目录
中间件的用途

中间件技术
属于可复用软件的范畴

中间件的特点

中间件的十大优越性

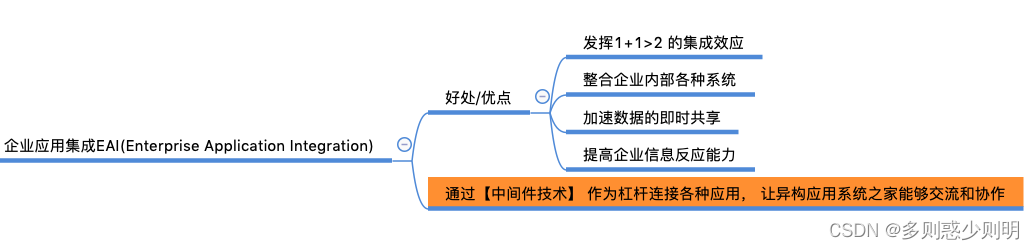
企业应用集成

轻量级架构

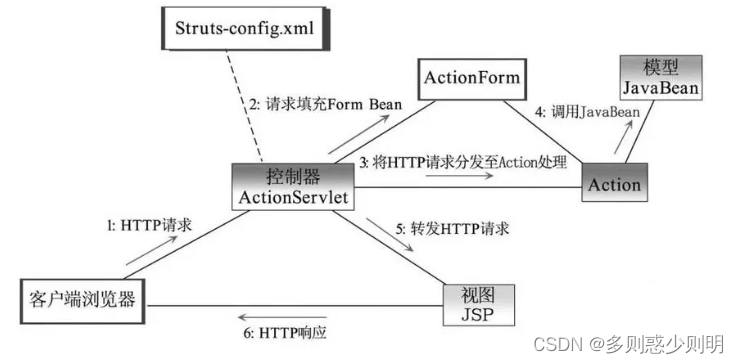
Struts框架

工作流程:
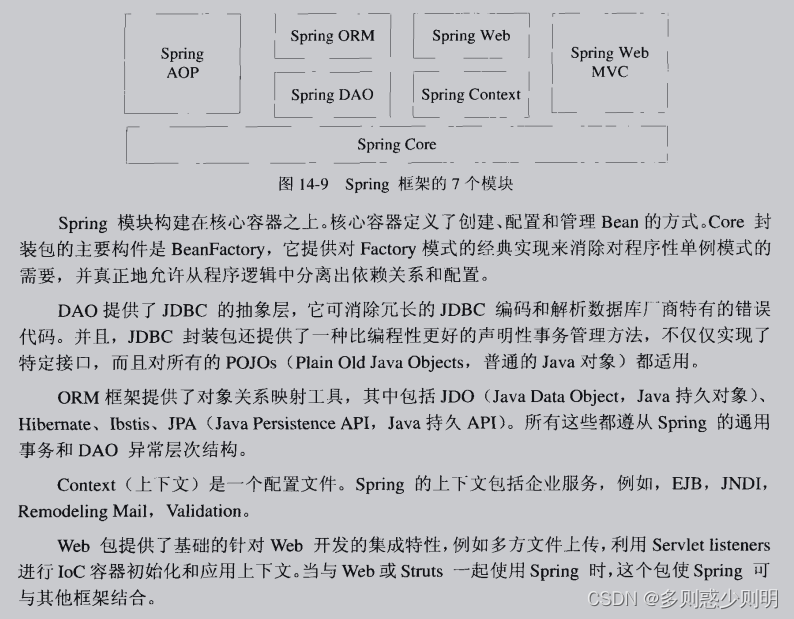
spring
企业级应用程序一站式解决方案
Hibernate
让开发摆脱麻烦的JDBC代码, 将精力更多集中在编写数据表示和 业务逻辑上
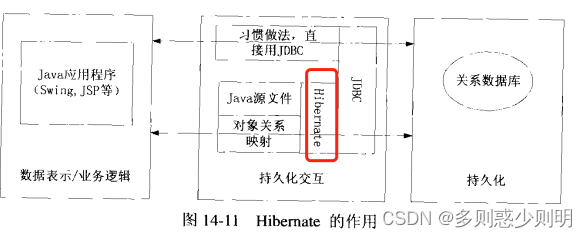
用struts, spring,hibernate构造轻量级WEB框架:

实际项目举例
产品逻辑大图
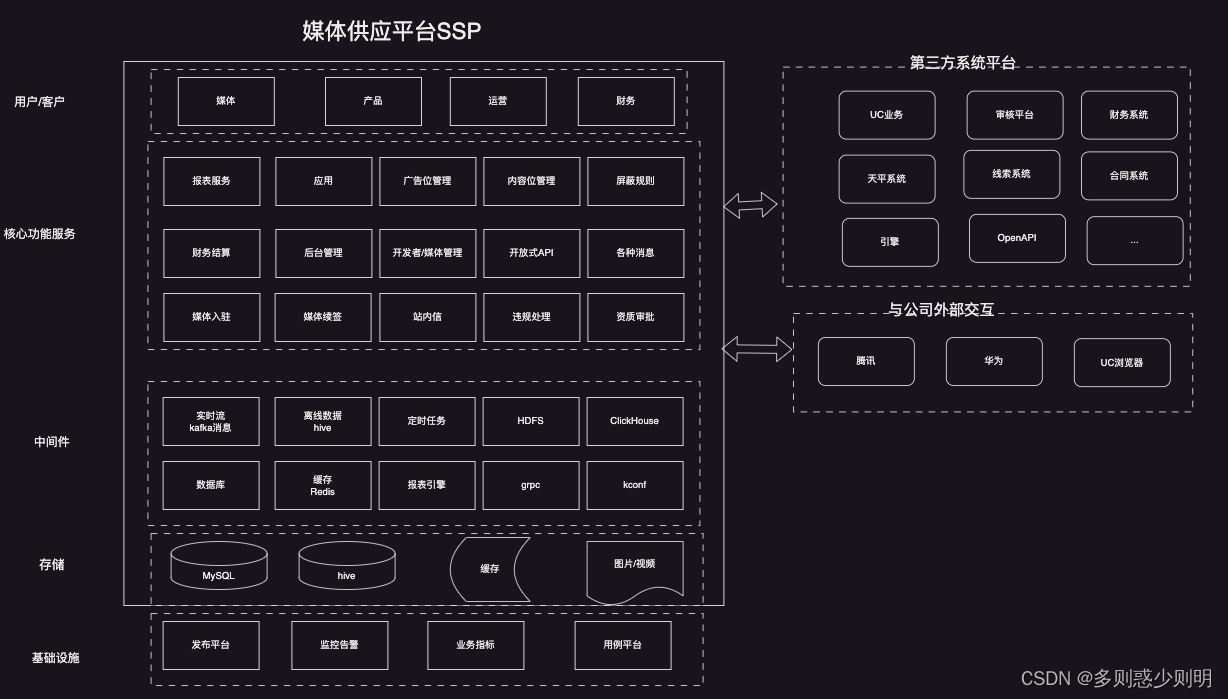
核心功能服务: 由于涉及的功能模块众多,150+http(s)接口给页面提供数据
中间件技术: 整体平台依赖的中间件技术众多, 分别包括:
- kafka消息。 使用kafka消息实现与第三方系统的异步交互,包括通过kafka消息,将财务结算数据同步给财务系统,将广告数据同步给第三方基础平台系统等等;
- hive数据。 大数据处理业务中,存在多种大数据处理场景,如 从第三方hive表中拿数据,然后进行加工,清洗,处理等,或者将从MySQL,缓存,hive,第三方接口等多处数据源拿来的数据经过统一处理,然后写入hive表中供后续业务逻辑使用。 