论文阅读集合【1】
- 目标检测
- 缺陷检测
- 神经网络结构设计
-
- On the Integration of Self-Attention and Convolution
- DeltaCNN: End-to-End CNN Inference of Sparse Frame Differences in Videos
- An Image Patch is a Wave: Quantum Inspired Vision MLP
- Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
- A Survey on 3D Skeleton-Based Action Recognition Using Learning Method
目标检测
Object Detection in 20 Years: A Survey
本节参考Object Detection in 20 Years: A Survey Zhengxia Zou, Zhenwei Shi, Member, IEEE, Yuhong Guo, and Jieping Ye, Senior Member, IEEE 对其中的部分内容进行介绍,以便加深理解和记忆
论文介绍
此篇综述参考了400多篇目标检测相关的论文,全面介绍了目标检测20年来(1990-2019)的发展,包括目标检测发展的里程碑、数据集、性能度量指标、加速技术、近三年来最先进的检测方法、重要应用。
相比于同类型的综述,此篇综述有如下优点:更加全面(时间跨度、参考文献量、涉及方面)、对关键技术和新技术的深度探究、对加速技术的全面分析、对目标检测困难和挑战的分析。
1.目标检测
-
定义:目标检测是一种重要的计算机视觉任务,用于检测特定种类的物体并确定它们的位置,即What objects are where?
-
定位:目标检测是计算机视觉的一个基础性问题,是其他一些计算机视觉任务的基础,如实例分割、图像标注、目标追踪
-
研究主题:目标检测被分为两类研究主题:一般目标检测(旨在探索基于统一框架下不同类型物体的检测方法)和检测应用(旨在基于特定场景下的检测方法,如行人检测、脸部检测、文本检测)
-
应用:目标检测近年来被广泛用于真实世界,如自动驾驶、机器人视觉、视频监控
2.目标检测的里程碑
目标检测的发展可以被分为两个阶段:传统目标检测阶段(2014年以前)和基于深度学习的目标检测阶段(2014年以后)
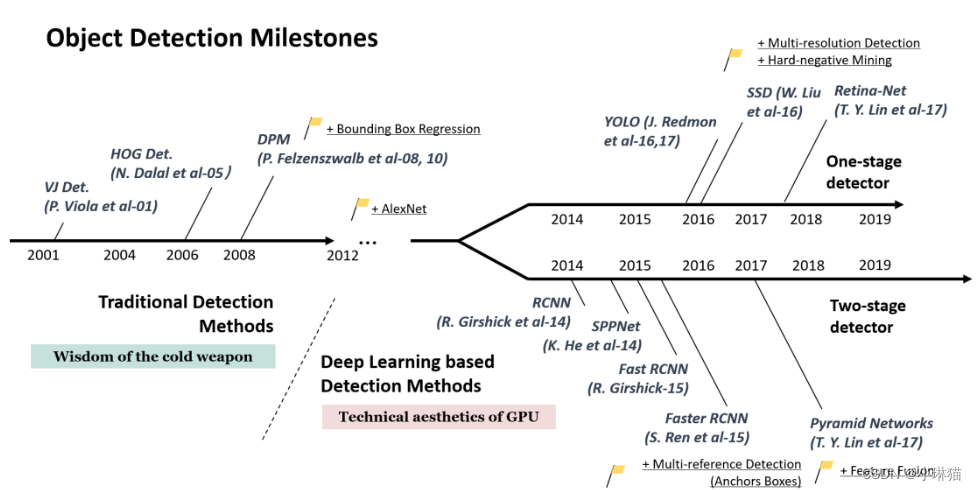
- 传统目标检测
多数传统目标检测算法是基于手工设计特征构建的,其不足在于:①需要手工设计特征;②识别效果不够好,准确率不高;③计算量较大,运算速度慢;④可能产生多个正确识别的结果
①Viola Jones Detectors
Viola Jones Detectors第一次实现了在无约束的条件下(如肤色分割)实时检测人脸。
其遵循了一个朴素的思想与方法:滑动窗口sliding windows,即通过一个滑动窗口在图像上遍历所有可能的位置和尺寸,看看这个窗口是否包含了目标(人脸)
尽管这一方法是朴素的,但它使用了三个当时先进的加速技术:
积分图像 Integral image:Haar小波 Haar wavelet被用作图像的特征。积分图像使得每个窗口的计算复杂度依赖于其独立的窗口大小,从而加速计算。
特征选择 Feature selcetion:使用Adaboost算法从一大组随机特征池中选择一小组最有利于面部检测的特征来代替基于手工选择的Haar滤波特征。
级联检测 Detection cascades:一种高效的分类策略,通过在背景框中花费更少的计算,而在脸部目标中花费更多的计算来降低计算复杂度。
②HOG Detector
方向梯度直方图 Histogram of Oriented Gradients,HOG是一种特征描述子,在2005年被N. Dalal and B. Triggs提出,最初用于行人检测,可用于不同种类物体的识别,是许多目标检测器和近年来许多计算机视觉应用的基础。
HOG可被视为一种尺度不变特征转换SIFT和形状上下文的改进。为了平衡特征不变性(平移、放缩、放射)和非线性变换,HOG特征描述子在均匀间隔单元的稠密网格上计算,并使用重叠的局部对比度归一化来提高精度,因此它是基于局部像素块进行特征直方图提取的一种算法,在目标局部变形和局部受光影响下都有很好的稳定性。
HOG为了适应检测物体的不同尺寸,通过多次放缩输入图像的大小来使得窗体的大小无需改变。
③Deformable Part-based Model (DPM)
DPM是VOC 07-09年目标检测任务的获奖者,是传统目标检测方法的顶峰,最早由P. Felzenszwalb在2008年提出,被视为对HOG检测器的扩展,然后又经过 R. Girshick进行了一系列的提高,许多当今的目标检测方法都深受其影响。
DPM遵循检测哲学“分而治之”,可将训练视为对分解物体的正确方法的学习,推理视为对不同物体部分的检测,如将检测一辆车视为检测它的车窗、车身和轮子。这部分工作被称为星形模型star-model,由P. Felzenszwalb完成,后由 R. Girshick扩展为混合模型mixture-model,来解决真实世界中具有更多变化的物体。
一个典型的DMP检测器由一个主滤波器root-filter和一些辅助滤波器part-filters组成。DMP通过一种弱监督学习方法,即所有辅助滤波器的配置可以通过潜变量自动地学习,来替代手工设置辅助滤波器的配置。
一些其他的重要技术如硬负挖掘hard negative mining、边框回归bounding box regression和上下文启动context priming也被应用其中,来提高精度。
为了加快检测速度,R. Girshick还提出了一种技术,能将模型“编译”为一种实现了级联框架的更快的模型,在不损失精度的情况下,可以加速10倍。
作为传统目标检测算法的SOTA(最新技术),DPM方法运算速度快,能够适应物体形变,但它无法适应大幅度的旋转,因此稳定性差。
- 基于CNN的目标检测器
随着传统检测器达到饱和,目标检测在2010年左右到达瓶颈。2012年CNN重生,2014年RCNN被引入目标检测任务,从此目标检测开始以前所未有的速度发展。在深度学习领域,目标检测可以被分为两类,二阶段检测器和一阶段检测器,前者将目标检测视为一个“由粗到细”的过程,后者将目标检测视为“一步到位”的过程。
- 基于CNN的二阶检测器
二阶检测器将目标检测分为两个阶段:候选区检测(找到可能存在目标的区域) + 分类(对目标进行分类),即proposal detection + verification
①RCNN
基本思想:通过选择性搜索selective search提取一组目标候选框 → 将每个目标候选框缩放大小为同一图像丢入AlexNet提取特征 →通过线性SVM分类器预测每个区域是否存在物体以及物体的种类
RCNN在VOC07目标检测任务上在平均精度mean Average Precision指标上大幅优于DPM-V5,但它的缺点也很明显:在重叠目标候选框上的重复特征计算导致其检测速度很慢。
②SPPNet
SPPNet在2014年被提出,其主要贡献在于:提供了空间金字塔池层 Spatial Pyramid Pooling(SPP) layer,可以产生固定长度的特征而不用考虑输入图像的尺寸并不做缩放。
另外,SPPNet的特征只需被计算一次,任意区域的固定长度的特征可以被生成来训练模型,避免了卷积特征的重复计算。在不损失精度的情况下,比RCNN快20倍。
不足:训练仍是多阶段的;SPPNet仅对全连接层进行微调,对之前的层没有进行改进。
③Fast RCNN
Fast RCNN在2015年被提出,能够在网络配置不变的情况下同时训练目标检测器和边框回归器。
Fast RCNN在平均准确率和速度方面大幅超过RCNN和SPPNet,但它的检测速度仍受限于候选框的检测。
④Faster RCNN
Faster RCNN是2015年提出的,第一个端到端的,接近实时检测的检测器。
其主要贡献在于:提出了Region Proposal Network (RPN),几乎能够达到在候选区域 Regin Proposals的零耗费,它将大多数独立的模块(如包括:候选区检测、特征提取、边框回归)整合到一个统一的、端到端的学习框架中。
尽管Faster RCNN突破了Fast RCNN的检测速度瓶颈,但在二级检测阶段仍有重复的计算。
⑤Feature Pyramid Networks
Feature Pyramid Networks在2017年在Faster RCNN的基础上被提出。
此前,绝大多数的基于深度学习的检测器都只是在网络的顶层进行检测,尽管网络的深度有益于分类,但对定位没有作用。为此,Feature Pyramid Networks发展了一种通过横向连接laterial connections的自顶向下的架构来对于不同尺寸的图像构建更高级的语义。
相比于CNN通常通过前向传播构建一种特征金字塔 feature pyramid的网络结构,FPN展现出不同尺寸的网络结构为目标检测带来的好处。
FPN目标已经变成了许多最新检测器的基础构建块。
- 基于CNN的一阶检测器
① You Only Look Once(YOLO)
YOLO在2015年被提出,是基于深度学习的第一个一阶检测器。相比于二阶检测器,检测速度得到了大幅提升,但牺牲了一定精度,尤其对于小目标问题。
通过一个单独的神经网络定位并分类图像。该网络将图像划分成不同区域,并同时预测边框盒子以及各区域存在物体的可能性。
②Single Shot MultiBox Detector (SSD)
SSD在2015年被提出,其主要贡献是:提出了多参考 multi-reference和多分辨率 multi-resolution检测技术,能够显著提高一阶检测器的准确率,尤其针对小目标,达到了速度和准确率的双高。
SSD与之前任何检测器的主要不同在于:SSD对于不同尺寸的图像使用不同层数的网络,其他检测器只在网络顶层进行检测。
③RetinaNet
作者提出:一阶检测器的精度低于二阶检测器精度的主要原因在于:训练稠密检测器时遇到极端的前景、背景类的不平衡。
一种新的损失函数焦点损失focal loss被提出,用于修改标准的交叉熵损失函数以便检测器能够在训练中将更多精力放在困难的、分类错误的样本。
RetianNet达到了同二阶检测器相当的精度,同时保持很高的检测速度。
3.数据集
- Pascal VOC (2005-2012):VOC07、VOC12最常用,现在已经不用
- ILSVRC(2010-2017)
- MS-COCO(2015-)
- Open Images(2018-)
- Other Datasets in specific areas
4.性能度量
- FPPW、FPPI
目标检测早期没有被广泛接受的评价指标,在早期行人检测任务中先后使用FPPW(miss rate vs false positives per-window)和FPPI(false positives vs per-image)作为性能度量指标。
①FPPW:横轴:miss rate=FN / P;纵轴:false positive per-window=FP / number of window
②FPPI:横轴:miss rate=FN / P;纵轴:false positive per-image=FP / number of image
- IoU(Intesection over Union)、AP(Average Precision)、mAP(mean Average Precision
最初由VOC07提出,多年来成为目标检测的性能度量标准
①IoU:交并比
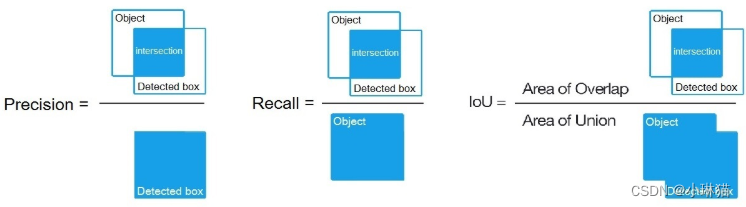
②AP:对PR曲线的纵轴Precision求平均,由于Recall∈[0,1],则对于PR曲线而言,AP即PR曲线与横轴所成图形的面积,实际计算不对PR曲线求积分,而通过平滑近似(具体的近似计算方法)
③mAP:AP是计算单个类别检测的指标,mAP将所有类别物体的AP取平均
- MS-COCO AP
COCO的AP不再考虑单个种类目标检测的AP,它只考虑全部类别的mAP,COCO的AP实际是mAP。另外,COCO AP计算时,不再使用固定阈值0.5的IoU,而是从0.5-0.95每隔0.05计算一次(共10次)的mAP并取平均。
- 其他性能度量指标
近年来一些新的性能度量指标也被提出,如localization recall precision等,但VOC/COCO-based mAP仍是主流的性能度量指标
A Dual Weighting Label Assignment Scheme for Object Detection
本节对CVPR2022年收录的A Dual Weighting Label Assignment Scheme for Object Detection进行简要总结,以便加深理解和记忆。
1.摘要
标签分配(LA)旨在为每个训练样本分配正(pos)和负(neg)损失权重,在目标检测中起着重要作用。现有的LA方法主要集中于正权重函数的设计,而负权重直接从正权重中导出。这种机制限制了检测器的学习能力。在本文中,我们探索了一种新的加权范式,称为双重加权(DW),以分别指定正负权重。我们首先通过分析目标检测中的评估指标来确定正负权重的关键影响因素,然后基于它们设计正负权重函数。具体而言,样本的正权重取决于其分类和定位分数之间的一致性程度,而负权重被分解为两个项:它是负类样本的概率和它的重要性取决于它是一个负类样本。这种加权策略提供了更大的灵活性来区分重要和不太重要的样本,从而产生了更有效的目标检测器。使用所提出的DW方法,单个FCOS-ResNet-50检测器在1×调度下可在COCO上达到41.5%mAP,优于其他现有LA方法。它一致地在没有附加功能的各种主干下大幅度地改进了COCO的基线。代码见: https://github.com/strongwolf/DW.
