Java集合常见面试
Java集合概览
主要实现两个接口
- Collection
- Map
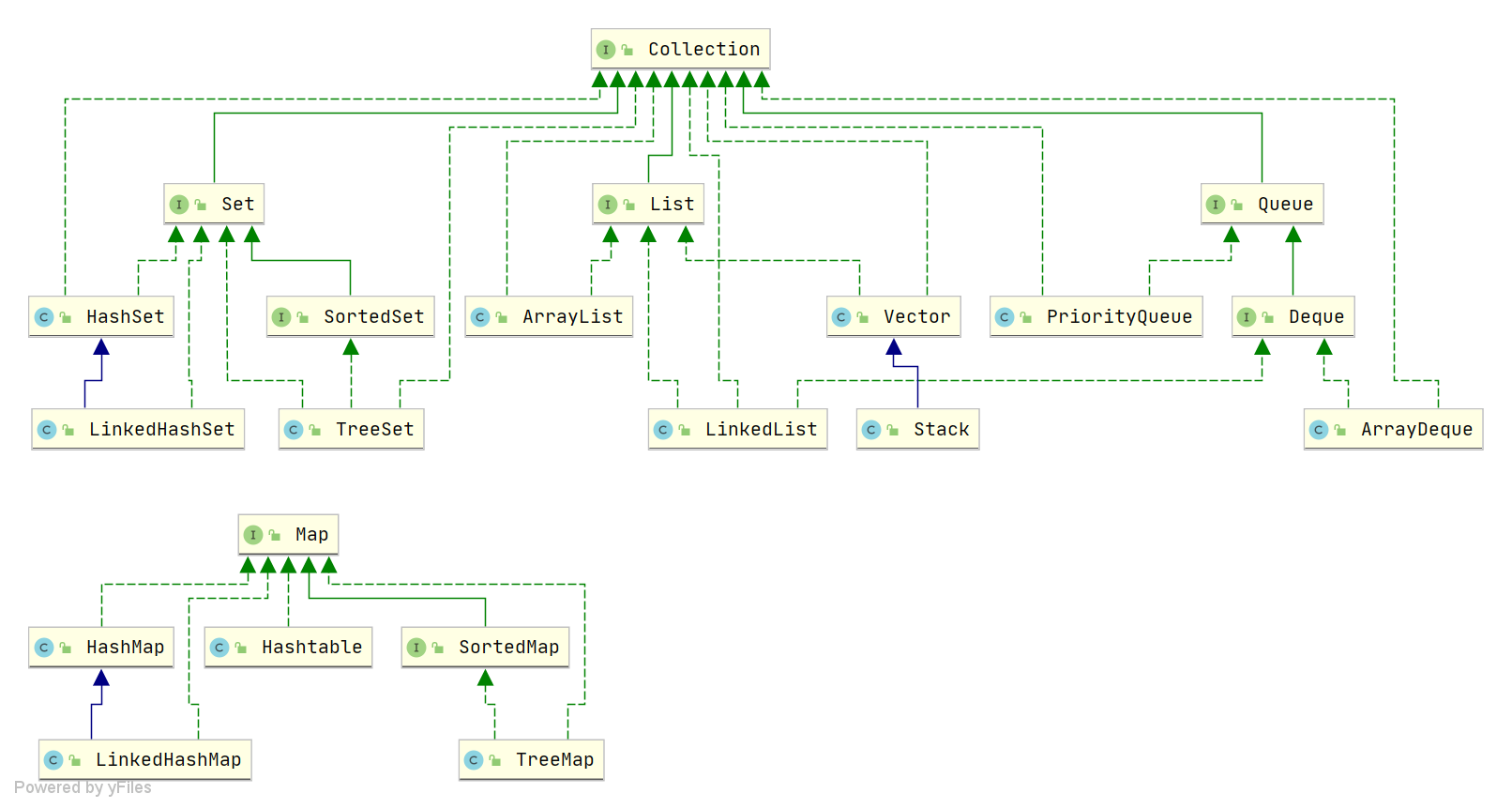
说说 List, Set, Queue, Map 四者的区别?
List顺序,可重复Set独一无二Queue实现排队Map用键值对(key-value)存储,可用key搜索
ArrayList 和 Vector 的区别?
