© 2016-2023 Conmajia × A. Bryan
Updated 11th March, 2023
Initiated 27th June, 2016
摘要 本文改编自 How to Create Your Own Virtual Machine 系列文章,承蒙原作者 Alan L. Bryan 许可. 文中提及的商标、名称等所有权归于其各自权利所有者.
简介
亲爱的读者朋友,你正在阅读的这个系列文章将从零开始,带你设计并实现一个完整可运行的虚拟机. 本文是这个系列的第一篇文章. 我们将使用 C# 语言,基于 .NET Framework 2.0 实现此虚拟机. 你需要具备最基本的 .NET 开发知识. 或者说,你应当至少具备使用 Visual Studio 开发环境进行简单 C# 编程的能力.
在开始设计前,我们先来了解一下虚拟机的相关知识. 所谓虚拟机即是一种“虚拟”硬件环境的中间件. 它是高度隔离的软件容器,可以运行自己的操作系统和应用程序. 从运行其上的应用程序角度看去,这就是一台“物理的”计算机:包含自己的处理器,甚至具有一台真正计算机应有的 RAM、磁盘或者网络接口卡(NIC)等硬件——尽管这些都是基于软件,于宿主计算机上实现的. 这里提到的宿主计算机指的是运行虚拟机的实体计算机.
计算机操作系统无法区分虚拟机与实体机,应用程序和网络中的其他计算机同样对此无能为力. 即使是虚拟机本身也认为自己是一台“真正的”计算机. 由于虚拟机完全由软件实现,因此可以做到在相当程度上不依赖于具体硬件. 这是虚拟机独特的优势.
虚拟机的特点
一般而言,虚拟机具备以下关键特点,也是设计虚拟机时的设计方向.
- 兼容性:虚拟机可以根据需要,兼容采用不同型号处理器的宿主计算机
- 隔离性:虚拟机运行于沙盒模式,可以有效隔离内部程序和宿主计算机
- 独立性:虚拟机运行于应用层,除驱动部分外不依赖于底层硬件
而在我们的设计中,虚拟机——我们命名为 SunnyApril ——被设计为由中央处理器、显示缓存组成的无外设结构. 这也许和你想象中的类似 VMWare、Parallel Desktop、Virtual PC 之类商用虚拟机不同,但其基本原理是别无二致的——除了商用版本会用到宿主处理器的高级特性,或者提供丰富的虚拟外设,并且不需要自行汇编可执行文件.
设计中央处理器
我们将 SA 设计成一个 16 位的虚拟机,这意味着它的 CPU 核心位宽将是 16 比特的. 如此一来,SA 可以支持的内存寻址空间为 0x0000-0xFFFF 共 64 KB.
通用寄存器
寄存器是计算机结构中一个重要的概念和组件. 一类是特殊功能寄存器,通过设置寄存器内容改变处理器运行方式,这在单片微处理器中十分常见. 另一类被称为通用寄存器(general purpose registers,GPR),用于数据交换和计算结果缓存.
不同于消费者熟知的 CPU 片内缓存,通用寄存器是位于 CPU 核心内的第一级原生缓存,其速度一般是门电路级,读写周期在 1 至 2 个时钟周期内. 例如
若以 Intel 处理器常见的 L1、L2 等高速缓存作为对照,通用寄存器以其运行速度和优先级而言,可以被称为 L0 级,甚至是 L-1 级缓存,其速度和优先级远高于 L1 级. 一方面如此高速的存储单元造价极高,另一方面过多的寄存器会增加处理器核心和内部通信总线复杂度,通常情况下计算机 CPU 中不会设计太多通用寄存器. 以 Intel i9-12900K 处理器为例,其 L1、L2、L3 级缓存分别为 32 KB、6 MB、24 MB,而该款 CPU 的寄存器数量则仅为 28 个,容量仅 288 字节. 当然,这里指的寄存器是通用寄存器,不包括用于配置处理器功能的专用寄存器.
