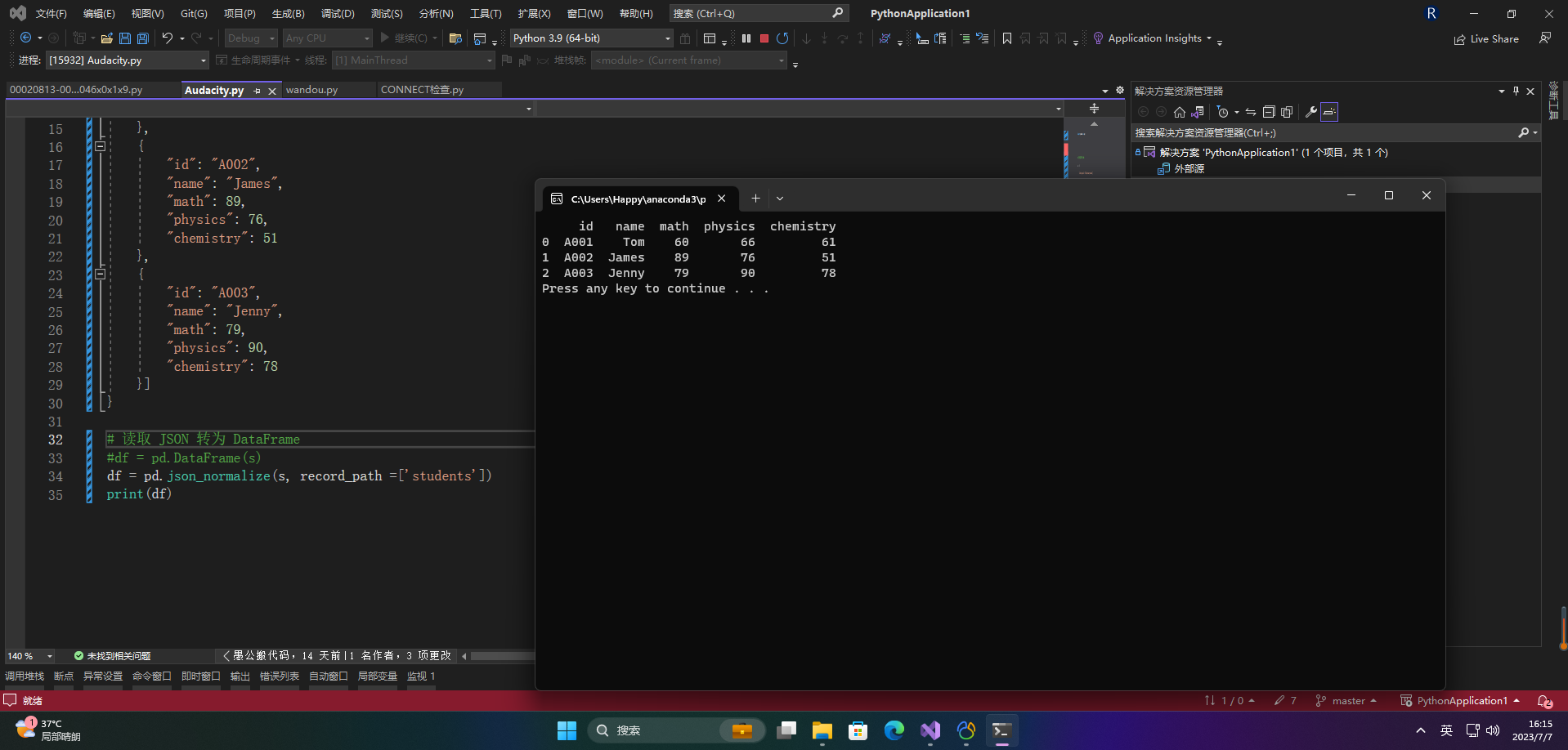
df = pd.DataFrame(s)
print(df)
import pandas as pd
# 字典格式的 JSON
s = {
"school_name": "ABC primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
# 读取 JSON 转为 DataFrame
#df = pd.DataFrame(s)
df = pd.json_normalize(s, record_path =['students'])
print(df)
import pandas as pd
# 字典格式的 JSON
s = {
"school_name": "local primary school",
"class": "Year 1",
"info": {
"president": "John Kasich",
"address": "ABC road, London, UK",
"contacts": {
"email": "[email protected]",
"tel": "123456789"
}
},
"students": [
{
"id": "A001",
"name": "Tom",
"math": 60,
"physics": 66,
"chemistry": 61
},
{
"id": "A002",
"name": "James",
"math": 89,
"physics": 76,
