背景
从AI可以画图到现在各家都在功课的连续性内容的输出,正在AI画图进入到大众圈其实也不过1年左右时间。对于单图的研究已经逐渐完善,单图理论上讲,只要你能按要求做promt的设计出图率应该是比较高的。但是对于要生成连续的图或者要生成连续的视频,模型的能力似乎强差人意。
既然是产图的工具,为何单图能够生成的很好,连续的图为何就生成不好。为何就不能跟漫画师一样生成连续的可以在视频播放的动漫视频呢?动漫师不也是一张一张的画图嘛,似乎这个问题也可以归结到做图啊。
要回答上面的几个问题,我们就不得不来看看单图、连续图、视频这几种表达之间的差异。以及在技术上他们之间的实现思路,如此我们才能通过差异看到问题在哪,也才能提出一些可能的解决方案。
单图
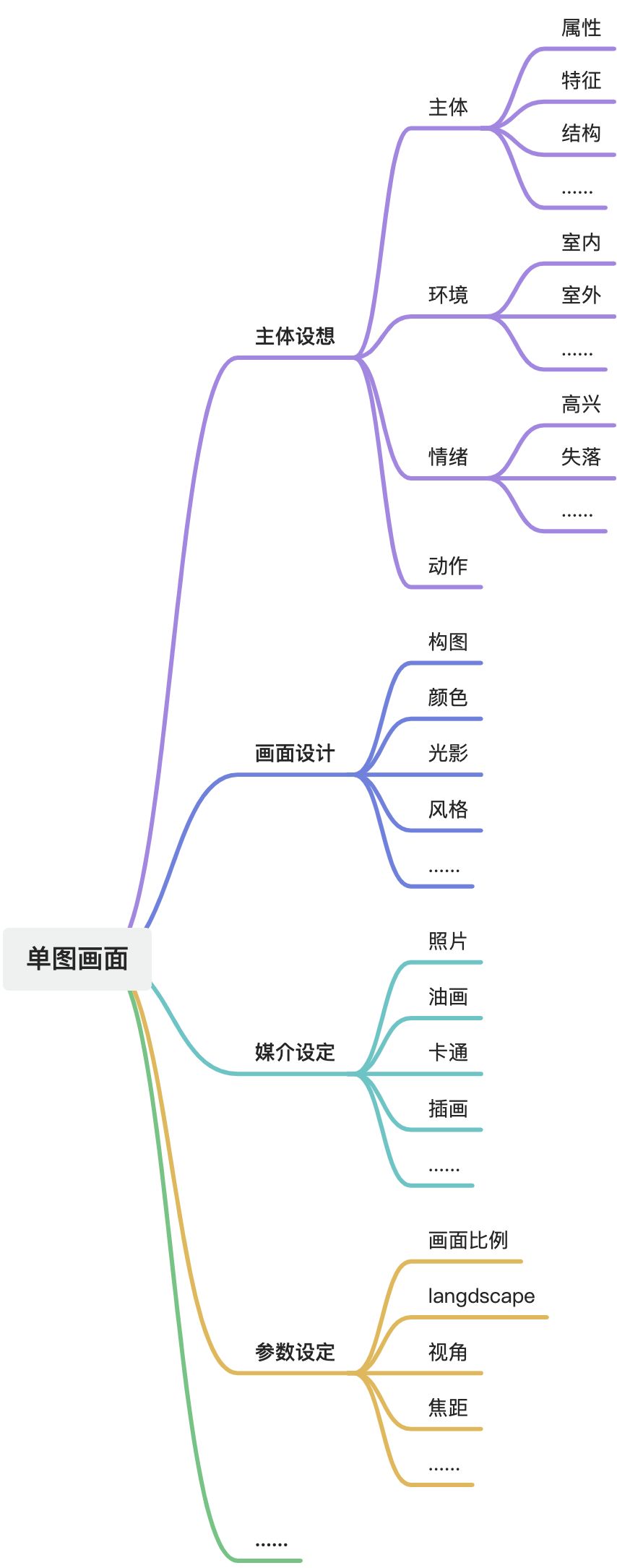
单图逻辑上来讲就是一个静态的画面,要解决的问题就是突出主体:
1.主体的形象(服饰、装饰、色彩搭配)、主体传递的情绪(动作、表情)、主体表达的意图
2.为了承托这些主体要传达的意图,需要安排好主体出场的场景(可以简单理解为背景)
3.场景包括了环境、氛围、静物、道具
4.以及如何把上面的这些元素按层次的构图(层次结构、视角、角度、光影...)
5.用什么样的画风呈现,这个其实包括作画者世界观和作画硬件设备约束(画风、拍摄设备、光圈焦距 ...)