hive表数据处理通常采用离线数据处理方式, 如 定时任务 方式处理, 每小时、每2小时、或者每天处理一次; 处理的数据量级也多种多样,如 几十上百条的小批量多频次处理, 或者百万千万级别的每天增量数据处理等等。hive适合用来做批量数据统计分析。
- 定时任务。 定时任务顾名思义,是按不同的频率来定时运行,通常用来离线加工数据。 业务系统中涉及100+个定时任务, 分别来处理不同数据源,不同量级,不同业务场景下的数据。
- HDFS文件。用于大规模数据的分布式读写,特别是读多写少的场景。
存储非常大的文件并且对延时没有要求 。HDFS文件在业务系统中,用于大批量写入数据,供第三方系统(如下游业务系统引擎等)读取。 业务场景中, 首先会从第三方拿到大批量广告素材数据, 然后本系统进行过滤、填充、筛选后, 然后调用第三方接口进行素材数据审核。 将符合业务要求的审核广告素材数据, 通过定时任务一次性写入HDFS文件中,写入的字段包括 素材ID、流量包ID、审核状态等信息。 - ClickHouse. 以下简称CH表,列式存储数据库,一款面向 OLAP 的数据库,ClickHouse支持类SQL语言,提供了传统关系型数据的便利。实际使用中,CH表的上游表是hive表,通过配置公司统一提供的IDP任务,即可按业务需求将hive表中的数据,自动同步到CH表中。CH表中的数据成为下游报表引擎的数据源。
- 数据库。业务中采用了主从的MySQL数据库,中间件采用mybatis。 由于业务上涉及多张表的增删改查,以及对于某张表可能会新增列字段等等操作,业务代码中采用了统一封装,既防止了SQL注入风险,又方便程序的扩展。
