背景
寒假的时候,由于up非常喜欢剪辑英雄联盟视频,但是在剪辑的时候会遇到没有英雄台词原声的问题,所以就去各大网站上找,但是遇到的问题是要么就是英雄台词不全,要么就是其他皮肤的原声没有。后来在某多商城里看到有人在卖这种原声,仅需3大洋,但是如果直接买的话,就失去了这种数据挖掘的乐趣了。所以我就走向了英雄联盟台词语音包数据挖掘的道路。
项目地址:点击跳转至gitee
话不多说,直接看项目。
工具
正所谓工欲善其事,必先利其器,这次项目我们需要用到其中一个工具Ravioli Explorer。工具下载链接:点击跳转 提取码:kgiu
下载压缩包并且解压之后,打开下图软件:
![]()
打开之后的界面是这样的,我们后面会用到。
作用:该工具的作用是打开英雄联盟文件包中的语音特定文件,因为不使用这个工具,直接打开是打开不了这些文件的(如.client),我们需要的就是用这个工具将一些特定的语音文件格式(如.wem)先转成可以供电脑可以直接播放的(.wav)文件。
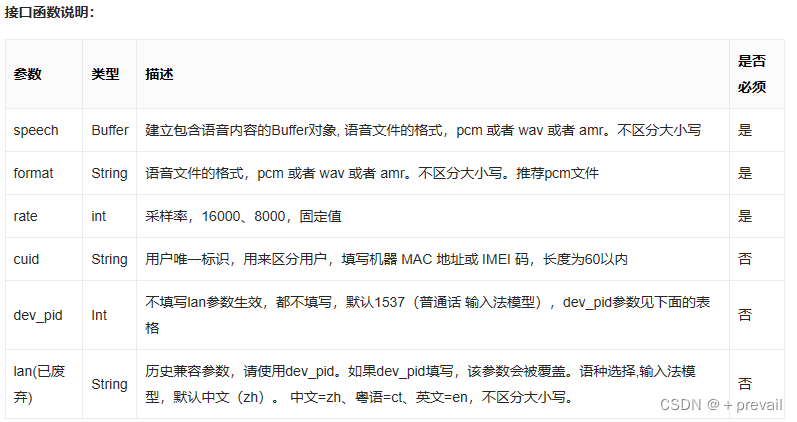
另一个工具是百度智能云,它是我们接口调用的平台,我们需要先使用百度账号领取一些免费的子资源。

按照上述照片领取相关资源,把能够免费领取的都领取了。
百度智能云接口使用方法:
①先创建应用,然后选取语音技术选项的全部
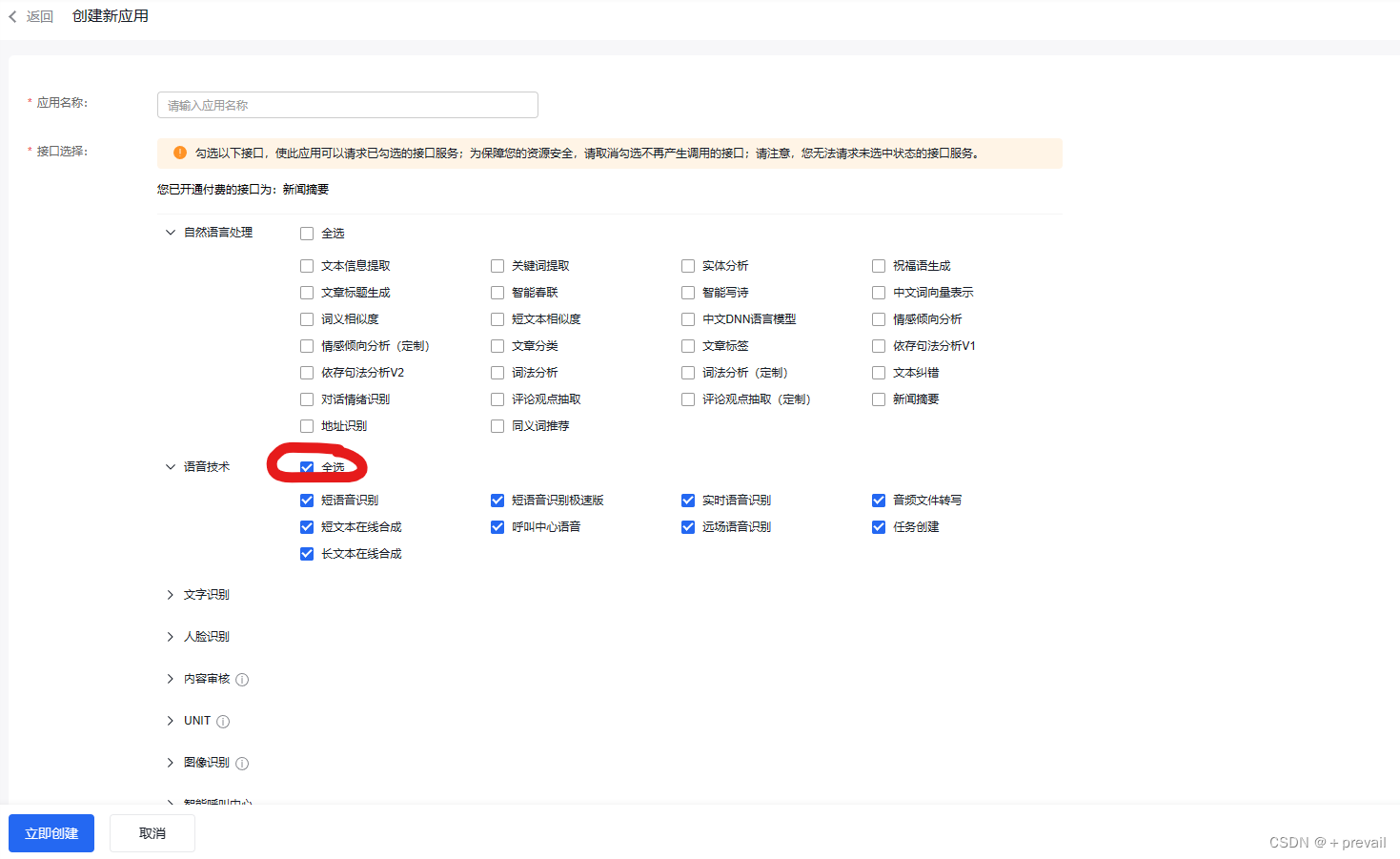
②此时就可以看到API列表中出现了下列API

