视频关键帧AI化的逻辑是将视频切分成一帧帧的画面,然后使用SD绘画固定风格,最后统一在拼接在一起成为一个新的视频。
不管是Mov2Mov还是Multi Frame都能制作这种视频。但是这些操作起来比较麻烦,经过尝试处理较稳定的方法是可以通过img2im的batch_size,ControlNet,ADetailer进行控制修复以及批处理,这样操作会异常简单。
Stable Diffusion 方法
安装视频转帧插件,在你的SD目录下的scripts文件夹下创建convert.py文件并复制下面的代码到文件中。
import cv2
import gradio as gr
import os
from tqdm import tqdm
from modules import script_callbacks
def add_tab():
with gr.Blocks(analytics_enabled=False) as ui:
with gr.Row().style(equal_height=False):
with gr.Column(variant='panel'):
gr.HTML(value="<p>Extract frames from video</p>")
input_video = gr.Textbox(label="Input video path")
output_folder = gr.Textbox(label="Output frames folder path")
output_fps = gr.Slider(minimum=1, maximum=120, step=1, label="Save every N frame", value=1)
extract_frames_btn = gr.Button(label="Extract Frames", variant='primary')
with gr.Column(variant='panel'):
gr.HTML(value="<p>Merge frames to video</p>")
input_folder = gr.Textbox(label="Input frames folder path")
output_video = gr.Textbox(label="Output video path")
output_video_fps = gr.Slider(minimum=1, maximum=60, step=1, label="Video FPS", value=30)
merge_frames_btn = gr.Button(label="Merge Frames", variant='primary')
extract_frames_btn.click(
fn=extract_frames,
inputs=[
input_video,
output_folder,
output_fps
]
)
merge_frames_btn.click(
fn=merge_frames,
inputs=[
input_folder,
output_video,
output_video_fps
]
)