- 缓存Redis。业务中采用缓存Redis集群来存储给下游业务的核心业务数据。 在业务实现中,首先通过定时任务,将MySQL数据库中的业务数据,如应用数据,广告位数据,内容位数据,屏蔽规则数据,媒体数据等,写入Redis缓存。 由于业务数据量百万级别,且业务数据存在实时变动的可能,整体同步一次数据,定时任务需要执行40多分钟,存在影响后续逻辑的风险。 为了加快缓存的同步,业务上进行了一次整体缓存同步的优化,将定时任务执行时间从40多分钟,减少到20分钟以内。 具体的做法包括: 采用异步多线程,并行处理应用数据,广告位数据,内容位数据,屏蔽规则数据,媒体数据等; redis的写入方式改成Pipeline管道写入方式。
- 报表引擎。报表引擎是公司架构组提供的一组底层服务,作为业务方可直接接入调用即可。 报表引擎对应的接口,调用传参数主要包括需要数据的维度、时间端、升序、倒序排序等等。
- grpc。rpc 远程过程调用, 不需要了解底层网络技术的协议,简单的理解是一个节点请求另一个节点提供的服务。RPC 只是一套协议,基于这套协议规范来实现的框架都可以称为 RPC 框架,比较典型的有 Dubbo、Thrift 和 gRPC。 GRPC是一种现代化开源的高性能RPC框架。
gRPC的接口规范
a. 当我们要创建gRPC服务时,通常第一步是在.proto文件中定义接口。使用这个.proto文件可以用protoc编译器生成客户端和服务端代码。服务端和客户端共享.proto文件。 客户端代码的生成,无需编写客户端代码,可以在具有许多服务的应用程序中节省大量大量开发时间。
