观看浙江大学暑期crypto school讲座的可证明安全有感,总结如下:
目录
· 概述
可证明安全主要分为三个步骤:
-
确定威胁模型;
-
其次构造方案;
-
给出一个正式的安全性证明。

注:可证明安全如果证出来安全,实际不一定安全。因为:
①assumption很可能被攻破;
②threat model可能和实际情况不一样;
③proof的过程可能有问题。
· 公钥密码
公钥加密始于1976年Diffie和Hellman的论文《New directions in Cryptography》,对于以下两个问题:

整个密码学的基础都基于假设。对于上图中的两个问题,前者为什么是安全的,因为它基于Diffie and Hellman assumption,后者为什么是安全的,因为它基于RSA assumption。(从严式/永真式)
RSA是一种典型的公钥加密算法,但我们从课本上学到到RSA并不是安全的,如下图所示。


一般而言,需要对消息进行padding(填充)才可以使用相应的RSA方案。这里我的理解是这样的:
-
防止明文长度不足:RSA加密算法要求明文长度必须小于或等于密钥长度,因此需要对明文进行填充,使得明文长度等于密钥长度或者小于密钥长度。
-
防止相同明文加密后生成相同密文:如果明文没有进行padding,那么相同的明文加密后会得到相同的密文,这样会导致安全性问题。通过padding可以防止相同的明文加密后生成相同的密文。
-
增加安全性:padding可以使随机性更强,防止攻击者通过对密文的分析获得明文的信息。
RSA本身不算是一个公钥加密算法(这里不是很理解),但是明文经过padding以后,我们用one-way trapdoor function或者是trapdoor one way permutation去做一下,就是个公钥加密算法了,而它的安全性(比如CPA、CCA)取决于我们的padding,而能不能证出来取决于我们的proof。
下面介绍One Way function(单向函数)。
· 单向函数
单向函数是整个密码学里面最基础的一个假设(因为我们不知道one way function是否真的存在)。
在单向函数中,对于定义域内的任何,在多项式时间内
一定是可以计算出来的,多项式时间的敌手也无法快速地找到单向函数输出所对应的原像。也就是以下定义:

(上图图解:在密码学中,一般这样的我们叫做安全参数,
为可忽略函数,而右边的Invert就是我们在论文中经常见到的“game”,这里game可以理解成:有一个challenger,有一个adversary,前者相当于是考官,后者相当于是考生,challenger出一些题让adversary做考试,通过adversary的behave来判断考试有没有通过,也就是game有没有win。这里为什么叫game,因为我们规定了adversary的能力,规定其能知道什么,不能知道什么,然后给出考试时间,比如两个小时要交卷)
言归正传,challenger先随意选一个(
是
位的二进制),然后计算
。把安全参数和
给adversary,让他选出一个
,adversary选出以后,问challenger,
是否等于
,如果确实相等,那么敌手赢得这个game,否则输。这里有了一些新的认识:
-
这里adversary A不要求challenger严格回答出
的值,我们的判断标准并不是A拿出的
等不等于
对应的一个原像就可以,而并不一定是challenger所选择的这个原像
-
那么有了单向函数这个铺垫以后,我们不禁会思考:可以不可以用当作是
的一个承诺呢?

