python 3之后,爬虫相对来说简单一些。主要会用到requests和beautifulsoup库,reuqests代替浏览器发送http请求并返回内容,返回的内容之前都是用正则表达式处理,当然现在也可以,不过现在beautifulsoup库用得比较多。beautifulsoup处理html标签,用得最多的是find、find_all、select函数。
一、研究网页结构
网址:https://www.qidian.com/rank/yuepiao?chn=-1&page=1
我用的是chrome浏览器,打开网址,鼠标右键选择“检查”,然后刷新。headers主要是头部信息,preview是页面的结构,主要是根据headers来写requests,分析preview找到自己要爬取的信息然后来写beautifulsoup。
二、爬取第一页内容
在preview里面,我找到了要爬取的信息都在rank-view-list这个标签,所以剩下就很简单了,定位到相应的标签即可。
res=requests.get('https://www.qidian.com/rank/yuepiao?chn=-1&page=1')
soup=BeautifulSoup(res.text,'html.parser')
for news in soup.select('.rank-view-list li'):
print({'title':news.select('a')[1].text,'name':news.select('a')[2].text,'style':news.select('a')[3].text,'describe':news.select('p')[1].text,'lastest':news.select('p')[2].text})

三、循环爬取25页的内容
因为url的前面都没有变化,只需要更改page后面的参数就好,所以加一个循环,完整代码如下:
import requests from bs4 import BeautifulSoup newsary=[] for i in range(25): res=requests.get('http://r.qidian.com/yuepiao?chn=-1&page='+str(i+1)) soup=BeautifulSoup(res.text,'html.parser') for news in soup.select('.rank-view-list li'): newsary.append({'title':news.select('a')[1].text,'name':news.select('a')[2].text,'style':news.select('a')[3].text,'describe':news.select('p')[1].text,'lastest':news.select('p')[2].text,'url':news.select('a')[0]['href'],'votes':news.select('p')[3].text}) #将爬取的信息保存到本地的excel文件中 import pandas import openpyxl newsdf=pandas.DataFrame(newsary) newsdf.to_excel('/Users/songrenqing/Downloads/qidian_rank1.xlsx')
爬好后,在excel中大概是这种形式,我做了一些简单的处理

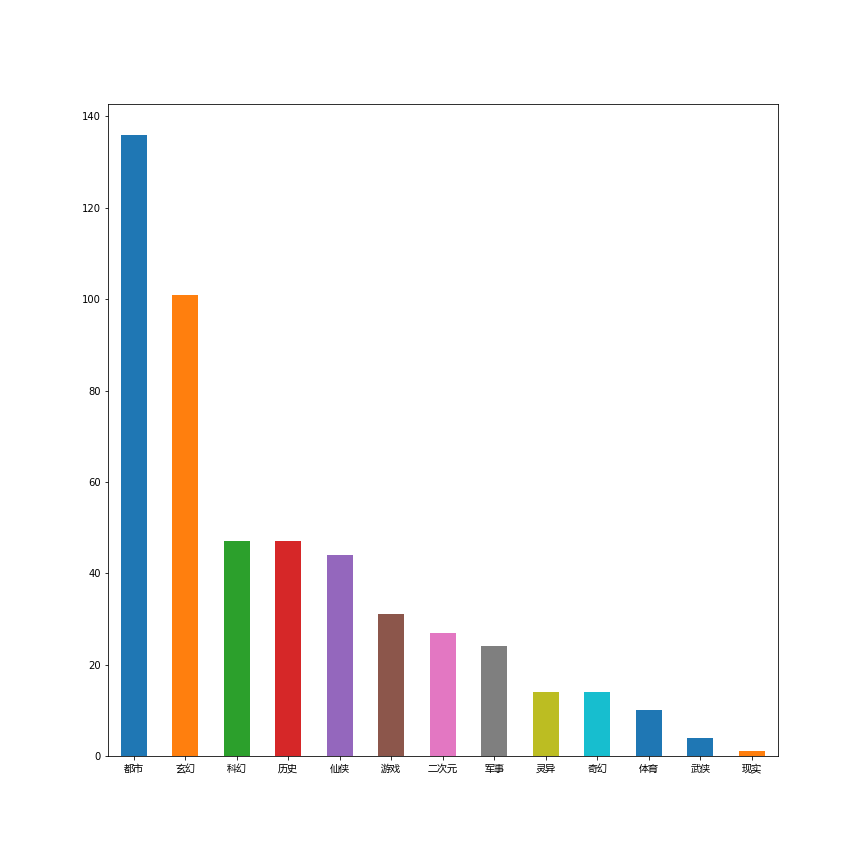
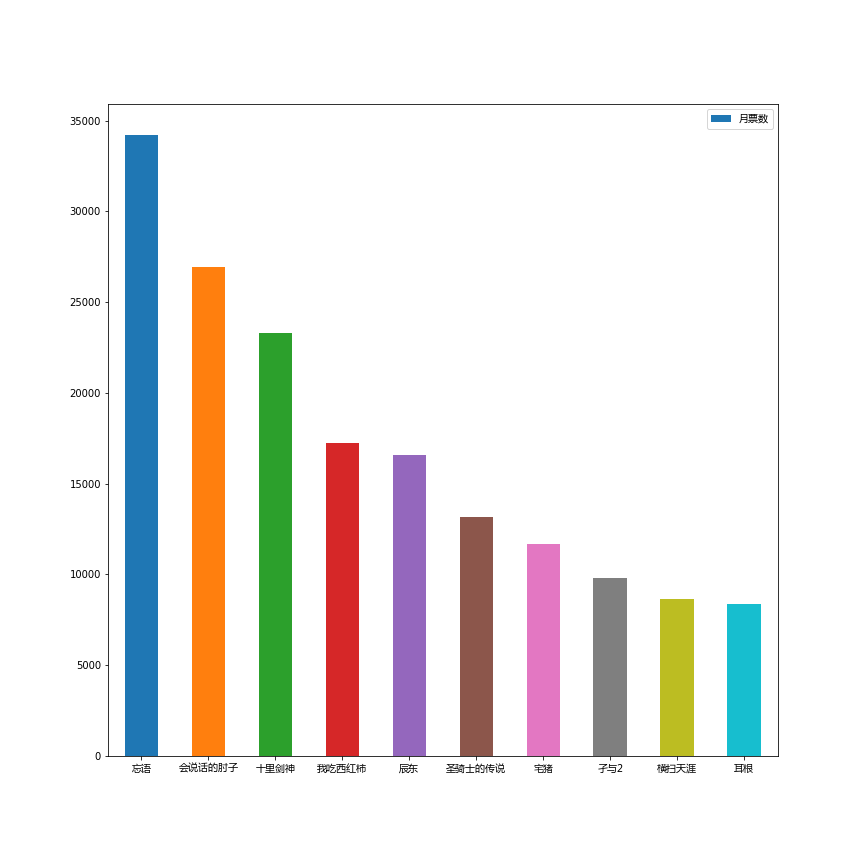
爬取到的信息主要是最新更新的章节,作者,文章类型,书名,书籍链接,简介,票数。然后用jupyter对数据进行了些简单的处理,用matplotlib绘图。
选取了得票最高的十位作者
都市和玄幻类题材最受作者欢迎,这两个题材的写作者占了一半左右。