"chemistry": 51
},
{
"id": "A003",
"name": "Jenny",
"math": 79,
"physics": 90,
"chemistry": 78
}]
}
# 读取 JSON 转为 DataFrame
#df = pd.DataFrame(s)
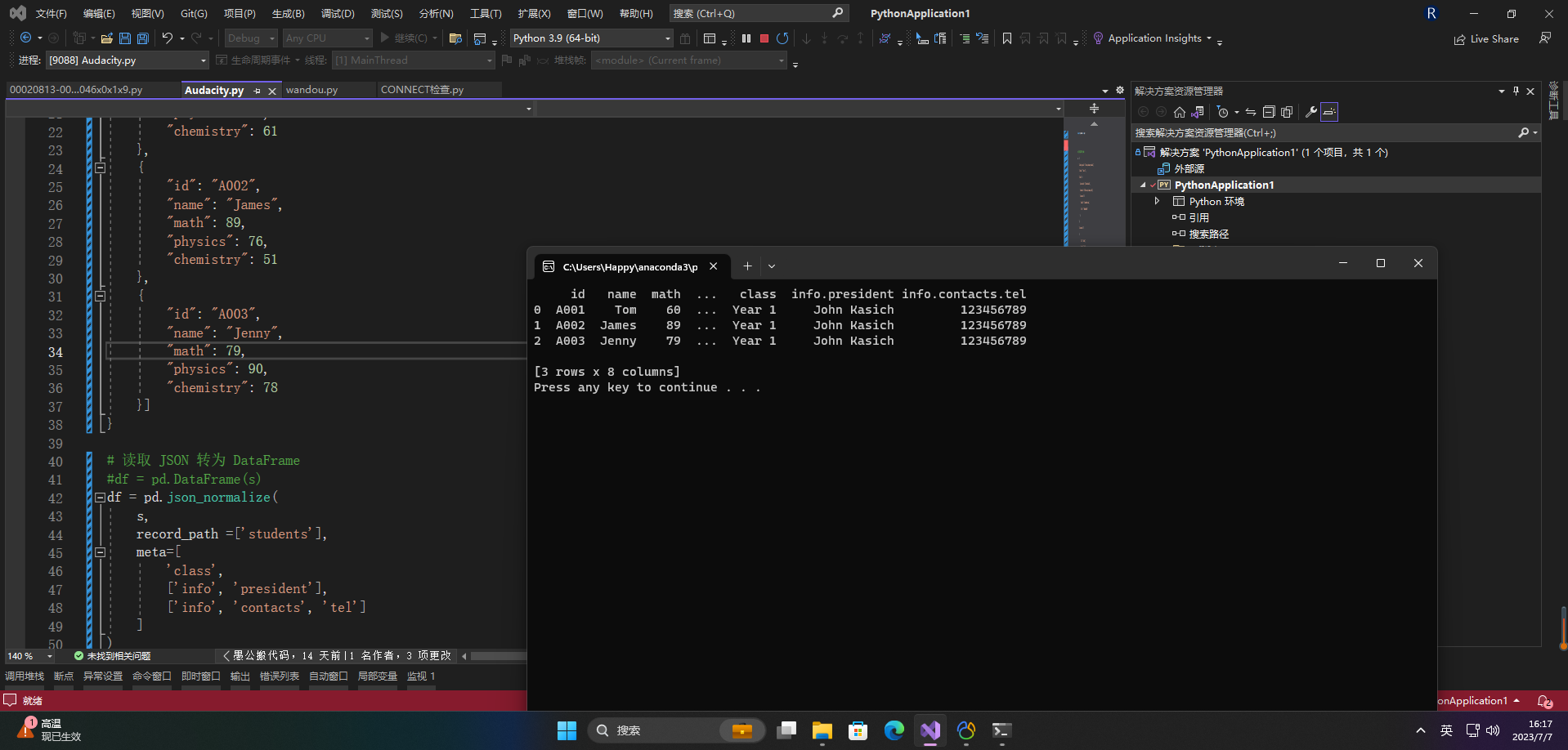
df = pd.json_normalize(
s,
record_path =['students'],
meta=[
'class',
['info', 'president'],
['info', 'contacts', 'tel']
]
)
print(df)
4.3 读取内嵌数据中的一组数据
这里我们需要使用到 glom 模块来处理数据套嵌,glom 模块允许我们使用 . 来访问内嵌对象的属性。
pip3 install glom
import pandas as pd
from glom import glom
# 字典格式的 JSON
s = {
"school_name": "local primary school",
"class": "Year 1",
"students": [
{
"id": "A001",
"name": "Tom",
"grade": {
"math": 60,
"physics": 66,
"chemistry": 61
}
},
{
"id": "A002",
"name": "James",
"grade": {