是不能的。因为只是一个单向函数而已,不满足承诺的hiding特性。
ps: 密码学中的承诺都是满足两个性质的:
-
hiding(隐藏性):根据
的承诺不能推断出关于
-
binding(捆绑性):没有
而对于单向函数来说,如果我们知道的映射结果集比较小,或者是
可能的取值很少,那么比较容易推断出
的信息。单向函数的输出通常是与输入相对应的、确定性的值,这种输出很难被视为随机的或均匀分布的,那么攻击者可能会利用这些信息来推断出输入。
那么既然不可以作为
的承诺,那我们是否可以用
作为
的一个承诺呢,如上图中问题2所示。这种看似安全的操作实质上hiding和binding一个也不满足。因为敌手可以通过尝试很多不同的
去猜测
的一些比特位的信息,可能该输出会泄露
中的部分比特信息,不满足hiding;由于
的值也不公开,那么其他参与者无法验证承诺的合法性。如果承诺的值被篡改,其他参与者也无法发现这种欺骗行为,不满足binding。但如果
是一个随机预言机(random oracle),那么
就可以是一个承诺。
· 离散对数
离散对数一般是基于group generator(群生成器,输入一个安全参数,输出一个group。但在实际中一般不使用,使用有说服力的公认的Security Group,比如我们对Group做定义,使其基于离散对数假设),离散对数假设的定义如下图中右下方所示:

首先输入一个安全参数,group generator会产生一个循环群,它的阶数是
,并且产生一个
。随后从
中均匀随机抽样出一个
,再提供给敌手关于group的一些信息
,看敌手是否能提供一个
使得
。上述概率式成立就表明在离散对数中给定一个生成元
和一个群元素
,敌手无法在多项式时间内求解出
。
注:
-
在有些资料中,这里的概率没有减去默认赢的概率
,原因是
-
概率一般要加上绝对值,因为敌手如果错的概率达到一个不可忽略的级别,我们认为他也是有一定能力的。
· DH密钥协商协议
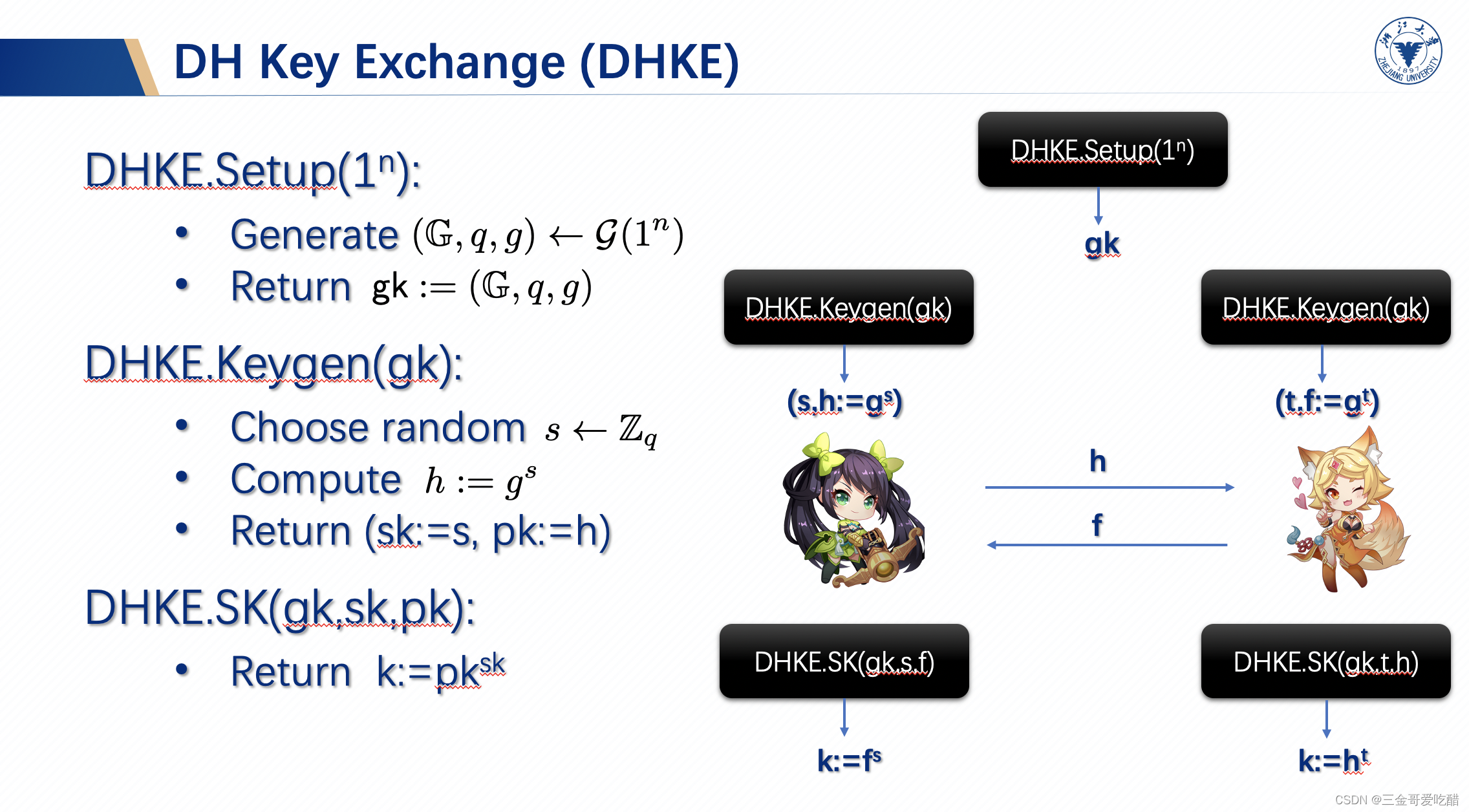
课程中主要是举了DH密钥协商协议的例子来进行可证明安全的证明。DH密钥协商协议分为初始化阶段,密钥生成阶段和生成会话密钥阶段,如下图所示:
-
Setup就是上述提到的group generator,将产生的group公开,双方都使用这个group;
-
两方分别产生一对公私钥对:
和
,然后相互交换公钥
和
的值;
-
在拥有了对方的公钥以后,双方用SK function产生最终的密钥:
和
。
那么DH密钥协商协议是安全的吗?
