一、Huffman编码
霍夫曼(Huffman)树是一类带权路径长度最短的二叉树树。Huffman树的一个非常重要的应用就是进行Huffman编码以得到0-1码流进行快速传输。
在电报收发等数据通讯中,常需要将传送的文字转换成由二进制字符0、1组成的字符串来传输。为了使收发的速度提高,就要求电文编码要尽可能地短。此外,要设计长短不等的编码,还必须保证任意字符的编码都不是另一个字符编码的前缀,目的是解决译码的二义性。
例如:假设有一电文“EABCBAEDBCEEEDCEBABC”,其中的字符集为C={A,B,C,D,E},各个字符出现的次数集为W={3, 5, 4, 2, 6}。

以字符集C作为叶子结点,次数集W作为结点的权值来构造 Huffman树,则得到如下的Huffman树:
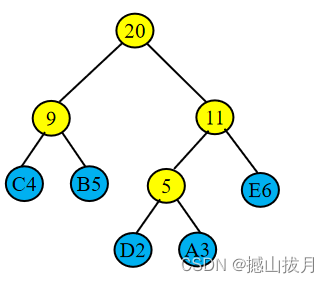
其中树叶结点就是电文中的字符,树叶中的数字就是对应字符出现的次数。
规定Huffman树中左分支代表“0”,右分支代表“1” ,则得到如下的Huffman树:
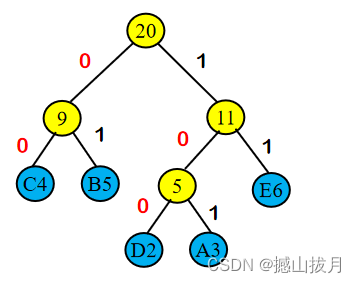
从根结点到每个叶子结点所经历的路径分支上的“0”或“1”所组成的字符串,为该结点所对应的编码,称之为Huffman编码。
各个字符的Huffman编码结果如下:
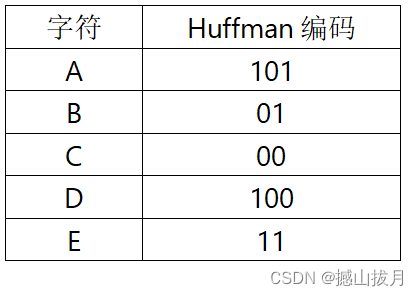
由于每个字符都是叶子结点,不可能出现在根结点到其它字符结点的路径上,所以一个字符的Huffman编码不可能是另一个字符的Huffman编码的前缀。
二、Huffman编码算法
1.编码方式
根据出现频度(权值)Weight,对叶子结点的Huffman编码有两种方式:
1)从叶子结点到根逆向处理,求得每个叶子结点对应字符的Huffman编码。
2)从根结点开始遍历整棵二叉树,求得每个叶子结点对应字符的Huffman编码。
2.逆向编码算法
本文以逆向编码为例,给出Huffman编码的算法。
对于每个树叶结点,其Huffman编码算法如下:
Step 1:把树叶作为当前结点,并获取其序号(数组的下标)
Step 2:获取当前结点的双亲结点的序号
Step 3:判断当前结点是其双亲结点的左或者右子树,如果是左,则编码为’0’,否则为’1’
Step 4:如果双亲结点为树根,则结束当前树叶的编码;否则,更新当前结点序号为其双亲的序号,返回Step 2.