- 是List的主要实现类,线程不安全
- 是List的古老实现类,一般不用,但线程安全
ArrayList 与 LinkedList 区别?
- 线程不保证安全
- 底层数据结构实现不一样:一个用数组,另一个用双向链表
- arrayList插入移动元素比较多,LinkedList插入方便(但也不是特别方便)
- arrayList支持快速随机访问而另一个不支持
- 内存空间占用:LinkedList会更大,因为要存储指针
我们在项目中一般是不会使用到
LinkedList的,需要用到LinkedList的场景几乎都可以使用ArrayList来代替,并且,性能通常会更好!就连LinkedList的作者约书亚 · 布洛克(Josh Bloch)自己都说从来不会使用LinkedList。
说一说 ArrayList 的扩容机制吧
- 在插入元素前会调用ensureCapacityInternal()确保容量
- 容量不足的时候会调用grow方法,新容量为旧容量的1.5倍
- 把旧的数据复制到新的
comparable 和 Comparator 的区别
comparable接口实际上是出自java.lang包 它有一个compareTo(Object obj)方法用来排序comparator接口实际上是出自 java.util 包它有一个compare(Object obj1, Object obj2)方法用来排序
无序性和不可重复性的含义是什么
- 无序就是底层存储没有顺序,而是根据数据的哈希值决定顺序
- 不可重复性指的是添加元素时会进行equals判断
比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
- 都是Set的实现类,不是线程安全的
- HashSet基于hash表,
LinkedHashSet的底层数据结构是链表和哈希表,TreeSet底层数据结构是红黑树, - 应用场景不同,看对顺序的要求,
HashSet用于不需要保证元素插入和取出顺序的场景,LinkedHashSet用于保证元素的插入和取出顺序满足 FIFO 的场景,TreeSet用于支持对元素自定义排序规则的场景。
Queue 与 Deque 的区别
Queue是单端队列,只能从一端插入元素,另一端删除元素,实现上一般遵循 先进先出(FIFO) 规则。Deque是双端队列,在队列的两端均可以插入或删除元素。
HashMap 和 Hashtable 的区别
- HashMap线程不安全,Hashtable线程安全(用了synchronized修饰内部方法)
- 因为线程安全的问题,HashMap效率更高
HashMap可以存储 null 的 key 和 value- HashMap中,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),HashTable不存在这样的机制
HashMap 和 HashSet 区别
HashMap |
HashSet |
|---|---|
实现了 Map 接口 |
实现 Set 接口 |
| 存储键值对 | 仅存储对象 |
调用 put()向 map 中添加元素 |
调用 add()方法向 Set 中添加元素 |
HashMap 使用键(Key)计算 hashcode |
HashSet 使用成员对象来计算 hashcode 值,对于两个对象来说 hashcode 可能相同,所以equals()方法用来判断对象的相等性 |
HashSet 如何检查重复?
HashSet的add()方法只是简单的调用了HashMap的put()方法,并且判断了一下返回值以确保是否有重复元素。
HashMap 的底层实现
解决hash冲突的方式变了
JDK1.8之前

JDK1.8之后

ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
- 数据结构不同:一个是数组加树或者链表,一个还是数据加链表
- 线程安全实现不同:
ConcurrentHashMap是分段锁的Hashtable就一把锁
ConcurrentHashMap和Hashtable的区别主要体现在实现线程安全的方式上不同。
- 底层数据结构: JDK1.7 的
ConcurrentHashMap底层采用 分段的数组+链表 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable和 JDK1.8 之前的HashMap的底层数据结构类似都是采用 数组+链表 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;- 实现线程安全的方式(重要):
- 在 JDK1.7 的时候,
ConcurrentHashMap对整个桶数组进行了分割分段(Segment,分段锁),每一把锁只锁容器其中一部分数据(下面有示意图),多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。- 到了 JDK1.8 的时候,
ConcurrentHashMap已经摒弃了Segment的概念,而是直接用Node数组+链表+红黑树的数据结构来实现,并发控制使用synchronized和 CAS 来操作。(JDK1.6 以后synchronized锁做了很多优化) 整个看起来就像是优化过且线程安全的HashMap,虽然在 JDK1.8 中还能看到Segment的数据结构,但是已经简化了属性,只是为了兼容旧版本;Hashtable(同一把锁) :使用synchronized来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。