学习视频:
YOLOV7改进-具有隐式知识学习的Efficient解耦头_哔哩哔哩_bilibili
改进的部分代码:
objectdetection_script/yolov7-DecoupledHead.py at master · z1069614715/objectdetection_script (github.com)为了方便我直接复制过来。
class IDetect_Decoupled(nn.Module):
stride = None # strides computed during build
export = False # onnx export
end2end = False
include_nms = False
concat = False
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(IDetect_Decoupled, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m_stem = nn.ModuleList(Conv(x, x, 1) for x in ch) # stem conv
self.m_cls = nn.ModuleList(nn.Sequential(Conv(x, x, 3), nn.Conv2d(x, self.na * self.nc, 1)) for x in ch) # cls conv
self.m_reg_conf = nn.ModuleList(Conv(x, x, 3) for x in ch) # reg_conf stem conv
self.m_reg = nn.ModuleList(nn.Conv2d(x, self.na * 4, 1) for x in ch) # reg conv
self.m_conf = nn.ModuleList(nn.Conv2d(x, self.na * 1, 1) for x in ch) # conf conv
self.ia_cls = nn.ModuleList(ImplicitA(x) for x in ch)
self.ia_reg = nn.ModuleList(ImplicitA(x) for x in ch)
self.ia_conf = nn.ModuleList(ImplicitA(x) for x in ch)
self.im_cls = nn.ModuleList(ImplicitM(self.nc * self.na) for _ in ch)
self.im_reg = nn.ModuleList(ImplicitM(4 * self.na) for _ in ch)
self.im_conf = nn.ModuleList(ImplicitM(1 * self.na) for _ in ch)
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m_stem[i](x[i]) # conv
bs, _, ny, nx = x[i].shape
x_cls = self.im_cls[i](self.m_cls[i](self.ia_cls[i](x[i]))).view(bs, self.na, self.nc, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
x_reg_conf = self.m_reg_conf[i](x[i])