b. 在.proto文件中清晰的描述了接口的入参以及出参,并且基于这个文件生成各中语言都能进行通信的接口,从而实现不同语言之间的通信。
c. 通过protoc生成的代码会确保客户端或者服务端发送的数据合乎规范,在各个平台和实现之间是一致的。
gRPC的优点 包括: 高效的二进制编码机制、清晰的接口规范、对流的支持。
实际业务场景中,分为两个方面的grpc使用:
1、 作为服务端,创建grpc服务,通过proto文件定义接口,入参,出参,并实现grpc接口的逻辑。 同时将接口即proto文件提供给第三方调用。
2、作为客户端,通过proto文件,生成客户端代码,去调用第三方业务提供的grpc接口来获取数据。
本人负责的业务系统中,存在若干grpc接口,提供不同场景、不同维度的数据,同时也会作为客户端,去调用第三方提供的grpc接口来获取数据。
- kconf. 公司内部提供出来的配置平台。 在上面可以进行各种k/v配置,然后在程序代码用引用kconf包,并且可以增删改查kconf中的配置。 支持的数据格式多种多样,如 boolean, int, float/double, hashmap/hashset,List链表,自定义对象等等。 在实际的业务开发中,通常有几种主要用途:
1、作为开关。 比如,配置值为TRUE时, 新增的逻辑生效;配置值为FALSE时,跳过新逻辑;
