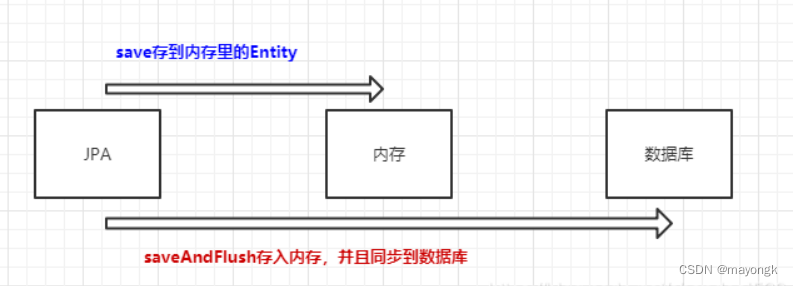
一、一张图片直接明白他俩的区别
 二、写个栗子看看
二、写个栗子看看
数据库创建一张表users
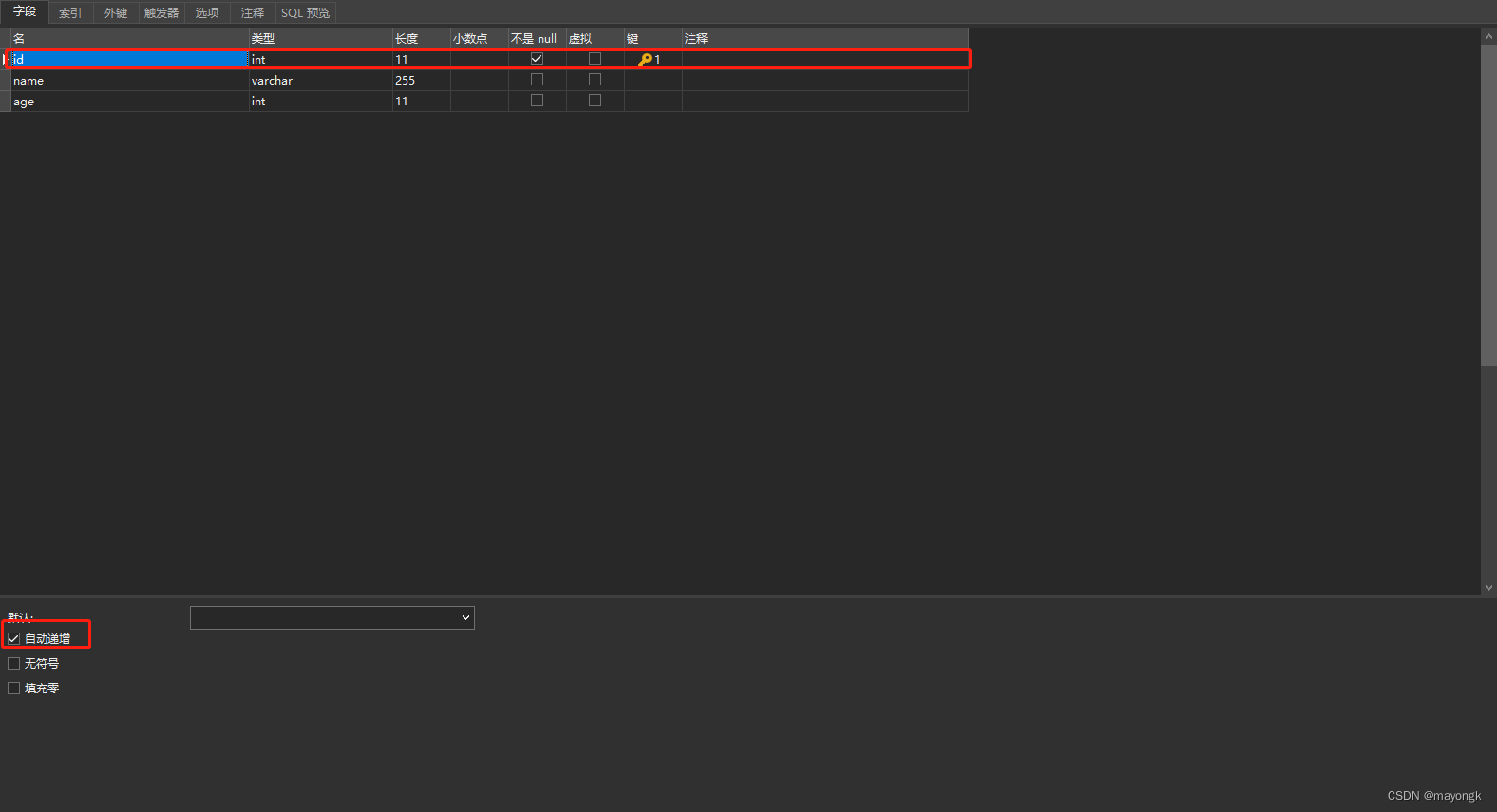
设置id为自增长
接下来就是创项目,引依赖,这些我就跳过了,说重点
先看一段代码
@Override
@Transactional(rollbackFor = Exception.class)
public void testabc() {
Users byId = usersRepository.findOneById(1L);
System.out.println(byId);
String s = UUID.randomUUID().toString();
System.out.println(s);
byId.setName(s);