作为演示,我们为 SA 设计了 5 个寄存器:A、B、D、X、Y. 其中,A、B 寄存器是 8 位寄存器,可存储数字范围 0x00-0xFF;X、Y、D 寄存器是 16 位寄存器,可存储数字范围 0x0000-0xFFFF.
D 寄存器是一个特殊的 16 位寄存器,它的值是由 A、B 寄存器的值合并而成. D 的高 8 位 DH 中保存 A 寄存器值,低 8 位 DL 则保存 B 寄存器值. 举个例子,某时刻虚拟机处理器中 A 寄存器的值为 0x3C,B 寄存器的值为0x10,则此时 D 寄存器值为 0x3C10. 改变 D 寄存器的值,则 A、B 寄存器的内容也会相应地改变.

▲ SA 处理器寄存器示意图
设计“虚拟显示器”

▲ 合理的视觉反馈对于提高成就感的帮助极大
为了让虚拟机能在第一时间反馈运行结果,我们从 SA 的 64 KB 内存空间中划出 4000 字节空间 0xA000-0xAFA0,用作显示缓存. 我们模仿用于 x86 处理器的 MASM 宏汇编语言,用这 4000 字节中的 2000 字节保存需要显示的 ASCII 字符——即一个 80×25 大小的字符型显示器. 剩余的 2000 字节用于保存每个字符的样式:每个样式字节的第 0 至 2 位表示前景色颜色值,共支持 7 种颜色;第 3 位表示明暗度;第 4 至 6 位则用于表示背景颜色值. 样式字节的最高位第 7 位是保留位,用于未来扩展. 下图解释了样式字节的格式,其中 SCRnnn 表示对应第 nnn 个显示字节,范围从 0x000 到 0x7D0.

▲ SA 显示器样式字节内容
- F2…0 前景色(文字)
- DIM 明暗开关
- B2…0 背景色
设计指令集
为了让我们的 CPU 运行起来,需要为它设计一套指令集,这类似于 Intel 处理器的 x86 指令集、ARM 的 Thumb 指令集,或者 Atmel1 的 AVR 8 位指令集.
简单期间,我们在此设计 4 个指令,分别是 A 寄存器写入 LDA、X 寄存器写入 LDX、内存写入 STA、结束指令 END. 表 1 简单列举了这几个指令的功能和用法.
| 指令 | 机器码 | 功能 | 示例 |
|---|---|---|---|
| LDA | 01 |
将数据存入 A 寄存器 | LDA #51H |
| LDX | 02 |
将数据存入 X 寄存器 | LDX #123 |
| STA | 03 |
将 A 寄存器的值写入指定内存地址,支持所有寻址方式 | STA X |
| END | 04 |
结束程序. 如果给出了汇编起始位置,则汇编器将从给定位置开始汇编 | END |
实际使用中,# 开头的数字表示这是“立即数”,后缀 H 表示其为十六进制. 类似地,B、O、D 分别用于表示二进制、八进制、十进制. 其中十进制可以省略后缀,例如 #1234 表示十进制数 1234.
指令 01、02:LDA、LDX
这两个指令的功能是写入 A 寄存器或 X 寄存器,即“load A”或“load X”. 下面的例子基于 LDA 演示了指令的用法.
1: LDA #51H ; (A) <- 51H
2: LDA 1234 ; (A) <- (1234),溢出
3: LDA X ; (A) <- (X)
注意第 2 行中数值 1234 超出了 8 位的 A 寄存器存储范围,将产生溢出错误. 此时 A 寄存器中数值将为其最大值 255,同时 SA 处理器中特殊功能寄存器 SFR 的 OV 位被置位,OV=1. 关于特殊功能寄存器,将在本章最后讲解.
LDX 与此类似,唯一区别是 X 寄存器支持 16 位的数据.
指令 03:STA
STA 是内存写入指令,用于将 A 寄存器的数据写入指定内存位置. 这里给出几个例子:
STA #1234 ; (1234) <- (A)
STA X ; (X) <- (A)
指令 04:END
END 是程序终止指令. 汇编器将在读取到该指令后停止对源代码的汇编动作.