return [(ui, "视频<->帧", "vf_converter")]
def extract_frames(video_path: str, output_path: str, custom_fps=None):
"""从视频文件中提取帧并输出为png格式
Args:
video_path (str): 视频文件的路径
output_path (str): 输出帧的路径
custom_fps (int, optional): 自定义输出帧率(默认为None,表示与视频帧率相同)
Returns:
None
"""
cap = cv2.VideoCapture(video_path)
fps = int(cap.get(cv2.CAP_PROP_FPS))
custom_fps = int(custom_fps)
frame_count = 0
print(f"Extracting {
video_path} to {
output_path}...")
while True:
ret, frame = cap.read()
if not ret:
break
if custom_fps:
if frame_count % custom_fps == 0:
output_name = os.path.join(output_path, '{:06d}.png'.format(frame_count))
cv2.imwrite(output_name, frame)
else:
output_name = os.path.join(output_path, '{:06d}.png'.format(frame_count))
cv2.imwrite(output_name, frame)
frame_count += 1
cap.release()
print("Extract finished.")
def merge_frames(frames_path: str, output_path: str, fps=None):
"""将指定文件夹内的所有png图片按顺序合并为一个mp4视频文件
Args:
frames_path (str): 输入帧的路径(所有帧必须为png格式)
output_path (str): 输出视频的路径(需以.mp4为文件扩展名)
fps (int, optional): 输出视频的帧率(默认为None,表示与输入帧相同)
Returns:
None
"""
# 获取所有png图片
frames = [f for f in os.listdir(frames_path) if f.endswith('.png')]
img = cv2.imread(os.path.join(frames_path, frames[0]))
height, width, _ = img.shape
fps = fps or int(cv2.CAP_PROP_FPS)
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(output_path, fourcc, fps, (width, height))
print(f"Merging {