usersRepository.save(byId);
System.out.println("=================================================");
Users byId1 = usersMapper.getById(1L);
System.out.println(byId1);
}代码很简单,我先根据id查询一条数据,然后将name字段改为随机生成的uuid,然后使用jpa进行save操作,由于是有id的,所以save就是更新数据,然后打印了一个分割线,然后再使用mybatis查询这个id,请注意第二次查询,我是使用的mybatis
离谱的事情来了,看我的打印日志
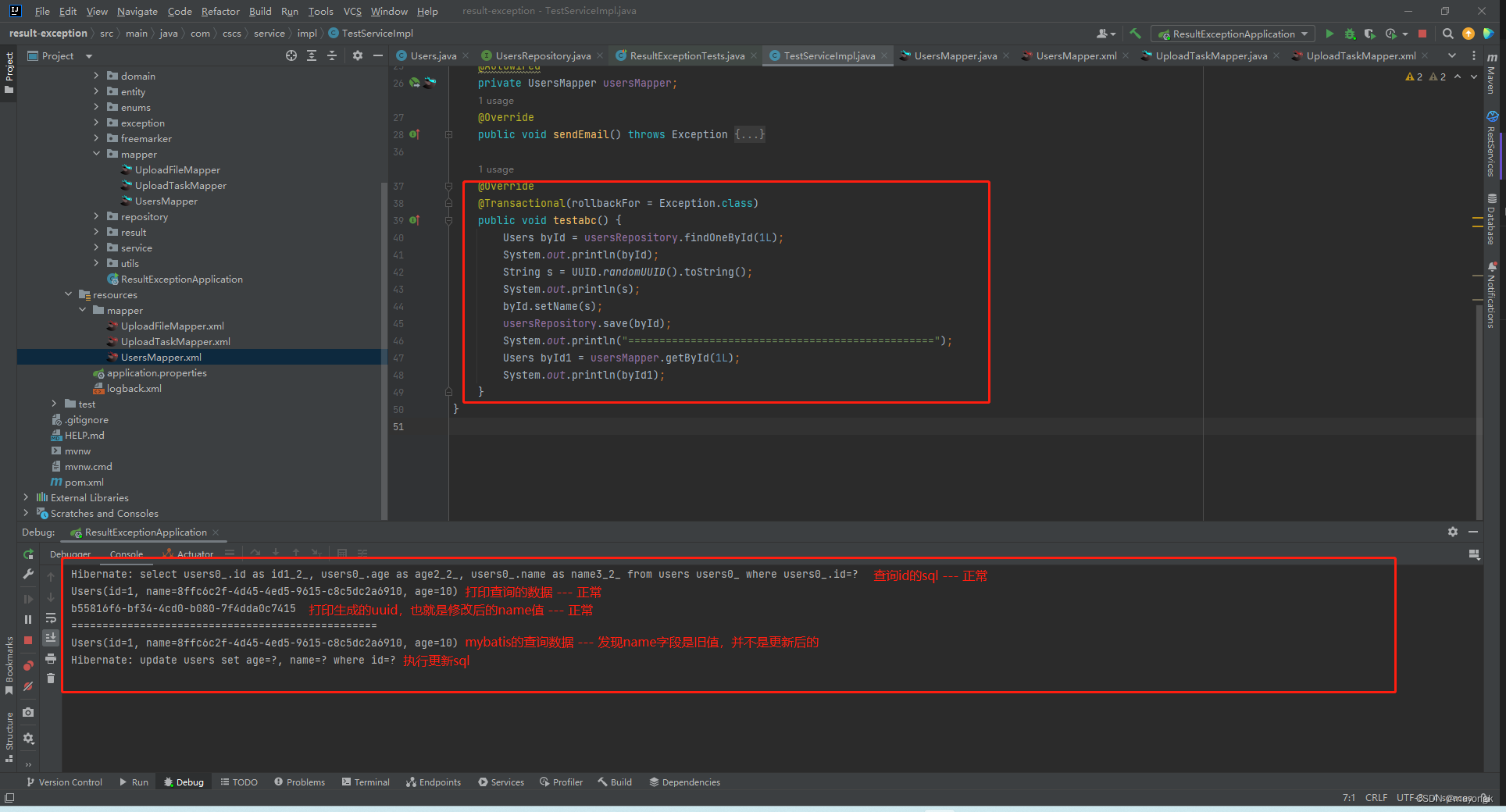
在整个方法中我都添加了事务控制,按理来说,在同一个session中,我是可以查询到还未提交的数据,但是为什么我使用mybatis查询的却是旧值?
