Flume自定义拦截器对数据进行脱敏处理
前言
使用Flume自定义拦截器,对较为敏感的数据进行MD5加密处理,本示例需要对以下数据中的用户密码,进行脱敏处理,并过滤性别字段数据。
# 数据样例
# 用户名 密码 年龄 性别 身高 体重
admin 123456 26 男 170 70 一、编写java程序
- maven依赖
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-sdk</artifactId>
<version>1.8.0</version>
</dependency>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.8.0</version>
</dependency>
</dependencies>自定义拦截器
- MyInterceptor类
public class MyInterceptor implements Interceptor {
// 原始数据字段的分隔符
private String fields_separator;
// 需要保留字段索引,形式如:1,2,3,4
private String indexs;
// indexs的分隔符
private String indexs_sparator;
// 需要加密字段索引
private String filed_encrypted_index;
public MyInterceptor(String fields_separator, String indexs, String indexs_sparator, String filed_encrypted_index) {
this.fields_separator = fields_separator;
this.indexs = indexs;
this.indexs_sparator = indexs_sparator;
this.filed_encrypted_index = filed_encrypted_index;
}
public void initialize() {
}
public Event intercept(Event event) {
if (event == null) return null;
// 通过获取event数据,转化成字符串
String line = new String(event.getBody(), Charsets.UTF_8);
// 通过分隔符分割数据
String[] split = line.split(fields_separator);
//获取需要保留的字段索引
String[] indexs_data = indexs.split(indexs_sparator);
// 需要加密的索引
int encrypted_index = Integer.parseInt(filed_encrypted_index);
String newLine = "";
for (int i = 0; i < indexs_data.length; i++) {
int index = Integer.parseInt(indexs_data[i]);
String filed = split[index];
if (index == encrypted_index) {// 字段需要加密处理
//通过MD5加密
filed = StringUtils.GetMD5Code(filed);
}
// 拼接字符串
newLine += filed;
//字段之间添加分隔符,舍弃最后一个
if (i < indexs_data.length - 1) {
newLine += fields_separator;