2、逐渐放量开关。 比如,配置值为20%,则20%流量/用户会看到新业务功能; 配置值为50%,则会有50%流量/用户会看到新业务功能; 观察一段时间,新功能正常, 会逐渐增大值,直到100%,这样新业务功能就完成了全部生效,系统发布全部完成了。
3、作为配置型常量数据。 比如, 业务中会用到一些相对固定不变的业务数据, 这些业务数据又想实现方便的改动(不需要改动代码、进行发布上线等一系列复杂操作),以及改动后可以实时生效, 就会将这些业务常量数据 配置到kconf中,然后在业务代码中做使用。
存储层: 涉及的存储中间件较多,有 MySQL,hive表,缓存,图片/视频存储等等; 涉及的表众多, MySQL数据库的表有100+,涉及的hive表有50+; 且需要多数据源同时处理。
整体MySQL数据库采用主从结构,核心逻辑、实时性要求高的逻辑会直接对主库操作。
hive表则是作为大数据存储来使用,并结合离线任务来做大数据的加工处理后,作为底层存储。 公司级别也会提供hive对应的公共平台、接口, 可以方便实现同其他数据源的迁移, 比如 hive表数据导入MySQL表,MySQL表数据导入hive表,hive表数据导入ClickHouse表等等。 由于不同的业务线都会有类似的操作需求, 所以架构组会将这类操作统一封装后,提供统一的公共平台, 有需要的业务线只需要在上面配置离线数据任务IDP即可。
关键中间件交互
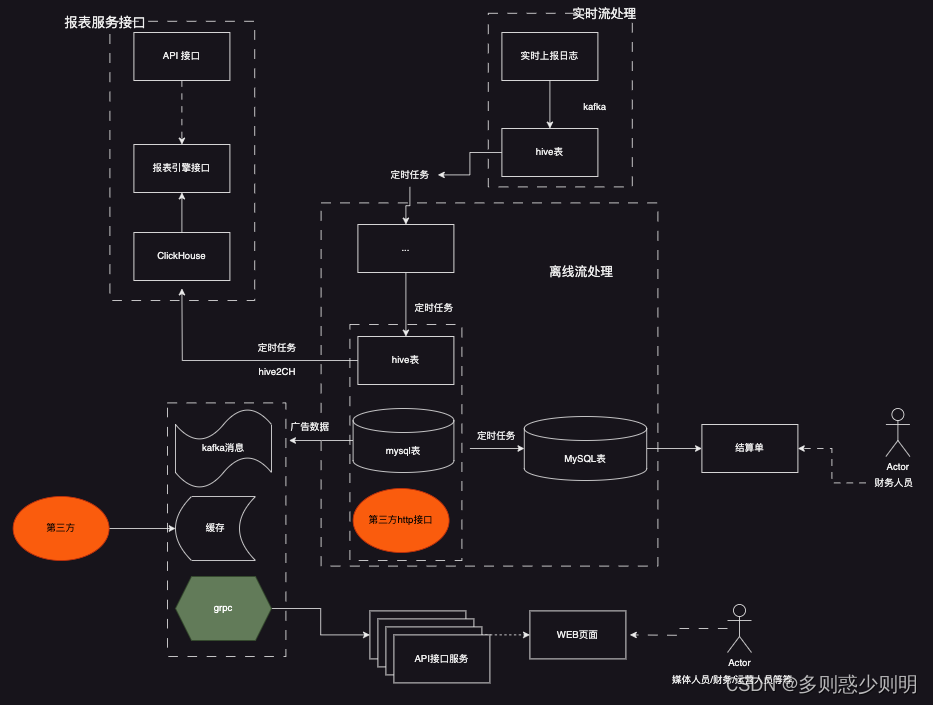
整体架构设计
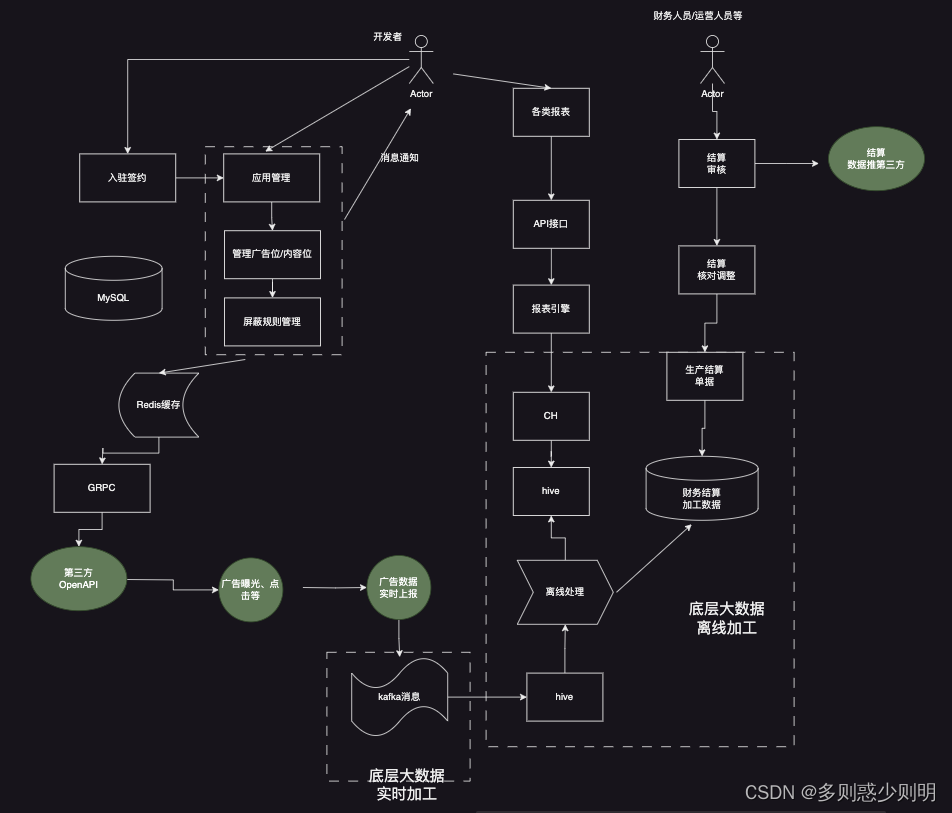
