提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言支持向量机的核函数

有了核函数之后,我们无需去担心究竟应该是什么样,因为非线性SVM中的核函数都是正定核函数(positive definite kernel functions),他们都满足美世定律(Mercer’s theorem),确保了高维空间中任意两个向量的点积一定可以被低维空间中的这两个向量的某种计算来表示(多数时候是点积的某种变换)。
关于理论部分,参看其他书本,这里演示支持向量机在非线性数据集上不可分,经过核函数变换后变成线性可分。

1、不同核函数在非线性数据集的表现
代码如下(示例):
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import make_circles
from mpl_toolkits import mplot3d
#产生非线性数据集
X,y = make_circles(100, factor=0.1, noise=.1)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
#定义画图函数
def plot_svc_decision_function(model, ax=None):
if ax is None:
ax = plt.gca()
# 画决策边界:制作网格,理解函数meshgrid
xlim = ax.get_xlim()
ylim = ax.get_ylim()
#在最大值和最小值之间形成30个规律的数据
x = np.linspace(xlim[0],xlim[1],30)
y = np.linspace(ylim[0],ylim[1],30)
#使用meshgrid函数将两个一维向量转换为特征矩阵
#核心是将两个特征向量广播,以便获取y.shape * x.shape这么多个坐标点的横坐标和纵坐标
X,Y = np.meshgrid(x,y)
#其中ravel()是降维函数,vstack能够将多个结构一致的一维数组按行堆叠起来
xy = np.vstack([X.ravel(), Y.ravel()]).T
#重要接口decision_function,返回每个输入的样本所对应的到决策边界的距离
#然后再将这个距离转换为axisx的结构,这是由于画图的函数contour要求Z的结构必须与X和Y保持一致
P = model.decision_function(xy).reshape(X.shape)
#画决策边界和平行于决策边界的超平面
ax.contour(X, Y, P,colors="k",levels=[-1,0,1],alpha=0.5,linestyles=["--","-","--"])
ax.set_xlim(xlim)
ax.set_ylim(ylim)
#线性核函数不能把数据分开
clf = SVC(kernel = "linear").fit(X,y)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
plot_svc_decision_function(clf)

非线性核函数的处理效果
clf = SVC(kernel = "rbf").fit(X,y)
plt.scatter(X[:,0],X[:,1],c=y,s=50,cmap="rainbow")
plot_svc_decision_function(clf)
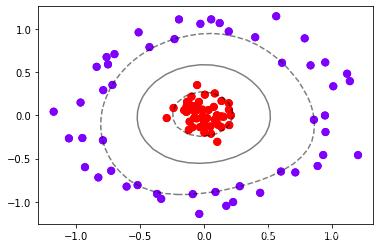
#此案例用来说明如果是非线性可分数据集,我们可以把此数据映射到高维空间,那么此数据集就变得线性可分
#这个过程就是核变换,即是将数据投影到高维空间中,以寻找能够将数据完美分割的超平面,即是说寻找能够让#数据线性可分的高维空间。
r = np.exp(-(X**2).sum(1))
rlim = np.linspace(min(r),max(r),100)
# elev表示上下旋转的角度
# azim表示平行旋转的角度
def plot_3D(elev=30,azim=30,X=X,y=y):
ax = plt.subplot(projection="3d")
ax.scatter3D(X[:,0],X[:,1],r,c=y,s=50,cmap='rainbow')
ax.view_init(elev=elev,azim=azim)
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.set_zlabel("r")
plt.show()
from ipywidgets import interact,fixed
interact(plot_3D,elev=[0,30,60,90,120],azip=(-180,180),X=fixed(X),y=fixed(y))
plt.show()
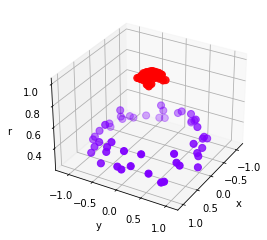
2、探索核函数在不同数据集上的表现
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
from sklearn import svm
from sklearn.datasets import make_circles, make_moons, make_blobs,make_classification
# noise设置的越大,那么噪声就越大,factor:factor:0 < double < 1 默认值0.8,内外圆之间的比例因子,设置的越大,两个环就越近
n_samples = 100
datasets = [
make_moons(n_samples=n_samples, noise=0.2, random_state=0),
make_circles(n_samples=n_samples, noise=0.2, factor=0.5, random_state=1),
make_blobs(n_samples=n_samples, centers=2, random_state=5),
#n_informative表示有信息的特征,n_redundant表示无信息的特征
make_classification(n_samples=n_samples,n_features = 2,n_informative=2,n_redundant=0, random_state=5)
]
Kernel = ["linear","poly","rbf","sigmoid"]
#四个数据集分别是什么样子呢?