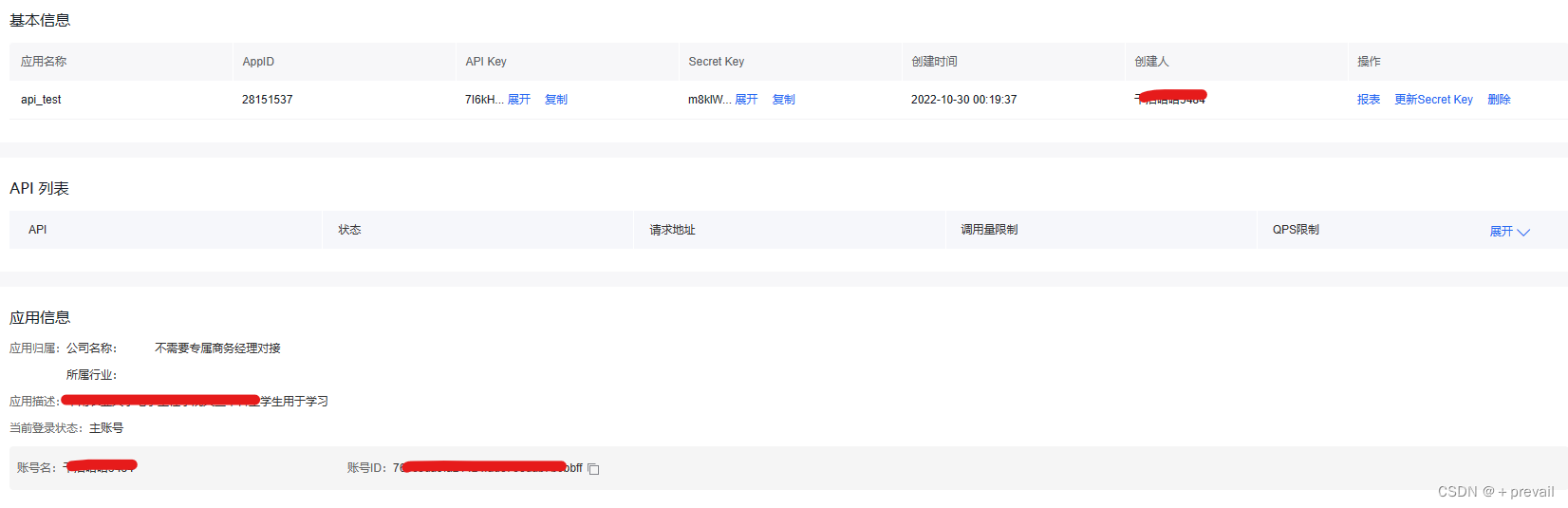
③记住AppID,APIKey以及SecretKey。后面调用的时候需要在放在代码里。
准备工作
英雄台词源文件地址:
1.打开目录
2.按照一下路径找到下图(一般都是这个路径D:\WeGameApps\英雄联盟\Game\DATA\FINAL\Champions)
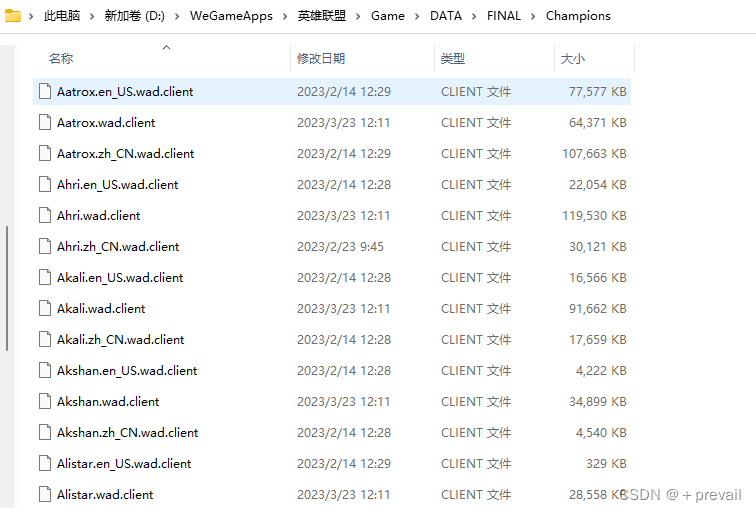
如下图,命名格式是英雄名+语言+后缀名
示例,下面是剑魔(Aatrox)的台词语音包

3.将中文英雄台词原文件拖入Ravioli Explorer(这里以永恩为示例,因为永恩皮肤比较少,需要识别的语音也少一点)(Yone.zh_CN.wad.client)
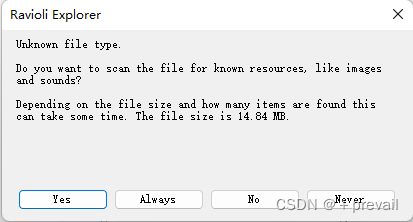
点击yes

出现了wem后缀的文件
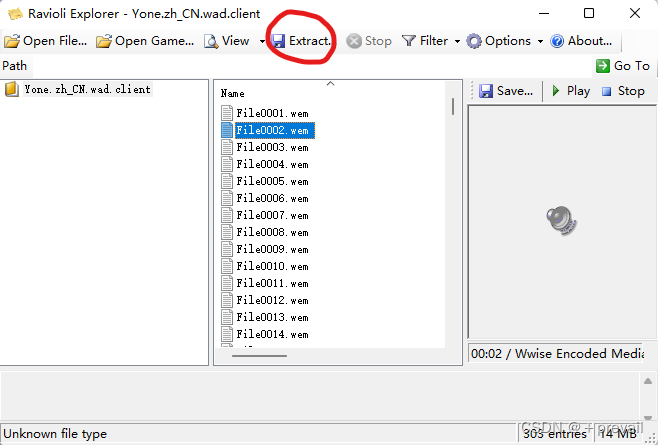
点击Extract
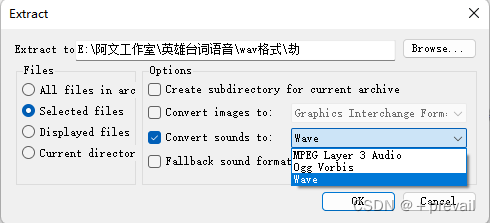
然后选择wav格式,选择想要将wav文件导出的路径,最后点击OK。
等他解码和编码完成之后,英雄台词的wav语音文件就得到了,但是这时候我们就会发现,这些语音的重命名都是字母和数字,我们根本就不知道某一条语音的内容是什么。
这时候我们批量语音识别就会发挥出作用了,下面我们就可以调用百度接口然后对语音进行语音识别工作了。
代码部分
项目结构:

项目步骤:
1.将wav语音文件转化成pcm语音文件。
根据百度接口的参考文档:点击跳转 推荐使用的文件格式是pcm,估计是官方测试下使用该文件的识别准确度比较高,所以我们也就稍微花一点时间把wav转化成pcm格式。
import ffmpy3
import os
def file_name(file_dir): # 获取文件
name_list1 = []
file_list1 = []
for root, dirs, files in os.walk(file_dir):
if len(files) != 0:
name_list1.append(root)
file_list1.append(files)
return files
wav_path = r"..\speech_to_text\yongen\wav"
pcm_path = r"..\speech_to_text\yongen\pcm"
voice_list = file_name(wav_path)
length = len(voice_list)
for n,i in enumerate(voice_list):
ff = ffmpy3.FFmpeg(
inputs={wav_path+"\\"+i:None},
outputs={pcm_path+"\\"+i[:-3]+"pcm":"-f s16le -ar 16000 -ac 1 -acodec pcm_s16le"}
)
ff.run()
print("一共%d个文件,第%d个wav语音转化为pcm完成"%(length,n+1))运行结果:
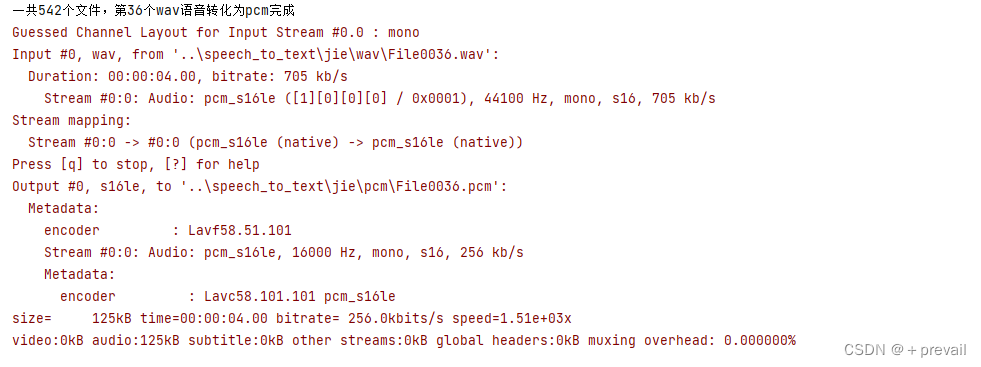
此时我们得到了一批顺序和wav文件是一样的pcm文件。
2.使用接口对pcm文件进行语音识别,然后用识别结果(文字)对wav文件进行重命名,这样我们就得到了一堆识别好的,以语音内容为重命名的wav语音文件。
#函数准备
import os
def file_name(file_dir): # 获取文件
name_list1 = []
file_list1 = []
for root, dirs, files in os.walk(file_dir):
if len(files) != 0:
name_list1.append(root)
file_list1.append(files)
return files
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
# 新建AipSpeech实例
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = 'yourappid'
API_KEY = 'yourapikey'
SECRET_KEY = 'yoursecretkey'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
wav_path = r"..\speech_to_text\yongen\wav"