2.介绍
目标检测作为一项基本的视觉任务,几十年来一直受到研究者的广泛关注。最近,随着卷积神经网络(cnn)[13-15,34-37]和Visual Transformer(ViTs)[4,6,8,10,27,39,40,42,50]的发展,社区见证了检测器的快速发展。目前最先进的检测器[1,22,24,29 - 31,38,46,48,49]主要通过使用一组预定义的锚点预测类别标签和回归偏移来执行密集检测。作为检测器训练的基本单元,锚需要分配适当的分类(cls)和回归(reg)标签,以监督训练过程。这样的标签分配(LA)过程可以被视为向每个锚分配损失重量的任务。锚的cls损失(reg损失可以类似地定义)通常可以表示为:
L c l s = − w p o s × l n ( s ) − w n e g × l n ( 1 − s ) L_{cls} = −w_{pos }× ln (s) − w_{neg} × ln (1 − s) Lcls=−wpos×ln(s)−wneg×ln(1−s)
其中, w p o s w_{pos} wpos和 w n e g w_{neg} wneg分别为正类和负类权重,s为预测分类得分。根据 w p o s w_{pos} wpos和 w n e g w_{neg} wneg的设计,LA方法可以大致分为两类:硬LA和软LA。
Hard LA假设每个锚为正或负,这意味着, w p o s w_{pos} wpos, w n e g w_{neg} wneg∈{0,1},, w p o s w_{pos} wpos+ w n e g w_{neg} wneg=1。该策略的核心思想是找到一个合适的分割边界,将锚点分割为正集合和负集合。沿着这条研究路线的划分规则可以进一步分为静态和动态两类。静态规则[18,24,32,38]采用预定义的度量,例如IoU或从锚点中心到ground truth(GT)中心的距离,以将目标或背景相互匹配。这样的静态分配规则忽略了这样一个事实,即具有不同大小和形状的目标的分割边界可能不同。最近,已经提出了许多动态分配规则[12,26]。例如,TSS[44]根据对象的IoU分布分割对象的训练锚点。预测感知分配策略[4,17,19]将预测的置信度分数视为估计锚质量的可靠指标。静态和动态赋值方法都忽略了样本并不同等重要的事实。目标检测中的评估度量表明,最佳预测不仅应该具有高分类分数,而且应该具有准确的定位,这意味着cls-head和reg head之间具有更高一致性的锚点在训练期间应该具有更大的重要性。
基于上述动机,研究人员选择为锚定器分配软权重。GFL[21]和VFL[43]是两种典型的方法,它们基于IoU定义软标记目标,然后通过乘以调制因子将其转换为损失权重。其他一些工作[9,11]通过联合考虑reg分数和cls分数来计算样本权重。现有的方法主要集中于正类加权函数的设计,而负类权重简单地从正类权重导出,这可能会由于付类权重提供的很少新的监督信息而限制检测器的学习能力。我们认为,这种耦合加权机制不能在更精细的水平上区分每个训练样本。
图1显示了一个示例,四个锚具有不同的预测结果。然而,GFL和VFL分别为(B,D)和(C,D)分配几乎相同的(正,负)权重对。GFL还将零位和负位权重分配给锚A和C,因为每个锚都具有相同的cls分数和IoU。
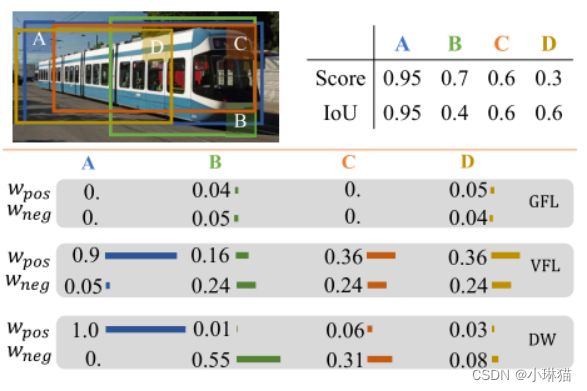
图1.所提出的DW方法与现有标签分配方法(例如GFL[21]和VFL[43])之间的差异说明。对于不明确的锚B、C和D,GFL和VFL将分别为{B、D}和{C、D}分配几乎相同的正负权重。相反,我们的DW为每个锚点分配一个不同的(正,负)对
由于在现有的软LA方法中,负权重函数与正权重函数高度相关,因此有时可以为具有不同属性的锚点分配几乎相同的(正,负)权重,这可能会削弱训练的检测器的有效性。
为了向检测器提供更具鉴别性的监督信号,我们提出了一种新的LA方案,称为双加权(DW),以从不同的角度指定正和负权重,并使它们彼此互补。具体而言,正类权重由置信度分数(从cls头部获得)和负类分数(从reg头部获得)的组合动态确定。每个锚的负权重被分解为两个项:它是负样本的概率和它的重要性以是负样本为条件。正类权重反映cls头部和reg头部之间的一致性程度,它将推动具有更高一致性的锚点在锚点列表中向前移动,而neg权重反映不一致性程度并将不一致的锚点推到列表的后面。通过这种方式,在推断时,具有更高cls分数和更精确位置的边界框在NMS之后将有更好的生存机会,而那些具有不精确位置的边缘框将落后并被过滤掉。参考图1,DW通过分配不同的(pos,neg)权重对来区分四个不同的锚点,这可以为检测器提供更细粒度的监督训练信号。
为了给我们的权重函数提供更准确的reg分数,我们进一步提出了一个box细化操作。具体而言,我们设计了一个学习预测模块,根据粗回归图生成4个边界位置,然后将它们的预测结果汇总,得到当前锚点的更新边界框。这个轻量级模块使我们能够通过引入适度的计算开销为DW提供更准确的reg分数。
通过在MS COCO[23]上的综合实验,证明了该方法的优越性。特别是,它将具有ResNet50[13]骨干的FCOS[38]检测器在普通1×训练方案下的COCO验证集上提高到41.5/42.2 AP w/wo盒细化,超过了其他LA方法。
3.相关工作
硬标签分配标记每个锚点为正类或负累样本是训练检测器的一个关键步骤。经典的基于锚的对象检测器[24,32]通过用GT对象测量锚的IoU来设置锚的标签。近年来,无锚探测器由于其简洁的设计和相当的性能而备受关注。FCOS[38]和Foveabox[18]都是通过中心采样策略选择pos样本:在训练过程中,靠近GT中心的锚点被采样为正类,其他锚点被采样为负类或忽略。上述LA方法对不同形状和尺寸的GT箱采用固定规则,属次优。
一些先进的LA策略[12,16,17,25,28,44]被提出来为每个GT动态选择pos样本。TSS[44]从特征金字塔的每一层中选择top-k锚点,并将这些top锚点的平均值+标准IoU作为pos/neg划分阈值。PAA[17]基于cls和reg损失的联合状态,以概率的方式自适应地将锚点分离为pos/neg。OTA[12]从全局角度处理LA问题,将分配过程制定为最优运输问题。基于变压器的检测器[4,6,27,50]采用一对一分配方案,为每个GT找到最佳pos样本。硬LA对所有样本一视同仁,但在目标检测中与评价指标的兼容性较差。
软标签分配由于预测框的评价质量不同,因此在训练时对样本的处理应有所区别。许多工作[3,20 - 22,43]被提出来解决训练样本的不平等问题。焦点损失[22]在交叉熵损失上增加了一个调制因子,以降低分配给分类良好的样本的损失权重,这推动探测器聚焦于硬样本。综合考虑cls评分和定位质量,广义焦点损失[21]为每个锚定器赋予一个软权重。Varifocal损失[43]利用一个欠条感知的cls标签来训练cls头。上面提到的大多数方法都集中在pos权值的计算上,并简单地将负权值定义为 1 − w p o s 1 - w_{pos} 1−wpos的函数。在本文中,我们解耦了这个过程,并分别为每个锚点分配pos和negative损失权值。大多数软LA方法为损失分配权重。有一种特殊的情况,权重被分配给分数,它可以被表述为: L c l s = − l n ( w p o s × s ) − l n ( 1 − w n e g × s ) L_{cls} = − ln (w_{pos} × s) − ln (1 − w_{neg} × s) Lcls=−ln(wpos×s)−ln(1−wneg×s)。典型的方法包括FreeAnchor[45]和Autoassign[47]。应该指出,我们的方法不同于他们。为了以完全不同的方式匹配锚点,自动分配中的 w p o s w_{pos} wpos和 w n e g w_{neg} wneg仍然接受梯度。然而,在我们的方法中,损失权重是经过精心设计的,并且完全与网络分离,这是加权损失的常见做法。
4.提出的方法
1)动机和框架
为了与NMS兼容,一个好的密集检测器应该能够预测具有高分类分数和精确位置的一致边界框。但是,如果所有的训练样本都被同等对待,那么两个头部之间就会出现错位:类别得分最高的位置通常不是回归对象边界的最佳位置。这种失准会降低检测器的性能,尤其是在高IoU度量下。软LA通过加权损失以软方式处理训练样本,旨在增强cls和reg头之间的一致性。对于软LA,锚的损失可以表示为:
L c l s = − w p o s × l n ( s ) − w n e g × l n ( 1 − s ) L r e g = w r e g × ℓ r e g ( b , b ′ ) L_{cls} = −w_{pos} × ln(s) − w_{neg} × ln(1 − s) \\ L_{reg} = w_{reg} × ℓ_{reg} (b, b′) Lcls=−wpos×ln(s)−wneg×ln(1−s)Lreg=wreg×ℓreg(b,b′)
其中s是预测的cls分数,b和b′分别是预测的边界框和GT对象的位置,以及 ℓ r e g ℓ_{reg} ℓreg是回归损失,如平滑L1损失[32]、IoU损失[41]和GIoU损失[33]。通过将更大的 w p o s w_{pos} wpos和 w r e g w_{reg} wreg分配给具有更高一致性的锚点,可以缓解cls和reg头之间的不一致性问题。因此,这些训练有素的锚能够在推断时同时预测高cls分数和精确位置。
现有的工作通常将 w r e g w_{reg} wreg设置为等于 w p o s w_{pos} wpos,主要关注如何定义一致性并将其整合到损失权重中。表1总结了最近代表性方法中pos锚的 w p o s w_{pos} wpos和 w n e g w_{neg} wneg的方案。

可以看到,目前的方法通常定义一个度量t来表示锚级两个头部之间的一致性程度,然后将不一致性度量设计为1−t的函数。一致和不一致的指标最终通过分别添加缩放因子( ( s − t ) 2 (s−t)^2 (s−t)2, s 2 s^2 s2或t)集成到pos和neg损失权重中。
与上述 w p o s w_{pos} wpos和 w n e g w_{neg} wneg高度相关的方法不同,我们建议以预测感知的方式分别设置pos和neg权重。其中,pos权值函数以预测的cls评分s和预测框与GT对象之间的借据为输入,通过估计cls与reg头的一致性程度来设置pos权值。负权重函数接受与pos权重函数相同的输入,但将负权重表示为两个项的乘法:锚为负的概率,以及锚为负的重要性。这样,具有相似pos权值的模糊锚点可以接收到更细粒度且负权值不同的监督信号,这是现有方法所不能做到的。
DW框架的管道如图2所示:
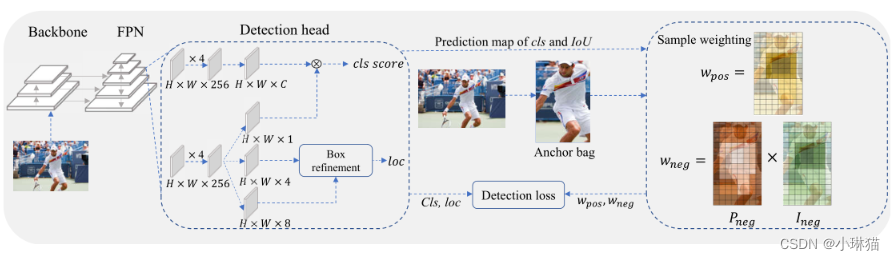
图2 DW管道。左侧为整体检测模型,由骨干、FPN和检测头组成。分类分支(H × W × C)和中心度分支(H × W × 1)的输出相乘作为最终的cls评分。盒子精化模块利用四个预测边界点(H × W × 8)将粗预测(H × W × 4)调整到更精细的位置。右边部分显示了加权过程。给定一个对象,首先通过选择靠近对象中心的锚点来构造一个候选锚包。然后,每个锚将从不同方面分配一个pos权重和negative权重
作为一种常见的做法[9,11,12,38],我们首先通过选择靠近GT中心(中心先验)的锚点,为每个GT对象构建一组候选正类。候选包外的锚被认为是负样本,由于它们的统计数据(如IoU、cls分数)在训练早期非常嘈杂,因此不参与加权函数的设计过程。候选包内的锚将被分配到 w p o s w_{pos} wpos、 w n e g w_{neg} wneg和 w r e g w_{reg} wreg三个权重,以更有效地监督训练过程。
2)正加权函数
