任务:要求动手从0实现 sin函数在区间[-2Pi,2Pi回归(只借助Tensor和Numpy相关的库)在人工构适的sin函数数据策,并对其训练和测试,并从loss、训练集以及测试集上的准确率等多个角度对结果进行分析。
1.导入相应的包以及seed()函数介绍
import numpy as np
import tensorflow as tf
import math
import random
import matplotlib.pyplot as plt
# 可重复性 seed
random.seed(0)
np.random.seed(0)
tf.random.set_seed(0)numpy.random.seed() 函数介绍
seed()函数用于指定随机数生成时所用算法开始的整数值,如果使用相同的 seed()值,则每次生成的随机数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同。 但是,只在调用的时候seed()一下并不能使生成的随机数相同,需要每次调用都seed()一下,表示种子相同,从而生成的随机数相同。
示例
相同的随机种子下生成相同的随机数
num=0
while(num<5):
random.seed(5)
print(random.random())
num+=1
#结果
#0.6229016948897019
#0.6229016948897019
#0.6229016948897019
#0.6229016948897019
#0.6229016948897019一个随机种子在代码中只作用一次,只作用于其定义位置的下一次随机数生成
num=0
print(random.random())
random.seed(5)
while(num<5):
print(random.random())
num+=1
#结果
#0.7417869892607294
#0.6229016948897019
#0.7417869892607294
#0.7951935655656966
#0.9424502837770503
#0.73989857473993072.第一个步骤是生成包含输入x和输出y的数据集。我们将把正弦函数限制在[-2Π, 2 Π]区间内。
# 生成训练集和测试集
num_points = 1000
x_data = []
y_data = []
for i in range(num_points):
x = random.uniform(-2*math.pi, 2*math.pi)
y = math.sin(x)
x_data.append(x)
y_data.append(y)
x_data = np.array(x_data).reshape(num_points, 1)
y_data = np.array(y_data).reshape(num_points, 1)+np.random.normal(0,0.05)
# 数据可视化
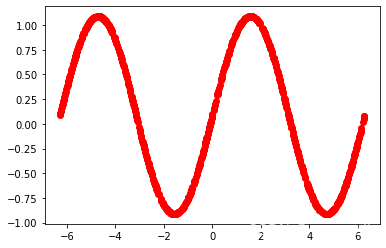
plt.plot(x_data, y_data, 'ro')
plt.show()
参数ro中r为red,o代表使用圆形标记绘制而不是用线绘制,这将在图形中显示我们的数据集。每个点代表一个(x,y)对,其中y是sin函数的值。
绘制结果:
3.先对数据进行标准化处理,然后划分训练集和测试集
# -- 对输入数据进行标准化处理 --
ave_input = np.average(x_data, axis=0)
std_input = np.std(x_data, axis=0)
input_data = (x_data - ave_input) / std_input
correct_data = y_data# -- 训练数据与测试数据 --
index = np.arange(num_points)
index_train = index[index%2 == 0]
index_test = index[index%2 != 0]
#print(index_train)
input_train = input_data[index_train, :] # 训练 输入
#print(input_train)
correct_train = correct_data[index_train, :] # 训练 正确答案
#print(correct_train)
input_test = input_data[index_test, :] # 测试 输入
correct_test = correct_data[index_test, :] # 测试 正确答案
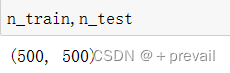
n_train = input_train.shape[0] # 训练数据的样本数
n_test = input_test.shape[0] # 测试数据的样本数
这里训练集和测试集对半分
4.设置网络中各层神经元的个数,以及一些学习率和其他参数的设置
# -- 各种设置值 --
n_in = 1 # 输入层的神经元数量
n_mid = 25 # 中间层的神经元数量
n_out = 1 # 输出层的神经元数量
wb_width = 0.1 # 权重和置的分散度
eta = 0.005 # 学习系数
epoch = 1000
batch_size = 32
interval = 100 # 显示进度的训练次数间隔5.接下来,我们需要创建模型。在这个模型中,我们将使用三个隐藏层,每个层都有25个神经元。我们将使用ReLU激活函数。输出层使用linear激活函数。
由于该回归问题比较简单,神经元数量以及隐藏层层数很小就能够拟合的很好了。
# -- 各个网络层的祖先类 --
class BaseLayer:
def __init__(self, n_upper, n):
self.w = wb_width * np.random.randn(n_upper, n) # 权重(矩阵)
self.b = wb_width * np.random.randn(n) # 偏置(向量)
def update(self, eta):
self.w -= eta * self.grad_w
self.b -= eta * self.grad_b
# -- 中间层 --
class MiddleLayer(BaseLayer):
def forward(self, x):