综上所述,我们判断xxx方案或协议是不是-安全的,需要先基于一个假设并定义其安全性。那么我们在证明DHKE安全性之前,需要确定DHKE在哪个假设之下是安全的,我们需要首先确定安全性和所基于的假设,然后使用规约的方式来证明DHKE可以在多项式时间内被规约到特定假设,若该假设是困难的,则说明被证明的密码方案很难被攻破,就具有安全性。如下图所示:

· 用可证明安全证明DH密钥协商协议的安全性
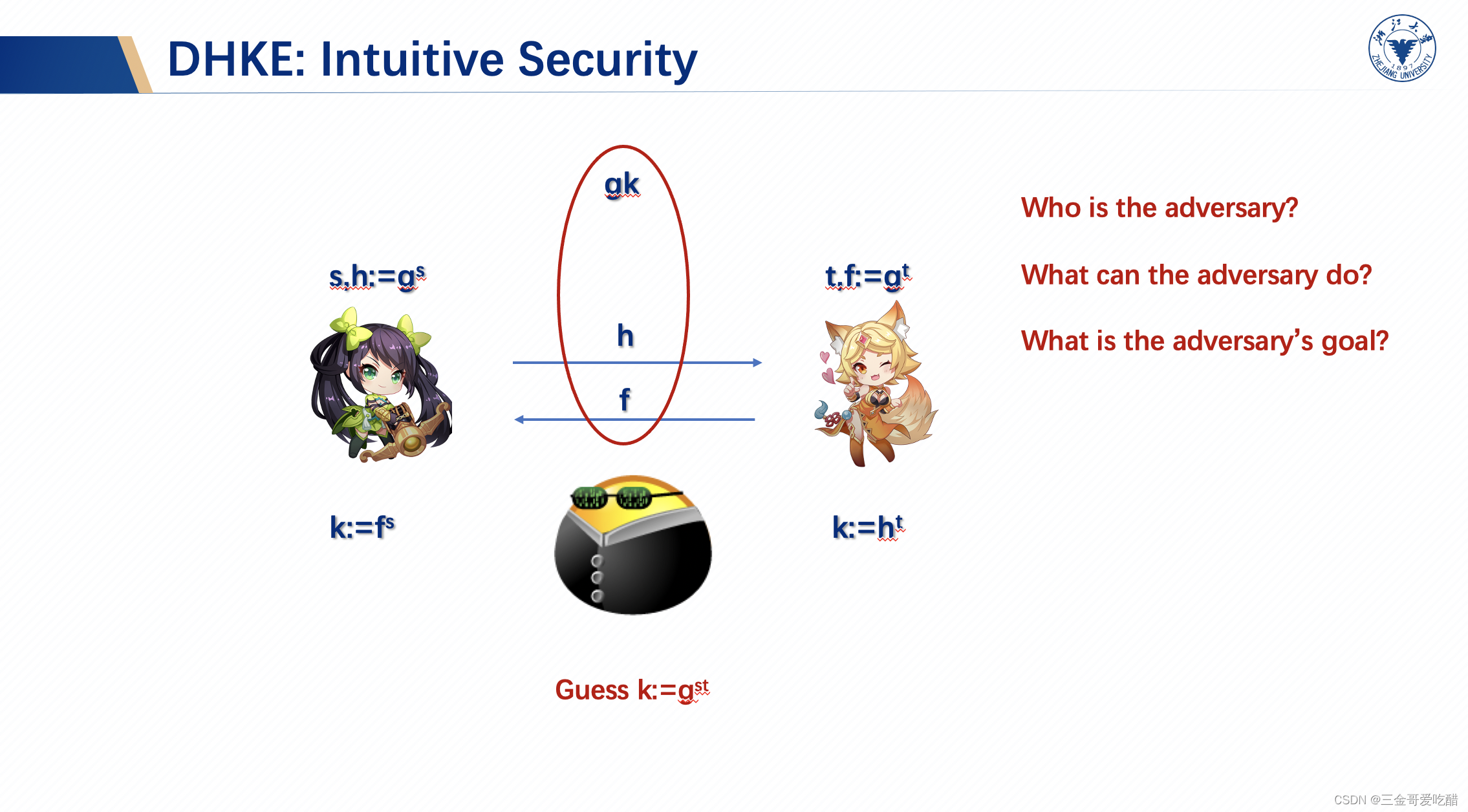
首先我们需要先定义安全目标,在协议/算法执行过程中,敌手是谁,敌手的攻击能力和确定敌手的攻击目标。在真实的实践中,如下图所示我们认为敌手就是中间的黑客,他所能知道的信息有:、
和
,他只能看到这些信息,不能对其进行篡改和操作,他的目标是猜到最终的密钥
。这里假设双方都是诚实的,并无作恶。
\
由于敌手要做的是密钥恢复,以下是关于密钥恢复(Key Recovery)算法的安全性的安全定义和安全模型:

那接下来我们如何证明安全性呢?首先要找assumption,而上述只介绍了离散对数假设问题,那么能不能把DH密钥协商的协议规约到离散对数问题呢?很显然是不可以的。
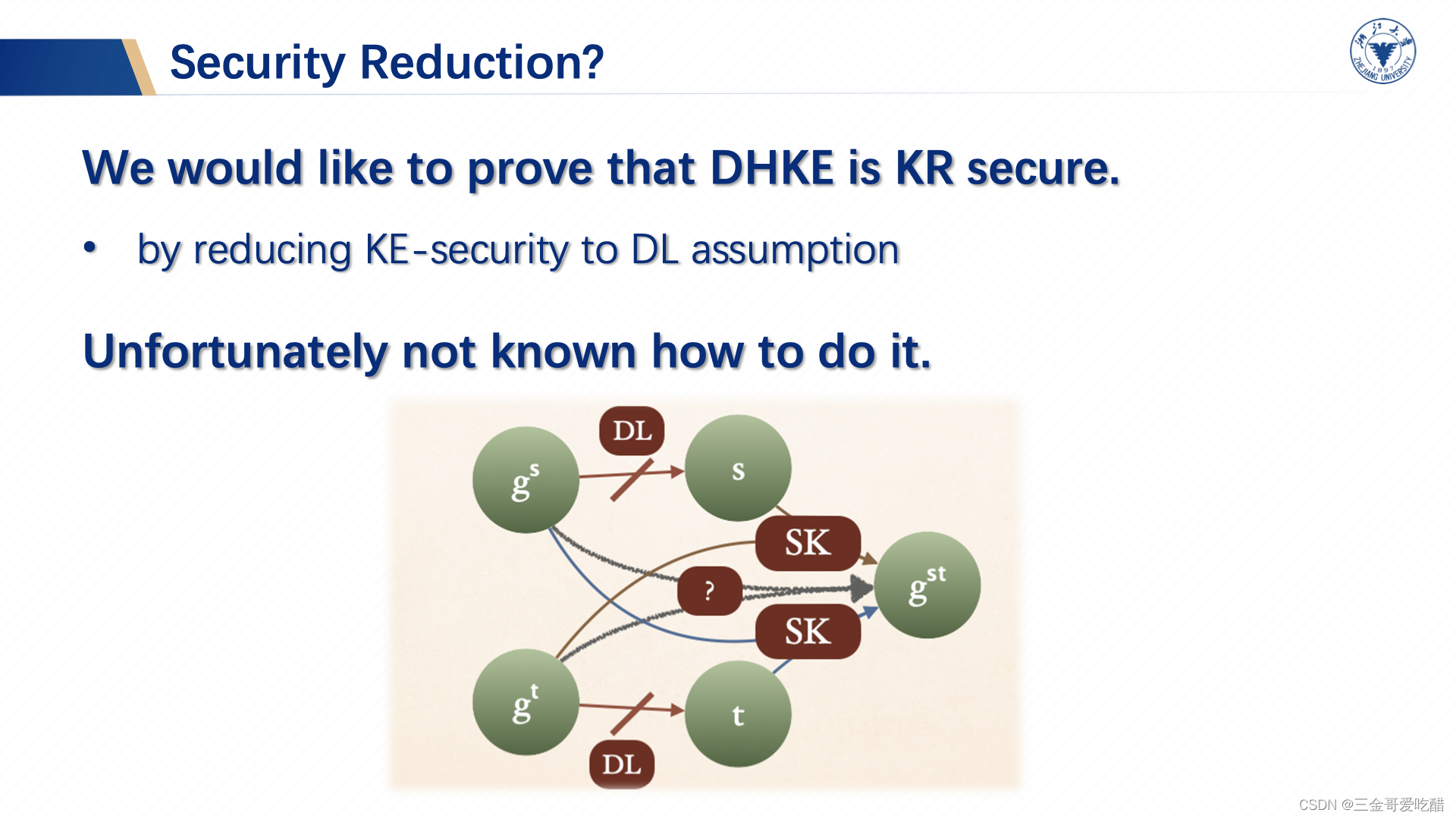
如上图所示,获得密钥是敌手的目标,
和
都是私钥,
和
是公钥。如果DL假设不成立,那么给出
和
,敌手是能获得
和
的,那么有了双方的公钥
和
,再加上现在已经有了
和
,那么就能够计算出最终的密钥
了。但是现在面临的问题是敌手拥有
和
,通过上图中的两条黑色的线,为什么获得不了
。那么这并不是一个离散对数问题了,把这个问题规约到DL assumption是不会成功的。
所以我们需要引入计算性的DH问题,简记为CDH(CDH assumption讲的就是DHKE is secure,那么就回到了从严式/永真式的问题,通俗来讲就是把刚刚的密钥恢复用Diffle-Hellman的语言再写一遍),下图介绍了CDH的敌手攻击能力和对应的博弈。