样本的pos权值应反映其在分类和定位中对准确检测目标的重要性。我们试图通过分析目标检测的评价指标来找出影响这一重要性的因素。在COCO的测试过程中,一个类别的所有预测都应该根据一个排名指标进行适当的排名。现有方法通常使用cls评分[32]或cls评分与预测借条[44]的组合作为排名指标。从排名列表开始,检查每个包围框的正确性。当且仅当以下情况时,预测才被定义为正确预测:
a)预测边界框与其最近的GT对象之间的IoU大于阈值θ;
b)满足上述条件的方框都不会排在当前方框的前面。
总而言之,预测列表中只有第一个IoU大于θ的包围框被定义为pos检测,其他的包围框都被认为是同一GT的假正类。由此可见,较高的排名分数和较高的IoU都是一个pos预测的充分和必要条件。这意味着同时满足这两个条件的锚点更有可能在测试中被定义为位置预测,因此在训练中它们应该具有更高的重要性。从这个角度来看,pos权重 w p o s w_{pos} wpos应该与IoU和排名得分呈正相关,即 w p o s w_{pos} wpos∝IoU和 w p o s w_{pos} wpos∝s。为了指定pos函数,我们首先定义一个一致性度量,记为t,来测量两个条件之间的对齐度:
t = s × I o U β t = s × IoU^β t=s×IoUβ
其中β用于平衡两个条件。为了鼓励不同锚点之间pos权重的较大差异,我们添加了一个指数调制因子:
w p o s = e µ t × t w_{pos} = e^{µt} × t wpos=eµt×t
其中µ是一个超参数,用于控制不同pos权值的相对间隙。最后,每个实例的每个锚的pos权重由候选包中所有pos权重的总和归一化。
3)负加权函数
虽然pos权重可以强制一致的锚点同时具有高cls分数和大IoU,但不一致的锚点的重要性不能通过pos权重来区分。参考图1,锚D的位置更细(IoU大于θ),但cls分数更低,而锚B的位置更粗(IoU小于θ),但是cls分数更高。它们可能具有相同的一致性程度t,因此将以相同的pos强度向前推进,这不能反映它们的差异。为了为检测器提供更具鉴别性的监督信息,我们建议通过向它们分配更不同的负权重来忠实地指示它们的重要性,负权重被定义为以下两个项的乘积。
a)成为负样本的概率
根据COCO的评估度量,IoU小于θ是错误预测的充分条件。这意味着不满足IoU度量的预测边界框将被视为负检测,即使它具有高cls分数。也就是说,IoU是确定负样本概率的唯一因素,用Pneg表示。由于COCO采用范围从0.5到0.95的IoU间隔来估计AP,因此边界框的概率Pneg应满足以下规则:
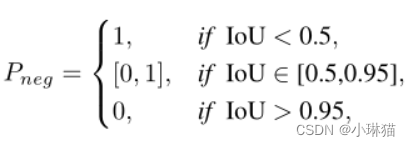
任何定义在区间[0.5,0.95]内的单调递减函数都符合 P n e g P_{neg} Pneg。为简单起见,我们将 P n e g P_{neg} Pneg实例化为以下函数:
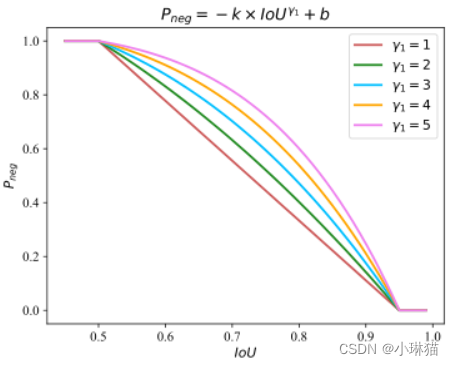
P n e g = − k × I o U γ 1 + b , i f I o U ∈ [ 0.5 , 0.95 ] P_{neg} = −k × IoU ^{γ1} + b, \; if \;IoU ∈ [0.5,0.95] Pneg=−k×IoUγ1+b,ifIoU∈[0.5,0.95]
它经过点(0.5,1)和(0.95,0).一旦确定了γ1,就可以用待定系数法得到参数k和b。图3绘制了不同γ1值下 P n e g P_{neg} Pneg与IoU的曲线。
在推理时,排名表中的阴性预测不会影响查全率,但会降低查准率。为了延迟这一过程,负包围框的排名应该尽可能地靠后,即它们的排名分数应该尽可能地小。基于这一点,排名分数大的负预测比排名分数小的负预测更重要,因为它们是网络优化的更难的例子。因此,负类样本的重要性,用 I n e g I_{neg} Ineg表示,应该是排名得分的函数。为简单起见,我们设它为:
I n e g = s γ 2 I_{neg} = s^{γ2} Ineg=sγ2
其中,γ2是一个因素,表明应给予重要阴性样品多大的偏好。
最后得到负权 w n e g = P n e g × I n e g w_{neg} = P_{neg} × I_{neg} wneg=Pneg×Ineg
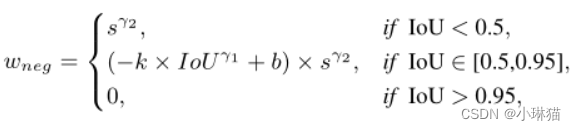
与IoU负相关,与s正相关。可以看出,对于两个pos权值相同的锚,借据较小的锚的负权值较大。 w n e g w_{neg} wneg的定义与推理过程很好地兼容,可以进一步区分具有几乎相同pos权值的模糊锚点。示例请参见图1
4)盒子细化
由于pos和negative加权函数都以借据作为输入,所以更准确的借据可以诱导出更高质量的样本,有利于学习更强的特征。我们提出基于预测偏移图O∈RH×W ×4对边界框进行箱体细化操作,其中O(j, i) ={∆l,∆t,∆r,∆b}分别表示从当前锚点中心到GT对象的最左l、最上t、最右r和最下b面的预测距离,如图4所示。
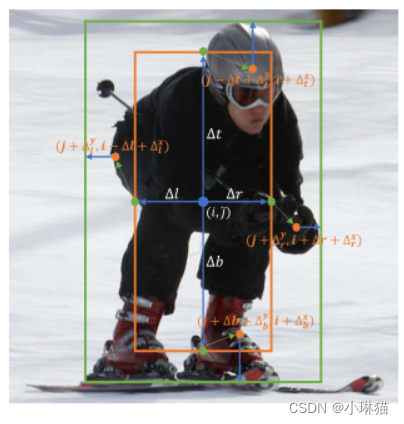
图4。盒子细化操作的说明。通过预测4个距离={∆l,∆t,∆r,∆b},首先生成锚在位置(j,i)处的粗包围框(橙色框)。然后相对于四个边点(绿色点)预测四个边界点(橙色点)。最后,将四个边界点的预测结果进行聚合,得到更精细的边界框(绿框)。基于物体边界附近的点更有可能预测准确的位置这一事实,我们设计了一个可学习的预测模块,基于粗包围盒为每边生成一个边界点。
由图4可知,四个边界点的坐标定义为:
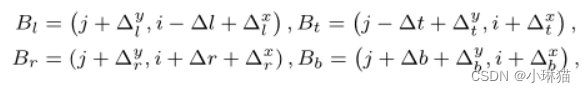
其中, ∆ l x , ∆ l y , ∆ t x , ∆ t y , ∆ r x , ∆ r y , ∆ b x , ∆ b y {∆^x_l,∆^y_l,∆^x_t,∆^y_t,∆^x_r,∆^y_r,∆^x_b,∆^y_b} ∆lx,∆ly,∆tx,∆ty,∆rx,∆ry,∆bx,∆by为细化模块的输出。
改进后的偏移图O’更新为:
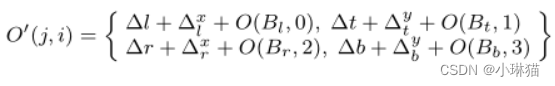
5)损失函数
所提出的DW方案可以应用于大多数现有的密集探测器。本文采用具有代表性的高密度检测器FCOS[38]来实现DW。如图2所示,整个网络结构由骨干网、FPN和检测头组成。按照约定[11,38,47],我们将中心度分支和分类分支的输出相乘作为最终的cls分数。我们网络的最终损失是:
L d e t = L c l s + β L r e g L_{det} = L_{cls} + βL_{reg} Ldet=Lcls+βLreg
式中,β为平衡因子,与式3中的平衡因子相同,
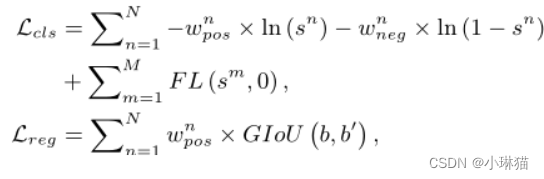
其中N和M分别为候选袋内外锚的总数,FL为Focal Loss [22], GIoU为regression Loss [33], s为预测的cls评分,b和b '分别为预测的盒子和GT对象的位置。
5.实验
6.结论
我们提出了一种自适应标签分配方案,称为双加权(DW),以训练精确的密集目标检测器。DW打破了以往密集检测器耦合加权的惯例,通过从不同方面估计一致性和不一致性指标,为每个锚点动态分配单个pos和negg权重。还开发了一种新的框细化操作,以直接细化回归图上的框。DW与评价指标高度兼容。在MS COCO基准上的实验验证了不同骨干网下DW的有效性。无论是否进行盒子改进,ResNet-50的DW分别达到了41.5 AP和42.2 AP,记录了最新的技术水平。作为一种新的标签分配策略,DW对不同的检测头也表现出良好的泛化性能。
目标检测对社会的负面影响主要来自于军事应用的滥用和隐私问题,在将该技术应用于现实生活之前需要仔细考虑。
缺陷检测
基于深度学习的钢铁瑕疵检测算法研究
本节参考电子科技大学2022年的工程硕士学位论文基于深度学习的钢铁瑕疵检测算法研究,以便学习论文撰写结构和方法、了解工业缺陷检测、积累改进点。
1.介绍
1.1钢铁瑕疵检测
1)钢铁表面可能存在裂纹、斑块、划痕、夹杂等缺陷,瑕疵缺陷检测是保证钢铁产品质量的重要一环
2)具体任务分类
①判断图像表面是否存在瑕疵缺陷
②检测图像中的缺陷位置,但不对瑕疵类别做进一步区分
③检测缺陷位置的同时,对瑕疵类别进行进一步区分
④缺陷分割

3)传统方法:漏磁检测、红外检测、涡流检测
4)难点:背景复杂、小目标问题突出、边界模糊、大量标签数据难获取、数据分布不平衡、图像采集环境不理想
5)实验数据集
东北大学开源的 NEU_DET数据集;Kaggle平台的KSSD钢铁数据集
1.2目标检测
1)任务:分类、位置回归
2)传统方法:基于模板匹配技术、基于组件的检测方法、基于几何表示的方法、基于统计分类器的方法等
3)典型的单阶检测方法:YOLO、SSD等
4)典型的二阶检测方法:Fast R-CNN、Faster R-CNN、Mask R-CNN等
1.3迁移学习
1)训练数据和测试数据在相同的特征空间中,不一定拥有着相同的数据分布;当面对一个新的数据分布时,如何减少模型训练对标注数据的依赖是一个非常值得关注的问题。
2)通过在不同的任务领域之间进行知识的迁移,来降低重新收集训练数据所需要的成本:即将不同但是跟目标域相关的源领域的知识进行迁移,来提高在目标域上的效果,从而减少构建目标域模型时对大量目标域有标签数据的依赖。
知识迁移的两个领域必须有着一定的相关性,否则可能无效甚至产生负迁移现象。
3)方法:基于差异的(通过微调的方法来减小域差异的问题)、基于对抗的(利用域鉴别器来对源域和目标域进行区分,然后利用对抗训练的方法对域进行混淆)、基于重建的(通过重构源域或者目标域图像来提 升在目标域上的效果)、混合的等
1.4Faster R-CNN
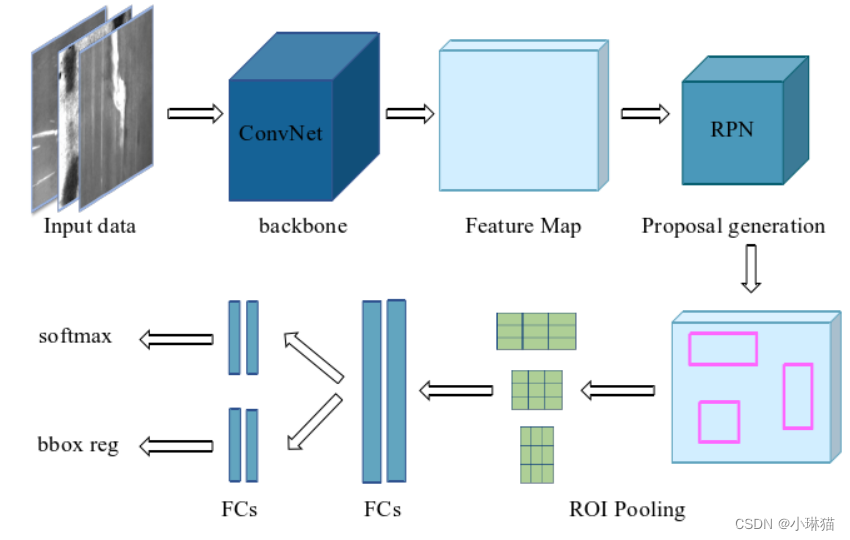
共享的底层卷积神经网络(提取特征)、区域生成网络RPN(获得检测目标的候选位置区域)、ROIPooling及ROIAlign、ROI分类及回归网络、非极大值抑制NMS
2.方法应用|改进点
2.1COPY-PASTE方法
将瑕疵区域从所有图像中裁剪下来,然后将这些瑕疵随机地粘贴到图像上,从而生成更多的训练数据,同时增加了图片中物体数量和瑕疵区域的占比大小。
2.2标签尺度抖动
对于非刚性的检测目标,对物体标注的真实标签做一个小 范围内的尺度随机抖动,从而减缓标注误差带来的影响,且能够提高模型的泛化能力。
2.3多尺度的特征金字塔FPN
多尺度训练的方法能够使得模型能够在不同尺度输入上都有较好的泛化性
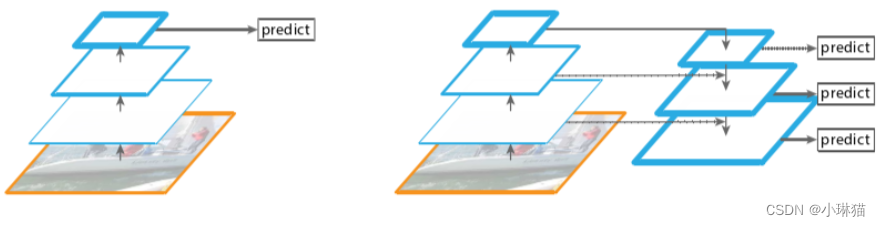
①自底向上的通路:获取高层次的语义信息
②自顶向下的通路:将高层的语义信息和低层的图像信息进行结合,使获得的特征图具有较高的分辨率的同时,也具有较强的语义信息。
③横向连接通路:利用多个层次不同大小的特征图来同时进行预测,能够有效检测不同尺度大小的物体
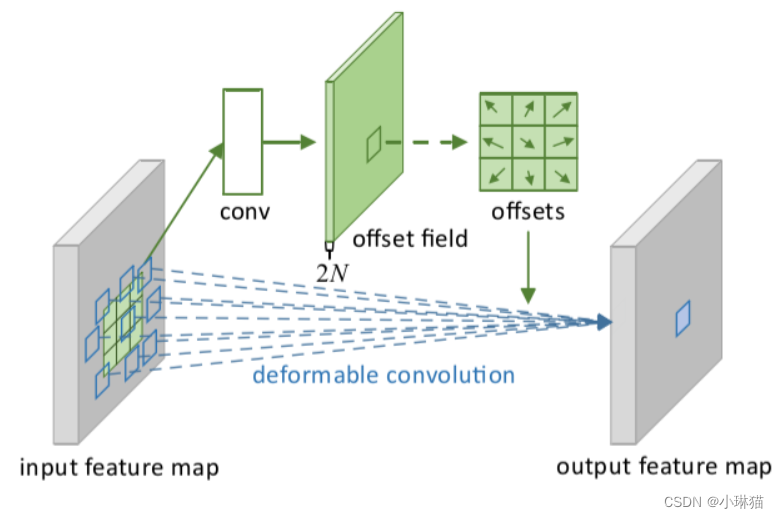
2.4可变形卷积DCN模块
1)动机:普通的卷积结构只在固定的几何位置进行数据采样,限制了模型的几何转换能力,对于多样化的瑕疵缺陷的特征提取能力不够好。
2)可变形卷积模块DCN通过从输入数据中学习额外的位 置偏移信息,然后利用位置偏移信息进行采样,因此DCN能够根据输入数据进行 自适应的采样,在卷积计算时能够适应包括尺度变化、长宽比变化、旋转等多种形式的变换。
2.5结合上下文语义信息的ROIAlign
一些任务中,候选区域周围的环境信息对于ROI的回归和分类也是非常重要的。
结合上下文语义信息的改进方法如下:在进行ROI对齐操作时,将输入到后 续网络的ROI区域进行放大,即ROI对齐操作的输入为放大后的区域位置,以此 获得包含ROI区域以及周围上下文区域在内的信息,更好地帮助对ROI进行分类 和回归。