其实这验证了最上方图片的 save方法的流程,他并没有执行sql,只是在你的缓存到了内存中,所以数据库的值是并没有发生改变的
由于我给整个方法都添加了事务,所以只有在整个方法执行完,才会执行jpa的save语句,这也说的通为什么,更新语句在最后面打印的,而不是在分割线之前打印的。
三、接下来我们把save换成saveAndFlush
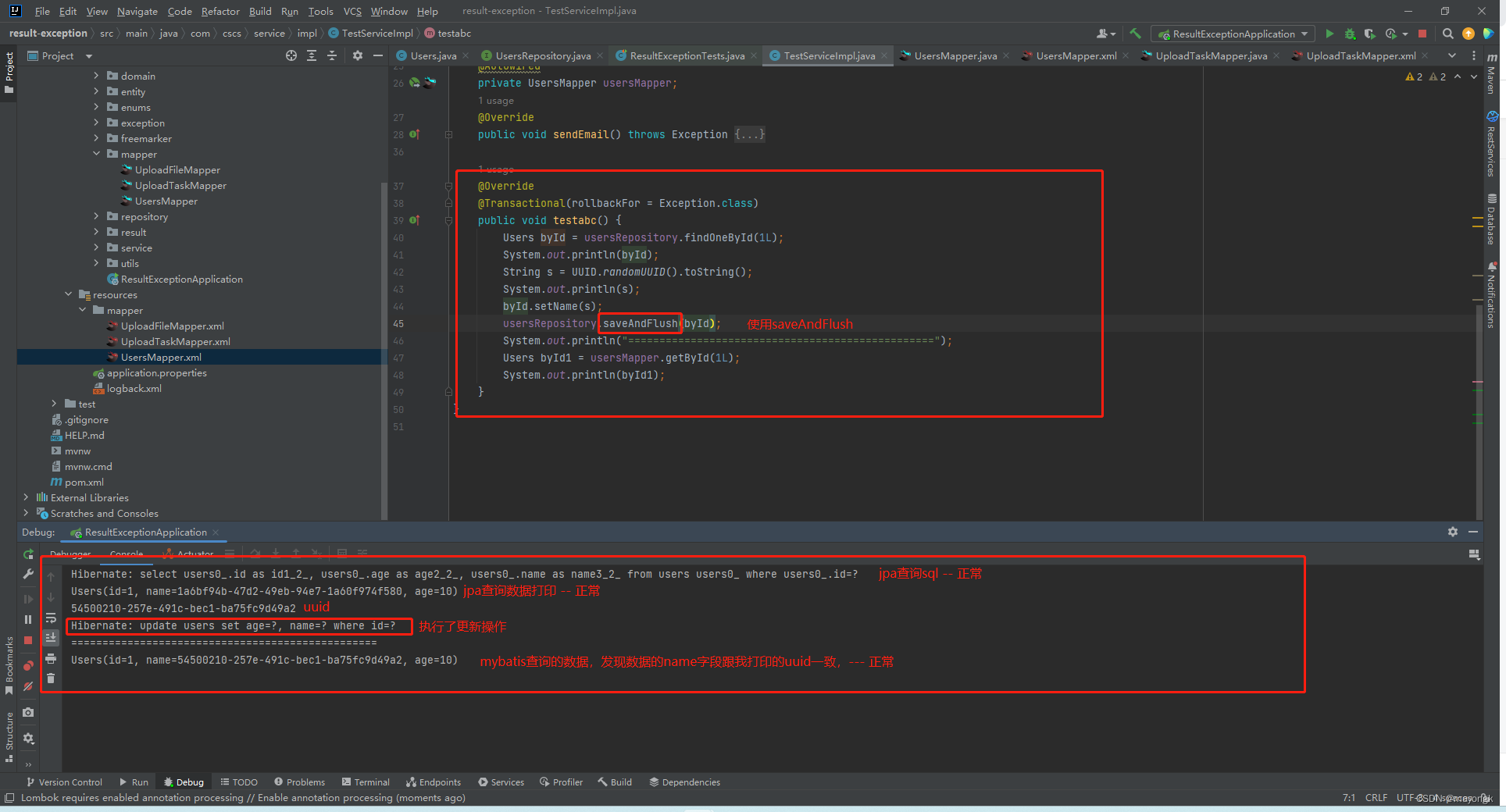
对嘛,这才是正常的结果,但是要注意一点,saveAndFlush,不是commit操作,重要的事情说三遍
saveAndFlush,不是commit操作!!!
saveAndFlush,不是commit操作!!!
saveAndFlush,不是commit操作!!!
还是要等到整个方法执行完,然后提交事务,数据库才能看见修改后的数据
昨天晚上就遇到了这个问题,坑啊,
如果后续我不使用mybatis查询,也是用jpa查询,那么打印的数据也是修改后的
一定要注意