x_reg = self.im_reg[i](self.m_reg[i](self.ia_reg[i](x_reg_conf))).view(bs, self.na, 4, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
x_conf = self.im_conf[i](self.m_conf[i](self.ia_conf[i](x_reg_conf))).view(bs, self.na, 1, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
x[i] = torch.cat([x_reg, x_conf, x_cls], dim=4)
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
def fuseforward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m_stem[i](x[i]) # conv
bs, _, ny, nx = x[i].shape
x_cls = self.m_cls[i](x[i]).view(bs, self.na, self.nc, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
x_reg_conf = self.m_reg_conf[i](x[i])
x_reg = self.m_reg[i](x_reg_conf).view(bs, self.na, 4, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
x_conf = self.m_conf[i](x_reg_conf).view(bs, self.na, 1, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
x[i] = torch.cat([x_reg, x_conf, x_cls], dim=4)
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
if not torch.onnx.is_in_onnx_export():
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else:
xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
xy = xy * (2. * self.stride[i]) + (self.stride[i] * (self.grid[i] - 0.5)) # new xy
wh = wh ** 2 * (4 * self.anchor_grid[i].data) # new wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, -1, self.no))
if self.training:
out = x
elif self.end2end:
out = torch.cat(z, 1)
elif self.include_nms:
z = self.convert(z)
out = (z, )
elif self.concat:
out = torch.cat(z, 1)
else:
out = (torch.cat(z, 1), x)
return out
def fuse(self):
print("IDetect.fuse")
# fuse ImplicitA and Convolution
for i in range(len(self.m_cls)):