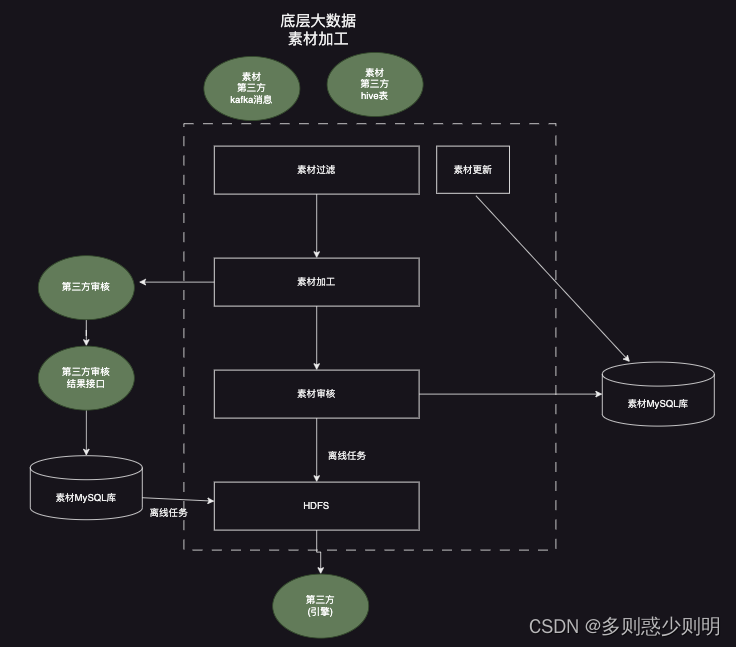
大数据素材底层处理
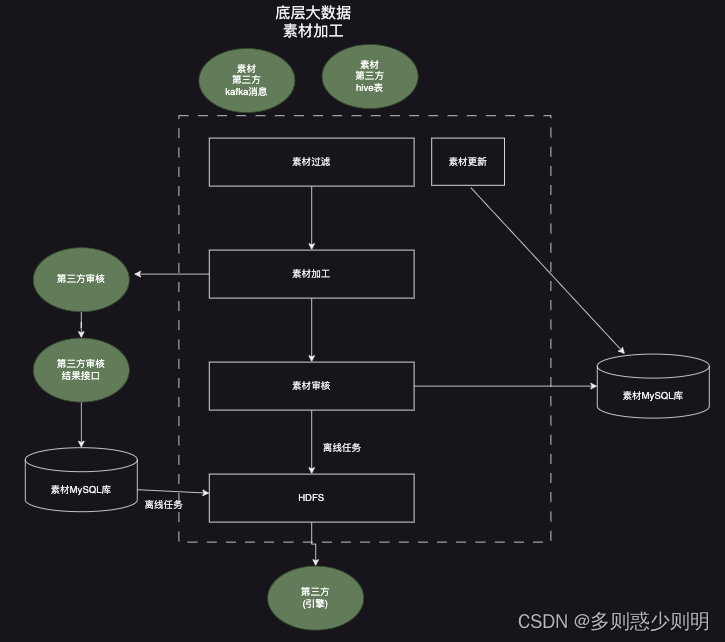
重点与难点:
- 素材过滤。 上游第三方业务系统的素材数量量级非常大(百万千万/天), 素材是全量的素材, 需要根据业务需求, 对全量素材进行多个条件过滤筛选, 筛选出符合业务需求的素材。 筛选的条件有多种,且随着业务发展,可能存在变动。 故而业务过滤 一方面需要满足业务需求, 另一方面也需要针对多种素材进行适配,方便后续扩展。 整个素材过滤逻辑处理,为了避免写多个if/else语句造成业务逻辑过于耦合,实现时采用了策略模式。 实际过滤条件众多, 这里为了便于说明讨论,简化为过滤条件A,B,C,D4个条件。
策略设计模式的特点:
1、提供一个策略接口
2、提供多个策略接口的实现类
3、提供一个策略上下文
策略设计模式优点:
1、可以自由切换算法(具体实现)
2、避免了多条件的判断(干掉了if else)
3、扩展性好可以定义新的算法提供给使用者(增加新功能时只需要增加代码而不需要修改代码)
于是4个过滤条件,可以实现为4个策略接口的实现类。 后面需求变更,比如新增了2个过滤条件, 那么只需要新增2个策略接口的实现类即可,既不影响原有的实现,避免改坏之前的业务逻辑, 有方便新增了新的业务逻辑。
- 素材加工。 从第三方拿到原始素材,往往都缺少业务需要的信息,比如,图片素材,需要对图片的大小,长宽等进一步裁剪,需要进一步补充title,标题,图片描述等等信息。 故而素材加工逻辑中,首先会调用第三方裁剪接口,进一步修剪图片; 然后调用引擎侧接口拿到title,标题,图片描述等等信息,填充原始素材信息。 填充完毕后, 将加工后的素材批量写入MySQL素材库,供后续逻辑使用。