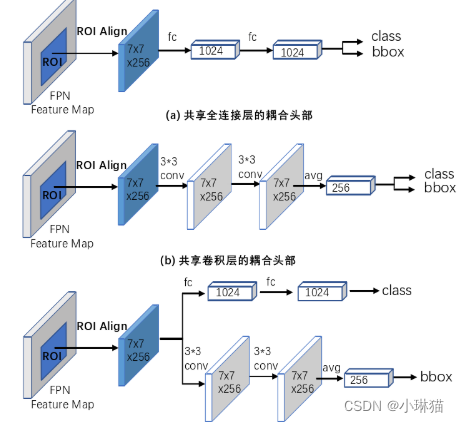
2.6回归和分支解耦合
将图像分类和边框回归进行解耦合。有研究表明,分类和回归分支之间存在着冲突,相比于卷积head,全连接 head能够更加鲁棒地对不完整物体区域进行分类,但回归子任务的效果较差,因此更适合于分类任务;而卷积层head刚好相反,能够提供更加精确的位置信息, 在分类任务上效果较差,所以更适合回归任务。
2.7跨域场景下的领域自适应检测算法
将不同钢铁瑕疵数据集上的瑕疵特征进行了行t-SNE可视化,图中的每个点都代表着一个瑕疵目标。不同领域瑕疵数据之间存在着明显差异,正是这种差异导致不同领域数据学习的知识不能直接被相互应用,每个域往往需要各自获取相应的标注数据来进行模型训练。
DA Faster R-CNN模型:从概率角度对跨域场景的领域偏移问题进行了理论分析,通过H散度来度量源域图像和目标域图像分布之间的差异,并基于对H散度的对抗训练提出了该模型,该自适应方法通过提取域不变特征,对 于目标域数据无标注的情况非常有效,能够缓解现实场景下训练数据不足的问题。保留原有结构、图像层级自适应的特征对齐分支、实例层级自适应的特征对齐分支、一致性约束组件
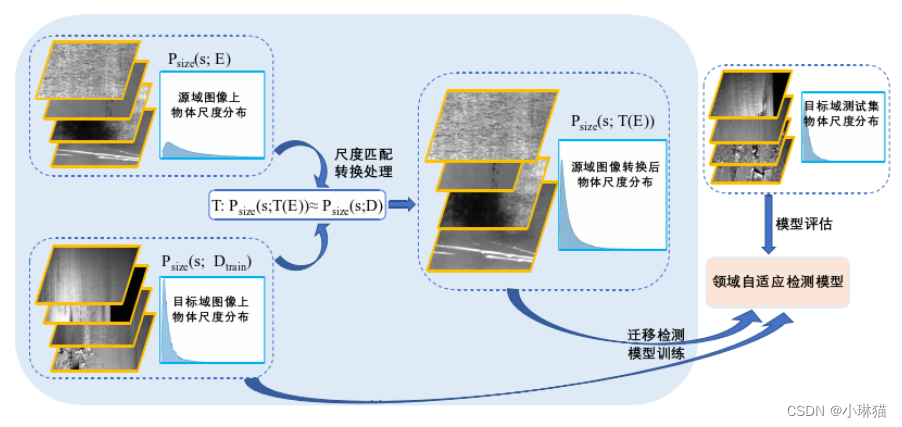
2.8尺度匹配对齐方法
尺度差异也是域差异的一种,这种差异的产生和因光照等因素导致的域差异是类似的。
①计算目标域物体的尺度大小分布,根据groundtruth标签,在去除两端极值后,将尺度分布区间划分成几十个小的区间,并计算得到目标域物体在每个小区间内的分布概率
②将源域检测目标大小按照目标域的概率分布进行划分,即统计源域物体在 区间端点上对应概率的尺度大小,得到源域图像在相应分布概率下每个区间的上下界
③在模型训练过程中,对于每张源域图像,根据groundtruth标签,计算该图像上所有目标的平均大小s
④根据检测物体的平均大小s,得到物体大小s对应的源域物体大小分布区 间n,然后在目标域大小分布的第n个区间内进行均匀分布采样,得到在目标域上 对应的物体大小s ∗,然后将该源域图像进行s ∗/s倍的尺度缩放
⑤在完成对该图像的尺度缩放后,就可以将该数据和目标域数据一起,输入到领域自适应模型中,进行后续的训练任务
2.9基于伪标签的类别加权对齐模块
神经网络结构设计
On the Integration of Self-Attention and Convolution
本节参考CVPR 2022年收录的由清华、华为、北京人工智能研究院联合发表的On the Integration of Self-Attention and Convolution,对其主要内容进行总结,以便加深理解和记忆。
论文:[2111.14556] On the Integration of Self-Attention and Convolution (arxiv.org)
代码:github、gitee
1.研究背景与相关工作
1.1卷积
卷积神经网络[27,28]利用卷积核提取局部特征,被广泛应用于图像识别[20,24],语义分割[9]和物体检测[39],并在各种基准测试中取得了最先进的性能[25,40]。
1.2自注意力
①自注意在自然语言处理中首次被引入[1,43],在BERT和GPT3等广泛的语言任务中也表现出了强大的能力[4,14,37]。
②理论分析[11]表明,当具有足够大的容量时,自注意力可以表示任意卷积层的函数类。因此,最近的一系列研究探索了将自我注意机制应用于视觉任务的可能性[16,23]。
③最近,随着Vision transformer的出现[7,16,38],基于注意力的模块在许多视觉任务上已经取得了与CNN相当甚至更好的表现。
④自注意力在图像生成和超分辨率领域也显示出巨大的潜力[10,35]。
目前主流的方法有两种,一种是将自注意力作为网络中的模块[7,33,55],另一种是将自注意力和卷积视为互补的部分[6,29,45]。
1)仅使用自注意力
①受自我注意在长程依赖中的表达能力的启发[14,43],一系列工作试图将自注意单独用作构建视觉任务模型的基本构建块[2,7,16]。
②一些工作[38,54]表明,自我注意可以成为视觉模型的一个独立单元,完全取代卷积运算。
③最近,Vision Transformer[16]表明,如果有足够的数据,我们可以将图像视为256个令牌的序列,并利用Transformer模型[43]在图像识别中取得有竞争力的结果。
④此外,transformer被用于检测[2,7,57]、分割[46,53,55]、点云识别[18,33]和其他视觉任务[8,35]。
2)注意力增强型卷积
先前提出的多种图像注意力机制表明,注意力机制可以克服卷积网络的局部性限制。因此,许多研究人员探索了使用注意力模块或利用更多关系信息来增强卷积网络功能的可能性。
①挤压和激励(SE)[23]和聚集激励(GE)[22]为每个通道重新加权映射。
②BAM[34]和CBAM[47]独立地重新加权通道和空间位置,以更好地细化特征图。
③AA-Resnet[3]通过连接来自另一个独立的自注意管道的注意图来增强某些卷积层。
④BoTNet[41]在模型后期用自注意模块代替卷积。
一些工作旨在通过聚集来自更大范围像素的信息来设计更灵活的特征提取器:
⑤Hu等人[21]提出了一种局部关系方法,以基于局部像素的组成关系自适应地确定聚合权重。
⑥Wang等人提出了非局部网络[45],该网络通过引入比较全局像素之间相似性的非局部块来增加感受野。
3)卷积增强注意力
随着Vision Transformer[16]的出现,已经提出了许多基于Transformer的变体,并在计算机视觉任务上取得了显著的改进。
①CvT[48]在标记化过程中采用卷积,并利用步长卷积来降低自注意的计算复杂度
②具有卷积茎的ViT[50]提出在早期阶段添加卷积,以实现更稳定的训练。
③CSwin Transformer[15]采用了基于卷积的位置编码技术,并对下游任务进行了改进。
④Conformer[36]将Transformer与独立的CNN模型相结合,以集成这两个功能。
2.ACmix:整合卷积和自注意力
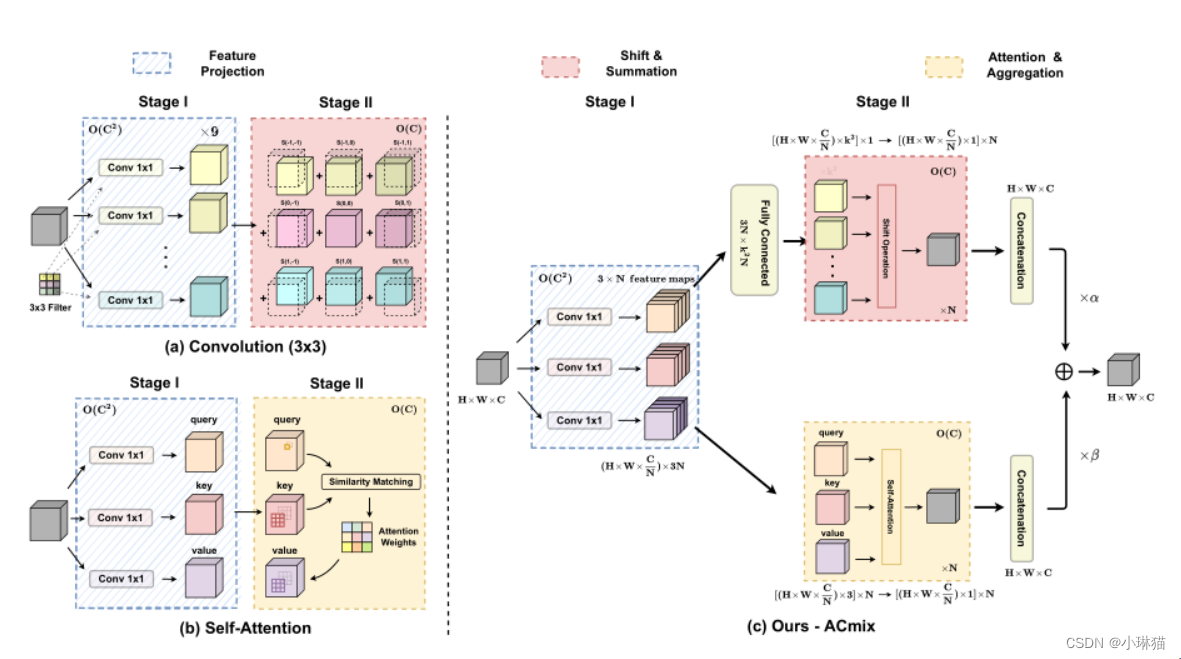
2.1将卷积和自注意力拆分为两个阶段
1)卷积
阶段①:对输入特征映射进行线性变换,与标准的1 × 1卷积相同
阶段②:线性变换后的特征根据内核位置进行移位,最后进行聚合
按阶段推导后的公式如下图所示(具体推导过程见原论文)
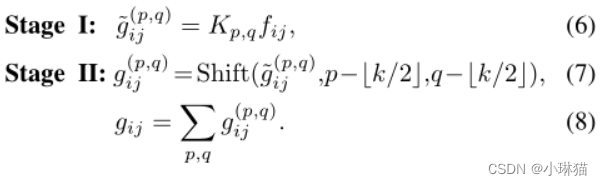
2)自注意力
与传统的卷积相比,注意力使模型能够关注更大范围内的重要区域
阶段①:进行1 × 1卷积,将输入特征投影为查询、键和值
阶段②:注意力权重的计算和值矩阵的聚集,即局部特征的聚集
按阶段推导后的公式如下图所示(具体推导过程见原论文)
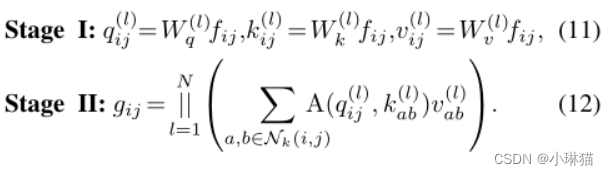
2.2计算复杂度的考量
卷积和自注意力在阶段①的理论FLOPs和参数的复杂度与通道数呈二次幂关系,而阶段②的计算复杂度与通道数C呈线性关系,且不需要额外的训练参数。
2.3将卷积和自注意力联系起来
自注意力模块和卷积模块的分解揭示了它们之间更深层次的关系。首先,这两个阶段的作用非常相似:阶段①是一个特征学习模块,其中两种方法通过执行1×1卷积将特征投射到更深的空间来共享相同的操作。阶段②对应于特征聚合的过程,尽管他们的学习模式不同。
从计算角度来看:卷积模块和自注意力模块在阶段I进行的1 × 1卷积对理论FLOPs和参数的复杂度要求为通道数C的二次幂。在阶段②,两个模块都是轻量级的。
2.4整合卷积和自注意力
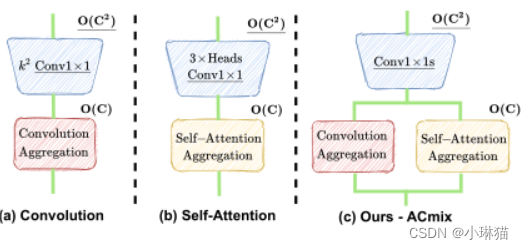
2.3的观察结果自然地促使卷积和自注意力完美地结合。由于两个模块共享相同的1 × 1卷积运算,所以我们只进行一次投影,并将这些中间特征映射分别用于不同的聚合运算,形成我们提出的模块:ACmix。
ACmix包括两个阶段:
阶段①:输入特征通过三个1×1卷积进行投影,并分别重塑为N个分片。由此获得了包含3×N特征映射的丰富的中间特征集。
阶段②:这些特征集按照两种不同的路径使用:
对于自注意路径,将中间特征收集N组,其中每组包含3个1 × 1的卷积核。对应的3个特征映射作为查询、键和值,遵循传统的多头自注意模块。
对于卷积路径,采用轻全连通层,生成 k 2 个 k^2个 k2个特征映射。因此,通过移动和聚合生成的特征我们以卷积方式处理输入特征,并像传统的那样从感受野收集信息。
最后,将两条路径的输出加在一起,强度由两个可学习标量α、β控制:
F o u t = α F a t t + β F c o n v F_{out} = αF_{att} + βF_{conv} Fout=αFatt+βFconv
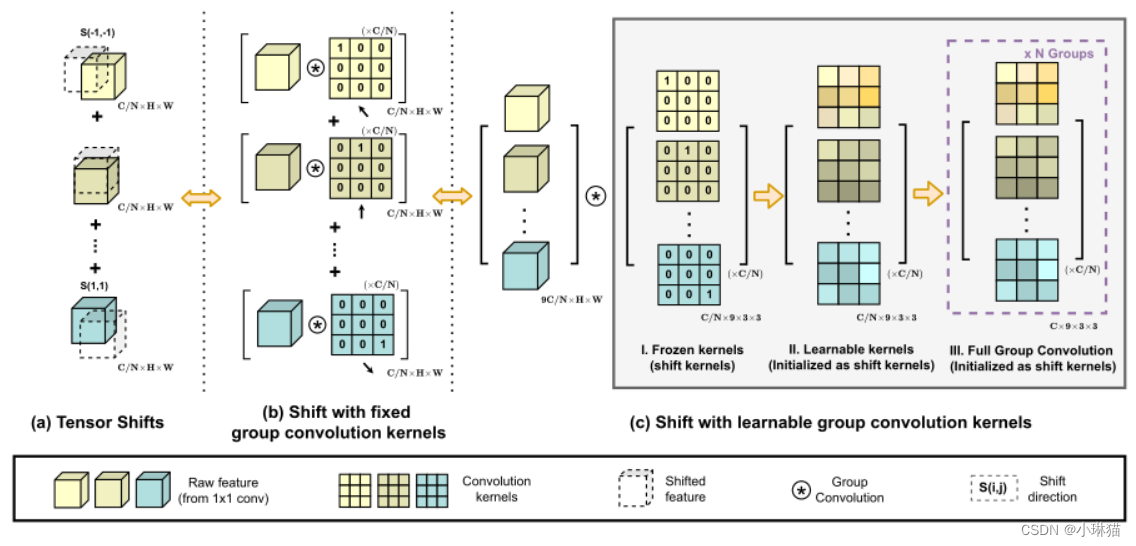
2.5卷积位移和求和阶段的改进
卷积路径中的中间特征遵循传统卷积模块中的移位和求和操作,该过程尽管理论上是轻量级的,但将张量向不同方向移动实际上打破了数据的局部性,并且难以实现向量化实现。这可能会大大削弱我们的模块在推理时的实际效率。
为此作者提出了改进的方法:使用精心设计的卷积内核群;利用可学习核和多卷积组
2.6分析ACmix的计算复杂度
阶段①的计算成本和训练参数与自注意力的相同,比传统卷积更轻。在阶段②, ACmix引入了额外的计算开销,使用轻全连接层和组卷积,其计算复杂度与通道数C线性相关,与阶段①相比较小。
2.7推广到其他注意模式
随着自注意机制的发展,许多研究都集中在探索注意力算子的变型,以进一步提高模型的性能。
①[54]提出的Patchwise attention将局部区域所有特征的信息作为注意权重,取代了原来的softmax操作。
②swing - transformer[32]采用的窗口注意对同一局部窗口内的令牌保持相同的接受域,节省计算成本,实现较快的推理速度。
③ViT和DeiT[16,42]考虑全局关注,以在单个层中保留长期依赖关系。这些修改在特定的模型体系结构下被证明是有效的。
在这种情况下,作者提出的ACmix是独立于自注意力公式的,并且可以很容易地采用在上述变体上。具体来说,注意权重可以归纳为(具体符号表示见原论文):
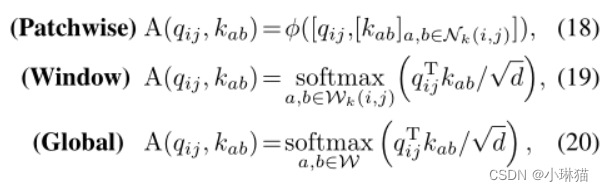
2.8路径的偏向性
ACmix引入了两个可学习的标量α, β来组合来自两条路径的输出,α和β实际上反映了模型在不同深度对卷积或自注意的偏向。
实验结果:
①不同实验的α、β的速率变化相对较小,尤其在深层时。这一观察表明,对于不同的网络设计,深度模型具有稳定的偏好。
②卷积在Transformer模型的早期阶段可以作为很好的特征提取器。在网络的中间阶段,模型倾向于利用两种路径的混合,并越来越倾向于卷积。在最后一个阶段,自注意力表现出优于卷积。
3.实验
1)ImageNet分类、语义分割和目标检测任务上实证验证ACmix,并与最先进的模型进行比较
2)实际推理速度:在Ascend 910环境下的实际推理速度,使用MindSpore,这是一个用于移动、边缘和云场景的深度学习计算框架
3)消融实验:①结合两个路径的输出②卷积核群
4)路径的偏向性
DeltaCNN: End-to-End CNN Inference of Sparse Frame Differences in Videos
本节参考CVPR 2022年收录的由格拉茨科技大学 元现实实验室发表的论文:DeltaCNN: End-to-End CNN Inference of Sparse Frame Differences in Videos,对其主要内容进行总结,以便加深理解和记忆。