len(frames)} frames to video...")
for f in tqdm(frames):
img = cv2.imread(os.path.join(frames_path, f))
video_writer.write(img)
video_writer.release()
print("Merge finished")
script_callbacks.on_ui_tabs(add_tab)
准备好我们需要进行AI化处理的短视频,注意存放视频的路径中不要有中文。这里的视频尽量选择高清分辨率的,要不然最后合成出来的视频人物会变形。
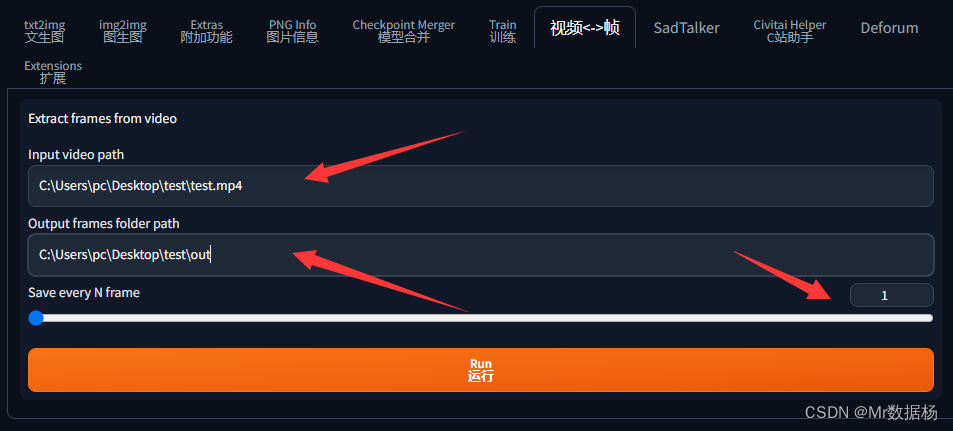
打开SD选择视频和帧互换选项卡,填写视频路径和转换帧保存图片的路径,下面的数字1表示每一帧都截取,表示如果60帧的视频1秒就是60张图。
点击运行在对应的文件夹下会出现保存每一帧的图片。

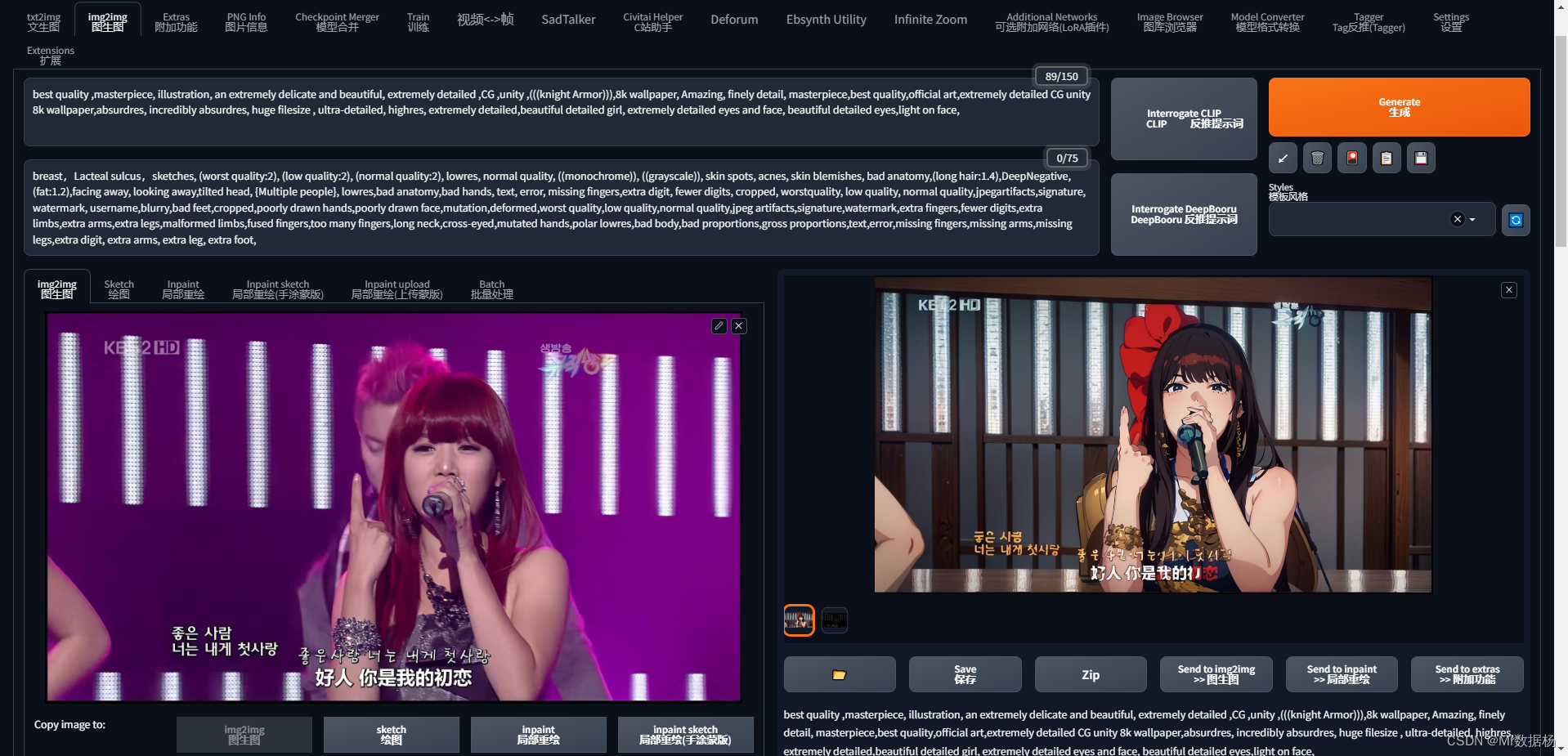
选择其中一张图片拖到img2img选项卡,根据自己喜好选择模型和输出对应的关键词。你会发现第一次处理出来的图像和原图没啥关系。
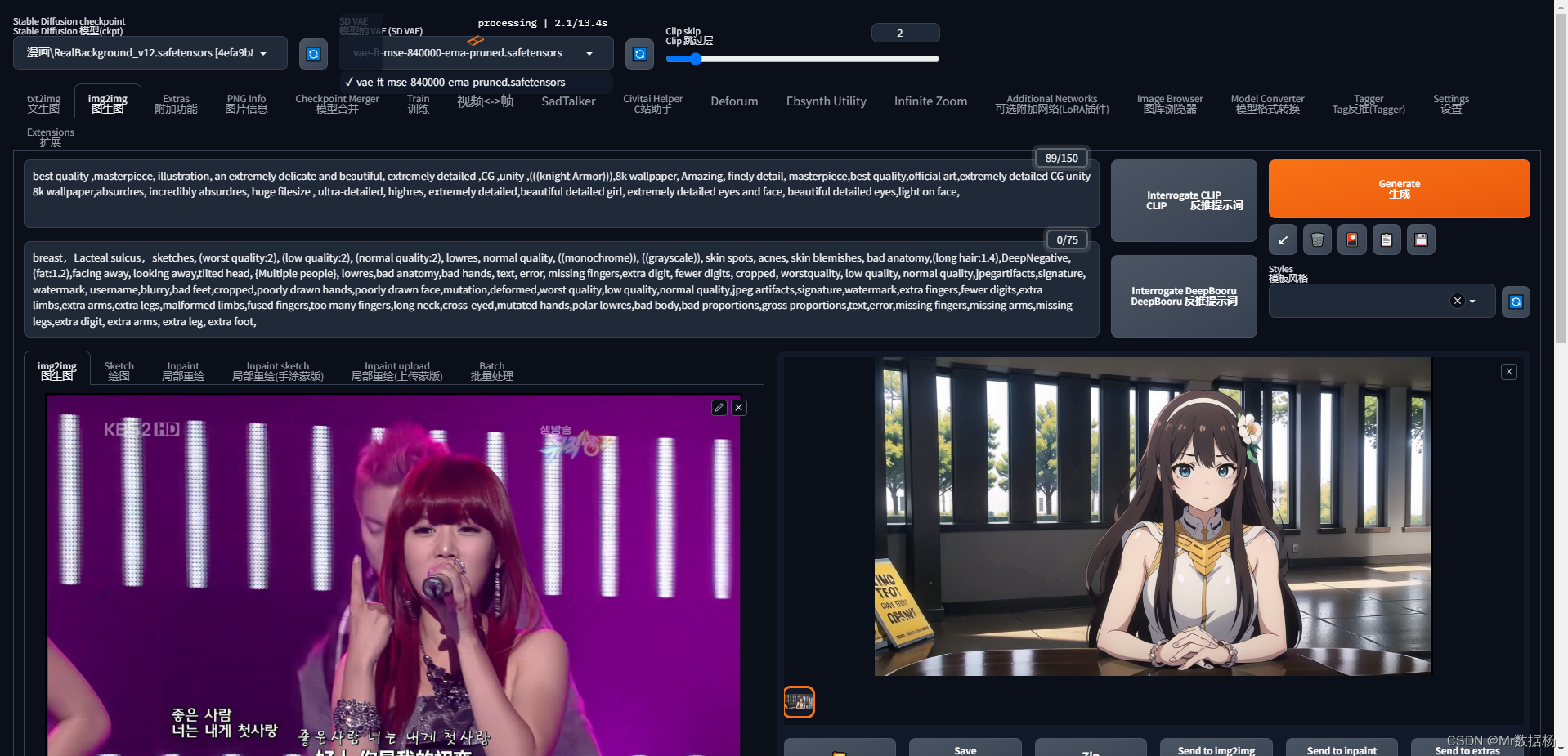
这是由于没有选择ControlNet进行控制,点击下方的ControlNet选项卡,设置Canny。
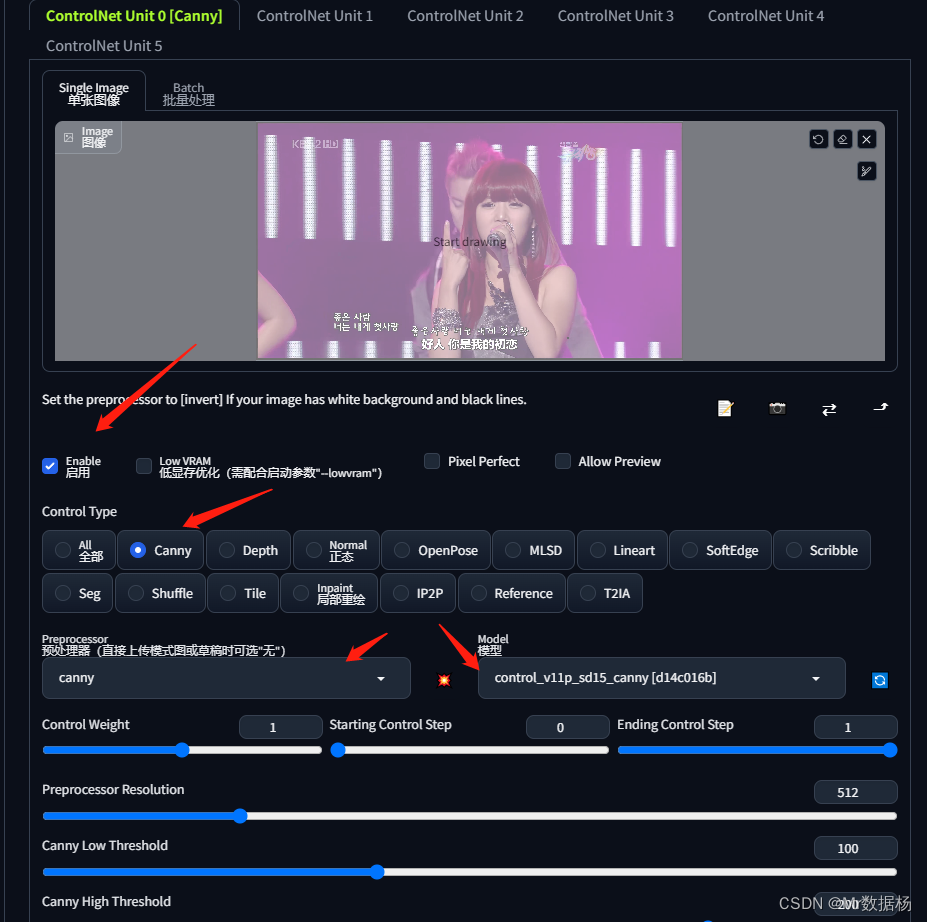
然后再次点击生成图片,你会发现图像变过来了。
