
1、逻辑函数
假设数据集有n个独立的特征,x1到xn为样本的n个特征。常规的回归算法的目标是拟合出一个多项式函数,使得预测值与真实值的误差最小:
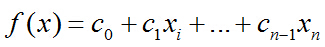
而我们希望这样的f(x)能够具有很好的逻辑判断性质,最好是能够直接表达具有特征x的样本被分到某类的概率。比如f(x)>0.5的时候能够表示x被分为正类,f(x)<0.5表示分为反类。而且我们希望f(x)总在[0, 1]之间。有这样的函数吗?
sigmoid函数就出现了。这个函数的定义如下:
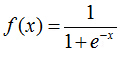
先直观的了解一下,sigmoid函数的图像如下所示(来自http://computing.dcu.ie/~humphrys/Notes/Neural/sigmoid.html):
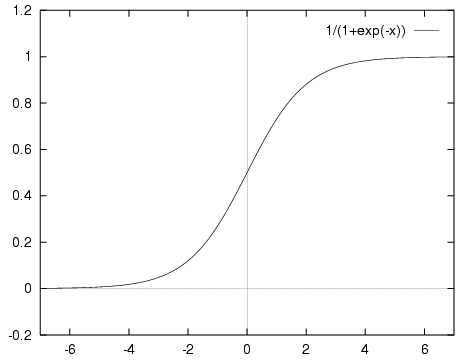
sigmoid函数具有我们需要的一切优美特性,其定义域在全体实数,值域在[0, 1]之间,并且在0点值为0.5。
那么,如何将f(x)转变为sigmoid函数呢?令p(x)=1为具有特征x的样本被分到类别1的概率,则p(x)/[1-p(x)]被定义为让步比(odds ratio)。引入对数:
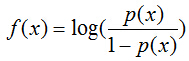
上式很容易就能把p(x)解出来得到下式:
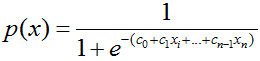
现在,我们得到了需要的sigmoid函数。接下来只需要和往常的线性回归一样,拟合出该式中n个参数c即可。
2、测试数据
测试数据我们仍然选择康奈尔大学网站的2M影评数据集。
在这个数据集上我们已经测试过KNN分类算法、朴素贝叶斯分类算法。现在我们看看罗辑回归分类算法在处理此类情感分类问题效果如何。
同样的,我们直接读入保存好的movie_data.npy和movie_target.npy以节省时间。
3、代码与分析
逻辑回归模型,自己的理解逻辑就相当于是非,那就只有0,1的情况。这个是我在一个大神那看到的,https://blog.csdn.net/zouxy09/article/details/20319673

逻辑回归模型用于分类,可以知道哪几个影响因素占主导地位,从而可以预测某事件。

步骤:1、读取数据 。
2、将特征(影响因素)和结果变成矩阵的形式。
3、导入模块sklearn.linear_model 下RandomizedLogisticRegression,进行实例化。
4、通过fit()进行训练模型。
5、通过get_support()筛选有效特征,也是降维的过程。
6、简化模型,训练模型。
#逻辑回归
import pandas as pda
fname = 'F://anacondadaima//shujuchuli//suanfa//luqu.csv'
dataf = pda.read_csv(fname)
x = dataf.iloc[:,1:4].as_matrix() #iloc[]切片,转为数组
y = dataf.iloc[:,0:1].as_matrix()
from sklearn.linear_model import LogisticRegression as LR #导入回归模型
from sklearn.linear_model import RandomizedLogisticRegression as RLR #导入随机模型
r1 = RLR() #建立随机逻辑模型(用于筛选)
r1.fit(x,y) #将x,y导入模型
r1.get_support(indices=True) #获取有效特征(特征筛选)降维
#print(dataf.columns[r1.get_support(indices=True)])
t = dataf[dataf.columns[r1.get_support(indices=True)]].as_matrix()
r2 = LR() #建立逻辑模型
r2.fit(t,y)
print('训练结束')
print('模型正确率为:'+str(r2.score(x,y)))