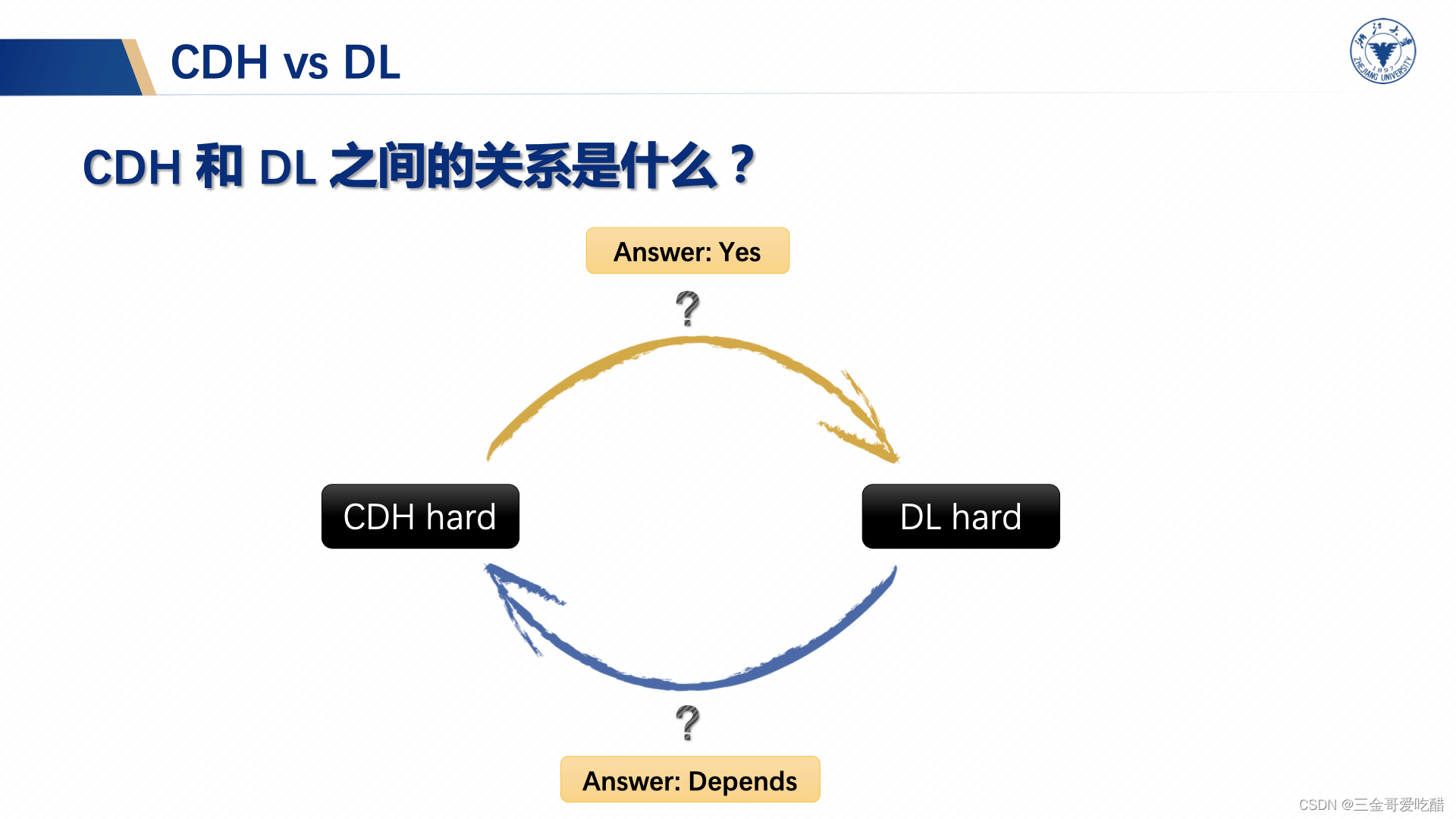
离散对数(DL)和CDH的关系如下图所示,当CDH是困难的,那么DL是困难的,同时如果DL问题是困难的,CDH问题在某些条件下才是困难的(结合上上幅图就很容易理解了)。我们将采用该定理来实现安全性的规约。

注:上图中在绝大多数的情况下,adversary B需要我们自己去构造。标准的范式应该是:给定一个adversary A能去破解DL,我们需要构造一个adversary B使其能破解CDH。
规约其实就是假设某个问题是困难的,那么能够规约到该问题的原问题也是困难的。一般规约分为两个步骤:
-
给构造;
-
证明我们构造出的adversary真的可以赢得对应的game。
CDH和DL问题也是这样的关系,下图描述了他们之间的关系(CDH是困难的,那么DL也是困难的):