"math": 89,
"physics": 76,
"chemistry": 51
}
},
{
"id": "A003",
"name": "Jenny",
"grade": {
"math": 79,
"physics": 90,
"chemistry": 78
}
}]
}
# 读取 JSON 转为 DataFrame
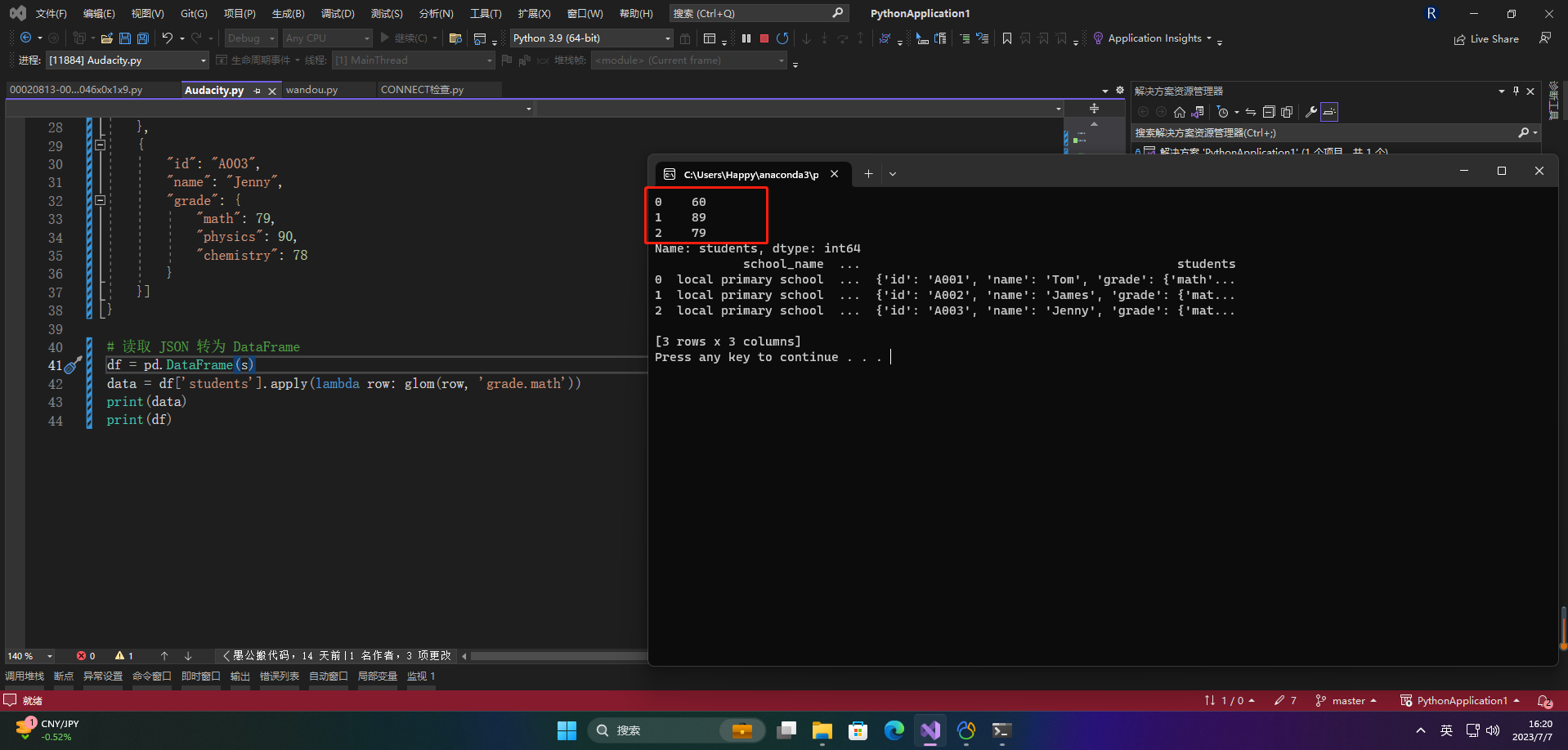
df = pd.DataFrame(s)
data = df['students'].apply(lambda row: glom(row, 'grade.math'))
print(data)
print(df)
5.Pandas数据清洗
介绍几个比较重要的点
1、指定空数据类型
import pandas as pd
missing_values = ["n/a", "na", "--"]
df = pd.read_csv('property-data.csv', na_values = missing_values)
2、日期格式化
import pandas as pd
# 第三个日期格式错误
data = {
"Date": ['2020/12/01', '2020/12/02' , '20201226'],
"duration": [50, 40, 45]
}
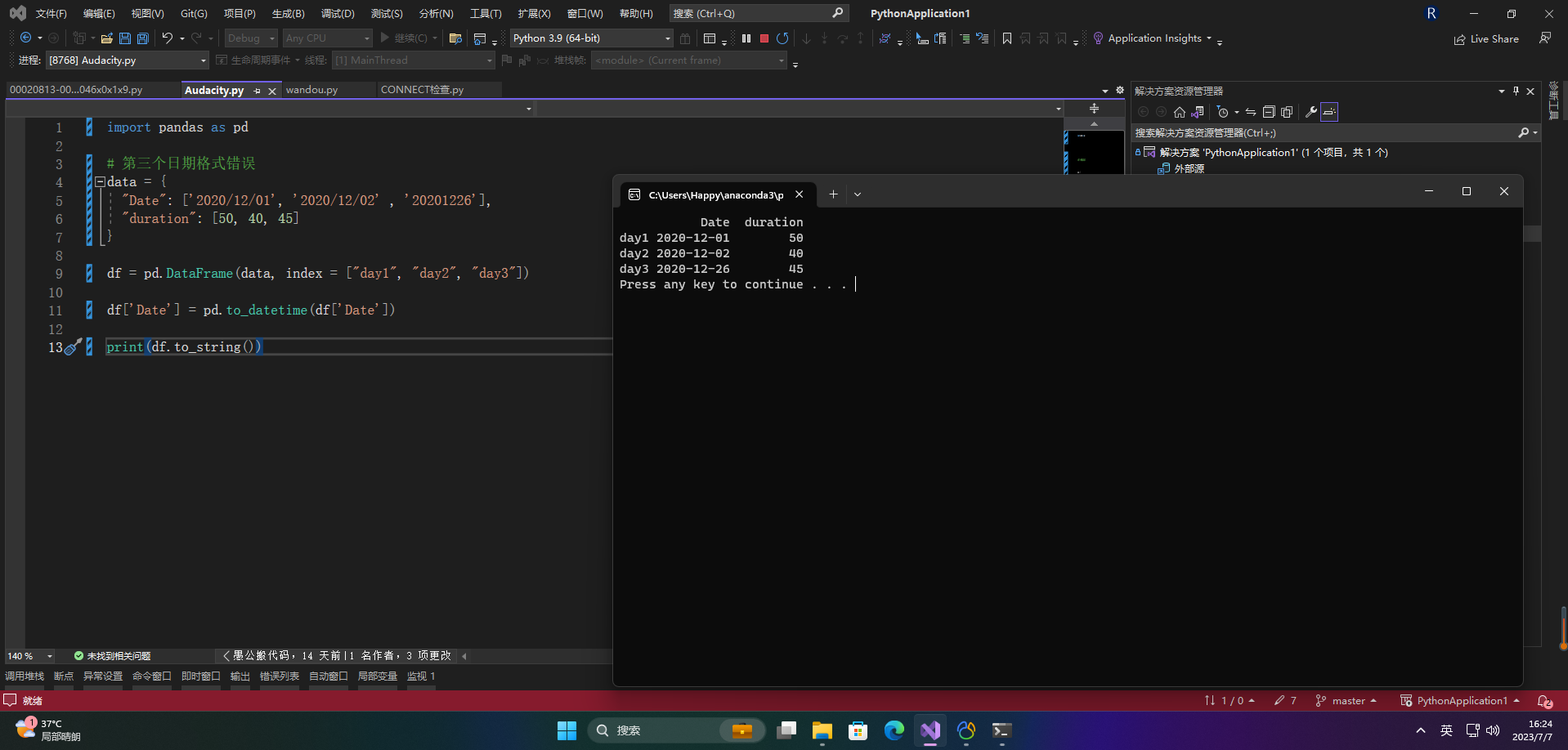
df = pd.DataFrame(data, index = ["day1", "day2", "day3"])
df['Date'] = pd.to_datetime(df['Date'])
print(df.to_string())
二、案例
import pandas as pd
# 读取 JSON 数据
df = pd.read_json('data.json')
# 删除缺失值
df = df.dropna()
# 用指定的值填充缺失值
df = df.fillna({
'age': 0, 'score': 0})
# 重命名列名
df = df.rename(columns={
'name': '姓名', 'age': '年龄', 'gender': '性别', 'score': '成绩'})
# 按成绩排序
df = df.sort_values(by='成绩', ascending=False)
# 按性别分组并计算平均年龄和成绩
grouped = df.groupby('性别').agg({
'年龄': 'mean', '成绩': 'mean'})
# 选择成绩大于等于90的行,并只保留姓名和成绩两列
df = df.loc[df['成绩'] >= 90, ['姓名', '成绩']]
# 计算每列的基本统计信息
stats = df.describe()
# 计算每列的平均值
mean = df.mean()
# 计算每列的中位数
median = df.median()
# 计算每列的众数
mode = df.mode()
# 计算每列非缺失值的数量
count = df.count()