c1,c2,_,_ = self.m_cls[i][-1].weight.shape
c1_,c2_, _,_ = self.ia_cls[i].implicit.shape
self.m_cls[i][-1].bias += torch.matmul(self.m_cls[i][-1].weight.reshape(c1,c2),self.ia_cls[i].implicit.reshape(c2_,c1_)).squeeze(1)
for i in range(len(self.m_reg)):
c1,c2,_,_ = self.m_reg[i].weight.shape
c1_,c2_, _,_ = self.ia_reg[i].implicit.shape
self.m_reg[i].bias += torch.matmul(self.m_reg[i].weight.reshape(c1,c2),self.ia_reg[i].implicit.reshape(c2_,c1_)).squeeze(1)
for i in range(len(self.m_conf)):
c1,c2,_,_ = self.m_conf[i].weight.shape
c1_,c2_, _,_ = self.ia_conf[i].implicit.shape
self.m_conf[i].bias += torch.matmul(self.m_conf[i].weight.reshape(c1,c2),self.ia_conf[i].implicit.reshape(c2_,c1_)).squeeze(1)
# fuse ImplicitM and Convolution
for i in range(len(self.m_cls)):
c1,c2, _,_ = self.im_cls[i].implicit.shape
self.m_cls[i][-1].bias *= self.im_cls[i].implicit.reshape(c2)
self.m_cls[i][-1].weight *= self.im_cls[i].implicit.transpose(0,1)
for i in range(len(self.m_reg)):
c1,c2, _,_ = self.im_reg[i].implicit.shape
self.m_reg[i].bias *= self.im_reg[i].implicit.reshape(c2)
self.m_reg[i].weight *= self.im_reg[i].implicit.transpose(0,1)
for i in range(len(self.m_conf)):
c1,c2, _,_ = self.im_conf[i].implicit.shape
self.m_conf[i].bias *= self.im_conf[i].implicit.reshape(c2)
self.m_conf[i].weight *= self.im_conf[i].implicit.transpose(0,1)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
def convert(self, z):
z = torch.cat(z, 1)
box = z[:, :, :4]
conf = z[:, :, 4:5]
score = z[:, :, 5:]
score *= conf
convert_matrix = torch.tensor([[1, 0, 1, 0], [0, 1, 0, 1], [-0.5, 0, 0.5, 0], [0, -0.5, 0, 0.5]],