论文:[2203.03996] DeltaCNN: End-to-End CNN Inference of Sparse Frame Differences in Videos (arxiv.org)
代码:facebookresearch/DeltaCNN:DeltaCNN端到端CNN对视频中稀疏帧差异的推理 (github.com)
1.降低卷积层训练成本的方法
1)通用方法
①深度可分离卷积[28]
②优化像素、通道和层数之间的比例[30]
③量化[14,20,22]
④修剪[13,18]
⑤专用硬件[5,6,12]
2)视频帧间的时间相似性
①视频帧中常见的时间相似性[1,3,9,11,16,19,23,24,27,33,34]
这些应用程序通常在固定摄像机的视频输入上使用CNN,其中帧与帧的高相似性提供了一个正交方向,以降低计算复杂性。CNN框架单独处理每一帧,因此不能利用帧到帧的相似性,通过在不变区域重复使用以前帧的结果,理论上可以大大降低计算成本[1,3,11,24]而不降低精度。
②小而不重要的更新可以被截断,以在CNN的所有层中保持高度的激活稀疏性,最终输出只有边际差异[11,24]
虽然研究人员已经表明,截断小的变化增加了稀疏性,从而在理论上减少了FLOPS,但有效地利用数据稀疏性来加速实际硬件的推理仍然是一个未解决的挑战。
2.视频帧间相似性
1)优化模型架构:高效的视频CNN架构
①降低网络中最昂贵的部分(骨干网)的处理频率。两种路径模型对关键帧使用细粒度特征生成,对中间帧使用粗粒度更新路径[9,23]。
②细粒度特征可以直接适应,例如通过使用网络输入的光流[16,34]。我们的方法不需要对网络架构进行任何更改,并在需要的地方自动执行细粒度更新。
2)截断不重要的更新来利用特征稀疏性
CNN中的数据稀疏性可以理解为特征图中的零值特征。虽然像ReLU这样的激活函数已经导致了某种程度的特征稀疏性,但视频中的稀疏性通常可以通过使用当前帧和前一帧之间的差值作为输入来增强(参见图1)。这样,背景和静态特征就变成了零,可以跳过。
这一特性在2D[1,3,11,24]和3D [25] CNN中都得到了利用。
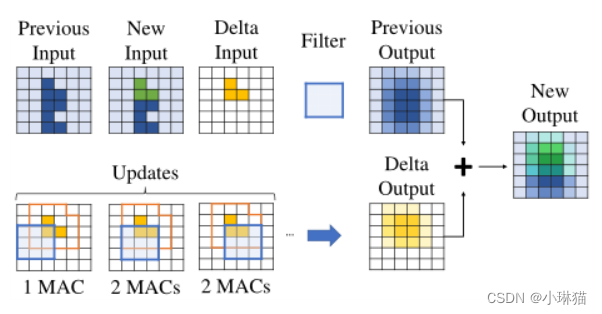
图1 视频空间稀疏卷积的工作原理。计算当前输入与之前输入的差值,卷积输入的很大一部分变为零(白色)。由于零值输入对输出没有贡献,因此可以跳过这些值以减少操作的数量
- 更新截断
①循环残差模块(RRM)[24]和CBinfer[3]表明,可以通过截断不重要的更新来进一步提高稀疏性,而不会显著损失精度。
②Skip-Convolution[11]不截断输入特征,而是截断输出特征。这可能导致更高的稀疏性,但需要定期进行密集更新(4-8帧)。
③作者将这些想法结合起来使用。像Skip-Convolution和CBInfer一样,使用空间(每像素)稀疏性,因为结构化稀疏性比每值稀疏性更适合SIMD架构。
像RRM一样,作者决定每个输入像素是否需要更新。虽然与Skip-Convolution相比,单个输入像素触发多个输出像素的更新可能会增加FLOPs,但它对于在稀疏模式下实现连续推理而不会随着时间的推移而积累错误至关重要。
- 缓存之前的状态
①RRM、CBInfer和SkipConvolution在每个卷积层缓存前一帧的输入和输出特征映射,以处理差异,增加稀疏性,然后将输出与前一帧的密集输出一起累积。所有卷积之间的运算(激活、池化)都被密集处理。虽然这种策略减少了FLOP,但它增加了内存传输。
②为了减少内存开销,[1]建议只在关键卷积层上存储输入和输出缓冲区,并且只在两者之间使用帧差。这种方法对于池化或激活函数等非线性层无效,并可能导致重大错误(见第3.1节)。
③DeltaCNN通过将输入特征(相机图像)与之前的完整输入进行比较,将稀疏特征更新传播到所有层,从而稀疏地执行所有操作,密集的结果只在最后一层积累。
④作者在上述基础上,也加速了非卷积层,如池化、上采样和激活。
此外,作者避免了稀疏计算和密集计算之间的切换,只需要缓存非线性层的累积值,与[3,11,24]相比减少了缓存数量,而不损失精度。
3.DeltaCNN
DeltaCNN,是作者提出的一种端到端的稀疏CNN框架,通过利用帧到帧的相似性来加速视频推断。DeltaCNN使用更新掩码跟踪要处理的像素,将所有稠密张量操作替换为稀疏操作。DeltaCNN用最小的网络输出变化来增加稀疏性,并且只处理每一层的稀疏帧更新。
1)增量值传播
DeltaCNN的核心特征是通过网络端到端传播稀疏帧更新,如下图所示:
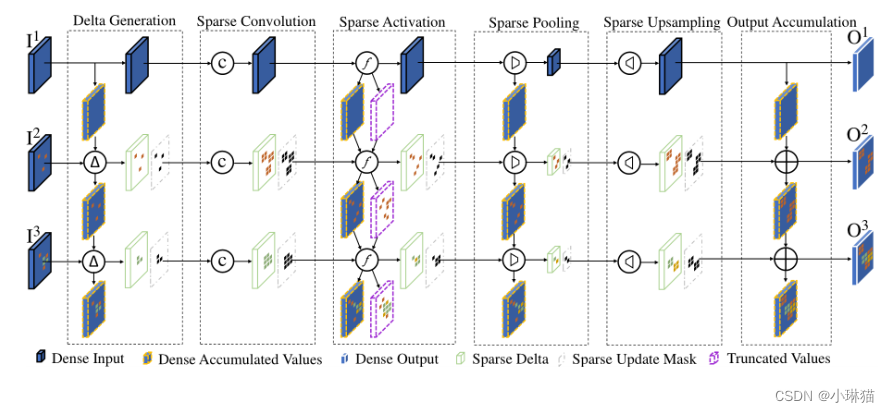
使用DeltaCNN对一个由卷积、激活、池化和上采样层组成的简单网络进行三帧推理的说明:
①第一帧I1被密集处理,并用于初始化密集累积V值的缓冲区。
②在随后的帧中,Delta Generation从当前中减去先前的输入,以生成一个更新掩码和一个仅包含重要像素更新的稀疏Delta特征映射。
③在稀疏卷积之后,导致更新掩码扩张,稀疏激活和截断截断小值以增加稀疏性。在最后一层之后,稀疏Delta输出被累积到前一个输出缓冲区上,为帧Ii生成稠密输出 O i O_i Oi
为了通过添加更新张量来重用之前帧的计算,在CNN中同时支持线性(例如卷积)和非线性(例如激活)层:
①卷积是线性算子:
c ( x + δ x ) = c ( x ) + c ( δ x ) c(x + δx) = c(x) + c(δx) c(x+δx)=c(x)+c(δx)
这允许使用两个图像之间的差,称为delta,作为卷积的输入。增量输出可以作为连续卷积的输入,而不需要在多个帧上累积增量更新。
②非线性层
大多数激活函数是非线性的,激活函数的非线性对用增量更新更新之前的结果提出了挑战,例如:
f R e L U ( − 1 ) + f R e L U ( 2 ) ≠ f R e L U ( 1 ) f_{ReLU}(−1) + f_{ReLU}(2) ≠ f_{ReLU}(1) fReLU(−1)+fReLU(2)=fReLU(1)
为了解决这一挑战,作者跟踪非线性层的累积输入。对于给定的激活或池化函数f, δ输出δy定义为:
δ y = f ( x + δ x ) − f ( x ) δy = f(x + δx) − f(x) δy=f(x+δx)−f(x)
δx是输入。差值δy被用作后续各层的δ输入。每个非线性层都存储自己的缓冲区,保存先前累积的输入。缓冲区在执行密集推理的第一帧期间初始化,并使用后续帧的增量保持最新。先前累积的输入隐含地包含了之前应用的所有偏差。因此,卷积和批归一层的偏差仅应用于第一帧。
③截断小更新
由于激活函数适用于大多数卷积层,并且需要对特征图中的每个像素进行操作,因此将激活和截断合并为一个操作有助于最小化开销。关于哪些值可以被截断的决定是在每个像素级别上做出的;我们截断一个给定的像素(将所有通道设置为0),如果 m a x k ∣ δ y k ∣ < ε max_k |δ_{y_k}| < ε maxk∣δyk∣<ε 如果任意 ∣ δ y k ∣ > ε |δ_{y_k}| > ε ∣δyk∣>ε,则像素被标记为已更新,我们使用一个累积值缓冲区 x A x^A xA来存储帧i的当前值:
x i A = x i − 1 A + δ x x^A_i = x^A_{i−1} + δx xiA=xi−1A+δx
然而,小的截断会随着时间的推移而增加,并导致每帧精度的下降。例如,当太阳缓慢升起,照亮室外场景时,帧与帧之间的差异太小,无法触发更新,并且累积的错误在删除一次后无法纠正。为了解决这个问题,我们引入了第二个缓冲区 x T x^T xT,其中包含自上次更新以来累积的截断。截断值 x T x^T xT与δ值 δ x δ_x δx和激活函数中的累积值 x A x^A xA一起使用:
δ y = f ( x A + x T + δ x ) − f ( x A ) δy = f(x^A + x^T + δx) − f(x^A) δy=f(xA+xT+δx)−f(xA)
当一个像素被截断时,δx被添加到截断值缓冲区 x T x^T xT中。当像素被标记为已更新时, x A x^A xA将使用:
x i A = x i − 1 A + x i − 1 T + δ x x^A_i = x^A_{i−1} + x^T_{i−1} + δx xiA=xi−1A+xi−1T+δx
并且截断值缓冲区xTi设置为零,如下图所示:

激活和截断函数的说明:它使用累积值执行激活,截断δ δx输出,并更新累积的xA和截断的xT值缓冲区。在这个例子中,ReLU被用作激活函数f和截断阈值 ε设置为1.5。彩色瓦片表示输入、更新状态和输出值之间的关系
使用这种技术,DeltaCNN只需要一个密集的初始帧,并且可以无限地应用稀疏更新,而不会随着时间的推移而累积错误。
2)GPU的设计考虑因素
通用GPU允许在许多核心设备上执行任意代码,理论上的指令缩减通常不能转化为有效的GPU代码。
不一致的执行路径和不连贯的内存访问可能会导致显著的速度减慢,GPU上高卷积性能的关键是优化内存访问并生成本地一致的控制流。
①更新掩码
将前一层的稀疏输出作为输入,每个层都需要知道更新了哪些像素。实现这一点的一种方法是在每一层的开始处对增量输入的所有值进行零检查,如前面的工作[3,11,24]所做。
为了避免加载和检查整个输入的更新,作者传播(与增量特征图一起)一个空间更新掩码,每个像素包含一个值,指示它是否已更新。
对于每一层,在加载任何其他数据之前,作者首先检查所有输入像素的更新掩码,并为整个平铺(平铺卷积tiled convolution)决定是否跳过所有内存操作和计算。
无论是否跳过平铺,作者都会为后续层编写更新掩码。使用更新掩码,不需要将特征映射中未处理的值初始化为零,因为它们永远不会被读取,从而进一步减少了内存带宽。
②内存考虑和平铺卷积
在2D卷积中优化内存重用和局部性的一种常见方法是以平铺形式处理图像。这样,输入特征和滤波器参数可以保持在本地并多次重复使用。tiled大小的选择是为了平衡内存访问和并行度之间的权衡。较大的平铺减少了内存访问,但需要更多的资源。
③每平铺稀疏度与子平铺稀疏度
作者在tiled层面上使用稀疏度,而不是细粒度条件。在仅更新tiled的一个像素的情况下,成本几乎与更新所有像素时一样高,因为需要加载所有滤波器参数,并且需要处理和写入多个输出像素。
④控制流程简化
为了避免细粒度的条件跳转,作者提出了一种混合内核,在三种处理模式之间进行选择:跳过、密集和非常稀疏。
3)截断更新与截断阈值选择
①DeltaCNN将像素的最大范数与阈值进行比较ε以确定像素更新是否可以被截断。
②通常,理想情况是ε将在网络甚至层之间变化。作者以从前到后的方式在子训练集上自动调整每个层的ε。作者迭代地增加ε,保持损失在预定义的误差阈值下,即,允许每个截断层对输出误差的贡献相等。
一旦找到低于此界限的最高阈值,将冻结该层的ε并按执行下一个。实验表明,*调整阈值时,还需要限制精度的提高,以避免在训练集的子集上过度拟合。
4.评估
人体姿态估计(Human3.6M[15]);目标检测(MOT16[7]和WildTrack[4])
速度;准确率;提高稳定性;阈值分析
5.讨论
平铺卷积;限制(固定相机;内存开销)
An Image Patch is a Wave: Quantum Inspired Vision MLP
本节参考2022年CVPR收录的An Image Patch is a Wave: Quantum Inspired Vision MLP,对其主要内容进行总结,以便加深理解和记忆。
论文:[2111.12294] An Image Patch is a Wave: Phase-Aware Vision MLP (arxiv.org)
代码:github 、gitee
1.视觉领域的几种研究架构
1.1CNN