证明过程:
-
这里我们假设敌手A可以去破坏DL,这里的A我们可以就当一个黑盒来看,也就是给它一个
的信息,它可以返回一个
。
-
敌手B想利用A这个黑盒去赢得CDH的game,那么基于他已经知道了
和
的信息,这里我们可以令
和
,B此时给出一个
-
如果A猜的
就能破解出DHKE的密钥了(此时B能破解CDH的概率为1);如果A猜的
(此时B能破解CDH的概率为
综上所述,B赢得CDH的概率为:
(此处令,这里
的数量级比
要高,所以
也是可忽略的)
所以如果DL是不安全的,那么CDH一定是不安全的。如果CDH是困难的,那么DL也是困难的。
但是证明安全证明是安全的实际上也不一定是安全的,因为所基于的假设(敌手能做什么,能知道什么,goal是什么)可能太弱了。敌手无法获得密钥k,密钥协商只实现这种安全性是不够的,还需要敌手无法获得关于k的任何信息。
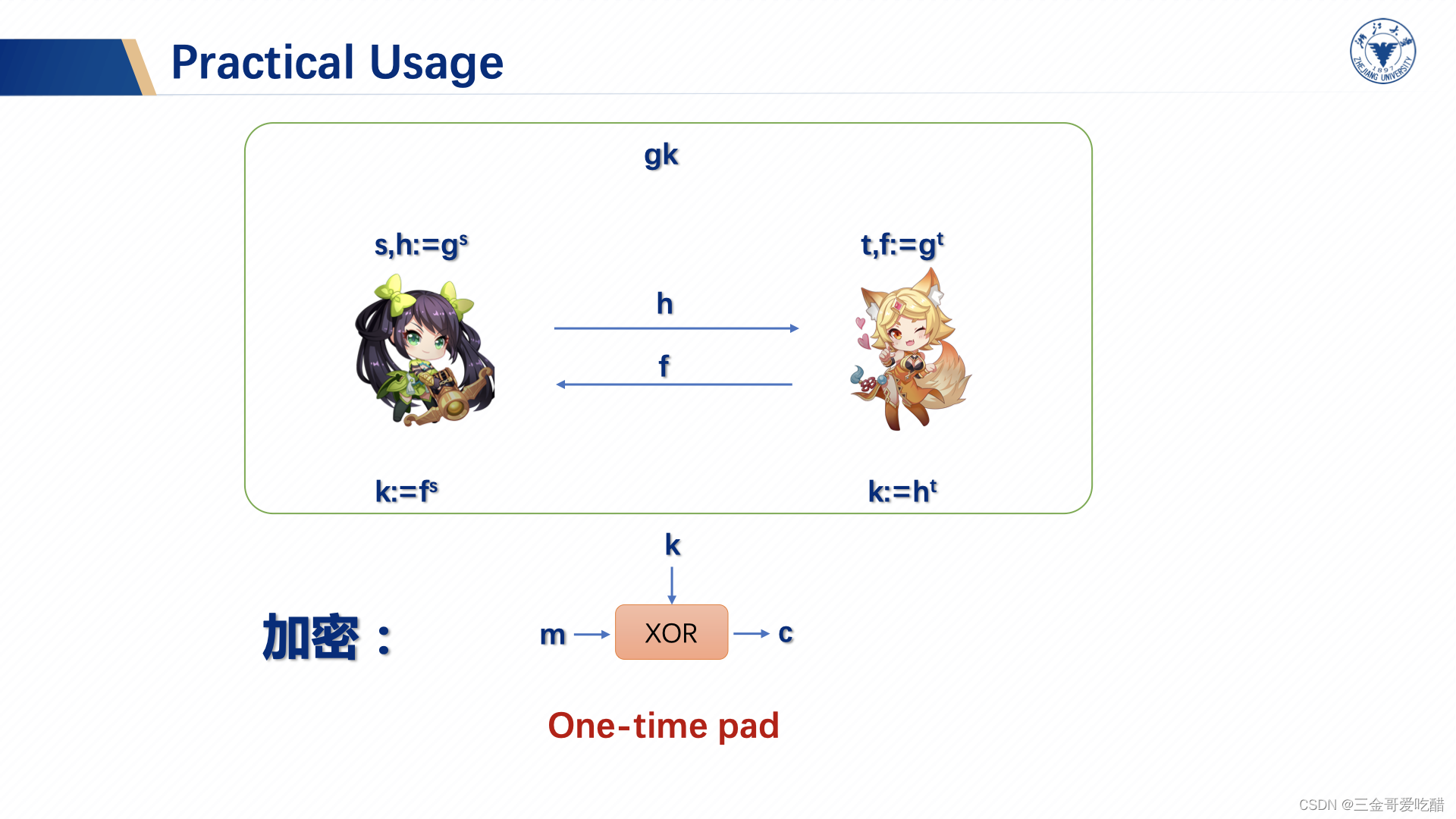