由于从第三方拿到的素材种类比较多,除了图片,视频外,还需要覆盖各个业务场景,以及不同业务场景下的素材,需要进一步填充的信息也不同。 故而素材加工逻辑中需要重点考虑对各种各样素材的正确处理。
- 素材审核。 素材审核,顾名思义,是将加工后的素材 给媒体审核,只有审核通过的素材才能最终在终端展示。 业务场景中,素材审核分为两种,一种是页面上审核,一种是将素材送去第三方审核。
页面上审核场景下,加工后的素材存储在MySQL素材库中。 审核逻辑会拿到待审核的素材,展示在页面上,供媒体人员审核。 素材审核通过、审核拒绝后,都会实时将审核结果更新到MySQL素材库中。
另一种素材审核方式,将素材送去第三方审核,即通过调用第三方提供的接口方式,将待审核的素材送去第三方。 然后会实现一个定时任务,离线调用第三方的审核状态接口,来获取最终的素材审核状态。 同样, 素材审核通过、审核拒绝后,都会实时将审核结果更新到MySQL素材库中。
- 素材写入hdfs。 由于素材数据量级巨大,且需要全部同步给第三方引擎侧使用, 这里采用定时任务,实现离线写入。 即定时任务每隔一段时间执行一次,将全量审核通过的素材写入hdfs文件中,写入的核心字段包括素材ID,审核状态,素材所属流量包等等。
业务交互大图
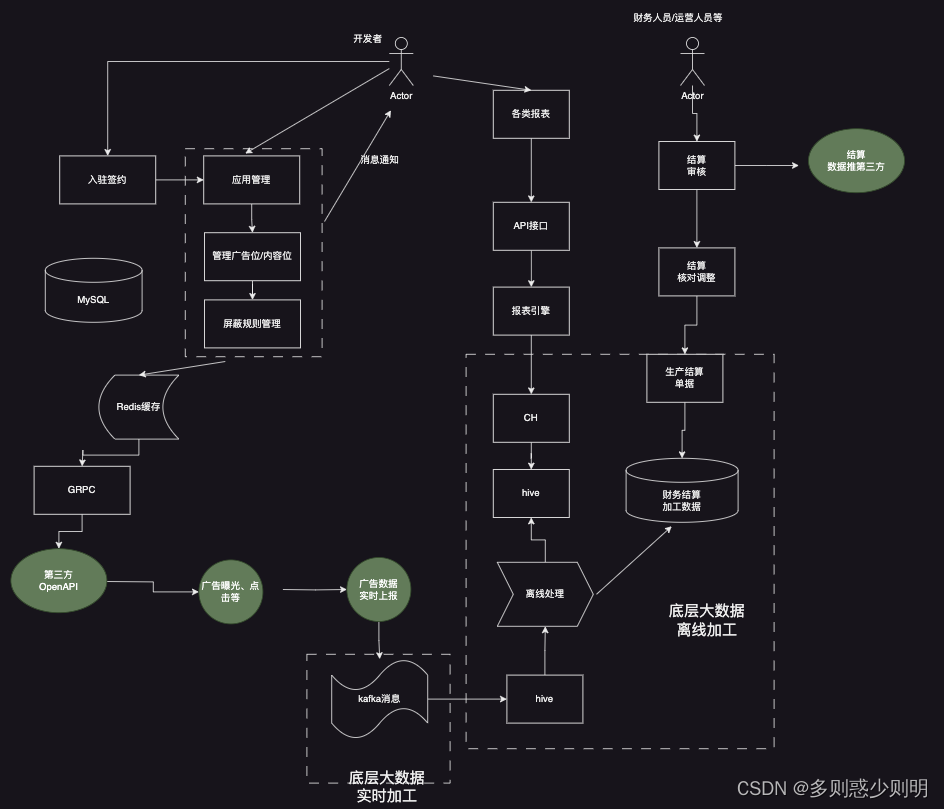
底层数据素材加工大图