卷积神经网络(CNN)长期以来一直是计算机视觉领域的主流。在[24]中给出了用于文档识别任务的CNN模型原型,其中卷积是核心操作。从ILSVRC 2012上AlexNet[23]的大获成功开始,开发了GoogleNet[36]、VGGNet[34]、ResNet[17]、RegNet[32]等多种架构。尽管为了追求高性能,模型架构变得越来越复杂,但核心操作始终是卷积及其变体。
1.2Transformer
Transformer[42]最初是为自然语言处理(NLP)任务提出的,例如语言建模和机器翻译。
1)Dosovitskiy等[9]将其引入计算机视觉,在图像分类任务中取得了出色的表现,特别是在训练数据极其充足的情况下。
2)Touvron等[41]改进了训练方法,并提出了一种专门针对变压器的teacher-student策略,该策略从头开始在ImageNet上训练产生具有竞争力的变压器模型。
随后许多研究探讨了视觉变压器的架构设计[5,12,15,37,38,44,45]。
3)Han等[15]提出了一个嵌套的变压器体系结构,以同时捕获全局和局部信息。
4)为了兼容目标检测、语义分割等密集预测任务,[9,19,43]采用了层次结构,将整个结构划分为多个阶段,合理地降低了空间分辨率阶段。
5)Swin Transformer[29]提取具有移动窗口的表示,并限制局部区域的自注意。与[9]中连接一层中所有令牌的自注意相比,移位窗口操作效率更高。
1.3MLP
近年来,由全连接层和非线性激活函数组成的类mlp架构备受关注[6,13,39]。虽然它们的架构更简单,引入的归纳偏差更少,但其性能仍然可以与SOTA模型相媲美。
1)MLP- mixer模型[39]使用了两种类型的MLP层,即信道混合MLP和令牌混合MLP。信道-MLP提取每个令牌的特征,而令牌混合MLP尝试聚合来自不同令牌的信息,以捕获空间信息。通过将这两种类型的MLP块交替堆叠,简单的MLP架构可以有足够的能力提取特征,并在视觉任务中获得良好的性能。
2)Touvron等人[40]提出了一个类似的架构,并将层归一化[2]替换为更简单的仿射变换。
3)Liu等[28]通过经验验证,在语言和视觉任务中,带门控的MLP架构可以实现与变压器相似的性能。
为了保留输入图像的位置信息
4)Hou等[20]保留输入图像的二维形状,并分别通过排列宽度和高度来提取特征。
5)Yu等[46]在MLP- mixer的基础上,用空间移位操作取代了令牌混合MLP,捕获局部空间信息,计算效率也很高。
6)目前,Lian等[25]提出沿两个正交方向移动标记来获得轴向感受野。
7)Chen等[6]提出了一种循环全连接层,该层同时混合了空间和通道维度上的信息,可以应对可变的输入图像尺度。
2.视觉MLP架构
类MLP模型是一种主要由全连通层和非线性激活函数组成的神经结构。对于视觉MLP,它首先将图像分割为多个图像块(也称为令牌),然后用两个组件提取它们的特征,即通道-FC和令牌-FC。
1)将包含n个标记的中间特征表示为 Z = [ z 1 , z 2 , ⋅ ⋅ ⋅ , z n ] Z = [z_1, z_2,···,z_n] Z=[z1,z2,⋅⋅⋅,zn],其中每个标记zj是一个d维向量。channel-FC表述为:
C h a n n e l − F C ( z j , W c ) = W c z j , j = 1 , 2 , ⋅ ⋅ ⋅ n Channel-FC(z_j, W^c) = W^cz_j, j = 1, 2, · · · n Channel−FC(zj,Wc)=Wczj,j=1,2,⋅⋅⋅n
其中 W c W_c Wc是具有可学习参数的权重。channel-FC对每个令牌进行独立操作,以提取它们的特征。为了提高转换能力,通常采用非线性激活函数将多个信道- fc层叠加在一起,从而构建信道混合MLP。
2)为了聚合来自不同令牌的信息,需要执行令牌-fc操作,即:
T o k e n − F C ( Z , W t ) j = ∑ W j k t ⊙ z k , j = 1 , 2 , . . . n Token-FC(Z, W^t)_j = \sum W^t_{jk} ⊙ z_k, j = 1, 2, ... n Token−FC(Z,Wt)j=∑Wjkt⊙zk,j=1,2,...n
其中 W t W_t Wt是令牌混合权值,⊙表示元素乘法,下标j表示第 J t h J_th Jth输出令牌。令牌-fc操作试图通过混合来自不同令牌的特征来捕获空间信息。
问题:在现有的MLP类模型中,如MLPMixer [39], ResMLP[40],也通过将令牌fc层和激活函数叠加来构造一个令牌混合MLP。这种简单的固定权重的令牌混合MLP忽略了不同输入图像中令牌语义内容的变化,这是限制类MLP体系结构表示能力的瓶颈。
3.Wave-MLP
贡献:提出了一种新的视觉MLP架构(称为Wave -MLP)
3.1启发
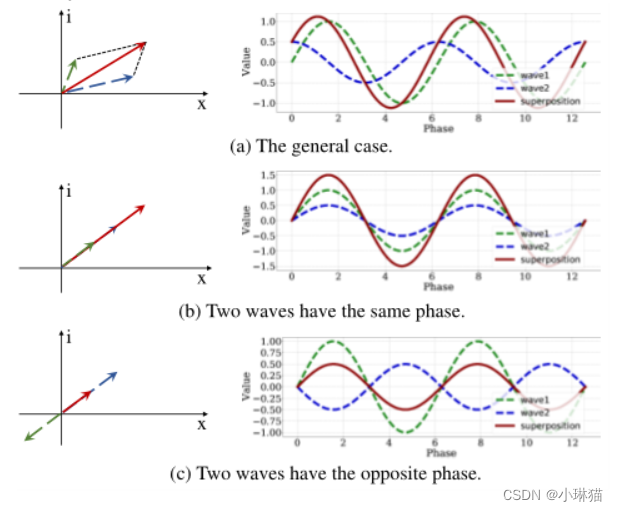
1)回想Transformer[9,42]用由注意力机制动态调整的权重聚合标记。计算不同令牌之间的内积,相似度越高的令牌在彼此的聚集过程中权重越大。
2)在量子力学中,一个实体(如电子、光子)通常由包含振幅和相位的波函数(如德布罗意波)表示[1,11,18]。振幅部分测量波的最大强度,相位部分通过指示波周期中一点的位置来调节强度。受量子力学的启发,我们将每个令牌描述为一个波,实现令牌的动态聚合过程。
3.2相位感知令牌混合模块(PATM)
PATM模块将每个令牌作为一个具有振幅和相位的波。振幅是表示每个令牌内容的实值特征,而相位是调制MLP中令牌与固定权重之间关系的单位复数,通过同时考虑振幅和相位来聚合它们。这些波状令牌之间的相位差会影响它们的聚合输出,相位接近的令牌往往会相互增强。
1)波表示
在wave - mlp中,一个令牌被表示为具有振幅和相位信息的波~ zj,即:
z ^ j = ∣ z j ∣ ⊙ e i θ j , j = 1 , 2 , . . . , n \hat z_j = |zj| ⊙ e^{iθ_j} , j = 1, 2,... , n z^j=∣zj∣⊙eiθj,j=1,2,...,n
其中i是满足 i 2 = − 1 i^2 =−1 i2=−1的虚数单位。|·|表示绝对值运算,⊙是逐元素的乘法。振幅 ∣ z j ∣ |z_j| ∣zj∣是表示每个令牌内容的实值特征。 e i θ j e^{iθ_j} eiθj是一个周期函数,其元素总是有单位范数。 θ j θ_j θj表示相位,是token在一个波周期内的当前位置。对于振幅和相位,每个令牌 z ^ j \hat z_j z^j表示在复数域中。
当聚合不同的标记时,相位 θ j θ_j θj调节它们的叠加模式。假设 z ^ r = z ^ 1 + z ^ 2 \hat z_r= \hat z_1+\hat z_2 z^r=z^1+z^2是类波令牌 z ^ 1 \hat z_1 z^1, z ^ 1 \hat z_1 z^1的聚合结果,则其振幅 ∣ z ^ r ∣ |\hat z_r| ∣z^r∣和相位 θ j θ_j θj可计算如下:
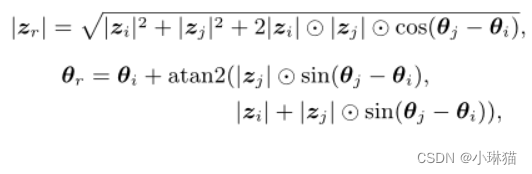
其中 a t a n 2 ( x , y ) atan2(x, y) atan2(x,y)是双参数arctan函数。如上式所示,两个令牌之间的相位差 ∣ θ j − θ i ∣ |θ_j−θ_i| ∣θj−θi∣对聚合结果 z r z_r zr的幅值影响较大。
图3显示了一个直观的图表。左边是两个波在复值域的叠加,而右边显示了它们沿实轴的投影随w.r.t的变化阶段。当两个符号具有相同的相位 ( θ j = θ i + 2 π ∗ m , m ∈ [ 0 , ± 2 , ± 4 , ⋅ ⋅ ⋅ ] ) (θj = θi + 2π * m, m∈[0,±2,±4,···]) (θj=θi+2π∗m,m∈[0,±2,±4,⋅⋅⋅])时,它们将相互增强,即 ∣ z r ∣ = ∣ z i ∣ + ∣ z j ∣ |z_r| = |z_i| + |z_j| ∣zr∣=∣zi∣+∣zj∣(图3 (b))。对于相反的相 ( θ j = θ i + π ∗ m , m ∈ [ ± 1 , ± 3 , ⋅ ⋅ ⋅ ] ) (θ_j = θ_i+π∗m, m∈[±1,±3,···]) (θj=θi+π∗m,m∈[±1,±3,⋅⋅⋅]),合成波将被削弱( ∣ z r ∣ = ∣ ∣ z i ∣ − ∣ z j ∣ ∣ |zr| = ||zi|−|zj|| ∣zr∣=∣∣zi∣−∣zj∣∣)。在其他情况下,它们的相互作用更复杂,但它们是增强还是减弱也取决于相位差(图3 (a))。请注意,只有实值特征的经典表示策略是式3的特殊情况,其相位 θ j θ_j θj仅为π的整数倍。
2)振幅
为了得到式3中的波状符号,振幅和相位信息都需要。振幅 ∣ z i ∣ |z_i| ∣zi∣与传统模型中的实值特征相似,只是有一个绝对运算。实际上,元素的绝对运算可以被吸收到相项中,即 ∣ z j , t ∣ e i θ j , t = z j , t e i θ j |z_{j,t}| e^{i θ_{j,t}} = z_{j,t}e^{iθ_j} ∣zj,t∣eiθj,t=zj,teiθj,t如果 z j , t > 0 z_{j,t} > 0 zj,t>0, ∣ z j , t ∣ e i θ j , t = z j , t e i ( θ j , t + π ) |z_{j,t}| e^{i θ_{j,t}} = z_{j,t}e^{i(θ_{j,t}+π)} ∣zj,t∣eiθj,t=zj,tei(θj,t+π),其中 z j , t z_{j,t} zj,t和 θ j , t θ_{j,t} θj,t表示 z j {z_j} zj和 θ j θ_j θj中的第t个元素。
因此,为了简单起见,我们在实际实现中删除了绝对操作。表示 X = [ x 1 , x 2 , … , x n ] X = [x_1, x_2,…, x_n] X=[x1,x2,…,xn]作为块的输入,我们通过简单的channel-FC运算得到令牌的幅值zj,即:
z j = C h a n n e l − F C ( x j , W c ) , j = 1 , 2 , ⋅ ⋅ ⋅ , n z_j = Channel-FC(x_j, W^c), j = 1, 2, · · · , n zj=Channel−FC(xj,Wc),j=1,2,⋅⋅⋅,n
3)相位
回顾阶段表示在一段波动期间令牌的当前位置,我们讨论以下生成阶段的不同策略。最简单的策略(“静态相位”)是用固定的参数来表示每个标记的相位 θ j θ_j θj,这可以在训练过程中学习。虽然静态阶段可以区分不同的标记,但它也忽略了不同输入图像的多样性。
为了分别捕获每个输入的特定属性,我们使用估计模块 Θ Θ Θ根据输入特征 x j x_j xj生成相位信息,即 Θ j = Θ ( x j , W Θ ) Θ_j = Θ(x_j, W^Θ) Θj=Θ(xj,WΘ),其中 W Θ W^Θ WΘ表示可学习参数。考虑到简单性是类MLP体系结构的一个重要特征,复杂的操作是不可取的。因此,我们也采用式1中的简单通道-fc作为相位估计模块。
4)令牌聚合
在式3中,波状符号表示在复域中。为了将其嵌入到一般的类mlp架构中,我们用欧拉公式展开它,用实部和虚部表示它,即:
z j = ∣ z j ∣ ⊙ c o s θ j + i ∣ z j ∣ ⊙ s i n θ j , j = 1 , 2 , ⋅ ⋅ ⋅ , n z_j = |z_j| ⊙ cos θ_j + i|z_j| ⊙ sin θ_j, j = 1, 2, · · · , n zj=∣zj∣⊙cosθj+i∣zj∣⊙sinθj,j=1,2,⋅⋅⋅,n
在上面的方程中,一个复值令牌被表示为两个实值向量,分别表示实部和虚部。然后用令牌-fc操作(式2)聚合不同的令牌 z ^ j \hat z_j z^j,即:
o ^ j = T o k e n − F C ( Z ^ , W t ) j , j = 1 , 2 , ⋅ ⋅ ⋅ , n \hat o_j = Token-FC(\hat Z, W^t)_j, j = 1, 2, · · · , n o^j=Token−FC(Z^,Wt)j,j=1,2,⋅⋅⋅,n
其中 Z ^ = [ ^ z 1 , ^ z 2 , ⋅ ⋅ ⋅ , ^ z n ] \hat Z = [\hat ~ z_1, \hat ~ z_2,···,\hat ~ z_n] Z^=[ ^z1, ^z2,⋅⋅⋅, ^zn]表示一层中所有的波状符号。在式8中,不同的令牌相互作用,同时考虑振幅和相位信息。输出 o ^ j \hat o_j o^j是聚合特征的复值表示。遵循常见的量子测量方法[3,21],将具有复值表示的量子态投射到实值可观测值,我们通过将 o j o_j oj的实部和虚部与权重相加来得到实值输出 o j o_j oj。结合公式8得到输出 o j o_j oj为:
o j = ∑ W j k t z k ⊙ c o s θ k + W j k i z k ⊙ s i n θ k , j = 1 , 2 , ⋅ ⋅ ⋅ , n , o_j =\sum W^t_{jk}z_k ⊙ cos θ_k + W^i_{jk}z_k ⊙ sin θ_k, j = 1, 2, · · · , n, oj=∑Wjktzk⊙cosθk+Wjkizk⊙sinθk,j=1,2,⋅⋅⋅,n,
其中 W t W_t Wt和 W i W_i Wi都是可学习权值。在上式中,相位 θ k θ_k θk根据输入数据的语义内容动态调整。除了固定的权重外,阶段还调节不同token的聚合过程。
3.3网络架构
整个Wave-MLP架构由PATM模块和信道混合MLP和归一化层交替堆叠而成。信道混合MLP由两个信道fc层和非线性激活函数叠加,对每个令牌提取特征。令牌混合块由所提出的PATM模块组成,通过考虑振幅和相位信息聚合不同的令牌。
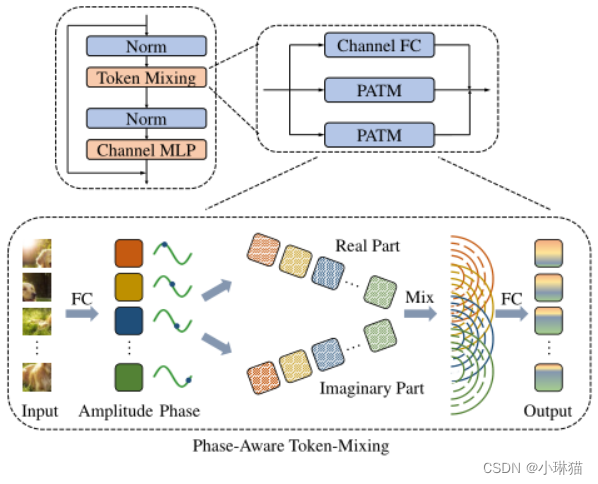
3.4成功实践
为了更好地兼容计算机视觉任务,我们使用形状为H × W × C的特征映射来保留输入图像的二维空间形状,其中H、W、C分别为高度、宽度和通道数。这是一种成功的实践,广泛应用于最近的视觉转换器架构(例如,PVT [43], SwinTransformer[29])。有两个并行的PATM模块,分别沿高维和宽维聚合空间信息。与[6,20]类似,不同分支用一个重加权模块进行求和。在传统的MLP-Mixer[39]中,每个令牌fc层将所有令牌连接在一起,令牌的维度取决于特定的输入大小。因此,它不兼容输入图像大小不同的密集预测任务(例如,目标检测和语义分割)。为了解决这个问题,我们使用了一个简单的策略,限制FC层只连接本地窗口内的令牌。窗口大小的实证研究见章节4.4的表7。除了PA TM模块外,还使用另一个通道fc直接连接输入和输出,以保存原始信息。块的最终输出是这三个分支的和。
3.5具体模型
Wave-MLP-T、Wave-MLP-S、Wave-MLP-M、Wave-MLP-B
4.实验
1)Wave MLP首先与ImageNet上现有的视觉MLP、视觉变换器和神经网络进行了比较[8],用于图像分类。
2)Wave MLP被用作两个检测器(RetinaNet[26]和Mask R-CNN[16])的主干,用于COCO数据集上的对象检测和实例分割[27]。
3)对于语义分割,采用了ADE20K[50]上广泛使用的语义FPN[22]。
4)消融实验:相位信息、相位估计模块、用于聚合令牌的窗口大小、可视化
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
本节参考CVPR 2022年收录的Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs,对其内容进行简要总结,以便加深理解和记忆。
为什么是简要总结呢?因为今天是星期五,已经做好开摆的准备了。
重新审视CNN中的大卷积核设计:将卷积核扩展到31x31
论文:[2203.06717] Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs (arxiv.org)
代码:github
1.通过ViTs审视CNN
CNN的地位受到了Vision Transformer[33,59,84,93]的极大挑战,ViTs在越来越多的视觉任务上表现领先,如上游任务:图像分类[33,104]和表示学习[3,9,15,100]等,以及目标检测[23,59]、语义分割[93,98]和图像恢复[10,54]等下游任务。
为什么ViTs如此强大?
1)人们普遍认为多头自注意(MHSA)机制在ViTs中起着关键作用。例如,先前的工作表明,与卷积相比,MHSA更灵活[50],有更少的归纳偏差[19],对扭曲更稳健[66,98],能够对长期依赖进行建模[69,88]等。
然而,最近的一些研究对MHSA的必要性提出了质疑[115],将ViTs的高性能归因于适当的构建模块[32]、动态稀疏权重[38,110]等。
2)作者关注的是CNN与Transformer另一个不同的差异:建立大范围的空间连接
在ViTs中,MHSA通常被设计为全局的[33,75,93]或具有较大的局部感受野[59,70,87] (例如≥7×7),因此单个MHSA层的每个输出都能够从一个相对较大的区域收集信息。
大卷积核在CNN中并不常用(除了第一层[40]),通常是使用许多小空间卷积的堆叠[40,44,47,68,74,79,108] (例如,3×3)来扩大CNN中的感受野。只有一些传统的网络,如AlexNet[53]、inception[76-78]以及一些从神经架构搜索衍生出来的架构[37,43,56,116]采用了大卷积核(大于5)作为主要部分。
由此作者提出了一个问题:如果在传统的CNN中引入几个大卷积核会怎样?大卷积核是弥补性能差距的关键吗?
2.相关工作
1)具有大卷积核的模型
正如前面提到的,除了inception[76-78]等少数传统模型,大内核模型在VGG-Net[74]之后就不再流行了
①Global Convolution Networks, GCNs[67]使用1×K和K×1的非常大的卷积来改进语义分割任务。
②有研究表明,大型内核会损害ImageNet的性能。LRNet[45]提出了一个空间聚合算子(LRLayer)来取代标准卷积,它可以被视为一个动态卷积。LR-Net可以从7×7大小的内核中受益,但如果使用9×9,性能会下降。当内核大小与特征图一样大时,top-1的精度显著降低,从75.7%下降到68.4%。
③最近,Swin transformer[59] 提出了用移动窗口注意力来捕捉空间模式,窗口大小从7到12不等,也可以看作是大内核的一种变体。
④后续研究如[31,58]甚至采用更大的窗口尺寸来获得更好的性能。
⑤受这些transformer成功的启发,最近的一项工作[38]在[59]中使用静态或动态7×7深度卷积替换MHSA层,同时仍然保持可比的结果。
[38]没有研究大卷积核和性能之间的关系,它将ViTs的优越性能归因于稀疏连接、共享参数和动态机制。
⑥另一项代表性工作是Global Filter Networks, GFNets[71]。GFNet优化了傅里叶域中的空间连接权值,相当于空间域中的圆形全局卷积。尽管GFNet隐式地引入了非常大的卷积核(与整个特征映射一样大),但与传统的CNN相比,它并没有探索更多的属性。
此外,[38]和[71]都没有在baseline上评估他们的模型,因此,目前尚不清楚大卷积核CNN是否能像ViTs一样扩展。
⑦ConvMixer[85]使用高达9×9的卷积来取代ViTs[33]的“混合器”组件或MLP[82,83]。
⑧MetaF ormer[103]建议用池化层代替自注意力模块。
⑨ConvNeXt[60]采用7×7深度卷积来设计强大的架构,突破了CNN性能的极限。
尽管这些研究表现出了出色的性能,但它们并没有说明更大卷积(例如,31×31)的好处。
2)模型缩放技术
对于一个小型模型,通常的做法是将其扩展以获得更好的性能,因此扩展策略在最终的精度-效率权衡中发挥着至关重要的作用。对于CNN,现有的缩放方法通常关注模型深度、宽度、输入分辨率[30,68,79]、bottleneck ratio和group width[30,68]。
然而,卷积核大小常常被忽略。作者表示卷积核大小也是CNN中一个重要的缩放维度,特别是对于下游任务。
3) Structural Re-parameterization
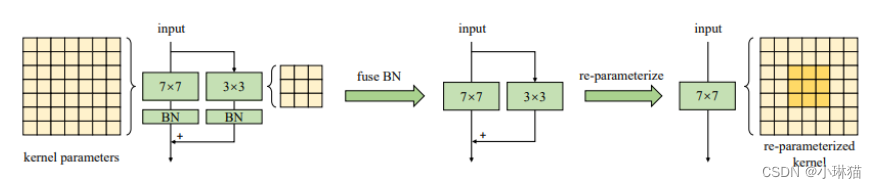
Structural Re-parameterization[25-29]是一种通过转换参数等价地转换模型结构的方法。
①例如,RepVGG针对的是一个深度推理时类VGG(无分支)模型,并在训练过程中构建了额外的RestNet风格的shortcut与3×3层卷积并行地进行训练。这样的shortcut方式帮助模型达到了令人满意的性能。训练结束后,通过一系列线性变换将shortcut合并到并行的3×3内核中。
作者使用这种方法将一个相对较小的卷积核(例如3×3或5×5)添加到一个非常大卷积核中。通过这种方式,使非常大的卷积核能够捕获小范围的模式,从而提高了模型的性能。
3.应用大卷积核的指南
简单地将大卷积应用到CNN上通常会导致性能和速度较差。作者通过实验总结了有效使用大型内核的5条指导原则并进行了解释(具体参考原论文)
1)大内核深度卷积在实践中是有效的
作者通过实验表明当卷积核变大时,计算的实际耗时并不会像理论FLOPs那样增加,增加的计算量是可接受的,并且与深度学习框架密切相关。
2)identity shortcut方式至关重要,尤其是对于具有常大卷积核的网络
3)用小内核重新参数化[29]有助于弥补优化问题
4)大卷积更能促进下游任务
5)大卷积核(例如13×13)在小特征映射(例如7×7)上也很有用
4.RepLKNet:一种大卷积核架构
RepLKNet由主干、Stem和Transition组成。除了(DW)大卷积核外,其他组件包括DW 3×3、密集1×1卷积和批归一化BN。每个卷积层后面都有一个BN。除了shortcut方式之前,这类Conv - BN序列使用ReLU作为激活函数。(具体网络各层的设计动机见原文)
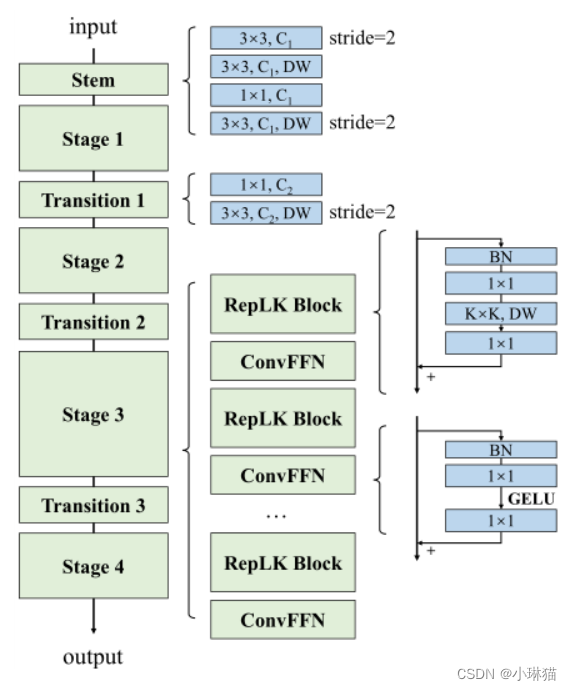
5.实验
1)使用更大的卷积核,从3×3到31×31
2)ImageNet分类
3)语义分割
4)目标检测
6.讨论
1)大核神经网络具有比DW核模型更大的ERFS
2)大核模型的形状偏好更接近人类
形状偏好与纹理偏好
3)扩张卷积
扩展卷积作为实现大核卷积的一种替代方法,是增加感受野的常用组件。实验表明,尽管深度扩张卷积具有与深度密集卷积相同的最大RF,但其表示能力要低得多,因为扩张卷积数学上等同于稀疏大核卷积。[92,98]进一步表明,扩张卷积可能存在网格化问题。作者认为扩张卷积的缺点可以通过不同扩张卷积的混合来克服,这将在未来进行研究。
4)局限性
大卷积核设计提高了CNN在ImageNet和下游任务上的性能,但是实验表明,随着数据和模型规模的增加,模型精度会有所下降,下降的原因未知需进一步研究。
A Survey on 3D Skeleton-Based Action Recognition Using Learning Method
本节参考CVPR2022年发布的基于深度学习的3D骨架行为识别综述:A Survey on 3D Skeleton-Based Action Recognition Using Learning Method,对其主要内容进行总结,以便加深理解和记忆。