}
}
event.setBody(newLine.getBytes(Charsets.UTF_8));
return event;
}
public List<Event> intercept(List<Event> list) {
if (list == null) return null;
List<Event> events = new ArrayList<Event>();
for (Event event : list) {
Event intercept = intercept(event);
events.add(intercept);
}
return events;
}
public void close() {
}
public static class Builder implements Interceptor.Builder {
// 原始数据字段的分隔符
private String fields_separator;
// 需要保留字段索引,形式如:1,2,3,4
private String indexs;
// indexs的分隔符
private String indexs_sparator;
// 需要加密字段索引
private String filed_encrypted_index;
public Interceptor build() {
return new MyInterceptor(fields_separator, indexs, indexs_sparator, filed_encrypted_index);
}
public void configure(Context context) {
fields_separator = context.getString(Constant.FIELDS_SEPARATOR, Constant.DEFAULT_FIELD_SEPARATOR);
indexs = context.getString(Constant.INDEXS, Constant.DEFAULT_INDEXS);
indexs_sparator = context.getString(Constant.INDEXS_SEPARATOR, Constant.DEFAULT_INDEXS_SEPARATOR);
filed_encrypted_index = context.getString(Constant.FIELD_ENCRYPTED_INDEX, Constant.DEFAULT_FIELD_ENCRYPTED_INDEX);
}
}
}- StringUtils类
public class StringUtils {
// 全局数组
private final static String[] strDigits = {"0", "1", "2", "3", "4", "5",
"6", "7", "8", "9", "a", "b", "c", "d", "e", "f"};
// 返回形式为数字跟字符串
private static String byteToArrayString(byte bByte) {
int iRet = bByte;
if (iRet < 0) {
iRet += 256;
}
int iD1 = iRet / 16;
int iD2 = iRet % 16;
return strDigits[iD1] + strDigits[iD2];
}
// 返回形式只为数字
private static String byteToNum(byte bByte) {
int iRet = bByte;
System.out.println("iRet1=" + iRet);