for X,Y in datasets:
plt.figure(figsize=(5,4))
plt.scatter(X[:,0],X[:,1],c=Y,s=50,cmap="rainbow")
# 构建子图
nrows=len(datasets)
ncols=len(Kernel) + 1
fig, axes = plt.subplots(nrows, ncols,figsize=(20,16))
#第一层循环:在不同的数据集中循环
for ds_cnt, (X,Y) in enumerate(datasets):
#在图像中的第一列,放置原数据的分布
ax = axes[ds_cnt, 0]
if ds_cnt == 0:
ax.set_title("Input data")
#zorder的值越大,图像显示在上面,表示散点图最优先
#cmap是两种差异比较大的颜色,edgecolors每个点的边缘是黑色的
ax.scatter(X[:, 0], X[:, 1], c=Y, zorder=10, cmap=plt.cm.Paired,edgecolors='k')
ax.set_xticks(())
ax.set_yticks(())
#第二层循环:在不同的核函数中循环
#从图像的第二列开始,一个个填充分类结果
for est_idx, kernel in enumerate(Kernel):
#定义子图位置
ax = axes[ds_cnt, est_idx + 1]
#建模
clf = svm.SVC(kernel=kernel, gamma=2).fit(X, Y)
score = clf.score(X, Y)
#绘制图像本身分布的散点图
ax.scatter(X[:, 0], X[:, 1], c=Y,
zorder=10,cmap=plt.cm.Paired,
edgecolors='k')
#绘制支持向量
ax.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1], s=50,
facecolors='none', zorder=10, edgecolors='k')
#绘制决策边界
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
#np.mgrid,合并了我们之前使用的np.linspace和np.meshgrid的用法
#一次性使用最大值和最小值来生成网格
#表示为[起始值:结束值:步长]