注:因为是从树叶开始到树根的编码,因此在存储编码的时候是倒序存储,即把当前树叶编码的第一个字符存到数组的最后位置,然后向前依次存储。
三、Huffman编码之C程序
1.Huffman编码算法
/******************************************************************************************
函数:void Huff_coding( int WeightNum, HTNode *HT, int NodeNum, char **HC )
功能:对Huffman树的叶子结点进行编码。
说明:Huffman树的结点存储在结构体数组HT里,其中前面WeightNum个元素为叶子结点,存储给定信息
的权值。
输入参数:WeightNum:权值的个数,也就是Huffman树上叶子结点的个数
NodeNum: Huffman树上全部结点的个数
HT: 存储Huffman树上所有结点的信息,权、双亲编号、左孩子编号、右孩子编号
输出参数:HC: 存储树叶结点的Huffman编码,每个编码均为一个字符串
*******************************************************************************************/
void Huff_coding( int WeightNum, HTNode *HT, int NodeNum, char **HC )
{
int k, sp, p, fp;
char *cd;
cd = new char[ WeightNum + 1 ]; // 动态分配存储编码的工作空间
cd[ WeightNum ] = '\0'; // 编码的结束标志
for ( k = 1; k <= WeightNum; k++ ) // 逐个求字符的编码
{
sp = WeightNum;
//从叶子结点到根逆向求编码
for( p = k, fp = HT[k].Parent; fp != 0; p = fp, fp = HT[p].Parent )
{
if ( HT[fp].Lchild == p )
cd[ --sp ] = '0';
else
cd[ --sp ] = '1';
}
HC[k] = new char[ WeightNum - sp + 1 ]; //为第k个字符分配空间
strcpy( HC[k], &cd[sp] ) ;
}
delete[] cd ;
}
2.完整的测试代码
#include"stdio.h"
#include"string.h"
#define MAX_NODE 200 //Max_Node>2n-1
//存储Huffman树结点
typedef struct
{
char Character; //信息字符
int Weight; //权
int Parent; //双亲结点编号
int Lchild; //左孩子结点编号
int Rchild; //右孩子结点编号
} HTNode ;
//创建一棵叶子结点数为WeightNum的Huffman树,生成Huffman树后,树的根结点的下标是2WeightNum-1
void Create_Huffman( int WeightNum, HTNode *HT, int NodeNum );
//对已经创建的huffman树进行编码
void Huff_coding( int WeightNum, HTNode *HT, int NodeNum, char **HC );
int main()
{
int WeightNum;//已知的权值的个数,也就是叶子结点个数
int NodeNum; //huffman树上全部结点个数
HTNode *HT; //存储Huffman树的结点
char **HC; //存储Huffman编码
WeightNum = 5;
NodeNum = 2 * WeightNum - 1;
//建立Huffman树
HT = new HTNode[MAX_NODE];
Create_Huffman( WeightNum, HT, NodeNum );
//向屏幕输出Huffman树的结点
printf( "Huffman树上的结点:\n" );
int i;
for( i = 1; i <= NodeNum; i++ )
{
if( i <= WeightNum )
printf( "%c %d %d %d %d\n", HT[i].Character, HT[i].Weight, HT[i].Parent, HT[i].Lchild, HT[i].Rchild );
else
printf( "%c %d %d %d %d\n", ' ', HT[i].Weight, HT[i].Parent, HT[i].Lchild, HT[i].Rchild );
}
//Huffman编码
HC = new char*[ WeightNum + 1];
Huff_coding( WeightNum, HT, NodeNum, HC );
//向屏幕输出Huffman编码
printf( "Huffman编码:\n" );
for( i = 1; i <= WeightNum; i++ )
{
printf( "%c: %s\n", HT[i].Character, HC[i] );
}
delete[] HT;
delete[] HC;
return 0;
}