self.x = x
self.u = np.dot(x, self.w) + self.b #p.dot()函数主要有两个功能,向量点积和矩阵乘法
self.y = np.where(self.u <= 0, 0, self.u) # ReLU
def backward(self, grad_y):
delta = grad_y * np.where(self.u <= 0, 0, 1) # ReLU的微分
self.grad_w = np.dot(self.x.T, delta) #p.dot()函数主要有两个功能,向量点积和矩阵乘法
self.grad_b = np.sum(delta, axis=0)
self.grad_x = np.dot(delta, self.w.T) # 反向传播 #p.dot()函数主要有两个功能,向量点积和矩阵乘法
# -- 输出层 --
class OutputLayer(BaseLayer):
def forward(self, x):
self.x = x
u = np.dot(x, self.w) + self.b #p.dot()函数主要有两个功能,向量点积和矩阵乘法
self.y = u # 使用linear激活函数
def backward(self, t):
delta = self.y - t
self.grad_w = np.dot(self.x.T, delta) #p.dot()函数主要有两个功能,向量点积和矩阵乘法
self.grad_b = np.sum(delta, axis=0)
self.grad_x = np.dot(delta, self.w.T) # 反向传播 #p.dot()函数主要有两个功能,向量点积和矩阵乘法6.对中间层类和输出层类的初始化(这里添加多了一层中间层),以及对正向传播和反向传播的定义
# -- 各个网络层的初始化 --
middle_layer_1 = MiddleLayer(n_in, n_mid)
middle_layer_2 = MiddleLayer(n_mid, n_mid)
middle_layer_3 = MiddleLayer(n_mid,n_mid) #加多一层中间层
output_layer = OutputLayer(n_mid, n_out)
# -- 正向传播 ,一层一层的传播--
def forward_propagation(x):
middle_layer_1.forward(x)
middle_layer_2.forward(middle_layer_1.y)
middle_layer_3.forward(middle_layer_2.y)
output_layer.forward(middle_layer_3.y)
# -- 逆向传播,一层一层传播 --
def backpropagation(t):
output_layer.backward(t)
middle_layer_3.backward(output_layer.grad_x)
middle_layer_2.backward(middle_layer_3.grad_x)
middle_layer_1.backward(middle_layer_2.grad_x)
7.#权重偏置的更新函数。由于是线性回归,这里采用均方误差作为损失函数
# -- 权重和偏置的更新 --
def uppdate_wb():
middle_layer_1.update(eta)
middle_layer_2.update(eta)
middle_layer_3.update(eta)
output_layer.update(eta)
def mean_squared_error(y_pred, y_true):
"""
计算均方误差
:param y_pred: 包含模型预测值的一维 Numpy 数组
:param y_true: 包含实际值的一维 Numpy 数组
:return: 均方误差
"""
assert y_pred.shape == y_true.shape, "Shape of y_pred and y_true must be same"
mse = np.mean(np.power(y_pred - y_true, 2))
return mse
# -- 用于记录误差 --
train_error_x = []
train_error_y = []
test_error_x = []
test_error_y = []8.在定义模型后,我们需要对模型进行训练。我们将对模型训练1000个epochs,并使用大小为32的批次大小。
# -- 记录学习的过程和经过 --
n_batch = n_train // batch_size # 每一轮epoch的批次尺寸
for i in range(epoch):
# -- 误差的统计和测算 --
forward_propagation(input_train) #调用forward_propagation函数
error_train = mean_squared_error(correct_train,output_layer.y) #采用均方误差
forward_propagation(input_test)
error_test = mean_squared_error(correct_test,output_layer.y) #采用均方误差
# -- 误差的记录 --
test_error_x.append(i)
test_error_y.append(error_test)
train_error_x.append(i)
train_error_y.append(error_train)
# -- 进度的显示 --
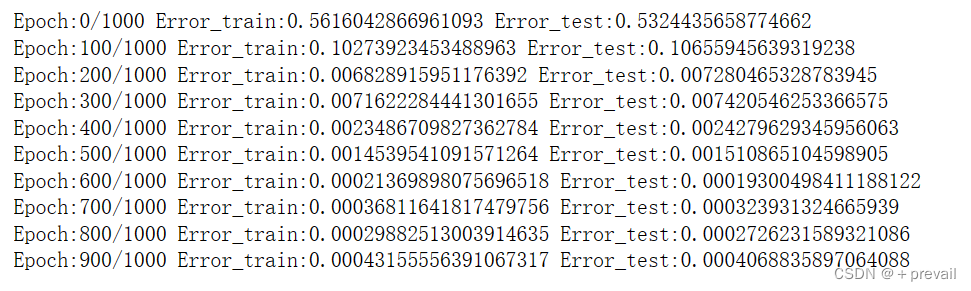
if i%interval == 0:
print("Epoch:" + str(i) + "/" + str(epoch),
"Error_train:" + str(error_train),
"Error_test:" + str(error_test))
# -- 学习 --
index_random = np.arange(n_train)
np.random.shuffle(index_random) # 将索引值随机的打乱排序 #np.random,shuffle作用就是重新排序返回一个随机序列作用类似洗牌
for j in range(n_batch):