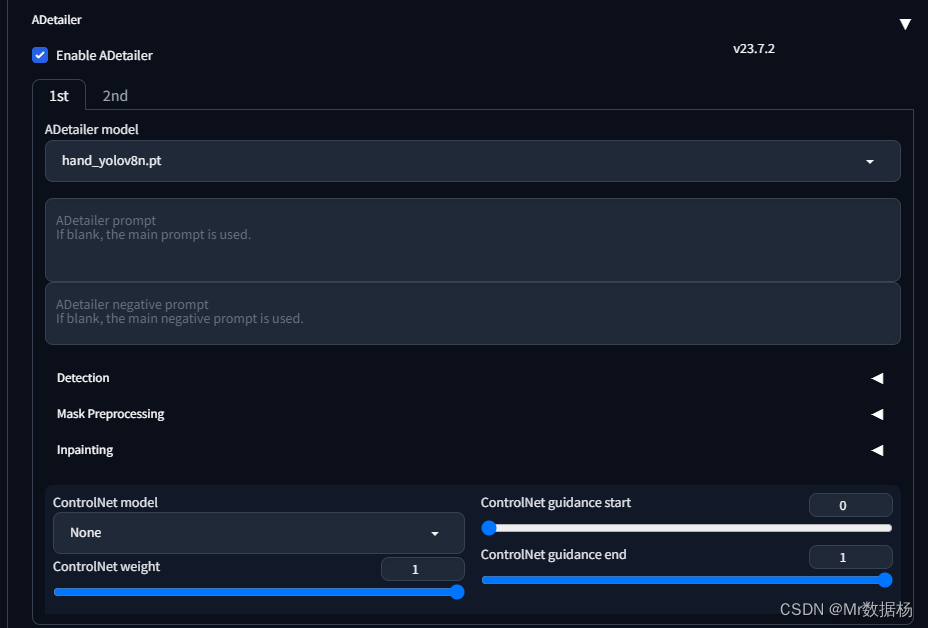
但是还会出现手脚崩坏的情况,需要在ADetailer中设置手脚修复功能。
设置好之后再次点击生成,来看看效果。
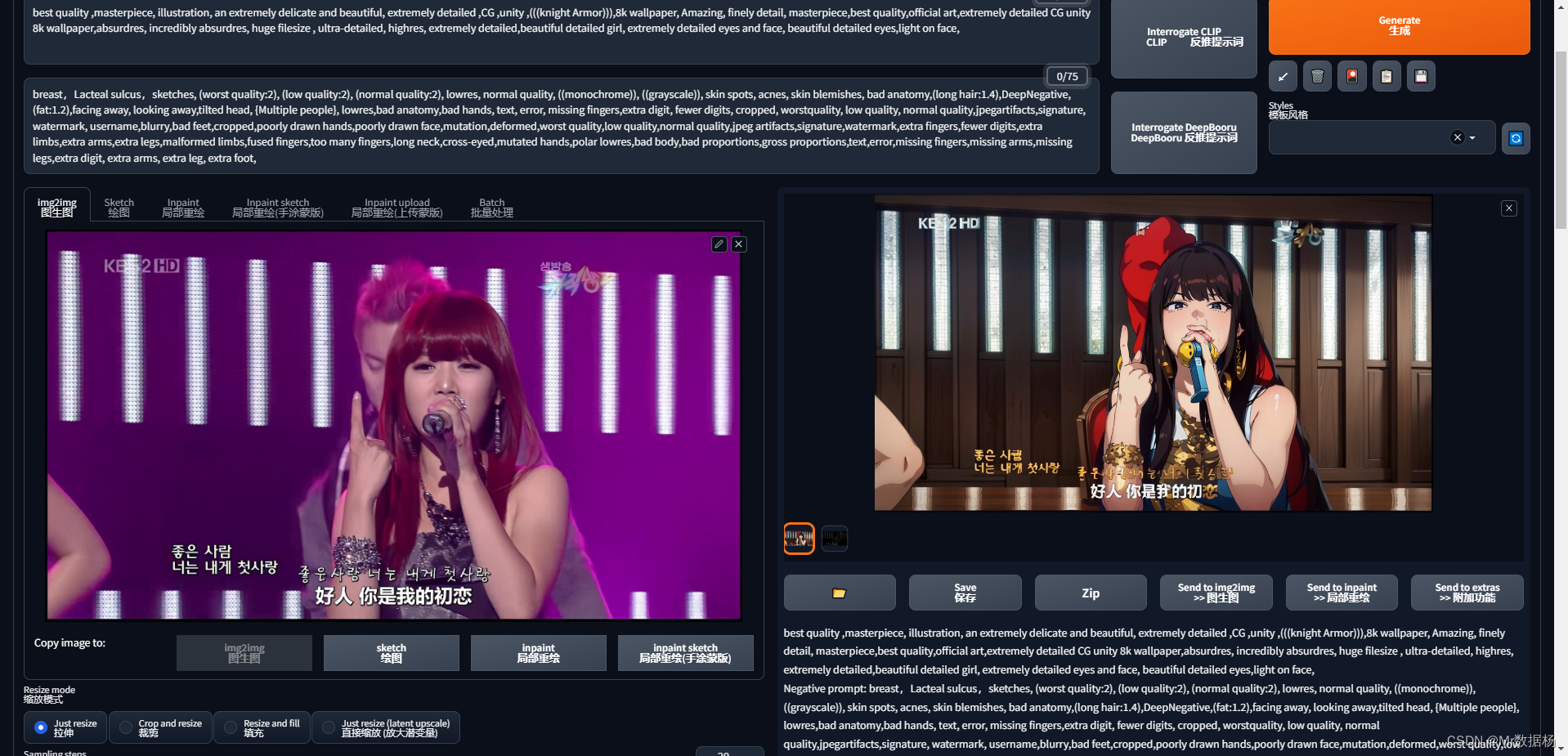
这里多生成几次记录下你满意的种子seed,记得将seed保存固定。
预处理这块就算完成了,接下来点击Batch批处理选项卡,这里要先把ControlNet中的图像叉掉。然后选择图片输入和输出路径。
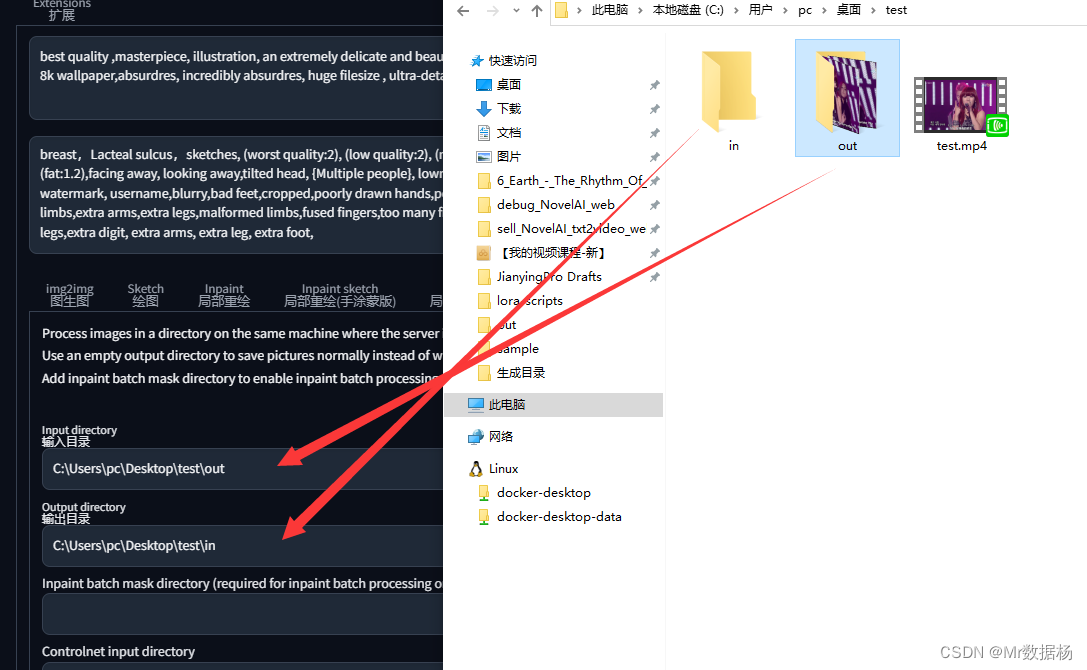
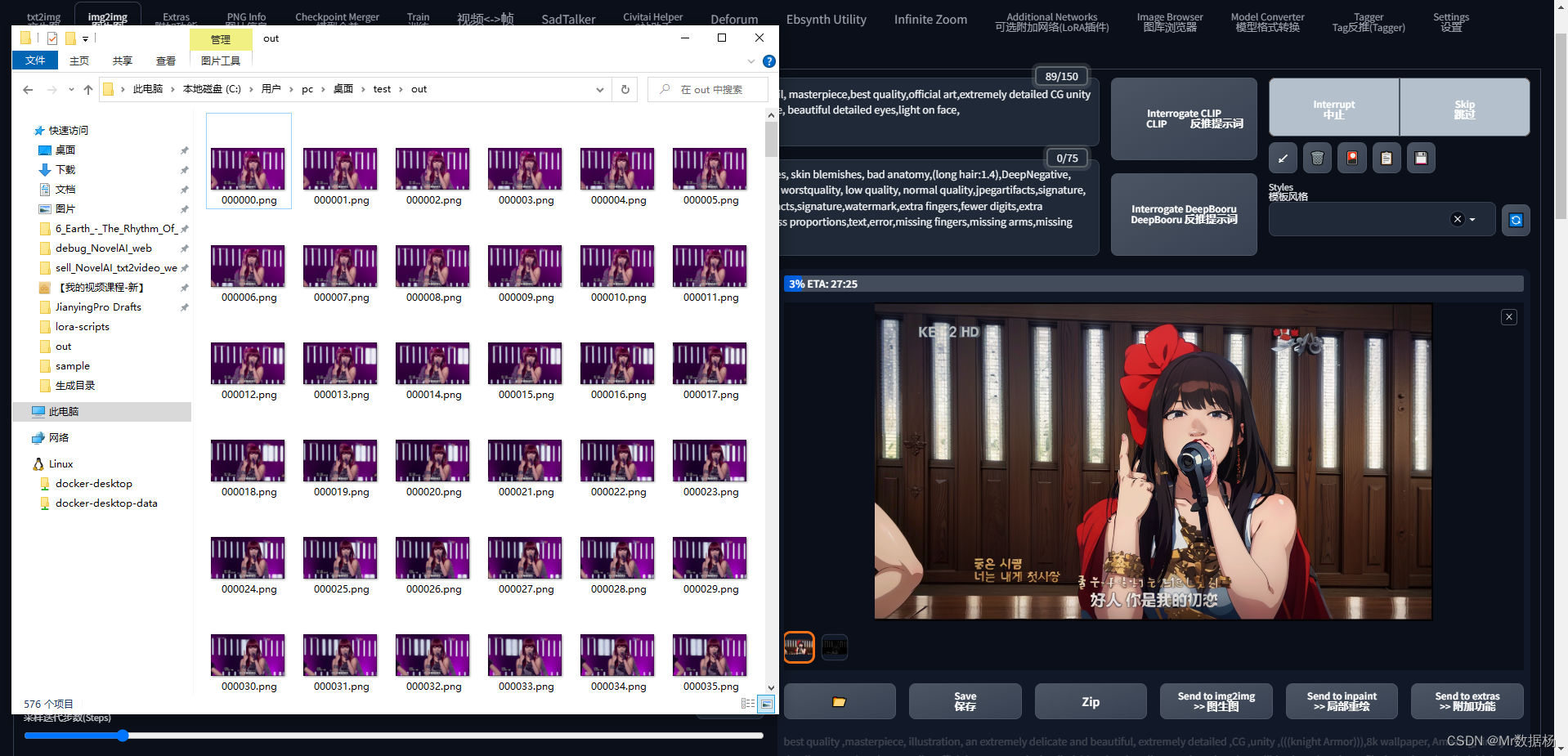
这么操作是将out文件夹下的图片批处理之后保存到in文件夹下,然后点击执行,开始一张张处理图像吧。这个过程对于显卡不好的人来说比较痛苦,我这576张图片处理需要30分钟。
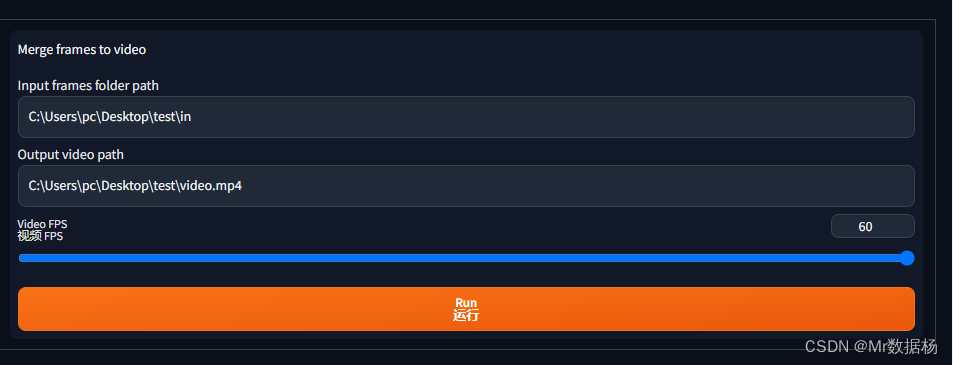
生成完所有图像后在in文件夹下删除后缀-1.png的轮廓图像。再回到视频帧互换选项卡设置需要拼接的图像目录,就是我们用SD绘画出来的图片文件夹,以及视频保存的目录,并且根据原有视频的帧数选择视频帧数。

点击运行之后会在test文件夹下生成一个video.mp4视频,就是我们要的结果了。
生成的视频会有闪烁的问题,后面会继续更新内容解决该问题。
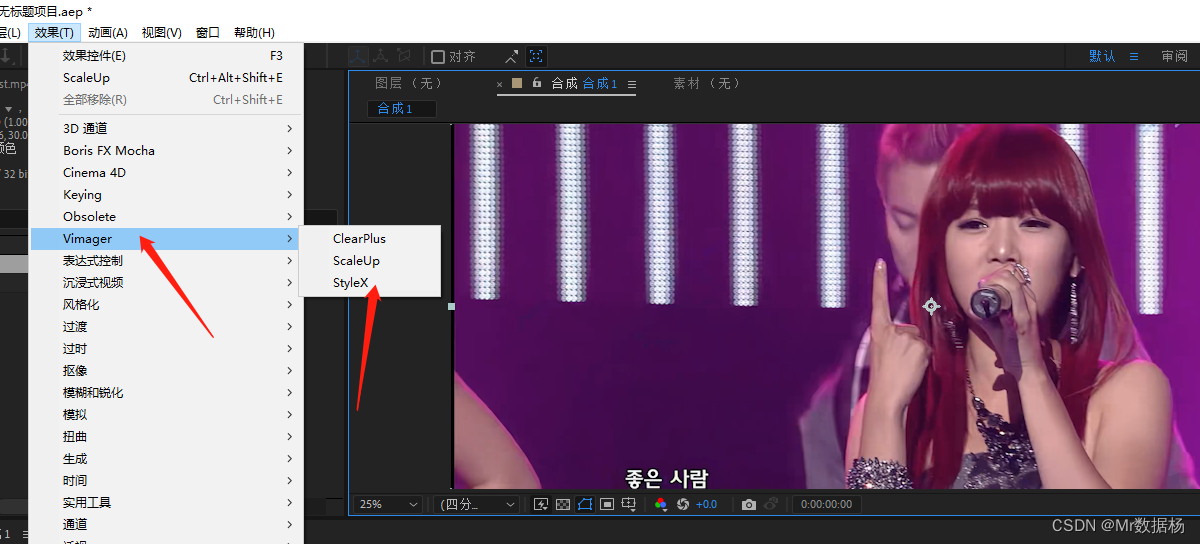
After Effects 方法
使用AE转换需要下载StyleX插件。
