背景引入
知识蒸馏最初的动机就是,想要将一个大模型“轻量化”,因为大模型无论是训练成本还是实际投入使用效率亦或是部署在移动端都十分不便。试想你手机里可怜的内存,每个月都会被QQ微信侵蚀一些,如果那些APP每个下载安装包都要4、5个G(游戏除外),想必手机用不了几个月就需要大清一次内存或者更换了(商家狂喜),而如果APP只有1、2G,你手机里就能多容纳3、4倍的软件。
那么为什么不直接使用轻量化的模型呢?
一般而言,轻量化的模型参数更少,其速率虽然提高,但是检测精度会大大降低,很可能不符合实际应用的标准。这就陷入了一个两难的问题,大模型小模型都部署不了。那么是否可以用大模型向小模型“传授”其强大的能力。对此,我们可以类比老师与学生,老师拥有大量知识,而学生只拥有很少量的知识,老师可以将其知识通过自己的提炼传授给学生,这样学生可以大大降低学习的成本。
类比于此,我们可以让大模型(教师模型)学习到的内容(知识)“传授”(蒸馏)给小模型(学生模型)。事实证明,这样能使小模型达到更好的效果。
前置知识
1、Softmax函数
softmax函数通常作为多分类以及归一化函数使用,其公式如下:
s o f t m a x ( x ) = e x i ∑ i = 1 e x i softmax(x)=\frac{e^{x_i}}{\sum_{i=1} e^{x_i}} softmax(x)=∑i=1exiexi
softmax函数有些重点的特点:
- 所有经过softmax输出数值总和为1且大于0,这满足一个概率分布。这点很好理解,因为分母是个求和,所有分式分子加起来就会得到分母
- 扩大化大小差距。这是由指数函数 e x e^x ex造成的,根据指数函数图像,自变量值 x x x越大,其因变量 y y y值增长的越快。可以看下面这个例子
| x | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| softmax(x) | 0.032 | 0.087 | 0.237 | 0.644 |
这就进一步带来一个问题,是否可以通过一个方法,使数之间差距没有那么大呢?这里我们使用了一个超参数温度T,来控制差距,公式如下:
s o f t m a x ( x , T ) = e x i t ∑ i = 1 e x i t softmax(x,T)=\frac{e^\frac {x_i}t}{\sum_{i=1} e^\frac {x_i}t} softmax(x,T)=∑i=1etxietxi
然后接着之前的例子,我们令T=0.5,1,2,4时,观察数据的变化。
| T\x | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 0.5 | 0.002 | 0.016 | 0.117 | 0.865 |
| 1 | 0.032 | 0.087 | 0.237 | 0.644 |
| 2 | 0.101 | 0.167 | 0.276 | 0.455 |
| 4 | 0.165 | 0.212 | 0.272 | 0.350 |
可以发现随着 T T T的增大,不同类别之间的差距值越小(对负标签,即非正确标签关注度更高),但是大小关系并不改变。下图是另一个softmax值与温度的关系图。

