网上的crf++教程很多,但小白还是花了不少时间去整合教程中的信息才得以应用,记录下本次步骤。
一、需求
大需求是抽取公开经济报告中的经济指标数据,其中重要一环是识别其中的经济指标专有名词(还有单位~)。
二、操作系统
window10
三、工具
python、crf++工具包
四、过程
4.1 原始文本
爬虫把标题(含了年份省份区县信息)和报告内容爬下来,存入txt,如下:

4.2 处理
本次大需求是抽取指标数据,故先将原始文本按句号和分号"。;"进行分句(先不加上","分句,保持主语连续便于后续操作),提取出含有数字的分句,减少处理量。处理后如下:

4.3 分词
采用jieba分词,本次再加上词性标注(后续crf++训练做特征用),并处理成cfr++的训练需求格式。代码及形式如下:
#读入分句,分词及词性标注,处理成训练需求的格式
for line in f.readlines():
sentence_seged = jieba.posseg.cut(line.strip())
for x in sentence_seged:
f1.write(x.word + "\t" + x.flag + '\n')初步 d
预测 vn
, x
全市 n
实现 v
生产总值 n
240 m
亿元 m
, x
增长 v
8.5 m
% x
“ x
十二五 m
” x
末 f
人均 j
GDP eng
达到 v
1 x
万美元 m4.4 标注
本次采用BMEWO标注(或BIESO),B(begin):实体的开始,M(middle):实体的中间,E(end):实体的结束,W(whole):单个分词就是实体,实体的全部,O(outside):界外值,非实体的任何一部分。标注在最后一列("\t"分隔),标注后如下:
训练文件 train.txt
初步 d O
预测 vn O
, x O
全市 n O
实现 v O
生产总值 n W
240 m O
亿元 m O
, x O
增长 v O
8.5 m O
% x O
“ x O
十二五 m O
” x O
末 f O
人均 j B
GDP eng E
达到 v O
1 x O
万美元 m O
, x O
人均 j B
财政收入 n E
突破 vn O
1 x O
万元 m O4.5 训练、测验及应用
首先是制作特征模板(template),crf++0.58工具包中有份template(在\example\seg路径下),如下:

搜索"crf++模板"了解template的含义和写法。学习后结合本次的特征情况采用如下模板
# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-1,0]/%x[0,0]
U06:%x[0,0]/%x[1,0]
U10:%x[-2,1]
U11:%x[-1,1]
U12:%x[0,1]
U13:%x[1,1]
U14:%x[2,1]
U15:%x[-2,1]/%x[-1,1]
U16:%x[-1,1]/%x[0,1]
U17:%x[0,1]/%x[1,1]
U18:%x[1,1]/%x[2,1]
U20:%x[-2,1]/%x[-1,1]/%x[0,1]
U21:%x[-1,1]/%x[0,1]/%x[1,1]
U22:%x[0,1]/%x[1,1]/%x[2,1]
# Bigram
B将工具包里的crf_learn.exe、crf_test.exe、libcrfpp.dll以及写好的模板文件template、训练文件train.txt、测试文件test.txt放在同一文件夹(下文称为A文件夹)下
模型训练:命令行下进入A文件夹,输入命令(crf_learn 参数 模板名 训练文件名 输出模型名),搜索"crf++参数"了解参数,本次采用默认参数。训练后A文件夹下生成model文件。
crf_learn template train.txt model模型测试:类似训练的做法,命令行下输入命令(crf_learn 参数 模型名 测试文件名 > 输出文件名),成功后A文件夹下生成标注文件。
crf_test -m model test.txt > bz.txt模型验证:检验模型的召回、F1等信息,本次不展开
模型应用:python执行命令行语句(同测试)调用模型并提取出其中的标注实体,代码及结果如下:
inputfile="inputfile.txt"#输入文件
predictfile="predictfile.txt"#输出模型标注预测文件
os.system("crf_test -m model "+inputfile+" > "+predictfile)#python执行命令行语句
df=pd.read_table(predictfile,sep='\t',header=None)
dflist=df[df[2]!="O"][[0,2]].values.tolist()#pandas提取标注非“O”的,1、3列
print("dflist:",dflist)
starr=[]#保存提取到的命名实体
for i in range(len(dflist)):
temstr = ""
if dflist[i][1]=="W":
starr.append(dflist[i][0])
if dflist[i][1]=="B":
temstr=temstr+dflist[i][0]
for j in range(i+1, len(dflist)):
if dflist[j][1]=="M" or dflist[j][1]=="E":
temstr = temstr + dflist[j][0]
else:break
starr.append(temstr)
print("提取到的命名实体:",starr)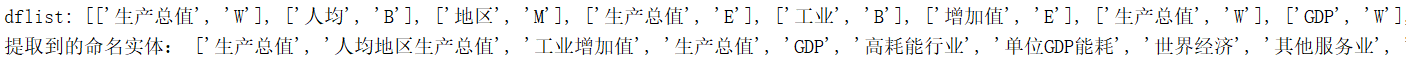
五、后续
1、分词效果不太好,后续试试其他分词工具
2、尝试python中调用crf++工具
——————————————————————————————————————
2020.12.10更新后续啦 https://blog.csdn.net/m0_49621298/article/details/111006708