背景
区块链共识是指多个节点或代理在给定的时间点就区块链状态达成一致的能力。当涉及区块链上分散记录保存和验证的核心功能时,单独依靠信任来确保添加到账本的信息是正确的可能会存在问题。因为没有中央实体来进行仲裁,这种问题在去中心化网络中更为明显。
共识度量是可测量的数据,区块链网络的节点必须在该数据上达成一致,以便为每个块中包含的数据建立并保持一致。在区块链技术中,每次将新块添加到链中时,每个网络节点都会测量并批准一致性度量。
共识度量有多种形式,最重要的两种是基于风险的度量(PoS)和基于工作量的度量(PoW)。本文将讨论的Quorum共识协议都是授权证明(PoA)的实现,而PoA是PoS一致性算法的子集,主要由测试网和私有或联盟网络使用。
IBFT
Istanbul Byzantine Fault Tolerant即IBFT是基于PBFT,PBFT就是Practical Byzantine Fault Tolerance的缩写,意为实用拜占庭容错算法,解决了原始拜占庭容错算法效率不高的问题,关于拜占庭容错BFT感兴趣读者可自行了解。
IBFT继承PBFT共识的三个阶段:pre-prepare,prepare和commit,称之为预准备阶段、准备阶段和提交阶段。系统可以容忍N个validator节点的网络中F个节点错误,其中 N = 3F + 1。每一轮之前,validators会首先投票选出一个proposer,默认的选举方式是轮询。选出的proposer将会打包一个新的区块并附随pre-prepare消息广播出去,当接收到pre-prepare消息,validators会进入pre-prepared状态,然后广播prepare消息。这一步是为了确认所有的validators在同一个sequence和同一个round上工作。当接收到 2F + 1个prepare消息,validator就会进入prepared状态并广播commit消息。这一步是为了通知其它节点,它验证了新区块并且将会把新区块添加到了区块链中。最后,验证者们等待2F + 1个commit消息并进入 committed 状态,并把区块添加到区块链末尾。
1.1 共识状态
IBFT是一个状态机复制算法,每个验证者为了达成区块一致都维持一个状态机副本。
状态(States):
new round:proposer打包新区块,验证者等待 pre-prepare 消息
pre-prepared:验证者接收 pre-prepare 消息,广播 prepare 消息,然后等待 2F + 1 个 prepare 或 commit 消息
prepared:验证者收到了 2F + 1 个 prepare 消息并广播 commit 消息,然后等待 2F + 1 个commit消息
commited:验证者收到了 2F + 1 个 commit 消息,可以将新区块插入区块链末尾了
final commited:新区块成功插入区块链末尾,验证者准备下一轮
round change:验证者等待同一轮上的 2F + 1 个round change消息
1.2 状态转换

New round —> Pre-prepared
1.proposer从交易池收集交易
2.proposer打包新区块并广播,然后进入 pre-prepared 状态
3.每个验证者收到pre-prepare消息后,若符合如下条件,进入pre-prepared状态
新区块来自有效的proposer
区块头有效
新区块的序号和轮数符合验证者状态
4.验证者向其它验证者广播prepare消息
Pre-prepared —> Prepared
1.验证者收到 2F+1 个有效prepare消息后进入prepared状态,prepare消息有效是指符合如下条件
序号和轮数匹配
区块哈希匹配
消息来自已知验证者
2.验证者进入prepared状态后广播commit消息
Prepared —> Committed
1.验证者收到 2F+1 个有效commit消息后进入committed状态,commit消息有效是指符合如下条件
序号和轮数匹配
区块哈希匹配
消息来自已知验证者
Commited —> Final committed
1.验证者附加2F+1个提交签名到extraData字段,将区块插入区块链末尾
2.区块插入成功后验证者进入Final committed状态
Final Commited —> New round
1.验证者选举新的proposer并启动新一轮共识计时器
1.3 共识回合改变
以下三个条件可以触发round change:
回合更改计时器到期。
无效的 PRE-PREPARE 消息。
块插入失败。
当一个验证者发现符合以上三种情况任一种时,就会将新的轮数附加到round change消息上广播出去,然后等待来自其它验证者的round change消息。附加的新的轮数根据以下条件确定
如果验证者已收到来自其对等方的round change消息,则它会选择具有F + 1个round change消息的最大轮数。
否则,它选择 1 + 当前轮数作为建议的轮数。
验证者一旦收到同一个轮数上的F+1个round change消息,它就会比较收到的轮数和自己的轮数,如果收到的更大,验证者会以收到的轮数再次广播round change消息,一旦收到了同一个轮数上的2F+1个round change消息,验证者就会退出round change循环,选举新的proposer,然后进入new round状态;当验证者通过节点同步收到了已验证的区块后也会退出round change循环。
1.4 术语
Validator
区块验证参与者。
Proposer
