本篇文章是一份关于大型语言模型评估的综述,涵盖了评估的各种方法,包括评估什么、在哪里评估以及如何评估。
进NLP群—>加入NLP交流群

文章首先介绍了大型语言模型的发展历程和应用领域,然后详细介绍了大型语言模型的评估方法,包括人工评估、自动评估和基准测试等。接着,文章介绍了大型语言模型在不同任务中的表现,包括文本生成、问答、机器翻译等。最后,文章总结了大型语言模型评估的挑战和未来发展方向。
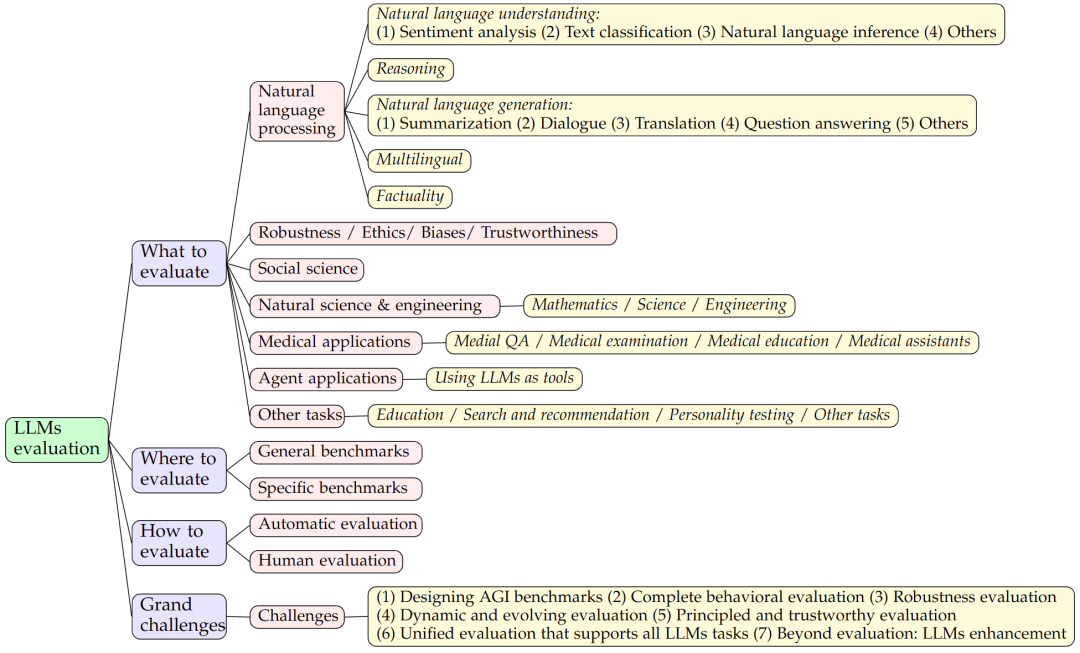

评估内容
本次调查涵盖了多个关键评估任务,包括一般自然语言处理任务、推理、医疗应用、伦理、教育、自然和社会科学、代理应用和其他领域。
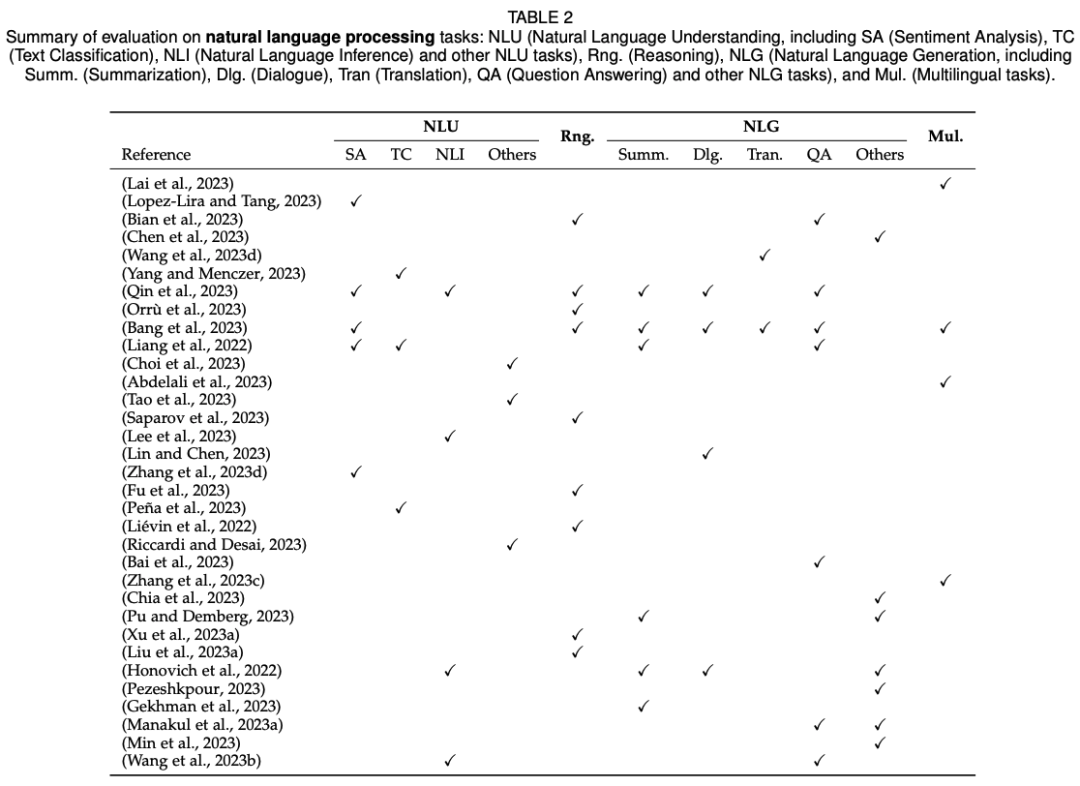
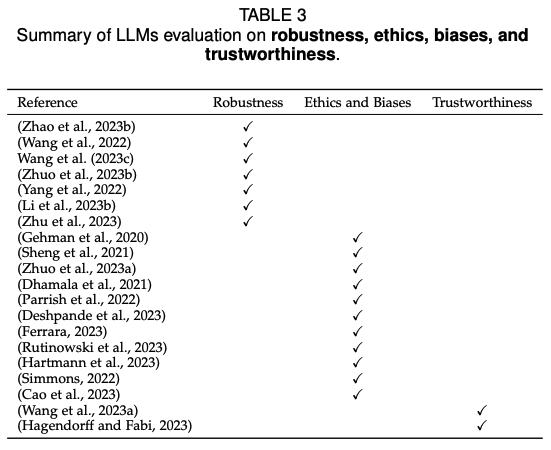