然后设置参数进行预览。
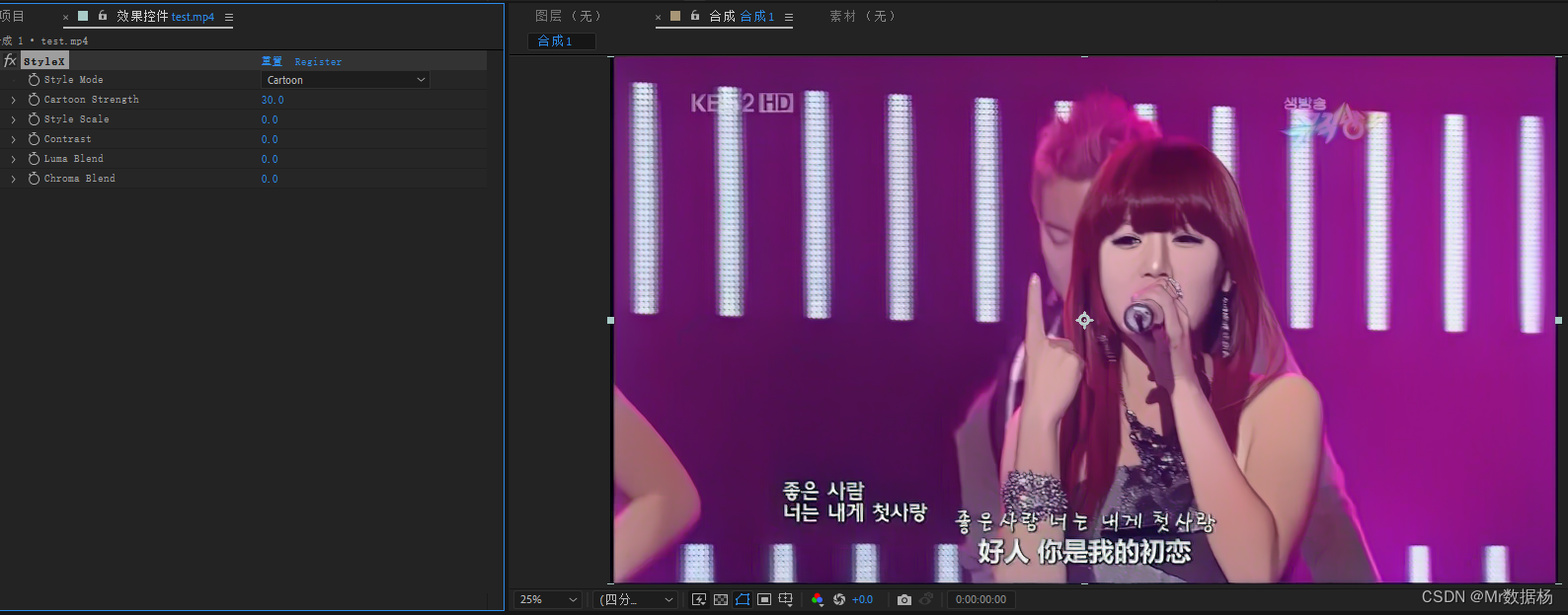
整体效果其实和SD没有办法比,可以理解为用了简单的滤镜进行处理而已。最后添加到渲染队列输出即可。
Ebsynth 方法
Ebsynth主要可以处理SD生成动漫视频的画面闪烁的问题。
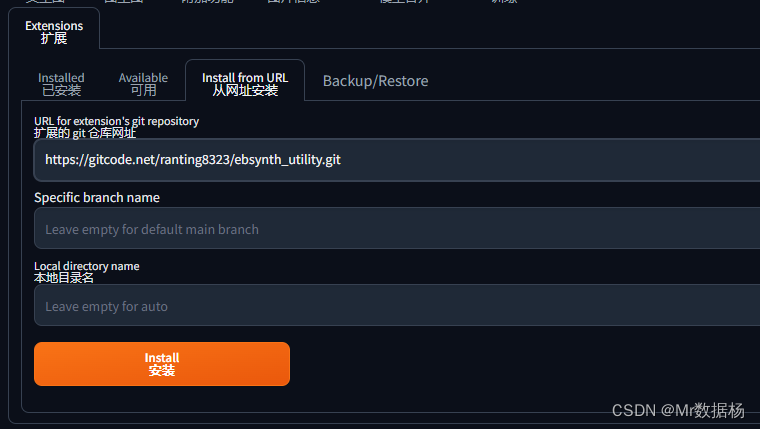
git 安装地址 https://gitcode.net/ranting8323/ebsynth_utility.git
在SD扩展中输入该网址进行安装即可。
安装完成后重启SD会在出现Ebsynth Utility选项卡。
进入Ebsynth官网根据你的系统下载安装程序。

然后在你的扩展目录下打开。
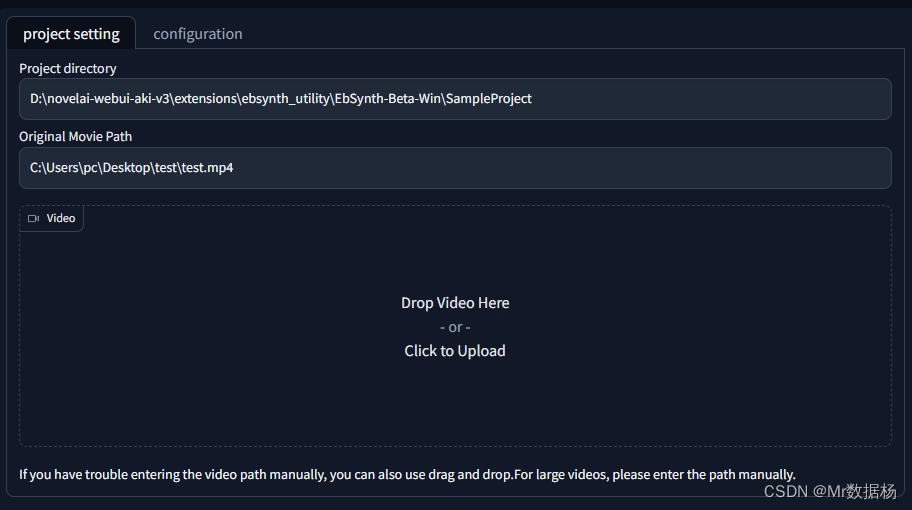
和SD处理方法一样,先要将视频按帧进行批量转换,首先拖入视频,然后指定提取关键帧的目录。视频的目录也可以手动输入。
在configuration选择stage1。如果想要保持原视频尺寸默认选在-1即可。其他的不用操作,然后点击生成。
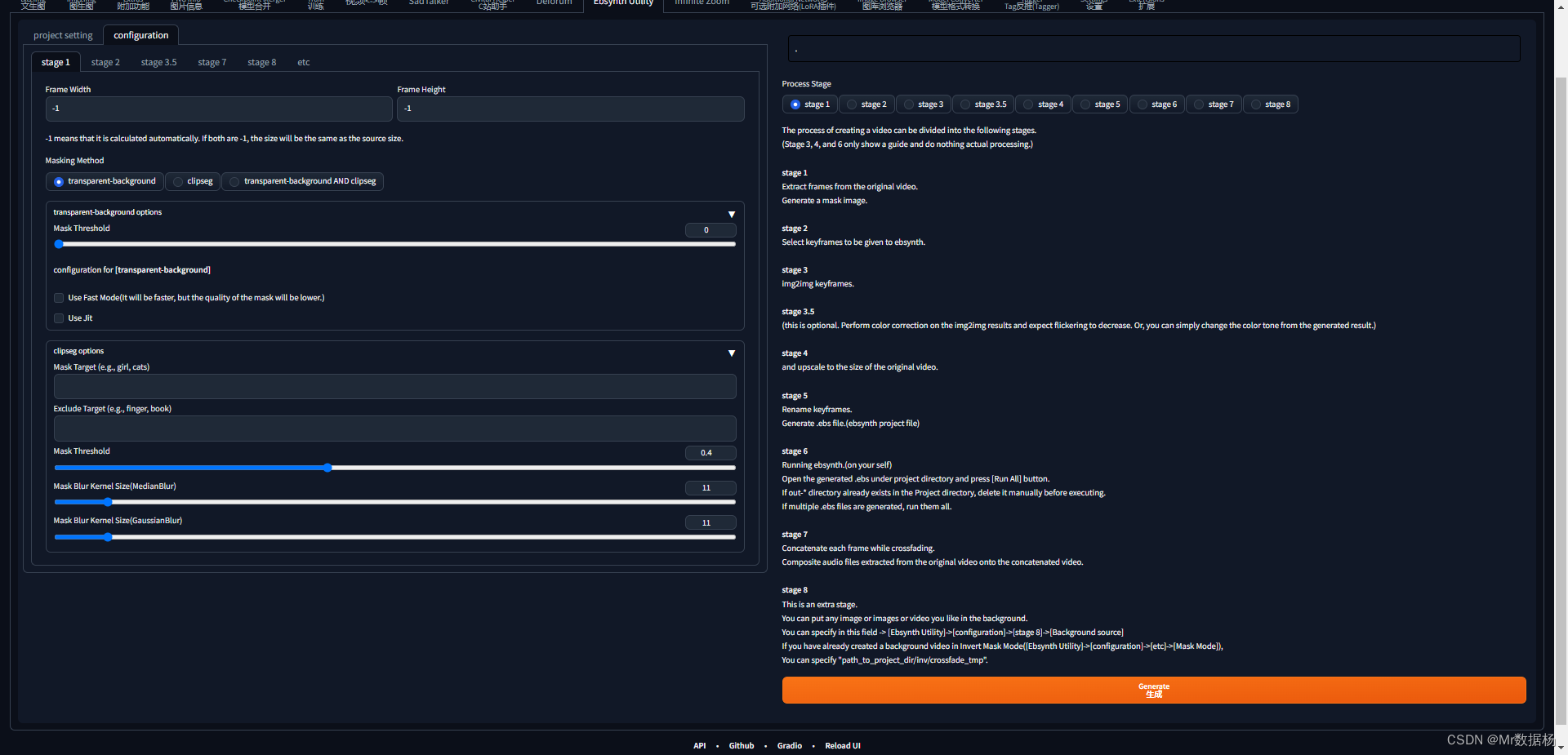
在项目文件夹下自动创建video_frame文件夹,并将按帧的生成图片保存到该文件夹下,效果和之前视频转帧效果相同。
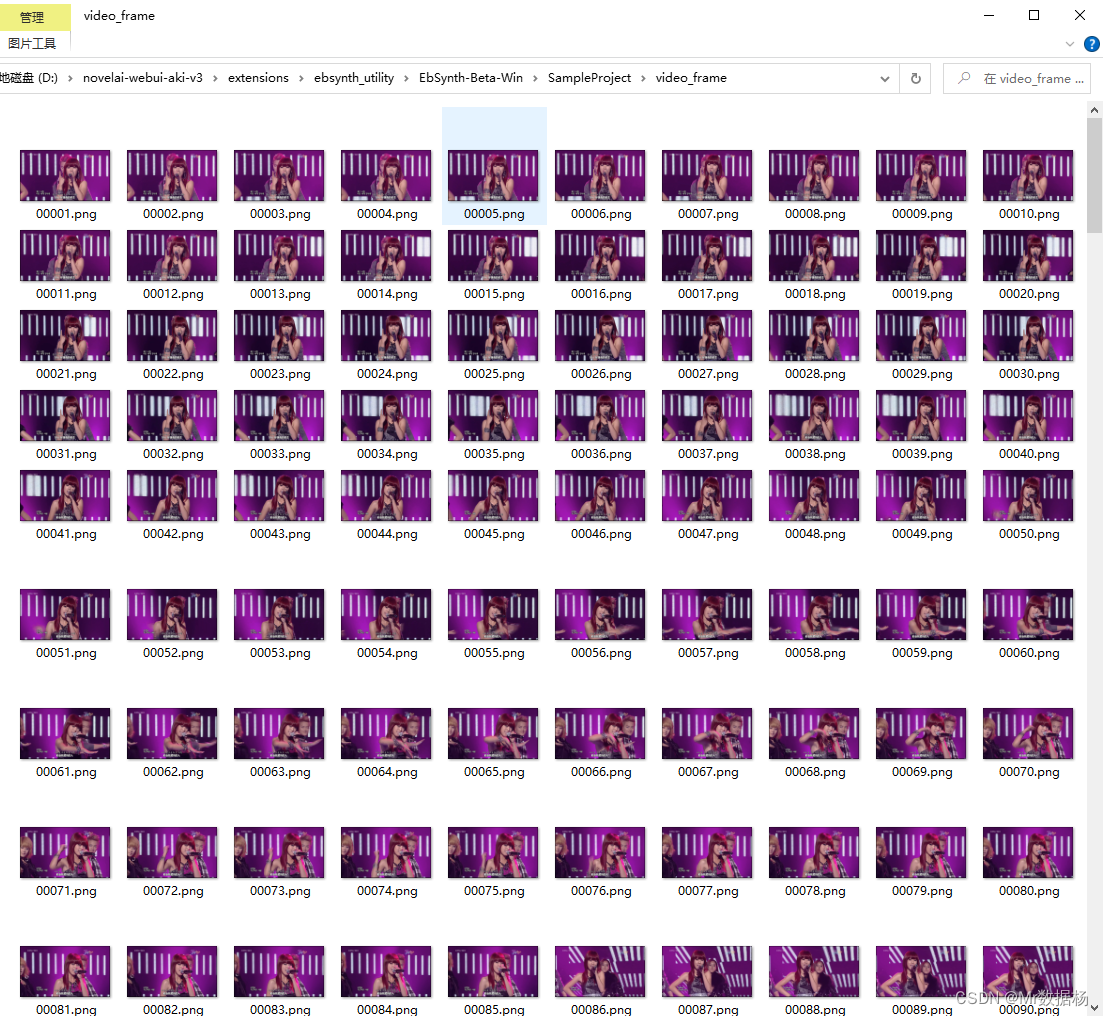
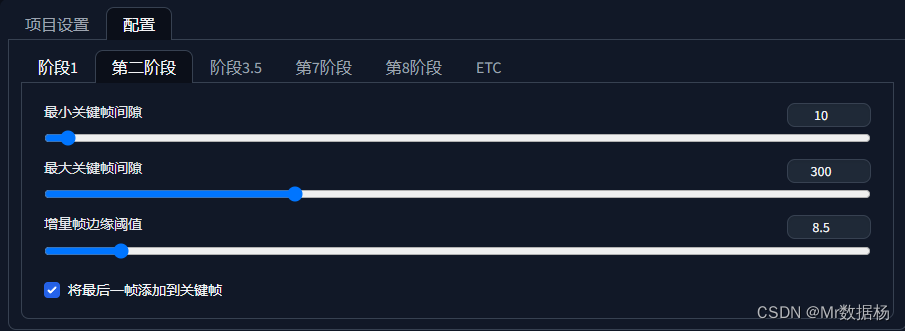