1.概念
1.1行为识别
1)行为识别背景
行为识别是CV领域重要的组成部分和最活跃的研究课题,已被研究了几十年。
2)为何进行行为识别
由于行为可以被人类用来处理事务和表达情感,因此识别某种行为可以被广泛应用于近年来尚未完全解决的应用领域,如智能监控系统、人机交互、虚拟现实、机器人技术等。
3)如何进行行为识别(通过什么样结构的数据进行学习)
①通常,图像序列、深度图像序列、视频、某种特定形式的光流,或这些模态的某种融合形式(如图像序列 + 光流)在行为识别任务中应用,并通过多种技术取得了良好的效果
②基于骨架序列的行为识别
①相较于②而言的计算量较大,当面对复杂的背景、随着身体尺度、视点和移动速度变化时也不那么健壮
1.2 3D骨架序列
1)何为骨架序列
骨架序列是一种具有关节和骨骼的人体拓扑表示
2)骨架序列的优势
①空间信息方面,关节节点与其相邻节点之间存在较强的相关性,从而可以在骨架序列中以框架内的方式获取丰富的身体结构信息
②时间信息具有帧间性,具有较强的时间相关性
③考虑关节和骨架时,空间和时间共现性
3)基于骨架序列的传统研究方式
基于骨架序列的行为识别主要是一个时序问题,传统的基于骨架的方法通常希望从特定的骨架序列中提取运动模式。这导致了对手工特征的广泛研究,其中经常使用各种关节或身体部位之间的相对3D旋转和平移。
然而,已经证明,手工特征只能在某些特定数据集上表现良好,即手工制作的用于一个数据集的特征可能无法转移到另一个数据集中,这个问题将使动作识别算法难以推广或应用于更广泛的应用领域。
2.相关工作
现有的大多数综述工作只关注传统技术或基于深度学习方法的图像或深度图像数据的方法,忽略了使用骨架序列时基于CNN、基于RNN以及基于GCN的方法之间的差异和动机。
1)Ronald Poppe[32]首先阐述了这个领域的基本挑战和特点,然后详细阐述了关于直接分类的基本分类方法和时间-空间状态模型的基本行为分类方法
2)丹尼尔和雷米仅在空间和时间领域对行为表示进行了全面的概述[33]
3)最近,[34]和[35]对基于深度学习的视频分类和字幕任务进行了总结,其中介绍了CNN和RNN的基本结构,后者阐明了常见的深度架构和用于动作识别的定量分析
4)据我们所知,[36]是最近对基于3D骨骼的动作识别进行深入研究的第一项工作,该研究从动作表示到分类方法得出了这一问题的结论,同时,它还提供了一些常用的数据集,如UCF、MHAD、MSR每日活动3D等[37]–[39],但它没有涵盖基于emgerging GCN的方法
5)最后,[27]提出了一个基于Kinect数据集的动作识别算法的新综述,该综述组织了基于Kinect的技术与各种数据类型(包括图像、深度、图像+深度和骨架序列)的彻底比较
3.基于深度学习的3D骨架行为识别
3.1一般流程
1)如何获取3D骨架数据:直接通过深度传感器获取、通过姿态估计算法获得
2)3D骨架数据被送入RNN、CNN、GCN网络
3)进行行为分类

3.2基于RNN的方法
对于基于RNN的方法,骨架序列是关节坐标位置的自然时间序列,可以看作序列向量,而RNN本身由于其独特的结构适合于处理时间序列数据。此外,为了进一步改进骨架序列的时间上下文学习,已经采用了一些其他基于RNN的方法,如长短期记忆(LSTM)和门控递归单元(GRU)来进行基于骨架的行为识别。
角度Ⅰ:时空建模
时空建模是行为识别的首要任务,由于基于RNN的架构的空间建模能力较弱,一些相关方法的性能一般无法获得具有很好的结果。
1)最近,Hong和Liang[44]提出了一种新的双流RNN体系结构,对骨架数据的时间动态和空间配置进行建模。交换骨架轴用于空间域学习的数据级预处理。
①两个流框架,通过添加一个新流来增强空间信息:

2)与[44]不同,Jun和Amir[45]采用了给定骨架序列的遍历方法来获取两个域(时空)的隐藏关系。
与一般方法将关节按简单链排列而忽略相邻关节间的动力学依赖关系相比,其提出的基于树结构的遍历方法不会在关节间关系不够强的情况下增加错误的连接。
然后,使用LSTM对输入进行判别处理,如果输入单元是可靠的,则通过导入输入潜在空间信息来更新存储单元。受CNN特性的启发,它非常适合空间建模。
3)Chun yu和Bao chang[46]采用了注意RNN和CNN模型,便于复杂时空建模。首先在剩余学习模块中引入时间注意模块,对骨架序列中的帧进行时间注意校正,然后在剩余学习模块中引入时空卷积模块,将校正后的关节序列作为图像处理。
4)此外,[47]采用了一种注意循环关系LSTM网络,利用循环关系网络获取空间特征,采用多层LSTM学习骨架序列中的时间特征。
角度Ⅱ:网络结构
网络结构可以看作是RNN的一个弱点驱动方面。虽然RNN的性质适合于序列数据,众所周知的梯度爆炸和消失问题是不可避免的。
1)为此,提出了几种新型RNN体系结构[48] - [50], Shuai和Wanqing[50]提出了一种独立的递归神经网络,可以解决梯度爆炸和消失的问题,通过它可以更鲁棒地构建更长的、更深入的高语义特征学习RNN。
这种改进不仅可以应用于基于骨架的动作识别,还可以应用于语言建模等其他领域。在这种结构中,一层神经元彼此独立,因此它可以用于处理更长的序列。
角度Ⅲ:数据驱动
1)考虑到动作分析中并非所有关节都是有信息的,[51]在LSTM网络中添加了全局上下文感知关注,该网络选择性地关注骨架序列中的有信息的关节。
下图展示了所提出方法的可视化效果,从图中我们可以得出结论,信息更丰富的关节用红色圈的颜色区域表示,这表明这些关节对该特殊动作更重要。
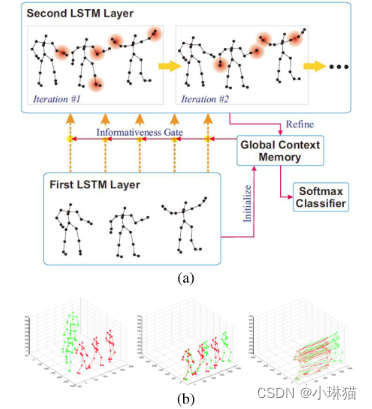
图(a)表示不同关节对于给定骨骼动作的不同重要性
图(b)给出a特征的表示过程,从左到右分别为原始输入骨架帧、变换后的输入帧和提取的显著运动特征
此外,由于数据集或深度传感器提供的骨架并不完美,这将影响动作识别任务的结果,因此[52]首先将骨架转换为另一个坐标系,使其具有缩放、旋转和平移的鲁棒性,然后从转换后的数据中提取显著的运动特征,而不是将原始骨架数据发送给LSTM。
3.3基于CNN的方法
卷积神经网络也被应用于基于骨骼的行为识别。与RNN不同,CNN模型具有天生的优秀高级信息提取能力,能够高效、轻松地学习高级语义线索。
基于CNN的方法通常将一个骨架序列表示为图像,将时间动态和骨架关节分别简单地编码为行和列,这样只会考虑卷积核内相邻的关节来学习共现特征,也就是说,可能会忽略一些与所有关节相关的潜在相关性,因此CNN无法学习到相应的有用特征。
CNN一般专注于基于图像的任务,基于骨架序列的动作识别任务无疑是一个严重的时间依赖问题。因此,如何在基于CNN的架构中平衡和更充分地利用空间和时间信息仍然是一个挑战。
除了三维骨架序列的表示,基于CNN的技术还存在一些其他问题,如模型[3]的大小和速度,CNN的架构(两流或三流[62]),遮挡,视点变化等[2],[3]。因此,使用CNN进行基于骨骼的动作识别仍然是一个有待研究人员深入研究的开放问题。
1)通常,为了满足CNN输入的需要,将三维骨架序列数据从矢量序列转换为伪图像。然而,同时具有空间和时间信息的相关表示通常并不容易,因此许多研究人员将骨骼关节编码为多个二维伪图像,然后将其输入CNN,以学习有用的特征[53],[54]。
2)Wang[55]提出了关节轨迹图(Joint Trajectory Maps, JTM),通过彩色编码将关节轨迹的空间构型和动态表现为三张纹理图像。但这种方法比较复杂,在映射过程中也失去了重要意义。
3)为了克服缺点2),Bo和Mingyi[56]采用平移尺度不变图像映射策略,首先根据人体物理结构将每帧人体骨骼关节划分为5个主要部分,然后将这些部分映射到2D形式。
该方法使骨架图像同时包含时间信息和空间信息。然而,虽然性能得到了提高,但没有理由把骨骼关节作为孤立的点,因为在现实世界中,我们的身体之间存在着密切的联系,例如,在挥手时,不仅要考虑到直接在手上的关节,肩膀和腿等其他部位也相当多。
4)Yanshan和Rongjie[57]提出了几何代数的形状运动表示方法,充分利用了骨骼序列提供的信息,同时考虑了关节和骨骼的重要性。同样,[2]也使用增强的骨骼可视化来表示骨骼数据。
5)Carlos和Jessica[58]还提出了一种名为SkeleMotion的基于运动信息的新表示,该表示通过显式计算骨骼关节的大小和方向值来编码时间动力学。
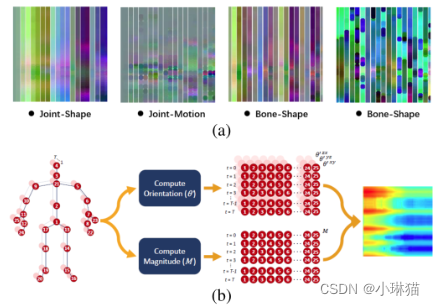
图5(a):[57]提出的形状-运动表示
图5(b):SkeleMotion表示
6)Chao和Qiaoyong[61]利用端到端框架,采用分层方法学习共同色彩特征,在这种方法中,不同级别的上下文信息逐渐聚合。首先对点级信息进行独立编码,然后将点级信息组合成时间域和空间域的语义表示。
3.4基于GCN的方法
基于GCN方法的灵感来自于人类3D骨架序列是一个天然的拓扑图,而不是基于RNN或基于CNN的方法处理的序列向量或伪图像。近年来,由于图结构数据的有效表示,图卷积网络被广泛应用于该任务中。
目前与图相关的神经网络通常有两种,即图循环神经网络(GNN)和图卷积神经网络(GCN),该综述主要关注后者。
从骨架的角度来看,仅仅将骨架序列内化为序列向量或二维网格,并不能完全表达相关节点之间的依赖关系。图卷积神经网络作为CNN的一种推广形式,可以应用于包括骨架图在内的任意结构。
基于GCN技术的最重要问题仍然与骨架数据的表示有关,即如何将原始数据组织成特定的图。
1)Sijie和Yuanjun[31]首次提出了一种基于骨骼的动作识别新模型——时空图卷积网络(ST-GCN),该模型首先以关节为图点,以人体结构和时间的自然连接为图边,构造了一个时空图。
之后,从ST-GCN到图上的更高层次的特征映射将由标准的Softmax分类器分类到crooresponcation类别。基于此,利用GCN进行基于骨骼的动作识别受到了广泛的关注,近年来也开展了大量相关的研究工作。
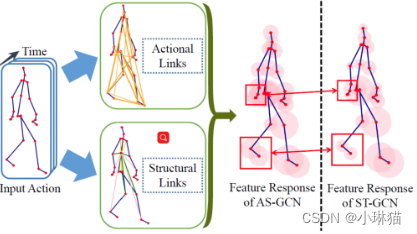
2)最常见的研究集中在骨架数据的高效利用上[68],[78],Maosen和Siheng[68]提出了动作结构图卷积网络(ActionStructural Graph Convolutional Networks, AS-GCN)不仅可以识别一个人的动作,还可以使用多任务学习策略输出对被试下一个可能姿势的预测。
这项工作中构建的图可以通过两个称为“动作链接”和“结构链接”的模块来捕捉关节之间更丰富的相关性。
下图显示了AS-GCN的特征学习及其广义骨架图:
4.最新数据集和性能
骨架序列数据,如MSRAAction3D[79]、3D Action Pairs[80]、MSR Daily Activity3D[39]等。所有这些数据都在大量综述[27]、[35]、[36]中进行了分析。
因此该综述主要讨论了以下两个数据集:NTURB+D[22]和NTU-RGB+D120[81]
1)介绍
NTU-RBG+D数据集于2016年提出,包含由Microsoft Kinect v2收集的56880个视频样本是基于骨架的动作识别的最大数据集之一。它为每个人在一个动作中提供25个关节的三维空间坐标。
为了获得对建议方法的评估,建议使用两种方案:C-S和C-V
①对于C-S,包含40320个样本和16560个样本用于训练和评估,将40个受试者平分为训练组和评估组。
②对于C-V,包含37920和18960个样本,使用相机2和相机3用于训练,使用相机1用于评估。
最近,原始NTU-RGB+D的扩展版也被提出,被称为NTU-RGB+D120,包含120个动作类和114480个骨架序列,其视点也是155个。
2)Top10行为识别方法
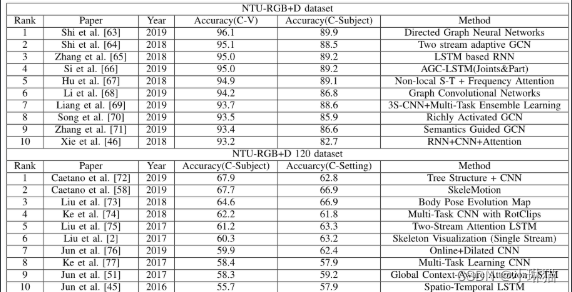
现有算法在原始数据集中获得了优异的性能,而在NTU-RGB+D120仍然是一个需要克服的挑战。