单图的衍生就是长图
单图受空间范围的约束,当在如此小范围不足以表示作者要表达的事物和意图时候,出现了单图的工程扩展——长图。比如“富春山居”、“清明上河图”、敦煌石窟壁画就是这类的典范,在现代的媒体艺术呈现是否也有如此之物,有的比如抖音里面的读故事配的视频图、动漫书籍都是。这类表现方式的特点是,从单一维度线性的来扩展呈现更多内容。这类的呈现方式最好的应该是在纸上,或者是引导性的线性扩展的画面(长廊、长廊状的lED屏)。反正单维度线性扩展的呈现载体比较适合这种表达方式。
这种方式的呈现已经有一定的连续性在里面,虽然是线性维度的。
1.确定长图需要的场景数、里面需要出现的角色、需要的道具
2.把关键的场景作为keyframe画出来,这里面keyframe的绘制就会用到单图的所有技能
3.把前后keyframe做渐变过渡画面构思,逐步的补画出来(微软最近几年把中国古画,补全用的就是这个思路)
分格漫画
分格漫画应该算是一种非连续的二维呈现方式。什么叫非连续的二维呈现呢,单图其实就是直接让你在一次睁眼闭眼过程可以把整张图信息完全摄入,长图是需要你做线性的移动,分多次的睁眼闭眼才能把信息摄入;而分格动漫,其实是需要上下、甚至可能斜向移动摄入设备眼睛才能完成信息摄入的过程,但是这个移动的状态位是有限的几个位置,所以叫非连续的二维呈现。
这种表达方式最难的地方在于,如何根据把要表达的内容选择合适的二维状态位来表现。
1.几格漫画,确定漫画布局
2.确定漫画内容
连续分格漫画书
连续漫画,最难地方在于漫画呈现分镜一致性,角色一致性和故事一致性。单张分镜漫画如果有比较好的效果,也就是对于要表达的内容单张漫画已经可以匹配比较好的分镜非连续状态来表达呈现了。对于连续输出多张漫画最难就在于,保持角色一致性和故事描述的前后一致性。
为什么角色一致性和前后故事描述呈现一致性很难呢,为什么人可以做到呢。根本原因在于现在的画图工具是没有记忆力和预测力的,也就是说它是无状态的在画。根本不会去记录前面它画了什么,也就根本不可能考虑如何基于前面画的内容思考现在的输入信息该如何表达,该如何的接续保持一致性。而人在做这些工作时候,是有记忆的基于前面的图的画面对输入的文本信息在构思如何接续画面,让这个故事里面需要出现的主角谁出场,这个主角他的外貌装饰是如何的表情动作该如何。
那如果要保持内容的一致性,是否给现在的无状态无记忆的做图AI加上状态、加上记忆就能画出连续的故事画面。理论上讲是这样的,但是更大的问题在于:如何加入记忆、如何加入状态;加入什么记忆、加入什么状态;在哪加入记忆、在哪加入状态。
可以讨论下加记忆和状态的两种方法:内存、外存,自状态机、外挂时钟状态器;其实说白了就是外挂一个plugin来实现这个,还是模型自己把这部分能力纳入进来。
如果是外挂记忆器就是,把故事里面出现的:角色、场景、道具、静物、动物、装饰这些相对固定的东西抽出来,作为物料存储起来,根据故事画面需要把这些物料调出来装饰构建画面,装饰完根据情节需要做一些变化就行。
如果是外观状态器,就是把这些状态跳转的规则或者是跳转的表存下来(这个规则获得可以通过关联学习得到,比如FP-TREE),然后根据前面一些帧的状态信息(这个粒度可根据需要控制)来预测下一个状态为何。
如果是模型把这部分能力给纳入进来,其实也很简单就是在给现在的画图模型加上时间序列(也就是在画单图之上加上一层图和图之间序列关系),这样其实就把状态和记忆力问题一起解决掉了。现在很多文本生成视频的思路都是如此。这种结构的设计已经有了,难点在于如何设计学习任务让模型记住要记住的东西,并在需要表现地方表现,知道状态该如何跳转。从目前的文本生成视频模型效果来看,在单具体任务上有些效果,但是在通用域看效果不太好。
视频生成
我们可以一起看看视频这种表现形式和前面讲的单图、分格漫画的差异在哪。视频的技术实现是通过刷帧来表现画面的变化。啥意思呢?意思就是前面的两种表现方式是图画出来了它也就在哪了,你只要线性的回拉就能看到历史了。但是视频的实现是:把前面的一帧画面毁了然后重画一帧新的画面;为了保证画面观感连续,做的一个事就是让前后画面的切换感觉合理:
1.包括针对前面画面增量改动画面,利用脑子残留记忆+增量画面脑补动作
2.利用各种人类感觉合理的镜头切换技巧,来实现大画面变化,或者是两帧画面巨变变得您能合理接受
如此看来视频画面前后两帧的画面上任何点都是可以变化的,也就是说视频变化应该是二维连续状态预测问题。所以视频生成理论要学的是两类:
1.画面增量变化的分布(画面大小是确定的,要预测的是根据历史帧画面里的像素哪些是要变的,他们符合什么规律)
2.画面切换如何符合人类感官(预测画面状态切换可能的合理状态,可以带约束:比如驱动视频、驱动动作骨架、驱动文本...)