在configuration选择stage2。这步是根据已经提取的关键帧按照间隔提取到Ebsynth中,关键帧间隔就是按照帧提取间隔,然后点击生成。
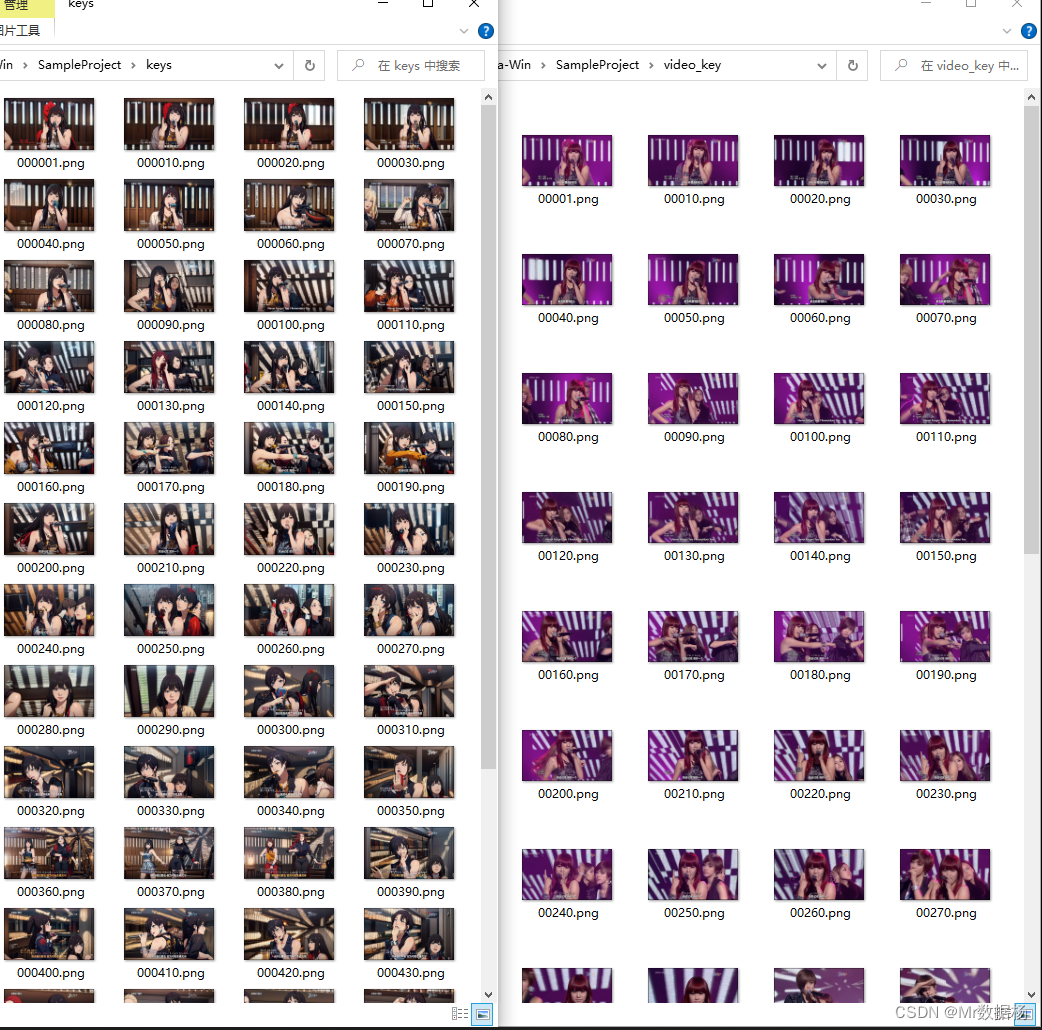
按照关键帧设置的配置提取关键帧Key到video_key中。

回到SD绘画中的img2img中,将这些图片批处理重绘和Stable Diffusion方法一样。生成完图像保存在img2img_key中。
在configuration选择stage3.5中提取mask蒙版,也可以不提取。
在configuration选择stage4中使用Extras将图片进行放大处理也可以不处理。
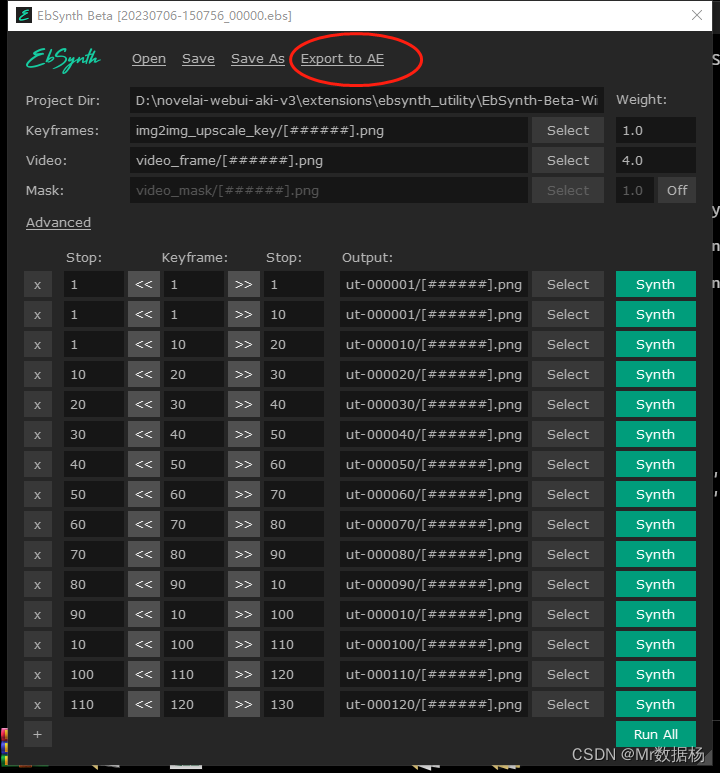
在configuration选择stage5将关键帧处理好的图片文件放到img2img_upscale_key中,如果该文件夹不存在则手动创建。然后执行生成会生成对应 .ebs文件。
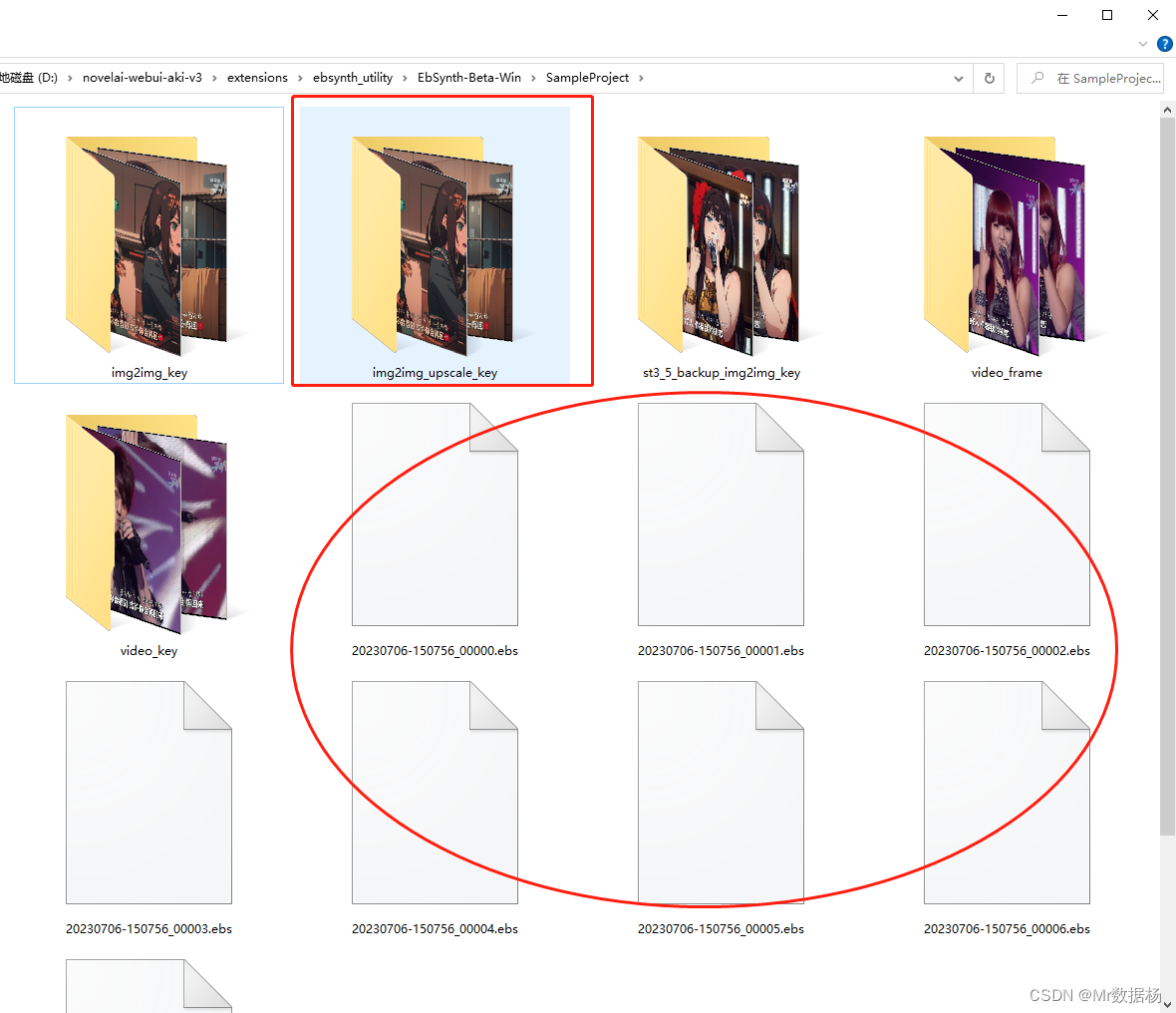
在configuration选择stage6打开EbSynth.exe依次将对应 .ebs文件拖入。关闭蒙版on,点击Run All,等待关键帧生成。
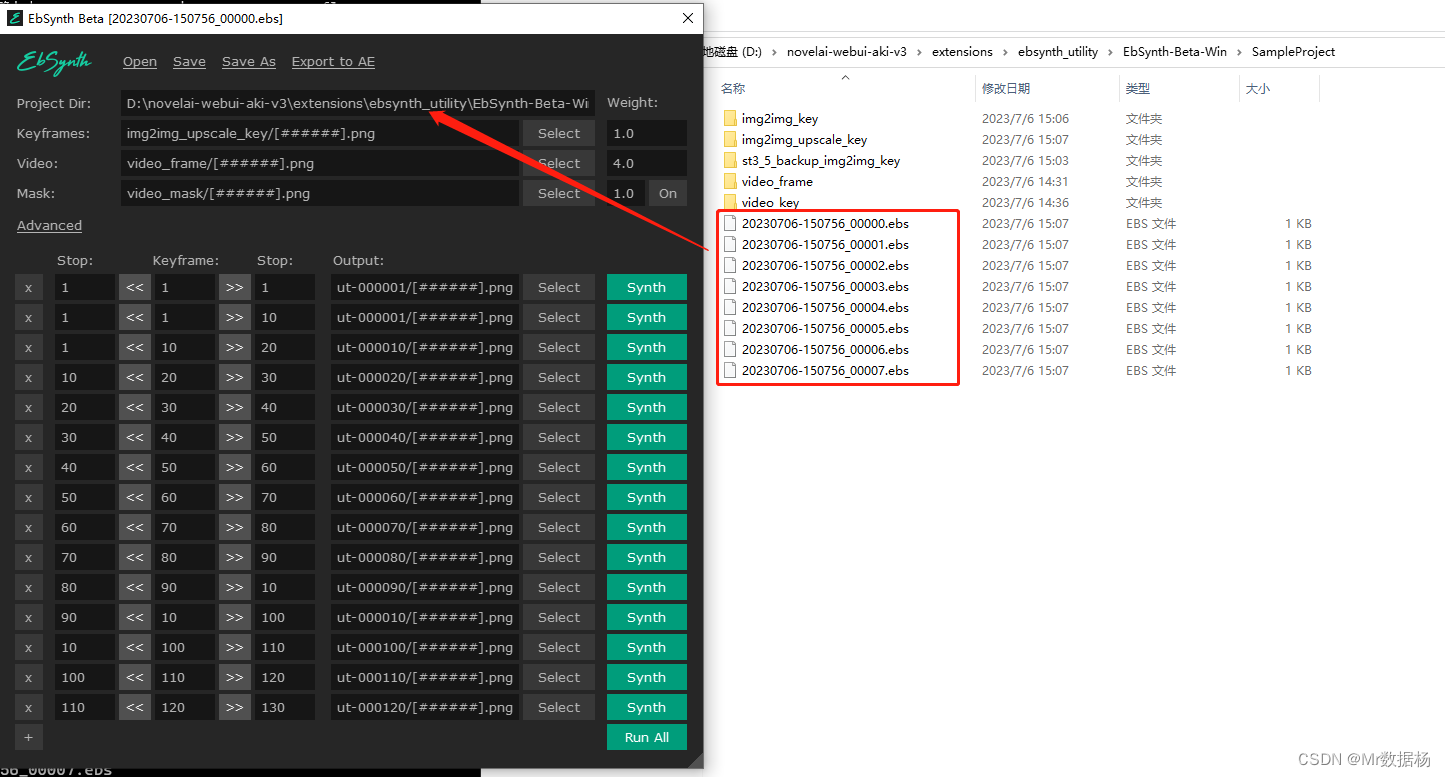
会生成关键帧的处理过的批处理图片。
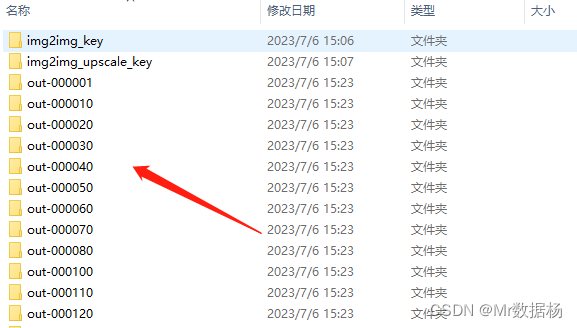
批处理之后点击Export to AE进行合成即可。