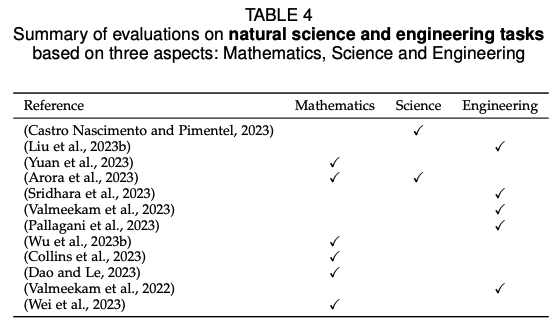
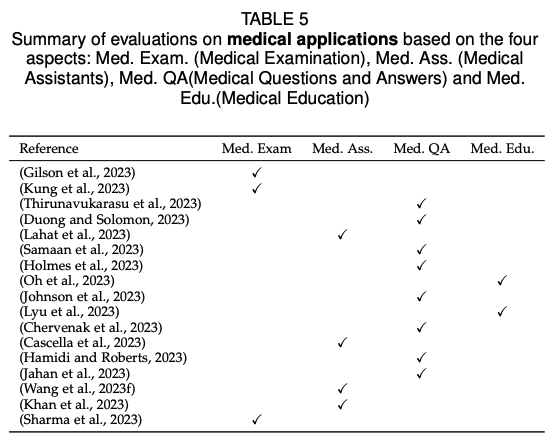
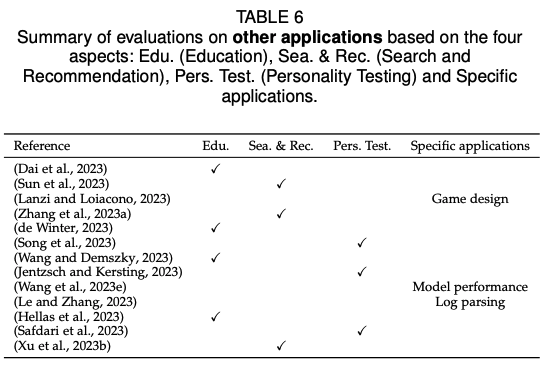
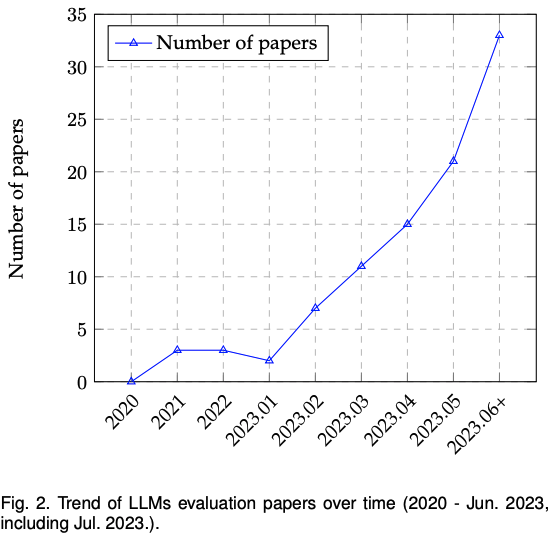
文章中提到了关于LLM在不同任务中成功和不成功的案例。
具体来说,在自然语言理解任务中,LLM在多项任务中表现出色。在文本生成任务中,LLM的生成质量有时甚至超过了人类提供的参考答案。然而,在法律任务中,LLM的零样本性能较差,存在多种问题,包括不完整的句子和单词、多个句子被无意义地合并以及更严重的错误,如不一致和虚构信息。
哪里评估
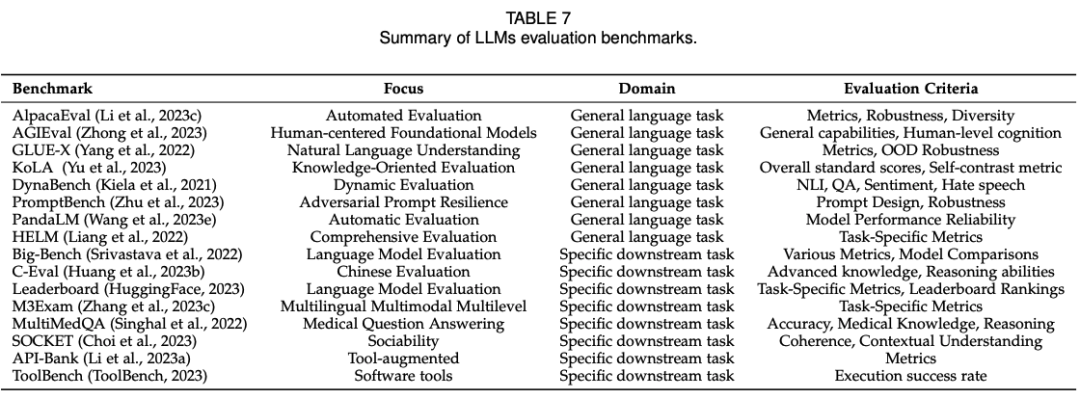
评估方法和基准在评估LLM的表现中发挥着关键作用。
评估方法可以帮助研究人员确定LLM在不同任务中的表现,并提供改进LLM的方向。基准测试可以提供一个公共的标准,使得不同的研究人员可以在相同的数据集上进行比较,从而更好地评估LLM的表现。因此,评估方法和基准测试都是评估LLM表现的重要组成部分。
怎么评估
主要包括自动评估和人工评估。

结论
本文的结论是,评估应该被视为更好地帮助开发更有效的LLM的关键学科。文章总结了LLM的评估方法和基准测试,并提供了LLM在不同任务中的成功和失败案例。此外,文章还指出了LLM评估面临的未来挑战。最后,本文还提供了一个开源的材料库,以帮助研究人员更好地评估LLM的表现能力。
论文:
A Survey on Evaluation of Large Language Models
地址:
https://arxiv.org/abs/2307.03109
进NLP群—>加入NLP交流群