if (iRet < 0) {
iRet += 256;
}
return String.valueOf(iRet);
}
// 转换字节数组为16进制字串
private static String byteToString(byte[] bByte) {
StringBuilder sb = new StringBuilder();
for (byte b : bByte) {
sb.append(byteToArrayString(b));
}
return sb.toString();
}
public static String GetMD5Code(String strObj) {
String resultString = null;
try {
MessageDigest md = MessageDigest.getInstance("MD5");
// md.digest() 该函数返回值为存放哈希值结果的byte数组
resultString = byteToString(md.digest(strObj.getBytes()));
} catch (NoSuchAlgorithmException ex) {
ex.printStackTrace();
}
return resultString == null ? strObj : resultString;
}
}
- Constants类:定义常量,与配置文件中字段相对应
public class Constant {
// 字段分隔符
public static final String FIELDS_SEPARATOR = "fields_separator";
// 默认字段分隔符
public static final String DEFAULT_FIELD_SEPARATOR = " ";
// indexs
public static final String INDEXS = "indexs";
// 默认indexs为0
public static final String DEFAULT_INDEXS = "0";
// indexs的分隔符
public static final String INDEXS_SEPARATOR = "indexs_separator";
// 默认indexs分隔符
public static final String DEFAULT_INDEXS_SEPARATOR = ",";
// 加密字段索引
public static final String FIELD_ENCRYPTED_INDEX = "filed_encrypted_index";
// 默认加密字段索引,为空
public static final String DEFAULT_FIELD_ENCRYPTED_INDEX = "";
}- 打成jar包
如图所示:
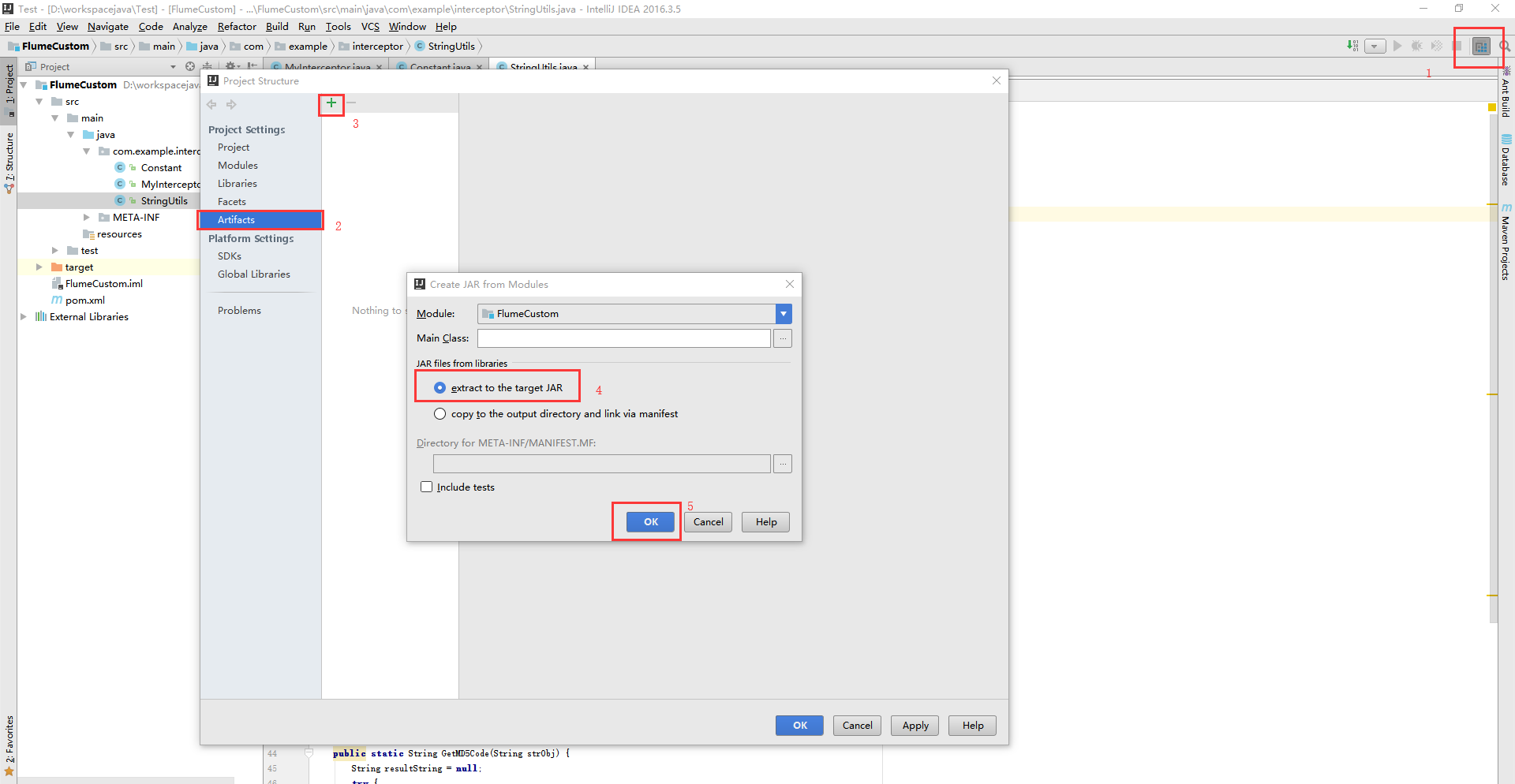
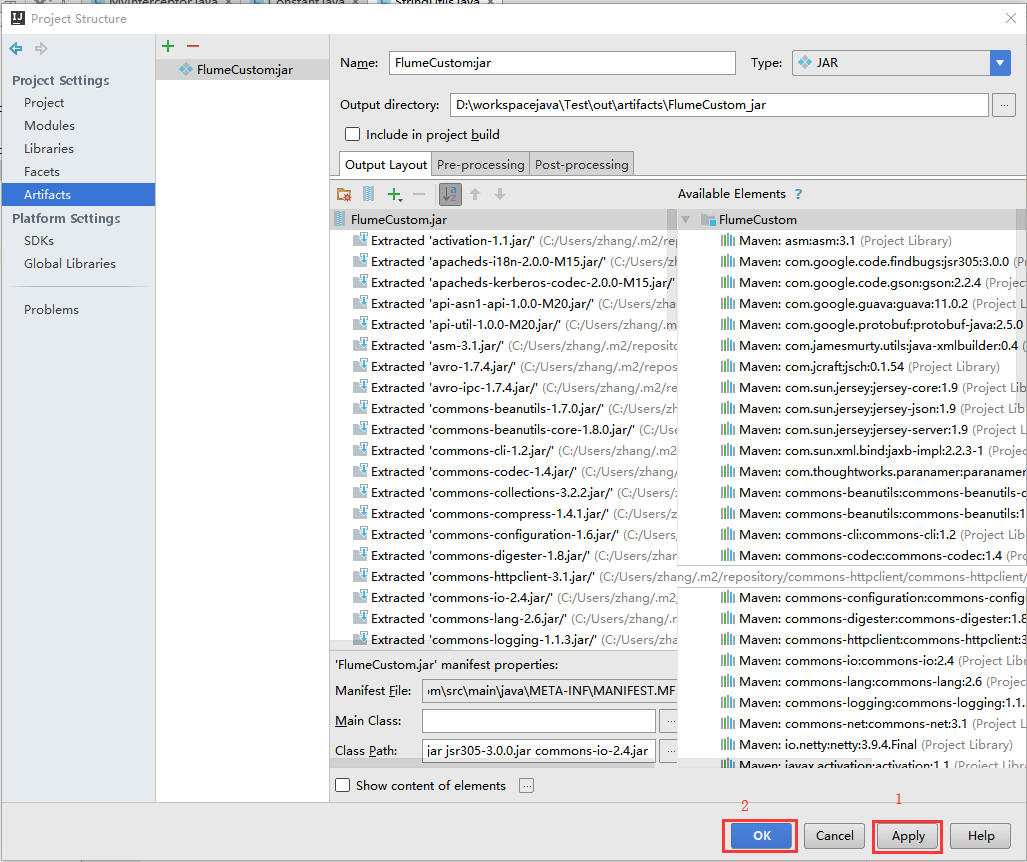
然后在选中Build–>Build Artfacts,出现一个弹窗,点击Build就会在out目录下生成jar。
- 上传到
flume/lib目录
scp Flume-Custom.jar hadoop@server01:/hadoop/flume/lib
二、编写配置文件
配置文件名称:flume-custom-en.conf,放入flum/conf目录
a1.sources = r1
a1.sinks = s1
a1.channels = c1
#source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/hadoop/data