被选中在共识轮中提议区块的区块验证参与者。
Round
共识回合。一轮以提议者创建区块提议开始,以区块提交或轮次更改结束。
Proposal
正在进行共识处理的新区块生成提案。
RAFT
Raft是实现分布式共识的一种算法,它和Paxos的功能是一样,但是相比于Paxos,Raft算法更容易理解、也更容易应用到实际的系统当中,Raft算法也是联盟链采用比较多的共识算法。
2.1 状态
Raft的三种状态(角色)
Follower(群众):被动接收Leader发送的请求。所有的节点刚开始的时候是处于Follower状态。
Candidate(候选人):由Follower向Leader转换的中间状态
Leader(领导):负责和客户端交互以及日志复制(日志复制是单向的,即Leader发送给Follower),同一时刻最多只有1个Leader存在。
2.2 领导人选举(Leader Election)
在介绍Raft工作原理前,先说明一些关键概念:
任期(Term)
Raft算法中采用任期(Term)的概念,将时间切分为一个个的Term(同时每个节点自身也会本地维护currentTerm),可以认为是逻辑上的时间。
每一任期的开始都是一次领导人选举,一个或多个候选人(Candidate)会尝试成为领导(Leader)。如果一个人赢得选举,就会在该任期(Term)内剩余的时间担任领导人。在某些情况下,选票可能会被评分,有可能没有选出领导人(如t3),那么,将会开始另一任期,并且理科开始下一次选举。Raft 算法保证在给定的一个任期最少要有一个领导人。
超时机制(timeout)
eletion timeout:即Follower等待成为Candidate状态的等待时间,这个时间被随机设定为150ms~300ms之间
headrbeat timeout:在某个节点成为Leader以后,它会发送Append Entries消息给其他节点,这些消息就是通过heartbeat timeout来传送,Follower接收到Leader的心跳包的同时也重置选举定时器。
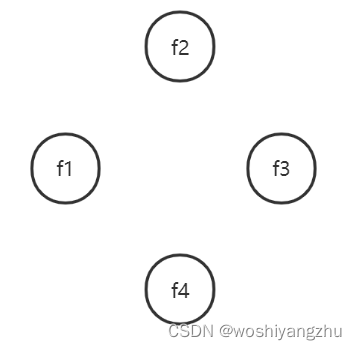
假设现在有如图4个节点,4个节点一开始的状态都是 Follower。
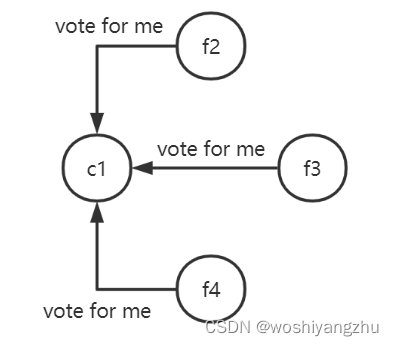
在一个节点倒计时结束 (Timeout) 后,这个节点的状态变成 Candidate 开始选举,它给其他几个节点发送选举请求 (RequestVote)
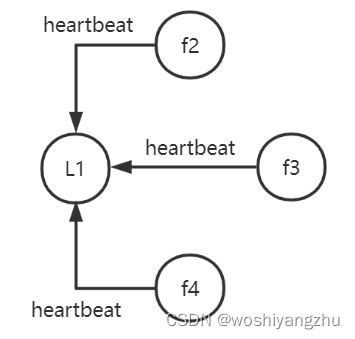
其他3个节点都返回成功,这个节点的状态由Candidate变成了 Leader,并在每个一小段时间后,就给所有的Follower发送一个Heartbeat以保持所有节点的状态,Follower收到Leader的 Heartbeat后重设Timeout。
这是最简单的选主情况,只要有超过一半的节点投支持票了,Candidate才会被选举为Leader,4个节点的情况下,3个节点 (包括Candidate本身) 投了支持就行。
Clique
Clique是一种基于认证的共识算法。这种算法的原理就是网络中的每一个区块是由某一个认证节点进行认证的,其他节点仅需要验证认证信息来判断该区块是否合法。
3.1 节点分类
节点可以分为两类:认证节点和非认证节点
前者具有为一个区块签名的权利,后者不具备签名的权利,是区块链网络中的普通同步节点,两者可以相互转换。
3.2 认证原理
clique中使用的认证原理借用了椭圆曲线数字签名算法进行实现。一个认证节点,可以利用本地节点的私钥对一个区块的数据进行签名,并将产生的数字签名放置在区块头的extraData字段中。普通节点在收到一个新区块时,会从区块头的extraData字段中取出认证节点的签名,利用标准的spec256k1椭圆曲线进行反解公钥信息,并且从公钥中截取出签发节点的地址,若该节点是认证节点,且该节点拥有签名的权限,则认为该区块为合法区块。
3.3 认证节点维护
由于认证节点可以认证区块,那么动态的维护认证节点信息列表是十分重要的,clique中采用了一种基于投票的认证节点维护机制。
先介绍几个基本概念:
signer:认证节点
purposal:用户可以利用rpc接口发起一次purposal,指定要加入或移除某一个认证节点。purposal的结构为需要改变状态的认证节点的地址和新状态;
vote:每个认证节点在每一轮签发区块时,都会从pending的purposal池里随机挑选一个purposal,并将purposal的目标节点地址填在beneficiary字段中,将新状态填在nonce字段中,以此作为一次投票
tally:每个认证节点本地会维护一个投票结果计数器tally,其中记录了每一个被选举节点的新状态(加入或者移除)和已经获取的票数。一旦获得票数超过半数,就立即更改认证节点的状态;
clique的一次投票流程如下:
1.用户通过rpc接口发起一次请求,要求对某个的节点进行状态变更,将其从普通节点变为认证节点或者从认证节点变为普通节点。生成的请求会缓存在本地的purposal池中。
2.本地认证节点在一次区块打包的过程中,从purposal池中随机挑选一条还未被应用的purposal,并将信息填入区块头,将区块广播给其他节点。
3.其他节点在接收到区块后,取出其中的信息,封装成一个vote进行存储,并将投票结果应用到本地,若关于目标节点的状态更改获得的一致投票超过半数,则更改目标节点的状态:
若为新增认证节点,将目标节点的地址添加到本地的认证节点的列表中
若为删除认证节点,将目标节点的地址从本地的认证节点列表中删除