2、log_softmax函数
log_softmax函数就是将softmax得到的输出值作为对数函数的输入值
l o g ( s o f t m a x ( x ) ) log(softmax(x)) log(softmax(x))
3、NLLloss函数
NLLloss是衡量两者之间的差距,公式如下:
N L L l o s s ( p , q ) = − ∑ i = 1 q i l o g p i NLLloss(p,q)=-\sum_{i=1} q_ilogp_i NLLloss(p,q)=−i=1∑qilogpi
如果两者差距越大则最后值越大
4、CrossEntropy函数
CrossEntropy函数又称交叉熵损失函数,其实公式表现形式和NLL损失函数一致,但是 p 、 q p、q p、q具体含义不同,这里的 p 、 q p、q p、q是要经过log_softmax的【在pytorch中】
》》NLLloss与CrossEntropy区别
#NLLloss
def forward()
x=self.fc2(x)
x=F.log_softmax(x,dim=1)
return x
F.nll_loss()
#CrossEntropy
def forward()
x=self.fc2(x)
return x
F.cross_entropy()
知识蒸馏具体内容
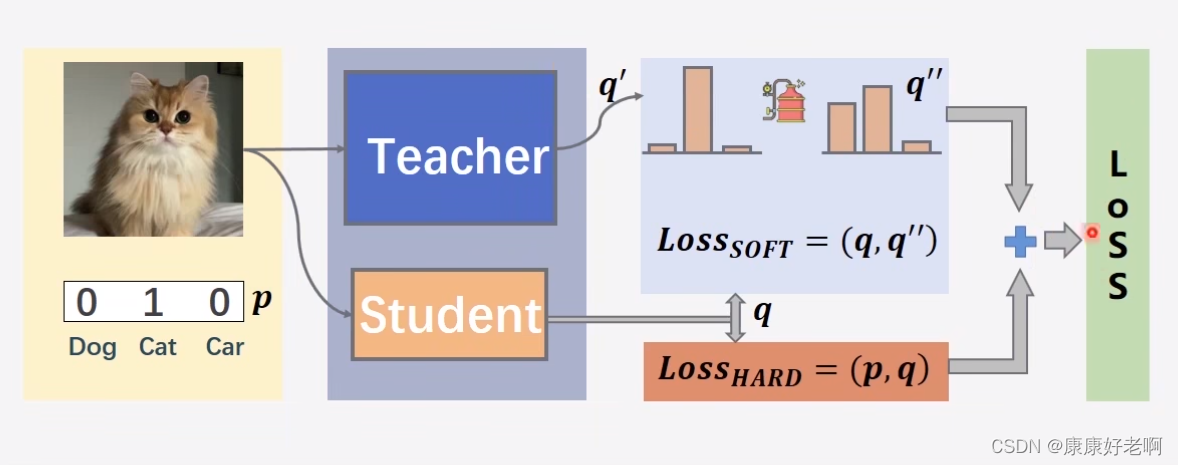
上面的一幅图可以很好的帮助理解知识蒸馏。首先看学生模型,正常情况下训练模型会使用交叉熵损失函数,即 L o s s H A R D ( p , q ) Loss_{HARD}(p,q) LossHARD(p,q),比如现在模型输出了一个 q = ( 0.4 , 0.2 , 0.4 ) q=(0.4,0.2,0.4) q=(0.4,0.2,0.4)三元组,而目标三元组是 p = ( 1 , 0 , 0 ) p=(1,0,0) p=(1,0,0)(我们称之为硬标签Hard Label),那么就会计算两者的交叉熵损失,再进行梯度下降和反向传播。教师模型也是如此,进过模型会输出一个 q ′ q' q′的三元组。
这种硬标签的编码方式也被称为“one-hot”编码
而蒸馏的部分在于,从教师模型得到的 q ′ q' q′会经过蒸馏得到 q ′ ′ q'' q′′(我们称之为软标签Soft Label),这个蒸馏过程就是用上述所讲的温度 T T T。然后再 q ′ ′ q'' q′′和 q q q之间也使用交叉熵损失函数 L o s s S O F T ( q , q ′ ′ ) Loss_{SOFT}(q,q'') LossSOFT(q,q′′),最后总的损失函数就是 α L o s s H A R D ( p , q ) + β L o s s S O F T ( q , q ′ ′ ) \alpha Loss_{HARD}(p,q)+\beta Loss_{SOFT}(q,q'') αLossHARD(p,q)+βLossSOFT(q,q′′)
在此处可以不使用交叉熵损失函数 L o s s S O F T ( q , q ′ ′ ) Loss_{SOFT}(q,q'') LossSOFT(q,q′′),而是使用衡量两个概率分布匹配程度的KL散度损失。
这里对软标签多解释一些。软标签并不像硬标签,硬标签只包含是与否的信息,而软标签会包含更多的信息。比如现在三元组定义为 ( 猫猫 , 狗狗 , 鸭鸭 ) (猫猫,狗狗,鸭鸭) (猫猫,狗狗,鸭鸭),那么硬标签 ( 1 , 0 , 0 ) (1,0,0) (1,0,0)只能表示这个对象是猫猫,而软标签 ( 0.6 , 0.3 , 0.1 ) (0.6,0.3,0.1) (0.6,0.3,0.1)可以表示这个对象是只猫的同时,他也十分像猫,而不太像鸭。
问题1:为什么不重新训练一个新的模型?
教师模型可以帮助学生模型更好地收敛,而不需要学生模型重新根据数据进行收敛,而且教师模型提供的信息比原数据集更加有效
问题2:为什么要对于最后一步输出结果进行蒸馏?
实际上,学生模型的中间网络层也可以学习教师模型的中间网络层输出结果,让学生模型的中间网络输出结果拟合教师模型的中间网络输出结果,如下图所示。这就好比一个教授教授一个婴儿,一下学不会那就分开学。

问题3:理论上来说,控制其它条件,模型参数量越大效果越好,那么为什么知识蒸馏后的模型效果还依旧很好呢?
其实很多模型的模型参数量与其包含的“知识”总量的大致关系如下图②③,不难发现,即使模型参数总量有少量的降低,“知识”量并不会降低多少,依然能达到很好的效果。

知识蒸馏的优点
(1)减少过拟合,泛化能力很强
这是当年知识蒸馏提出论文中的一张,可以发现soft targets可以很好地减少过拟合(相比于baseline训练准确度降低,但是测试准确度反而提高)

(2)使模型更加轻量化,速度、效率提高,更容易部署在移动端之上
(3)一些情况下可以提升模型的效果
知识蒸馏发展方向
(1)教学相长,学生模型帮助老师模型,个人理解为学生模型可以学一些老师不知道的领域然后从而提升老师的能力
(2)多个老师、助教进行知识蒸馏
(3)结合对比学习、迁移学习
(4)网络中间层之间进行知识蒸馏,而不仅仅是最后结果进行知识蒸馏