a1.sources.r1.batchSize= 50
# 设置字符集UTF-8
a1.sources.r1.inputCharset = UTF-8
a1.sources.r1.interceptors =i1 i2
# 自定义拦截器
a1.sources.r1.interceptors.i1.type =com.example.interceptor.MyInterceptor$Builder
# 字段分隔符
a1.sources.r1.interceptors.i1.fields_separator=,
# 需要保留的字段
a1.sources.r1.interceptors.i1.indexs =0,1,2,4,5
# indexs的分隔符
a1.sources.r1.interceptors.i1.indexs_separator=,
# 需要加密处理的字段索引
a1.sources.r1.interceptors.i1.filed_encrypted_index =0
a1.sources.r1.interceptors.i2.type = timestamp
#sink
a1.sinks.s1.type = hdfs
a1.sinks.s1.hdfs.path =hdfs://192.168.100.11:9000/flume-log/en/%Y%m%d
a1.sinks.s1.hdfs.filePrefix = event
a1.sinks.s1.hdfs.fileSuffix = .log
a1.sinks.s1.hdfs.rollSize = 10485760
a1.sinks.s1.hdfs.rollInterval =20
a1.sinks.s1.hdfs.rollCount = 0
a1.sinks.s1.hdfs.batchSize = 1500
a1.sinks.s1.hdfs.round = true
a1.sinks.s1.hdfs.roundUnit = minute
a1.sinks.s1.hdfs.threadsPoolSize = 25
a1.sinks.s1.hdfs.useLocalTimeStamp = true
a1.sinks.s1.hdfs.minBlockReplicas = 1
a1.sinks.s1.hdfs.fileType =DataStream
a1.sinks.s1.hdfs.writeFormat = Text
a1.sinks.s1.hdfs.callTimeout = 60000
a1.sinks.s1.hdfs.idleTimeout =60
#channel
a1.channels.c1.type = memory
a1.channels.c1.capacity=100000
a1.channels.c1.transactionCapacity=50000
# 设置r1 s1 c1之间的关系
a1.sources.r1.channels = c1
a1.sinks.s1.channel = c1三、执行
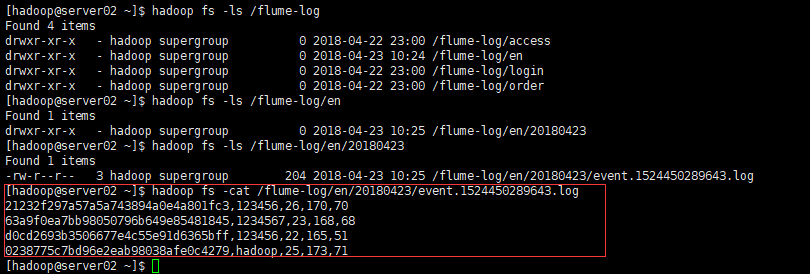
将需要脱敏的data放入/home/hadoop/data目录中。
测试文件内容如下
admin,123456,26,男,170,70
root,1234567,23,男,168,68
zhang,123456,22,女,165,51
hadoop,hadoop,25,男,173,71- 启动flume服务
bin/flume-ng agent -c conf -f conf/flume-custom-en.conf -name a1 -Dflume.root.logger=INFO,console- 查看hdfs中结果