于是我们很容易就想到one-time-pad,因为它的安全等级是perfect security,不基于任何假设。每次使用一个新的随机密钥,对
进行异或操作,给定密文
和随机值,敌手很难在多项式时间内判断哪个是随机值,哪个是密文。如下图所示:
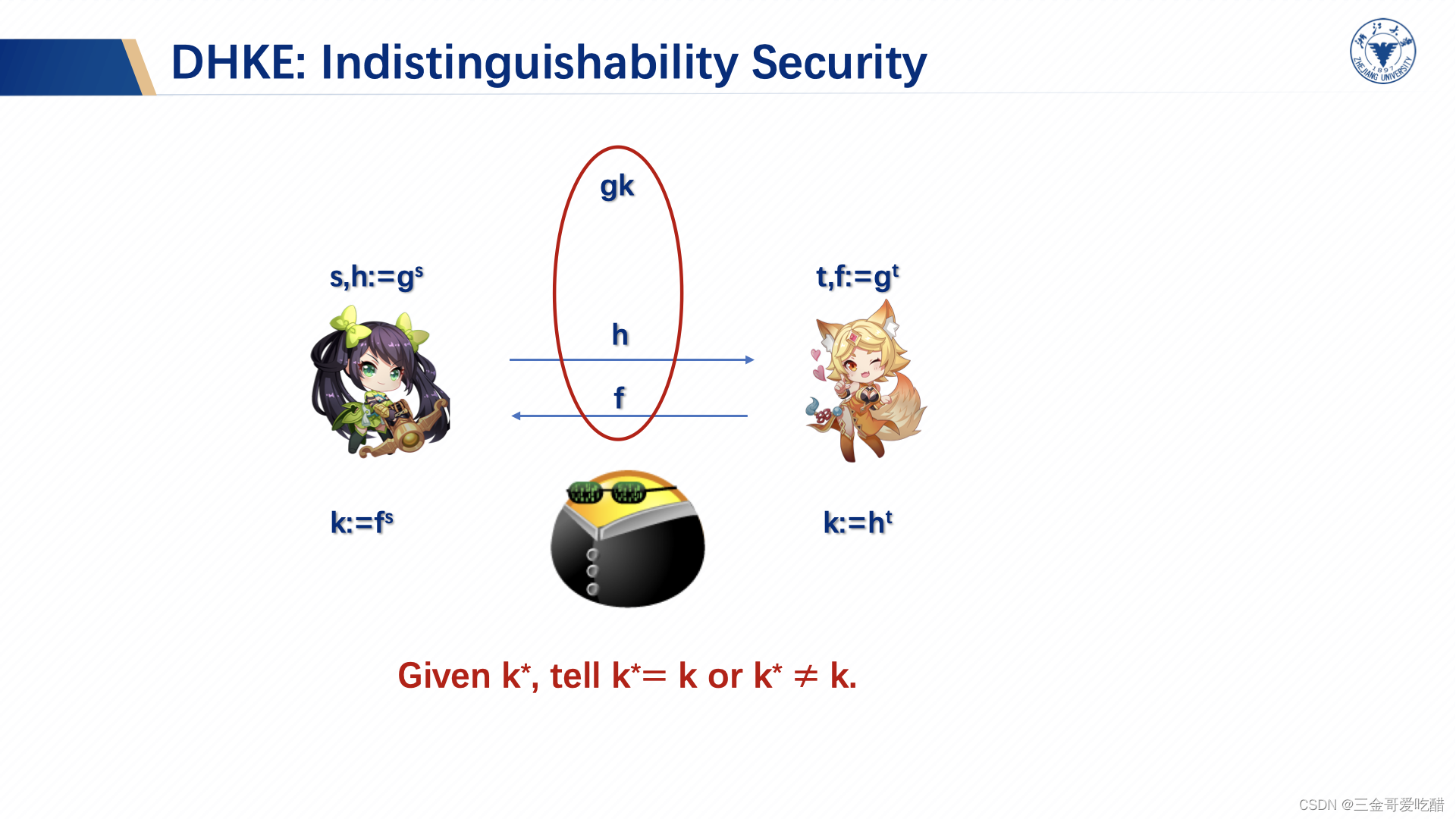
但是如果我们知道每一个的每一个比特异或起来是多少,那我们也就知道每一个
异或起来是多少,那这也造成了信息泄露。于是我们要去了解不可区分安全,也就是给出一个
,敌手无法区分这个
是随机选出来的一个假的值还是真实值。通俗来讲,也就是以
的概率给敌手一个真实的密钥
,以
的概率给敌手一个假的密钥
,敌手无法区分其真实性。如下图所示:
基于此,我们需要对不可区分安全进行一个正式化的定义,下图定义了不可区分(IND)的模型(由于上文中已经介绍了game,这里不再重复解释,相信一定能看懂):

ps:这里还有一种等价的定义,可以做一个对于真实的密钥值的experiment,再做一个对于假的密钥值
的experiment,观察在这两个experiment中的behave是否相同,它们的概率差不了多少(可忽略)。
那我们是否能证明DHKE在基于CDH假设的情况下是满足IND secure的呢?显然不可以。于是我们要介绍一个新的假设:DDH Assumption。下图定义了决定性DH问题,简记为DDH,该问题相对于CDH而言,在安全性证明规约中更通用,安全性也更强(CDH的安全性是敌手不能恢复出整个key,而DDH的安全性是不能区分哪一个是真实的key)。下图是DDH问题的敌手攻击能力和博弈描述(也就是把上面的NIKE的IND security用DH的形式重新描述一遍):

上图中是假的密钥,
是真的,观察敌手是否能赢得game。
有了DDH假设,就能顺理成章地证明DHKE在基于CDH假设的情况下是满足IND secure的。