dtype=torch.float32,
device=z.device)
box @= convert_matrix
return (box, score)
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
if isinstance(m, IDetect):
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b.data[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
elif isinstance(m, IDetect_Decoupled):
for mi, s in zip(m.m_conf, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b.data += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
for mi, s in zip(m.m_cls, m.stride): # from
b = mi[-1].bias.view(m.na, -1) # conv.bias(255) to (3,85)
b.data += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi[-1].bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
if isinstance(m, IDetect_Decoupled):
s = 256 # 2x min stride
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
check_anchor_order(m)
m.anchors /= m.stride.view(-1, 1, 1)
self.stride = m.stride
self._initialize_biases() # only run once
# print('Strides: %s' % m.stride.tolist())插入一条快捷方式:直接ctrl+f搜索
首先将链接中代码第1-150行复制,粘贴在model文件夹下的yolo.py文件的,第208行,如下图
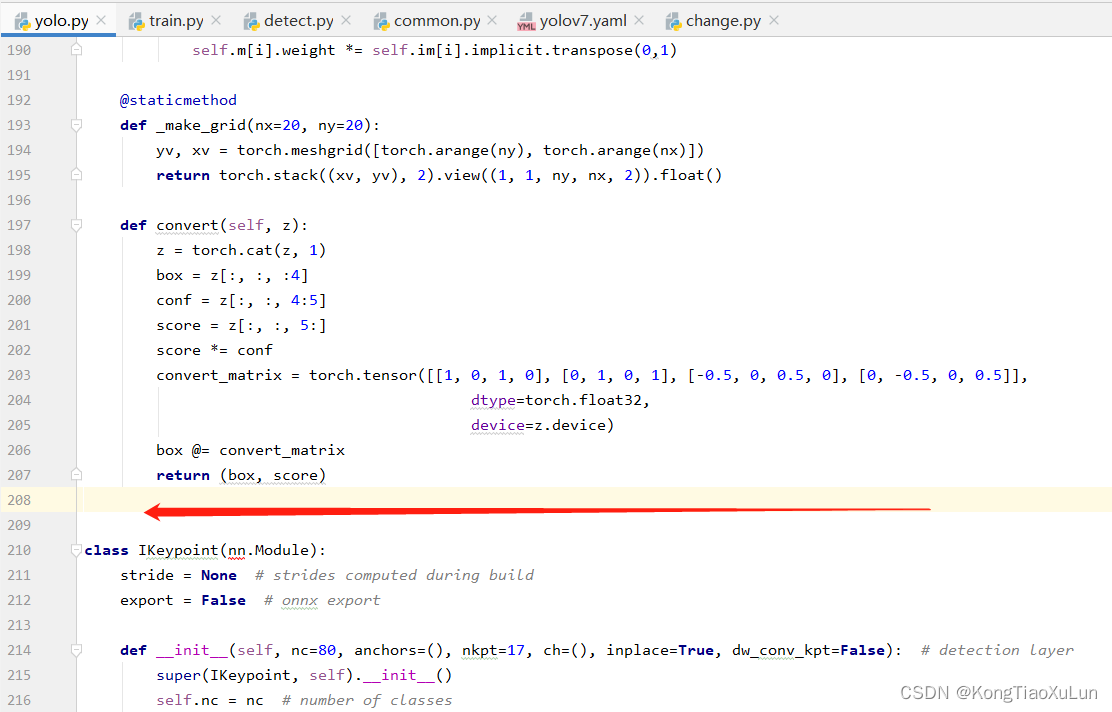
然后将链接中代码152-172代码,替换yolo.py中如下图模块
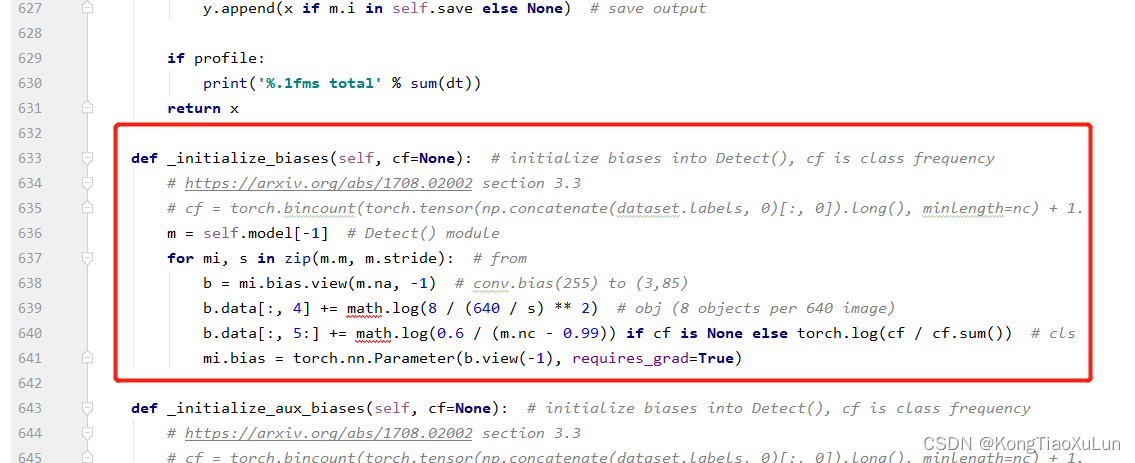
最后将链接中代码174-181行,添加到yolo.py位置如下图
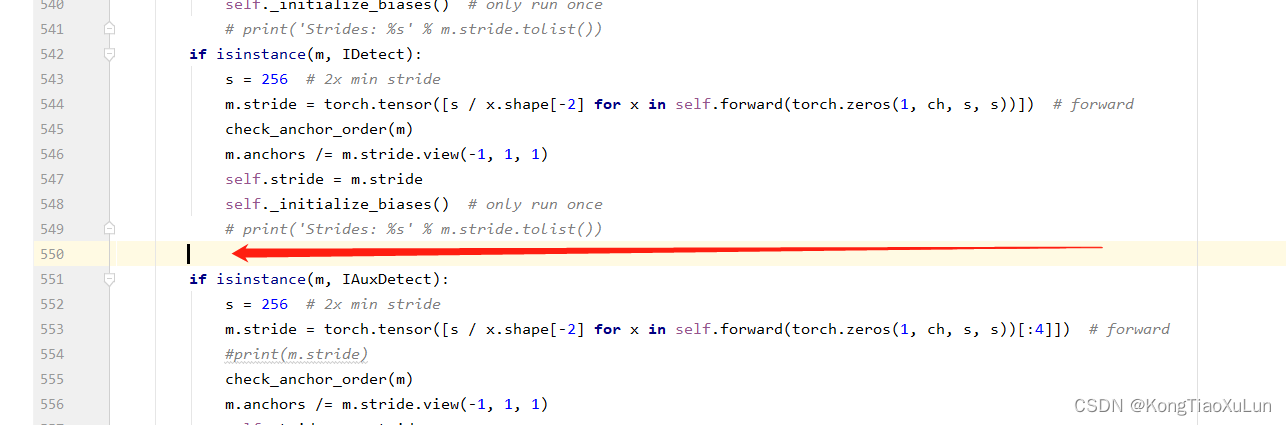 接下来修改forward_once
接下来修改forward_once
修改前: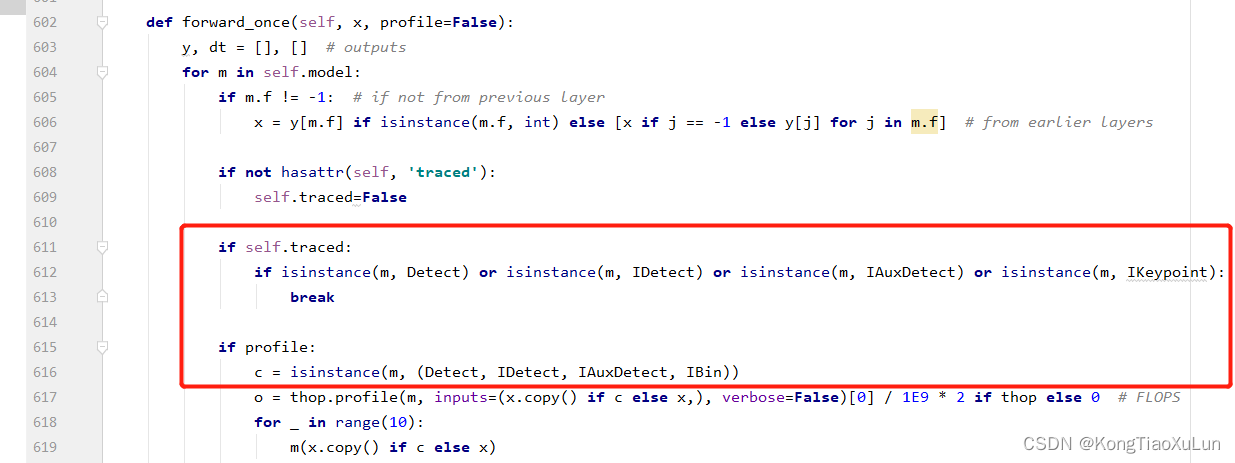
修改后:新增蓝框内容
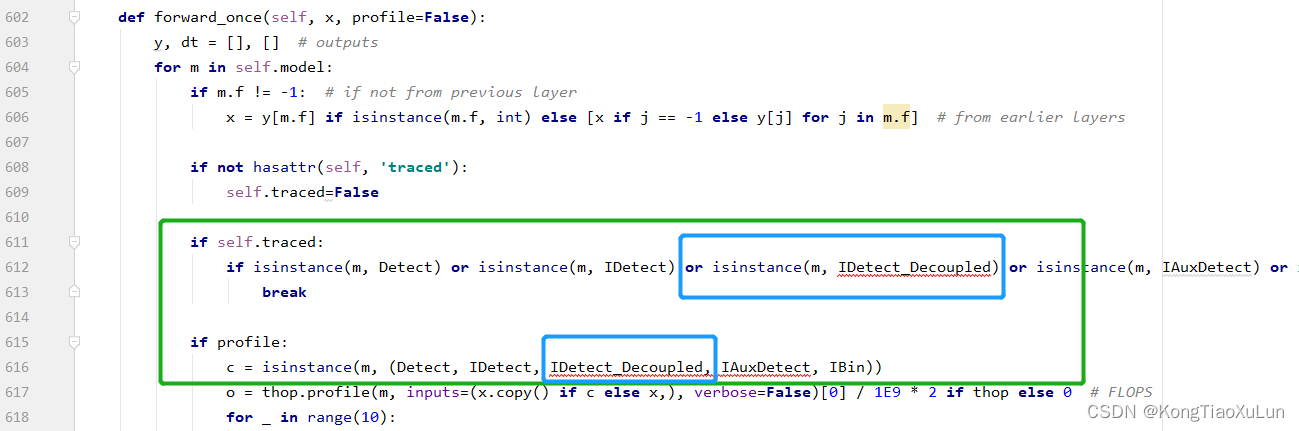
接下来修改:
修改前:
 修改后:新增绿框内容
修改后:新增绿框内容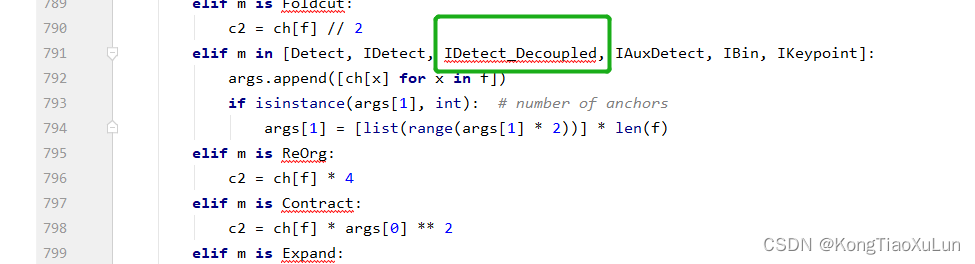
最后一步:
用哪个cfg的yaml文件,就把哪个文件最后一行的头改成IDetect_Decoupled,

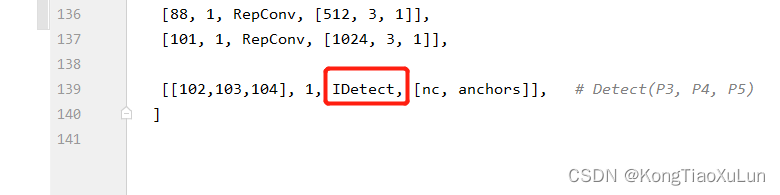
改完就可以训练了,对比修改前看看精度高了没