#如果步长是复数,则其整数部分就是起始值和结束值之间创建的点的数量,并且结束值被包含在内
XX, YY = np.mgrid[x_min:x_max:200j, y_min:y_max:200j]
#np.c_,类似于np.vstack的功能
Z = clf.decision_function(np.c_[XX.ravel(), YY.ravel()]).reshape(XX.shape)
#填充等高线不同区域的颜色
ax.pcolormesh(XX, YY, Z > 0, cmap=plt.cm.Paired)
#绘制等高线
ax.contour(XX, YY, Z, colors=['k', 'k', 'k'], linestyles=['--', '-', '--'],levels=[-1, 0, 1])
#设定坐标轴为不显示
ax.set_xticks(())
ax.set_yticks(())
#将标题放在第一行的顶上
if ds_cnt == 0:
ax.set_title(kernel)
#为每张图添加分类的分数
ax.text(0.95, 0.06,
('%.2f' % score).lstrip('0'),#不要显示0.11的0
size=15,#尺寸大小
#为分数添加一个白色的格子作为底色,boxstyle圆角格子,alpha透明度,facecolor格子颜色
bbox=dict(boxstyle='round', alpha=0.8, facecolor='white'),
#确定文字所对应的坐标轴,就是ax子图的坐标轴本身
transform=ax.transAxes,
horizontalalignment='right' #位于坐标轴的什么方向
)
# 图像之间的间隔为紧缩模式
plt.tight_layout()
plt.show()
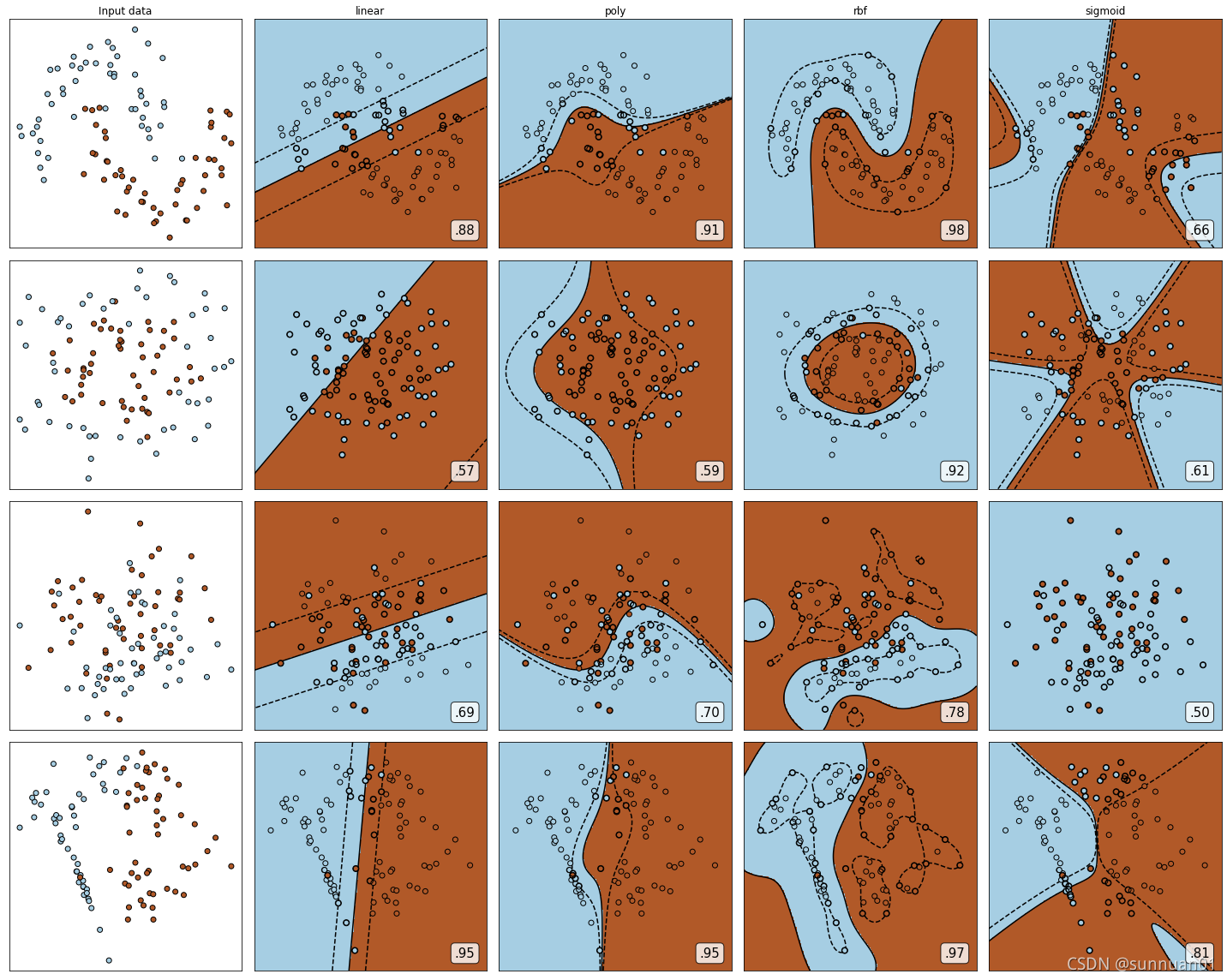
rbf高斯径向基核函数基本在任何数据集上都表现不错,属于比较万能的核函数
线性核函数和多项式核函数在非线性数据上表现会浮动,如果数据相对线性可分,则表现不错,如果
是像环形数据那样彻底不可分的,则表现糟糕。在线性数据集上,线性核函数和多项式核函数即便有扰动项也可以表现不错,可见多项式核函数是虽然也可以处理非线性情况,但更偏向于线性的功能。
Sigmoid核函数就比较尴尬了,它在非线性数据上强于两个线性核函数,但效果明显不如rbf,它在线性数据上完全比不上线性的核函数们,对扰动项的抵抗也比较弱,所以它功能比较弱小,很少被用到。
#代码来自菜菜机器学习