/******************************************************************************************
函数:void Create_Huffman( int WeightNum, HTNode *HT, int NodeNum )
功能:对给定的权值,生成Huffman树
说明:Huffman树的结点存储在结构体数组HT里,其中前面WeightNum个元素为叶子结点,存储给定信息
的权值。
输入参数:WeightNum:权值的个数,也就是Huffman树上叶子结点的个数
NodeNum: Huffman树上全部结点的个数
输出参数:HT: 存储Huffman树上所有结点的信息,权、双亲编号、左孩子编号、右孩子编号
*******************************************************************************************/
void Create_Huffman( int WeightNum, HTNode *HT, int NodeNum )
{
int k , j; //循环下标
int w1, w2; //w1 , w2分别保存权值最小的两个权值
int p1, p2; //p1 , p2保存两个最小权值的下标
for ( k = 1; k <= NodeNum; k++ ) //step1:初始化向量HT,即所有成员均当做树根
{
if( k <= WeightNum ) //输入时,所有叶子结点都有权值
{
printf( "Please Input Character : Character =?" );
scanf( "%c", &HT[k].Character );
printf( "Please Input Weight : Weight =?" );
scanf( "%d", &HT[k].Weight );
getchar(); //过滤输入数据时的换行符
}
else
HT[k].Weight = 0; //非叶子结点没有权值
HT[k].Parent = HT[k].Lchild = HT[k].Rchild = 0 ;
}
for( k = WeightNum + 1; k <= NodeNum; k++ )//step2:对非叶子节点赋值,以生成H树
{
p1 = 0;
p2 = 0;
w1 = 0xFFFFFFF;
w2 = w1;
for( j = 1 ; j <= k-1 ; j++) //找到权值最小的两个值及其下标
{
if( HT[j].Parent == 0 ) //尚未合并
{
if( HT[j].Weight < w1 )
{
w2 = w1;
p2 = p1;
w1 = HT[j].Weight;
p1 = j;
}
else if( HT[j].Weight < w2 )
{
w2 = HT[j].Weight;
p2 = j;
}
}
}
HT[k].Lchild = p1;
HT[k].Rchild = p2;
HT[k].Weight = w1 + w2;
HT[p1].Parent = k;
HT[p2].Parent = k;
}
}
/******************************************************************************************
函数:void Huff_coding( int WeightNum, HTNode *HT, int NodeNum, char **HC )
功能:对Huffman树的叶子结点进行编码。
说明:Huffman树的结点存储在结构体数组HT里,其中前面WeightNum个元素为叶子结点,存储给定信息
的权值。
输入参数:WeightNum:权值的个数,也就是Huffman树上叶子结点的个数
NodeNum: Huffman树上全部结点的个数
HT: 存储Huffman树上所有结点的信息,权、双亲编号、左孩子编号、右孩子编号
输出参数:HC: 存储树叶结点的Huffman编码,每个编码均为一个字符串
*******************************************************************************************/
void Huff_coding( int WeightNum, HTNode *HT, int NodeNum, char **HC )
{
int k, sp, p, fp;
char *cd;
cd = new char[ WeightNum + 1 ]; // 动态分配存储编码的工作空间
cd[ WeightNum ] = '\0'; // 编码的结束标志
for ( k = 1; k <= WeightNum; k++ ) // 逐个求字符的编码
{
sp = WeightNum;
//从叶子结点到根逆向求编码
for( p = k, fp = HT[k].Parent; fp != 0; p = fp, fp = HT[p].Parent )
{
if ( HT[fp].Lchild == p )
cd[ --sp ] = '0';
else
cd[ --sp ] = '1';
}
HC[k] = new char[ WeightNum - sp + 1 ]; //为第k个字符分配空间
strcpy( HC[k], &cd[sp] ) ;
}
delete[] cd ;
}
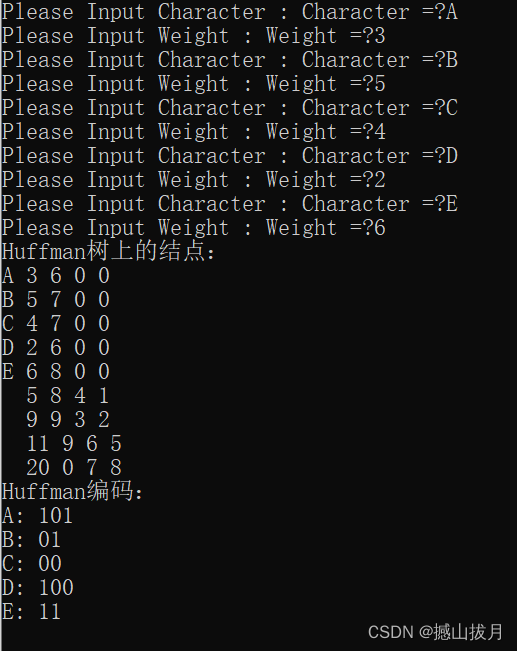
3.测试结果