方案介绍
单图到长图
单图
长图
故事物料
| 场景 |
角色—人物 |
角色-动物 |
静物 |
道具 |
|
| 内容 |
场景1—生物实验室 场景2-硅谷11号酒店 |
男主1—未来科学家 女主1—黑暗交际花 |
猫1-萌萌间谍猫 狗1-科学家守卫 |
实验室试剂架 实验室五颜六色液体 酒店吧台 酒店酒架 |
科幻的机械臂 监听手机 |
| 描述 |
干净整洁实验室,里面摆满了各种仪器设备,五颜六色的掩体在管道里缓慢流动,科幻感十足的生物仪器 |
高高的、秃头、polo衫、长长的脸、严肃、带着金色眼镜、黑色工装裤、强壮的身体 |
两眼放光、毛茸茸的,胖乎乎的,大大的脸,灵活的身体 |
横轴单图生成的流程线,纵轴故事线(用关键帧表示)。
| 故事原文 |
故事里出现哪些场景 |
故事里出现哪些主角 |
主角在场景中动作表情画面位置 |
故事出现哪些静物 |
静物在场景位置 |
故事出现哪些道具 |
道具在场景位置 |
storyboard描述 |
图片后续处理 |
|
| 关键帧1 |
生物实验室 |
男主1 |
男子在实验台前摇动仪器,认真的做实验,表情严肃,在画面正中间 |
试剂架 五颜六色的液体在实验仪器里流动 |
在场景左上部分 |
机械手臂 |
在画面右下角,靠近男主 |
增删改 |
||
| 关键帧2 |
||||||||||
| 关键帧3 |
关键帧的画面如何生成:
A:生成底稿图,然后手动把物料仓中物料替换底稿图,把物料摆到合适位置后用sd重新对摆好图重新生成(或者脚本自动)
1.把上面的物料根据,场景描述+静物描述+主角描述+道具描述+位置关系描述生成画面
2.按底稿图图层关系,利用物料仓库中场景图、角色(头)、静物、道具摆出底稿图样子
3.把摆好的图重新生成
B:场景图+inpaint重绘+摆骨垫图换角色
1.判断这个帧该选用,物料场景中的哪个场景
2.根据静物在场景中摆放位置描述,和需要哪个静物,把静物在场景位置inpaint+静物controlnet
3.对图重绘
关键帧之间的画面如何渐变过渡:
A.关键帧之间,生成过度的文本描述5-10段,outpaint插帧补图
B.Text-to-Image Model Editing,利用前后帧文本描述,利用模型生成渐变图(这个模型现在只能文本控制,改造下应该可以支持文本+图+每步更多控制条件)

直接训练带记忆状态的模型,这种思路解决更彻底。
分格漫画到多页漫画

这个思路和连续图一样。

动图到视频生成
这个现在基本只能靠模型来解决。但是这个其实有个问题:
1.模型需要如何设计学习任务
2.如何给模型引入更多的控制因素,让模型可控性更强
3.给模型引入哪些控制因素
小结
文章介绍了几种连续内容生成的差异,同时介绍了如果要稳定生成连续内容的可能的几种解决思路。提出来两个抽象框架:外挂记忆、序列化模型两种可能的解决框架和他们现在个字问题。
1.现在的AI做图模型是无状态的生成思路,所以多单图的生成支持较好
2.现在单图生成,主流模型是基于latent model方式来生成,并且训练任务更多是建模在摄影框架上,所以对人类自然描述支持不够
3.长图的生成思路,是最容易想到的线性拓展思路,只要解决好画之间角色和场景一致,理论讲这个是可以通过外挂记忆力系统+工程技巧方式给予现在无状态的AI生成思路解决的问题;个人判断这个问题应该会很快出效果
4.对于视频生成,根本原因在于:连续画面帧变化分布学习,这个基本只能通过建模方式来解决,并且理论讲建模方式解决会比长图、连续动漫效果更好,因为视频画面是连续的,而长图和连续动漫是非连续的。