pcm_path = r"..\speech_to_text\yongen\pcm"
voice_list = file_name(wav_path)
length = len(voice_list)
for n,i in enumerate(voice_list):
strs = client.asr(get_file_content(pcm_path+"\\"+i[:-3]+"pcm"), 'pcm', 16000, {'dev_pid': 1537,})['result'][0].strip("。")
old_name = wav_path+"\\"+i
new_name = wav_path+"\\"+str(n+1)+strs+".wav"
os.rename(old_name, new_name)
print("一共%d个语音,当前第%d个语音已重命名完成。"%(length,n+1))
运行示例:

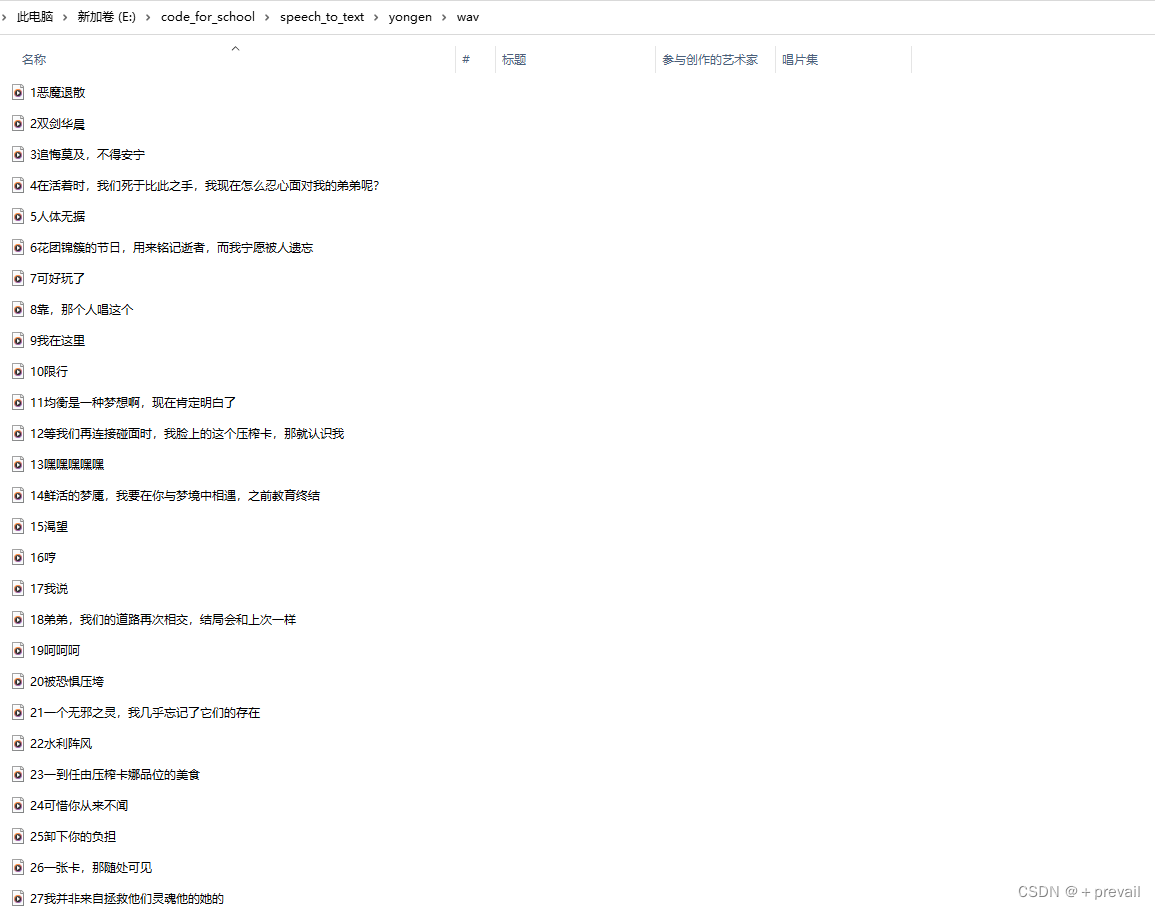
从结果上来看,也许有些许错别字或者是偏离正确文字,但总比一堆英文和数字好吧,其他英雄和皮肤的语音包文件同样适用这个方法去挖掘出我们想要的语音。同时,我在百度很多文章看到,其他游戏例如某荣耀也是可以使用该方法进行语音包挖掘的。我们在需要使用某个语音时,可以根据粗检索加上自己二次检索就可以找到我们想要的那个语音了。
总结
以上就是该项目的全部内容,总的来说还是比较有趣的。
如果其他问题,请私信我,谢谢。