设计一个汇编器
汇编器是从文本形式的源文件到二进制格式的机器码——也叫可执行文件2——的翻译器. 也许是处于程序员的恶趣味,大部分的二进制文件格式都是以一串所谓“魔法数字”的字符串开头. 例如,Windows 系统的 exe 文件以“MZ”开头. Java 的二进制文件开头是 4 个字节的数字:3405691582 ,用 16 进制表示即为“CAFEBABE”(咖啡宝贝). 我们在 SA 中也将使用 8 个字节的“CONMAJIA”作为魔法数字.
可执行文件结构
可执行文件以魔法数字开始,如图所示. 8 字节的之后是偏移量,即包含可执行的 CPU 指令的“文件体”部分起始位置. 偏移之后是 2 字节的文件体长度,这意味着每个可执行文件只支持运行编译后长度在 65535 字节,即 64 KB 以内的机器码. 当然,作为演示用的虚拟机,和它带来的便利相比,程序长度的问题不大. 起始地址作为保留字在演示中将始终固定为 0. 偏移段用于保存额外的数据或者中断向量表等,其长度为“偏移-14”字节. 文件头之后是文件体,保存了程序编译后可以直接在虚拟 CPU 中执行的全部字节码.

▲ SA 机器码文件结构,图中“B”为字节数
汇编器
由于这是一个简单的演示,所以我们不希望搞得过于复杂并牵扯出编译理论中的那些词法、句法之类的晦涩理论. 我们只是简单地设计一个可以把用文本形式写成的汇编源代码翻译为 SA 处理器可识别的机器码的工具.
假设我们规定了汇编指令的编写规范,
; 注释
标签:
<指令> <操作数> <换行>
然后得到一个示范用的汇编源代码,以文本形式保存为 demo1.asm 文件:
1: LDA #65
2: LDX #A000H
3: STA X
4: END
这个程序的功能是把字母 A 输出到屏幕的左上角,即 80×25 显存的第一个位置. 第 1 行代码将立即数 65(即 ASCII 编码中的字母“A”)存入 A 寄存器;第 2 行将立即数 0xA000(即坐标为 (0, 0) 的显示字符缓存的地址)存入 X 寄存器;第 3 行代码以寄存器寻址的方式将 A 寄存器中的值 65 存入 X 寄存器中的数值所指向的内存地址. 最后的 END 结束程序. CPU 执行到此将进入闲置状态.
我们在 Visual Studio 实现了这个汇编器,如图所示.
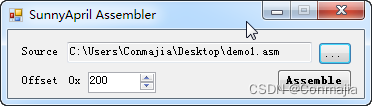
▲ SA 汇编器
这个汇编器的实现代码很简单,使用了一个枚举类型定义各个寄存器:
enum Registers {
A = 4,
B = 2,
D = 1,
X = 16,
Y = 8
}
我们使用二进制写入器 BinaryWriter 实现向文件中写入二进制数据流:
BinaryWriter output;
FileStream fs = new FileStream(
file_path + file_name + ".o",
FileMode.Create
);
output = new BinaryWriter(fs);
// 写入魔法数字 "CONMAJIA",需要确保字母以单字节方式写入而非 Unicode
output.Write("CONMAJIA".ToCharArray());
// 从 offset 指定偏移出开始写入,numericUpDown1 是界面上的数据输入控件
output.Write((UInt16)numericUpDown1.Value);
output.Seek((int)numericUpDown1.Value, SeekOrigin.Begin);
// 逐行解析汇编源代码,textBox1.Text 存有源代码文件路径
TextReader input = File.OpenText(textBox1.Text);
string line;
while ((line = input.ReadLine()) != null) {
parse(line.ToUpper(), output);
dealedSize += line.Length;
// Invoker 请参阅拙作《InvokeHelper:多线程修改主界面控件属性并调用其中方法》
Invoker.Set(
progressBar1,
"Value",
(int)((float)dealedSize / (float)totalSize * 100));
}
input.Close();
output.Seek(10, SeekOrigin.Begin);
output.Write(binaryLength);
output.Write(executionAddress);
output.Close();
fs.Close();
在这个方法中,我们使用一个 while 循环逐行解析源代码,方法如下:
public void parse(string line, BinaryWriter output)
{
// 处理前后空白字符,可以使用任意方法
line = cleanLine(line);
// 判断标签
if (line.EndsWith(":"))