# 取出最小批次
mb_index = index_random[j*batch_size : (j+1)*batch_size] #实现8个数据重新排序
x = input_train[mb_index, :] #随机取batch_size个数据当作输入
t = correct_train[mb_index, :] #t代表真值,true
# 正向传播和反向传播
forward_propagation(x)
backpropagation(t)
# 权重和偏置的更新
uppdate_wb()
现在,我们已经成功地训练了我们的模型。让我们输出一些有用的统计信息,例如,所有批次上的平均损失、训练集和测试集的平均绝对误差。
9.绘制loss曲线
# -- 用图表表示误差的记录 --
plt.plot(train_error_x, train_error_y, label="Train")
plt.plot(test_error_x, test_error_y, label="Test")
plt.legend()
plt.xlabel("Epochs")
plt.ylabel("Error")
plt.show()
# -- 测算正确率 --
forward_propagation(input_train)
count_train = np.sum(np.argmax(output_layer.y, axis=1) == np.argmax(correct_train, axis=1))
forward_propagation(input_test)
count_test = np.sum(np.argmax(output_layer.y, axis=1) == np.argmax(correct_test, axis=1))
print("Accuracy Train:", str(count_train/n_train*100) + "%",
"Accuracy Test:", str(count_test/n_test*100) + "%")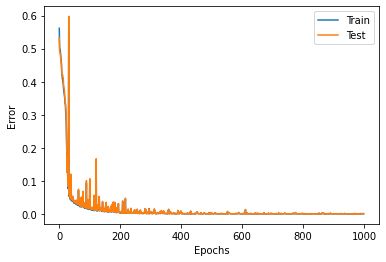
10.模型的保存
# 创建模型
W1 = middle_layer_1.w
b1 = middle_layer_1.b
W2 = middle_layer_2.w
b2 = middle_layer_2.b
W3 = middle_layer_3.w
b3 = middle_layer_3.b
W4 = output_layer.w
b4 = output_layer.b
# 训练模型...
# 保存模型参数
np.savez('model.npz', W1=W1, b1=b1, W2=W2, b2=b2,W3=W3,b3=b3,W4=W4,b4=b4)
# 加载模型参数
data = np.load('model.npz')
W1_loaded = data['W1']
b1_loaded = data['b1']
W2_loaded = data['W2']
b2_loaded = data['b2']
W3_loaded = data['W3']
b3_loaded = data['b3']
W4_loaded = data['W4']
b4_loaded = data['b4']
# 预测时重新调用模型进行计算
def predict(X):
Z1 = np.dot(X, W1_loaded) + b1_loaded
Z1 = np.where(Z1 <= 0, 0,Z1)
Z2 = np.dot(Z1, W2_loaded) + b2_loaded
Z2 = np.where(Z2 <= 0, 0,Z2)
Z3 = np.dot(Z2, W3_loaded) + b3_loaded
Z3 = np.where(Z3 <= 0, 0,Z3)
Z4 = np.dot(Z3, W4_loaded) + b4_loaded
Z4 = Z4
return Z4
11.预测新点(预测时,丢进模型前要对预测数据先进行标准化)
# 预测新点
x_test = np.linspace(-2*math.pi, 2*math.pi, num=100).reshape(100,1)
x_test1 = (x_test - ave_input) / std_input #丢进模型前归一化
y_pred = predict(x_test1)
# 绘制预测的sin函数曲线
plt.plot(x_test, y_pred, 'bo')
plt.plot(x_data, y_data, 'ro')
plt.show()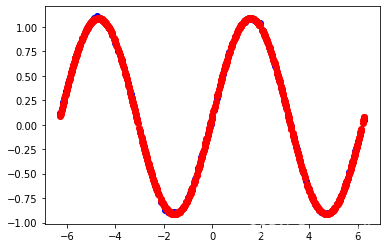
# 预测新点
x_test = np.linspace(-2*math.pi, 2*math.pi, num=100).reshape(100,1)
x_test1 = (x_test - ave_input) / std_input #丢进模型前归一化
y_pred = predict(x_test1)
# 绘制使用sin函数生成的sin函数曲线
# plt.plot(x_test, y_pred, 'bo')
plt.plot(x_data, y_data, 'ro')
plt.show()
# # 预测新点
x_test = np.linspace(-2*math.pi, 2*math.pi, num=100).reshape(100,1)
x_test1 = (x_test - ave_input) / std_input #丢进模型前标准化
y_pred = predict(x_test1)
# 绘制预测的sin函数曲线
plt.plot(x_test, y_pred, 'bo')
# plt.plot(x_data, y_data, 'ro')
plt.show()
总结:
在这个实验中,我们使用了numpy和TensorFlow库,通过从零开始实现sin函数的线性回归模型,从而更好地理解了深度学习中的一些概念。在实验中,我们先生成了训练数据,然后使用TensorFlow的优化器和损失函数,对模型的参数进行了训练,最终获得了一个拟合良好的sin函数线性回归模型。
通过这个实验,我们深刻认识到使用numpy和TensorFlow可以帮助我们有效地实现深度学习算法,并且可以提高算法的效率和准确性。我们相信这些工具在将来的深度学习实践中将发挥越来越重要的作用。
补充:
如有其他问题,请私信我,谢谢。