1.激活函数
(1)阶跃型激活函数: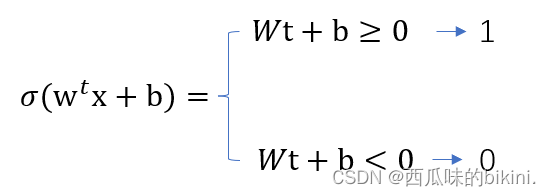
(2)sigmod型激活函数: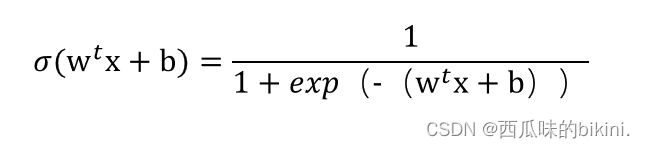
2.损失函数 softmax loss:①softmax②cross-entroy loss 组合而成的损失函数
用来评测模型预测值f(x)与真实值y的相似程度,损失函数越小,模型鲁棒性越好,损失函数指导模型学习。根据损失函数来做反向传播修改模型参数。机器学习的目的是学习一组参数,使预测值与真值无限接近。
(1)softmax
z:某个神经网络全连接层输出的一组结果,例如分类问题,做4分类,z为1*4向量
j:0~3下标号
zk:全连接层第k个值
全连接输出的向量z值无大小限制,(1)将其限制为0-1之间,变为概率值
(2)cross-entroy loss 交叉熵损失函数 (交叉熵:作为损失函数好处,使用sigmod函数在梯度下降时避免均方误差损失函数学习速率降低问题)
即为
即为softmax函数输出值
yc为样本真值
与真值越接近,损失函数越小,与真值相对越远,损失函数越大
优化过程:不断提升与真值接近概率,降低损失函数
(3)交叉熵做损失函数
①信息量
②信息熵
③相对熵(KL散度)
同一个随机变量x又两个单独概率分布p(x),q(x)
可使用kl散度来衡量两个概率分布之间差异
④交叉熵
判定实际输出分布于期望输出分布接近程度:最小化交叉熵
⑤均方误差损失函数(MSE)