labelDict.Add(line.TrimEnd(new char[] { ':' }), binaryLength);
else {
Match m = Regex.Match(line, @"(\w+)\s(.+)");
string opcode = m.Groups[1].Value;
string operand = m.Groups[2].Value;
switch (opcode) {
case "LDA":
output.Write((byte)0x01);
output.Write(getByteValue(operand));
binaryLength += 2;
break;
case "LDX":
output.Write((byte)0x02);
output.Write(getWordValue(operand));
binaryLength += 3;
break;
case "STA":
output.Write((byte)0x03);
Registers r = (Registers)Enum.Parse(typeof(Registers), operand);
output.Write((byte)r);
binaryLength += 2;
break;
case "END":
output.Write((byte)0x04);
if (labelDict.ContainsKey(operand)) {
output.Write(labelDict[operand]);
binaryLength += 2;
}
binaryLength += 1;
break;
default:
break;
}
}
}
程序中用到了读取 8 位字节 byte 操作数的内部方法,如下所示. 稍作改进可以很方便地支持多种数制. 读取 16 位字 word 操作数的方法与此类似,不再另作说明.
private byte getByteValue(string operand)
{
byte ret = 0;
if (operand.StartsWith("#"))
{
operand = operand.Remove(0, 1);
char last = operand[operand.Length - 1];
if (char.IsLetter(last))
switch (last)
{
case 'H':
// hex
ret = Convert.ToByte(operand.Remove(operand.Length - 1, 1), 16);
break;
case 'O':
// oct
ret = Convert.ToByte(operand.Remove(operand.Length - 1, 1), 8);
break;
case 'B':
// bin
ret = Convert.ToByte(operand.Remove(operand.Length - 1, 1), 2);
break;
case 'D':
// dec
ret = Convert.ToByte(operand.Remove(operand.Length - 1, 1), 10);
break;
}
else
ret = byte.Parse(operand);
}
return ret;
}
需要注意的是以上代码均未加入错误处理的语句,无法处理带有错误的源文件.
我们运行汇编器,对前面保存的 demo1.asm 文件进行汇编,得到 demo1.o 二进制字节码文件. 请注意这里的文件后缀 .o 相当于 Windows 上的可执行文件后缀 .exe,而非编译型编程语言编译器生成的 .o 输出文件.
该文件内容如下:

▲ 汇编完成的可执行文件
可以见到,我们的汇编器忠实地完成了它的任务,正确计算出文件大小,并从 0x0200 处开始,写入了其汇编出的字节码 01 00 02 00 00 03 10 04 00 02 接下来我们用人工校验的方式对比源程序和生成的机器码.
demo1.asm 文件内容为:
1: LDA #65
2: LDX #A000H
3: STA X
4: END
- 第 1 行
LDA指令生成指令字节码0x01,然后存入单字节操作数(A 寄存器是 8 位寄存器)65,即0x41. - 第 2 行
LDX指令生成指令字节码0x02,然后存入双字节操作数(X 寄存器是 16 位寄存器)0xA000,由于开发计算机采用小端模式(低位在前),所以在文件中是以00 A0的形式存储的. - 第 3 行
STA指令生成指令字节码0x03,然后存入Registers.X枚举值(16,即0x10). - 第 4 行
END指令生成指令字节码0x04,然后存入指定的偏移地址0x0200(2 字节,仍以小端模式存储).
根据以上分析,结合生成的机器码可执行文件,我们可以确认 SA 汇编器完全符合设计.
以上就是本季上篇的全部内容. 在下篇中,我们将开始设计虚拟机处理器的核心功能,负责计算的算术逻辑单元 ALU.
(第一季·上篇)
© Conmajia 2012, icemanind 2012